







完整源码资源下载地址
点此下载完整源码
一、系统综述
1、引言
人脸识别作为生物识别技术的重要分支,已经广泛应用于安全监控、身份认证、人机交互等多个领域。在人脸识别技术中,支持向量机(Support Vector Machine,SVM)作为一种强大的分类器,凭借其出色的分类性能和泛化能力,成为了人脸识别领域的重要工具。本文将对基于SVM支持向量机的人脸识别系统的设计与实现进行综述。
2、SVM支持向量机概述
SVM是一种基于统计学习理论的机器学习方法,其核心思想是通过求解一个二次规划问题,找到一个最优超平面,使得不同类别的样本在该超平面上的间隔最大化。对于非线性可分问题,SVM通过引入核函数,将输入空间映射到高维特征空间,实现非线性分类。
3、人脸识别系统设计
基于SVM的人脸识别系统主要包括以下几个部分:图像预处理、特征提取、SVM分类器训练和人脸识别。
图像预处理:由于人脸图像的复杂性,如光照变化、姿态变化、表情变化等,都会对识别效果产生影响。因此,在进行特征提取之前,需要对人脸图像进行预处理,包括图像去噪、灰度化、归一化、几何校正等步骤,以提高后续特征提取和识别的准确性。
特征提取:特征提取是人脸识别系统的关键环节。通过提取人脸图像中的有效特征,可以降低数据维度,提高分类器的泛化能力。常用的特征提取方法包括主成分分析(PCA)、线性判别分析(LDA)、局部二值模式(LBP)等。在SVM人脸识别系统中,可以根据实际需求选择合适的特征提取方法。
SVM分类器训练:在提取到人脸特征后,需要使用SVM分类器进行训练。训练过程中,首先需要将人脸特征划分为训练集和测试集,然后使用训练集数据训练SVM分类器,得到分类器的最优参数。在训练过程中,可以采用网格搜索、交叉验证等方法对SVM的参数进行优化,以提高分类器的性能。
人脸识别:在SVM分类器训练完成后,就可以使用测试集数据进行人脸识别。将待识别的人脸图像进行预处理和特征提取后,输入到训练好的SVM分类器中,得到分类结果。根据分类结果,可以判断待识别的人脸图像属于哪个类别。
4、实现与优化
在实现基于SVM的人脸识别系统时,需要注意以下几个方面:
数据集的选择与准备:选择合适的人脸数据集是训练SVM分类器的关键。需要确保数据集具有足够的样本数量和多样性,以覆盖各种光照、姿态和表情变化。同时,还需要对数据集进行预处理和标注,以便于后续的特征提取和分类器训练。
特征提取方法的选择:特征提取方法的选择对人脸识别系统的性能具有重要影响。需要根据实际需求选择合适的特征提取方法,并在实践中不断优化和改进。
SVM参数的优化:SVM的参数对分类器的性能具有重要影响。需要通过实验确定最优的参数组合,以提高分类器的分类精度和泛化能力。
模型的评估与改进:在实现人脸识别系统后,需要对模型进行评估,并根据评估结果进行改进和优化。常用的评估指标包括准确率、召回率、F1分数等。同时,还可以采用集成学习、深度学习等方法对SVM模型进行改进,以提高其性能。
5、总结与展望
基于SVM支持向量机的人脸识别系统具有出色的分类性能和泛化能力,在人脸识别领域具有广泛的应用前景。在未来,随着计算机技术的不断发展和数据量的不断增加,基于SVM的人脸识别系统将面临更多的挑战和机遇。需要不断探索新的特征提取方法、优化SVM参数和模型评估方法,以提高人脸识别系统的性能和稳定性。同时,还需要关注人脸识别技术的伦理和法律问题,确保技术的合法性和安全性。
整体流程及部分源码解析
本项目使用支持向量机实现人脸的分类识别,主要流程是对输入的人脸数据,使用主成分分析(PCA)方法进行降维处理,然后利用降维后的数据作为人脸特征,输入到SVM中,进行人脸的分类识别。主要分为以下几个关键步骤
1、获取数据集
# 获取人脸数据
faces = fetch_lfw_people(min_faces_per_person=60)

2、数据集划分
# 将数据集划分为训练集和测试集
xtrain, xtest, ytrain, ytest = train_test_split(faces.data, faces.target,
random_state=2)
3、使用PCA进行特征提取
# 对PCA进行训练
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True, random_state=42).fit(xtrain)
4、使用线性SVM进行预测
# 实例化SVM
svc = SVC(kernel='linear',C=10)
SVC(C=10, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=‘ovr’, degree=3, gamma=‘auto_deprecated’,
kernel=‘linear’, max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
效果评估
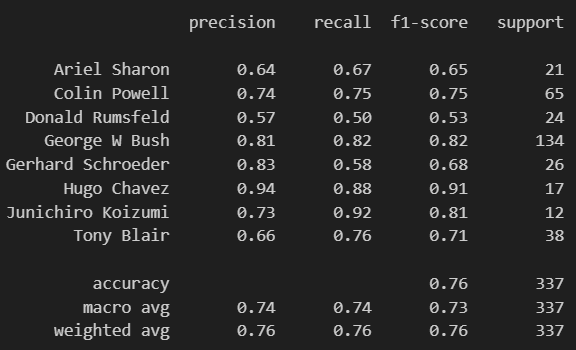
5、交叉验证进行优化
通过交叉验证的方法寻找最佳的kernel及相关参数,进行超参数调参
# 参数列表
param_grid = [
{'kernel': ['linear'], 'C': [1, 5, 10, 50]},
{'kernel': ['rbf'], 'C': [1, 5, 10, 50], 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1]},
{'kernel': ['poly'], 'C': [1, 5, 10, 50], 'degree':[2,3,4], 'gamma': ['auto']}
]
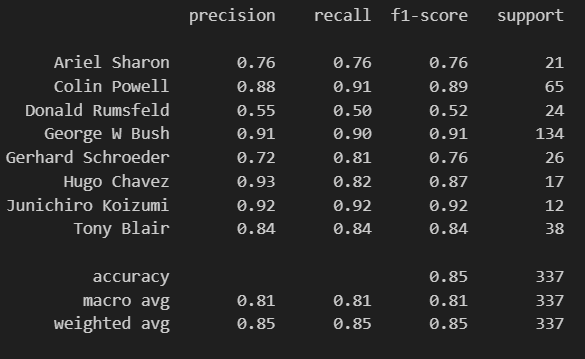
6、使用最好的超参预测
7、可视化展示

8、评估及分析
混淆矩阵
# 利用预测结果和真实结果绘制混淆矩阵
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');
项目备注
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
如有其他毕设方面的需求、咨询,也可联系博主
完整源码资源下载地址
点此下载完整源码
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











