







 本文介绍了如何将网页爬取的HTML数据转换为Markdown格式,进一步处理为Jsonl格式,同时剔除内容中的链接和跳转信息。通过使用html2text库、Markdown处理和正则表达式实现这一过程。
本文介绍了如何将网页爬取的HTML数据转换为Markdown格式,进一步处理为Jsonl格式,同时剔除内容中的链接和跳转信息。通过使用html2text库、Markdown处理和正则表达式实现这一过程。
任务需求
将已切分好的网页爬取数据(包含标题和HTML格式的网页内容)转为Jsonl格式,其中内容转为MarkDown格式。同时剔除内容中的跳转、链接、引用等。

解决步骤
HTML->MarkDown+MarkDown->Json+Json->Jsonl
1、HTML转MarkDown
使用html2text库,convert_to_markdown(file_path)函数输入原始数据文件地址,返回一个数组。
def convert_to_markdown(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
markdown = ""
for i in range(0, len(lines), 3):
title = lines[i].strip()
html_content = lines[i + 1].strip()
if html_content.startswith('@@@LINK='):
continue
markdown_content1 = html2text.html2text(html_content)
markdown += f"title is {title}\n\n"
markdown += f"{markdown_content1}\n\n"
return markdown写入文件函数,读入markdown_c数组和输出文件,将数组内容写入文件
def save_as_text_file(markdown_c, file_path): #写入文件函数
with open(file_path, 'w', encoding='utf-8') as file:
file.write(markdown_c)

2、转JSON
使用Json库,输入文件,返回Json格式的内容
def convert_to_json(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
result = []
title = None
html_content = ""
for line in lines:
line = line.strip()
if not title:
title = line
elif line == '</>':
if not html_content.startswith('@@@LINK='):
json_content = html2text.html2text(html_content)
entry = {
"title": title,
"content": json_content
}
result.append(entry)
title = line = ""
html_content = ""
else:
html_content += line + '\n'
# 处理最后一个网页内容
if html_content:
if not html_content.startswith('@@@LINK='):
json_content = html2text.html2text(html_content)
entry = {
"title": title,
"content": json_content
}
result.append(entry)
return json.dumps(result, ensure_ascii=False)3、Json转Jsonl
直接使用逐行输出的方法即可
def save_json_to_file(json_result, output_file_path):
with open(output_file_path, 'w', encoding='utf-8') as output_file:
# 遍历结果列表,逐行将内容写入文件
for entry in json.loads(json_result):
output_file.write(json.dumps(entry, ensure_ascii=False) + '\n')4、去除链接等
使用re库,利用正则表达式去除
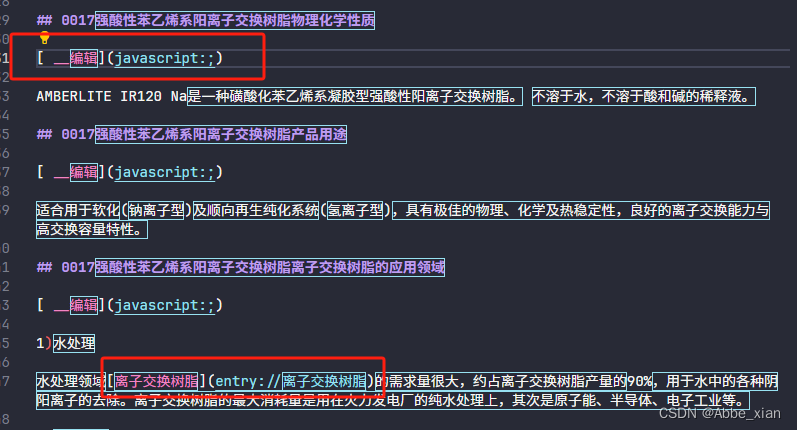
def process_document(file_path): #处理输出文档
with open(file_path, 'r', encoding='utf-8') as file:
document = file.read()
# 移除类似于(entry://编程)和(entry://安格斯)的跳转内容
document = re.sub(r'\(entry://[^\)]+\)', '', document)
# 移除类似于[ __锁定](/view/10812319.htm "锁定")和[ __讨论](../planet/talk@lemmaId=3276377)的内容
document = re.sub(r'\[.*?\]\([^)]+\)', '', document)
# 将处理后的文档内容写回到文件中
with open(file_path, 'w', encoding='utf-8') as file:
file.write(document)完整代码
记得pip install 那几个库,注意内存溢出的问题
import html2text
import json
import re
def convert_to_json(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
result = []
title = None
html_content = ""
for line in lines:
line = line.strip()
if not title:
title = line
elif line == '</>':
if not html_content.startswith('@@@LINK='):
json_content = html2text.html2text(html_content)
entry = {
"title": title,
"content": json_content
}
result.append(entry)
title = line = ""
html_content = ""
else:
html_content += line + '\n'
# 处理最后一个网页内容
if html_content:
if not html_content.startswith('@@@LINK='):
json_content = html2text.html2text(html_content)
entry = {
"title": title,
"content": json_content
}
result.append(entry)
return json.dumps(result, ensure_ascii=False)
def save_json_to_file(json_result, output_file_path):
with open(output_file_path, 'w', encoding='utf-8') as output_file:
# 遍历结果列表,逐行将内容写入文件
for entry in json.loads(json_result):
output_file.write(json.dumps(entry, ensure_ascii=False) + '\n')
def process_document(file_path): #处理输出文档
with open(file_path, 'r', encoding='utf-8') as file:
document = file.read()
# 移除类似于(entry://编程)和(entry://安格斯)的跳转内容
document = re.sub(r'\(entry://[^\)]+\)', '', document)
# 移除类似于[ __锁定](/view/10812319.htm "锁定")和[ __讨论](../planet/talk@lemmaId=3276377)的内容
document = re.sub(r'\[.*?\]\([^)]+\)', '', document)
# 将处理后的文档内容写回到文件中
with open(file_path, 'w', encoding='utf-8') as file:
file.write(document)
if __name__ == '__main__':
file_path = 'E:\Deskbook/file_tf/test.txt' # 输入测试文件
json_content = convert_to_json(file_path)
file_jsonpath = 'E:\Deskbook/file_tf/output_json.txt' # json输出文件路径
save_json_to_file(json_content, file_jsonpath)
process_document(file_jsonpath)

心得
无无无无无无无无无无无无无无无无无无















 6488
6488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









