







前言
GPT-SoVITS是花儿不哭
大佬研发的低成本AI音色克隆软件
只要有足够的音频素材加上合理的参数调控,就能让你克隆出你想要的语音模型,配合上推理tts,就能合成出你喜欢的角色的声音(请在法律允许的范围内使用)
同样的,只要是AI相关的项目,对电脑配置的要求都不低
小b也没啥实力,本项目也是勉强能跑,以下配置仅供参考
Windows 11 家庭中文版
CPU:12th Gen Intel(R) Core(TM) i7-12700H 2.30 GHz
GPU:NVIDIA GeForce RTX 3060 Laptop
内存:16(无所谓杂牌)
硬盘:无所谓杂牌(只要存储空间够就行)
你显卡的显存越高,能调控的参数和训练轮数越大,训练出来的模型效果会更好
如果你是第一次使用,很多步骤使用时会进行初始化,如果没有爆出错误,耐心等待即可
部署GPT-SoVITS整合包
下载地址
百度网盘下载
提取码:mqpi
UC网盘下载
直连下载(推荐)
GPT-SoVITS(点击下载)
下载好并解压后进入GPT-SoVITS主文件目录
找到go-webui.bat文件双击
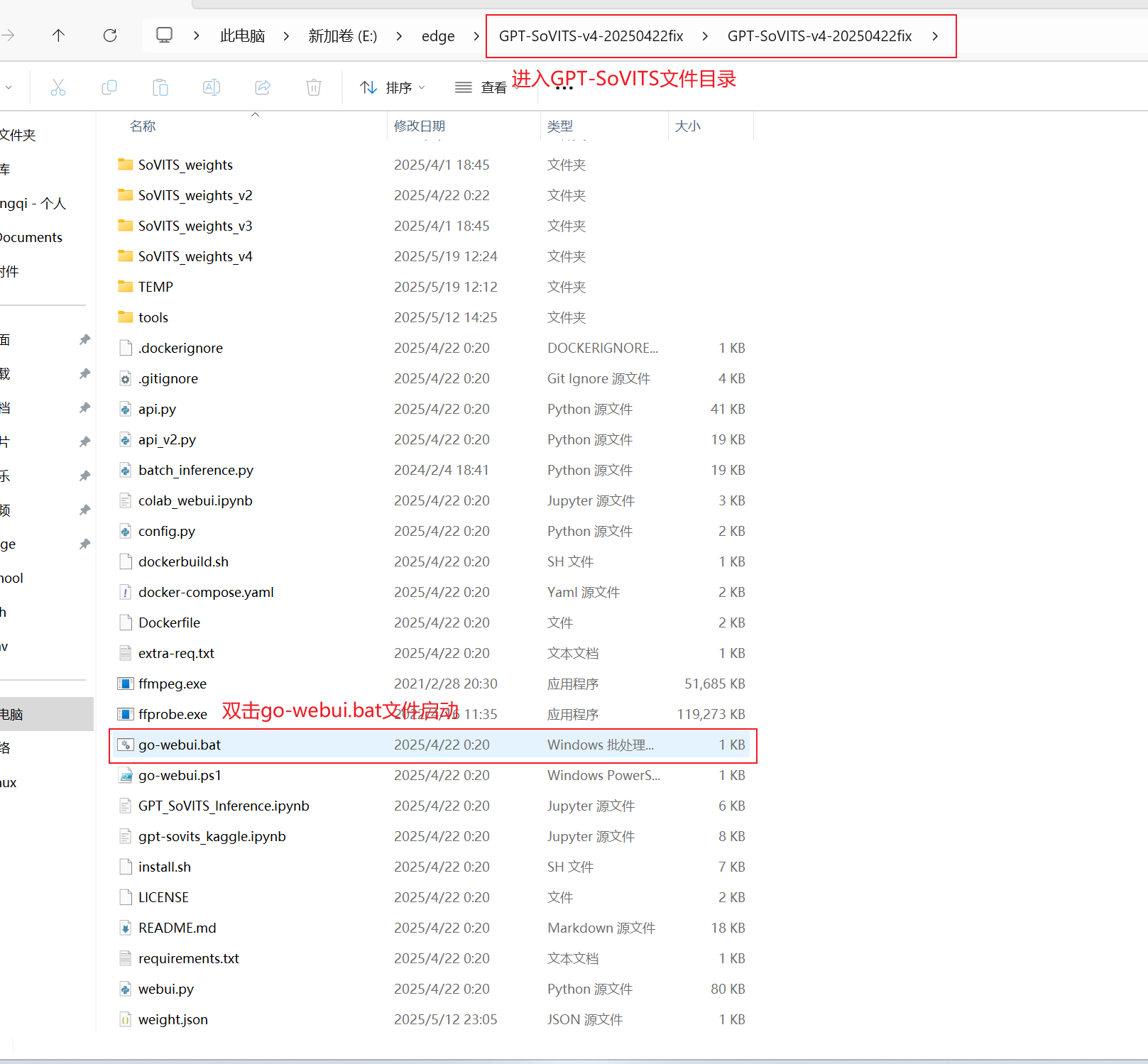
此时会跳出命令行界面,稍作等待即可
![]()
等待一会后,会自动跳转到游览器webui界面,如果没有跳转就在游览器输入http://localhost:9874即可
进入到webui界面即为部署成功
数据收集数据处理
数据收集
你想要训练出哪个角色的语音模型,就去找谁的语料
我非常喜欢 饿殍:明末千里行 里面的满穗,所以本次训练会以游戏里的满穗的游戏语音进行训练
你知道的,我一直都是很喜欢满穗的
训练出来的模型我会放在我的github上的开源仓库,见文章末尾(仅供学习交流)
本教程不包含gal的解包教程,有需要的自行寻找学习
这些就是我的语音素材
切记:音频文件一定要是wav格式的!!!

数据处理
我们收集到的数据不一定是纯粹的语音(gal除外),需要进一步的提取人声,例如去除伴奏,去除混响(可以理解为回音)
回到我们的GPT-SoVITS的webui界面
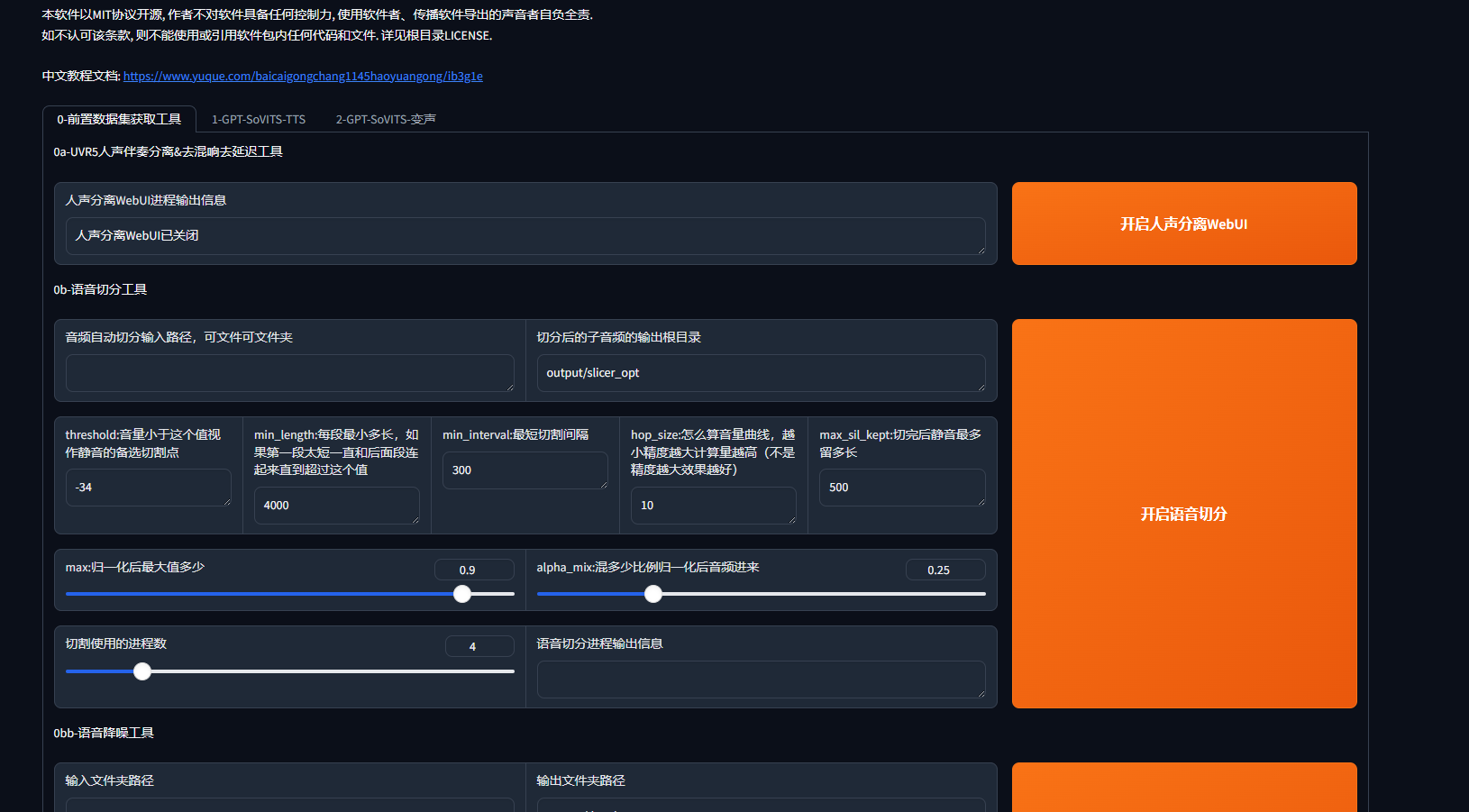
第一步:人声提取webui界面
开启人声分离webui
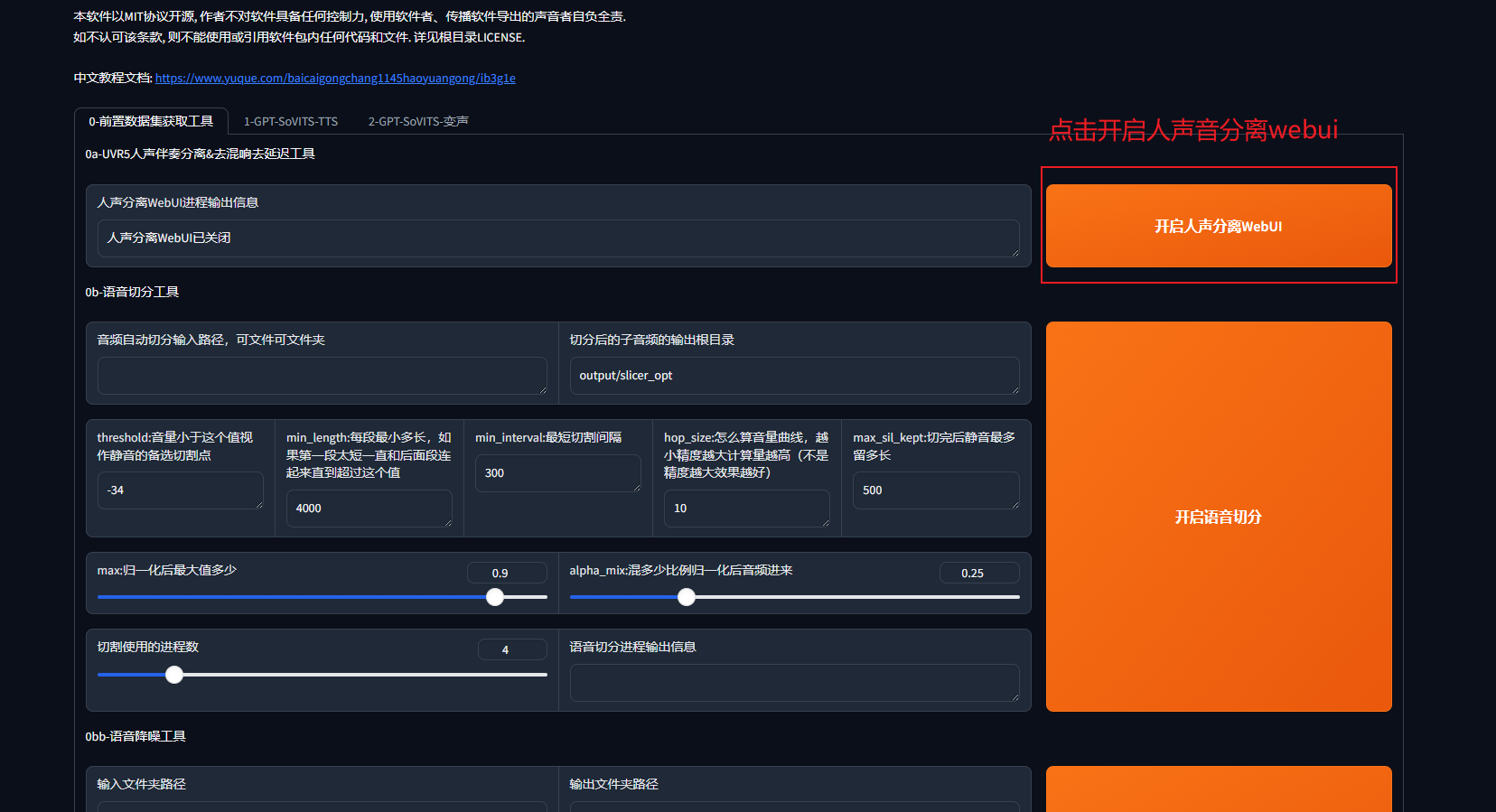
GPT-SoVITS自带webui的UVR5,我们启动人声分离webui后,游览器就会自动跳转至UVR5的webui,如果没有跳转就在游览器输入http://localhost:9873/ 进行访问即可
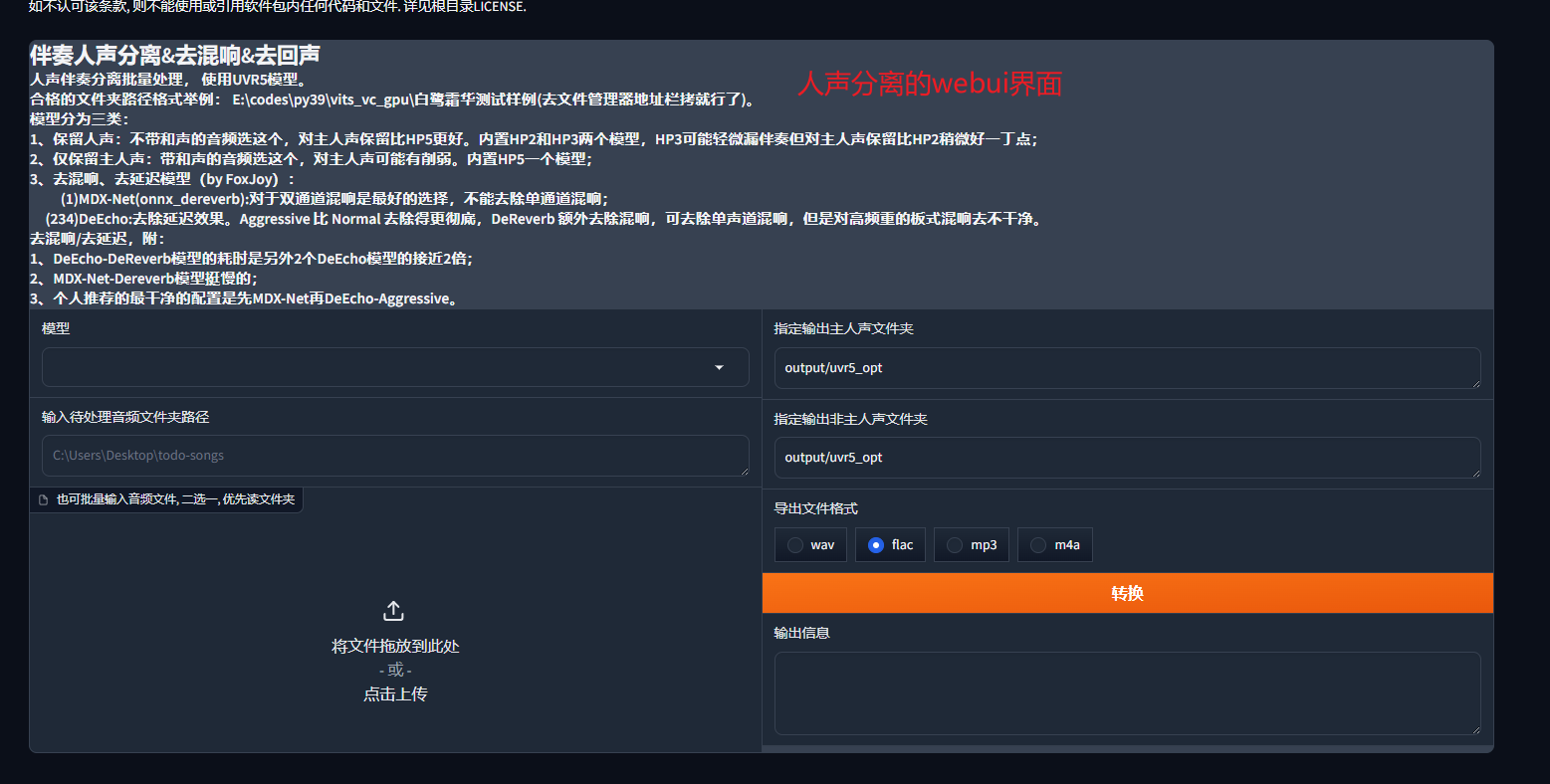
注意:本项目有各种webui界面,还有一个webui界面下有许多子路径,希望各位不要绕晕了
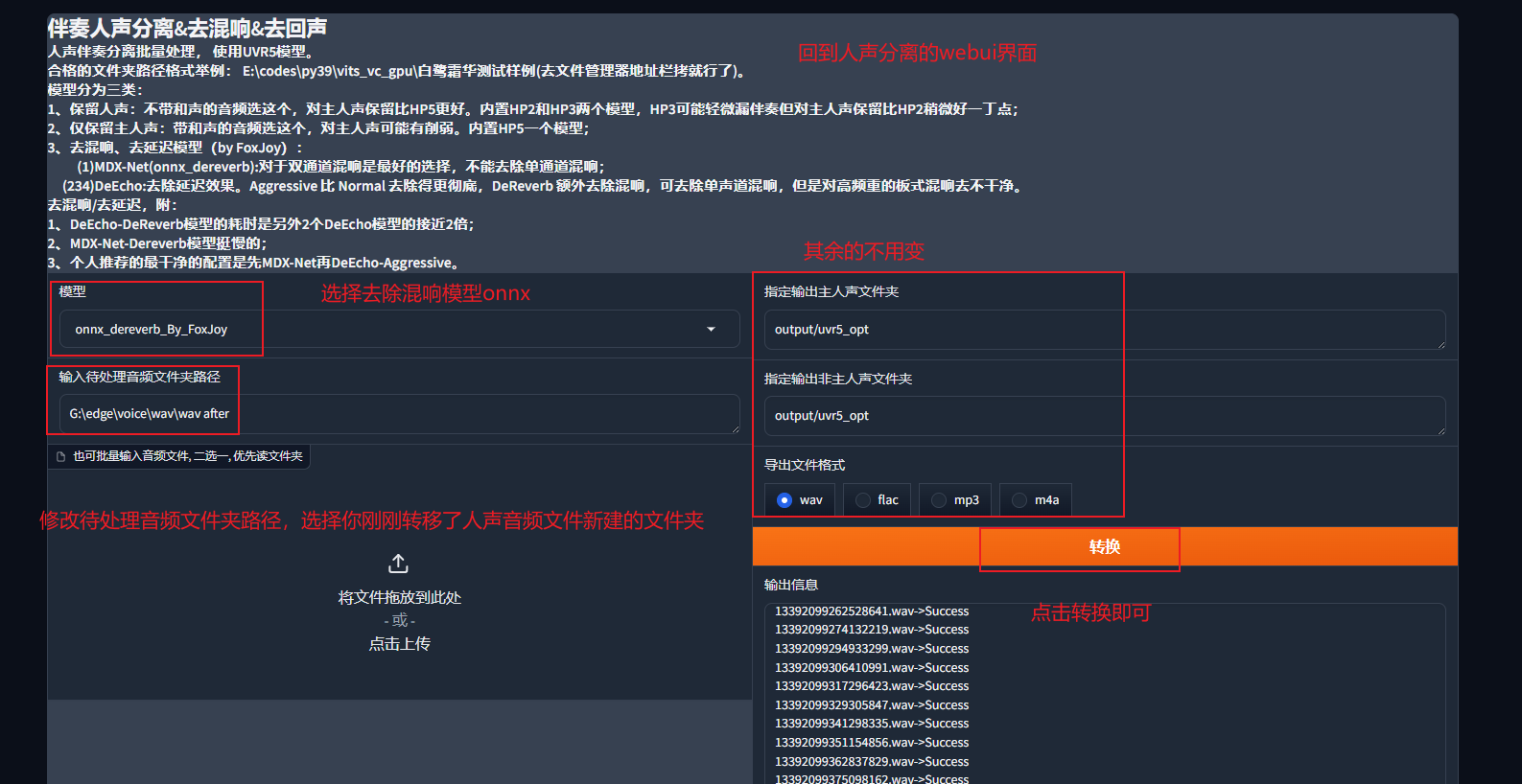
输入待处理音频文件夹路径
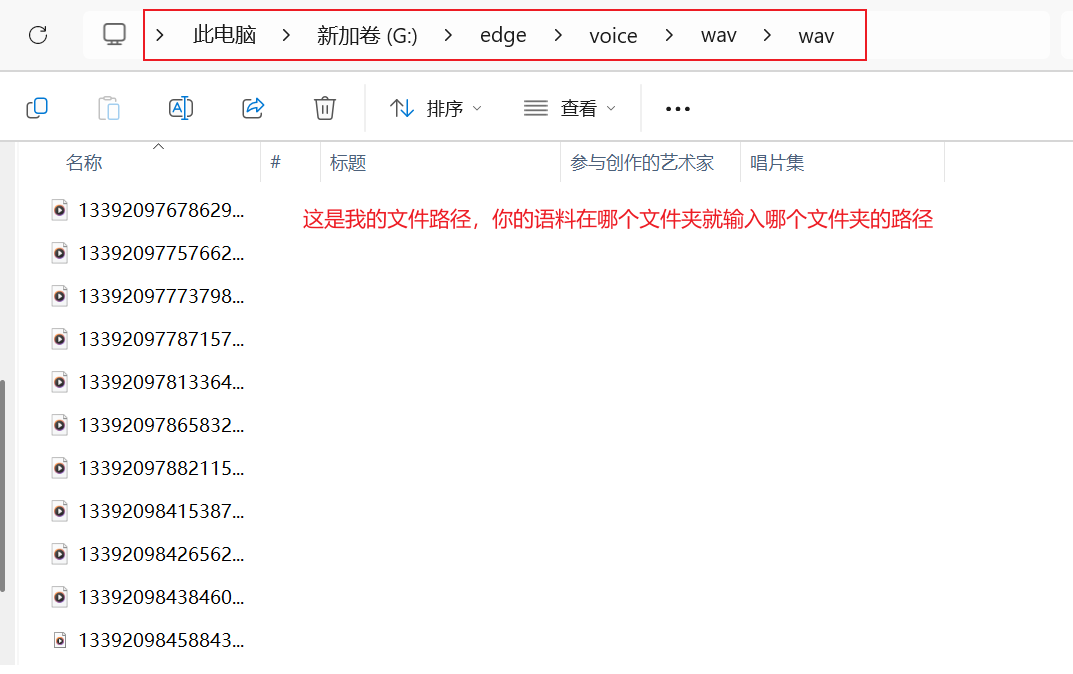
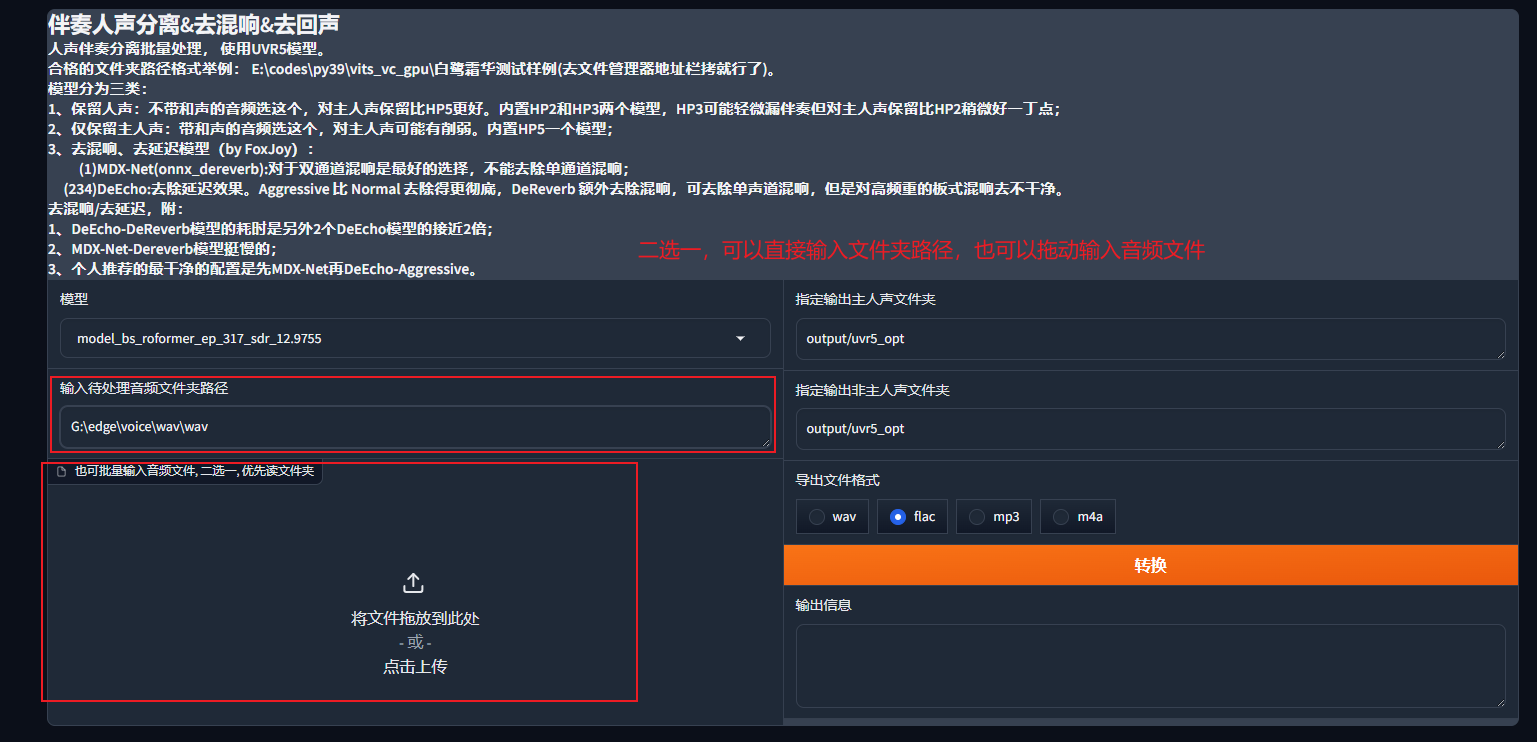
指定输出文件夹
如果没有特殊要求,推荐不要改变
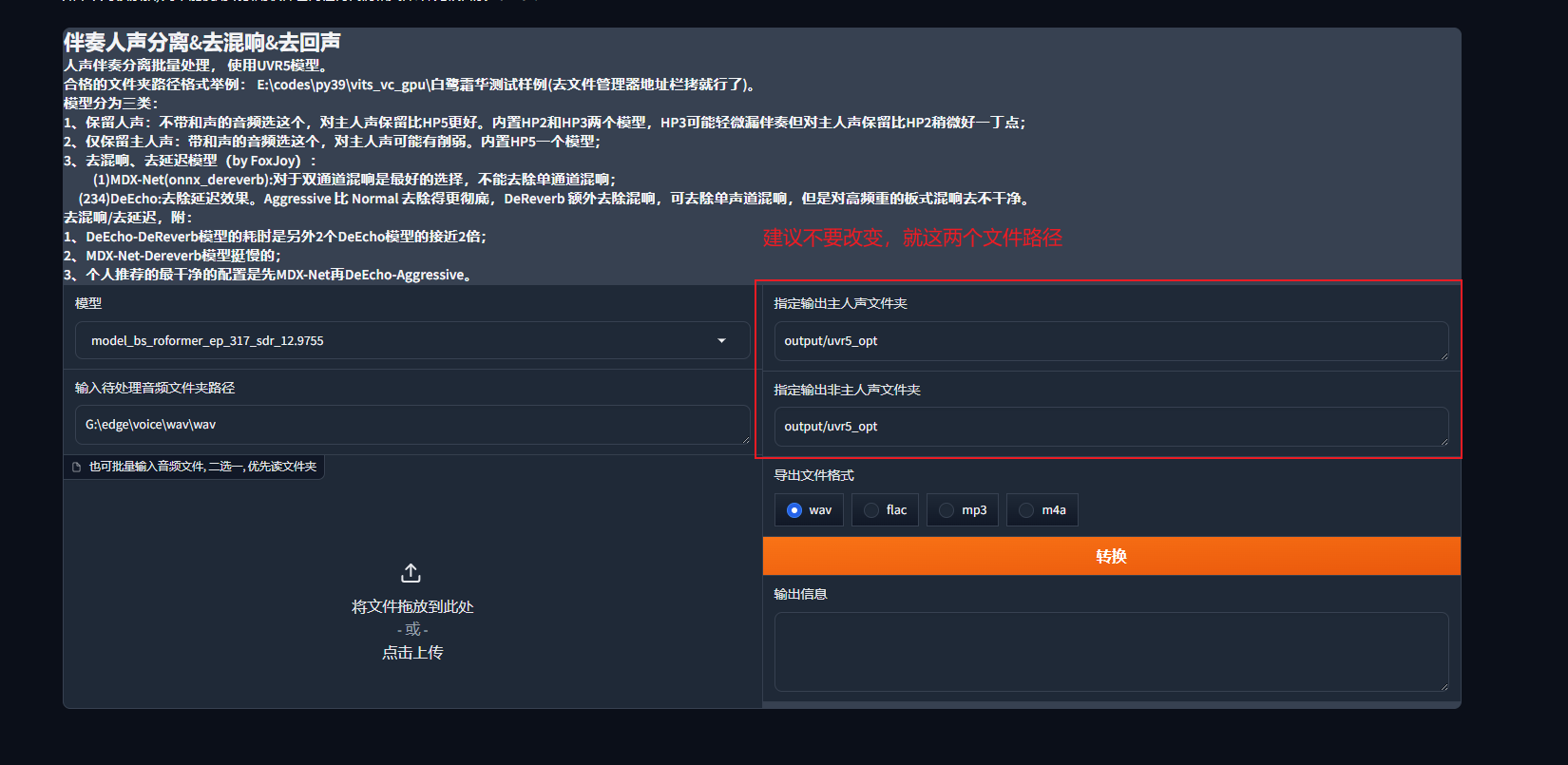
这两个文件就在GPT-SoVITS的主文件夹路径下
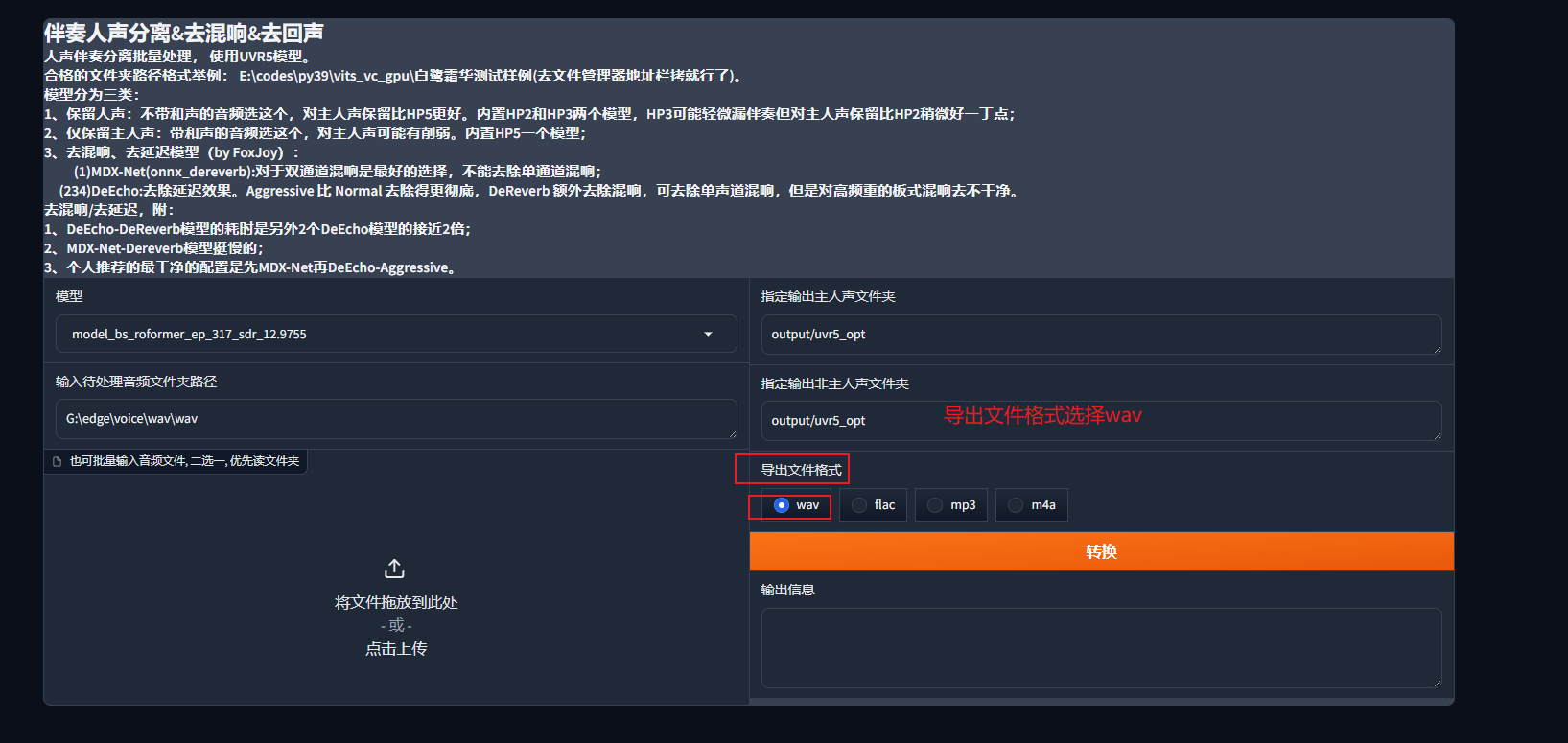
导出文件格式
导出文件格式一定要用wav!!!
模型提纯
我们要过三遍模型,分别是提取人(去除伴奏),去除混响,去除第二次混响
第一遍:提取人声,选择模型model_bs_roformer_ep_317_sdr_12.9755
model_bs_roformer_ep_317_sdr_12.9755模型的用途是提取人声,我们的音频中可能会混有bgm,杂音等等,我们需要用这个模型来提取我们需要的纯粹的人声
当然你的素材越纯净越好,这些模型也只是辅助手段
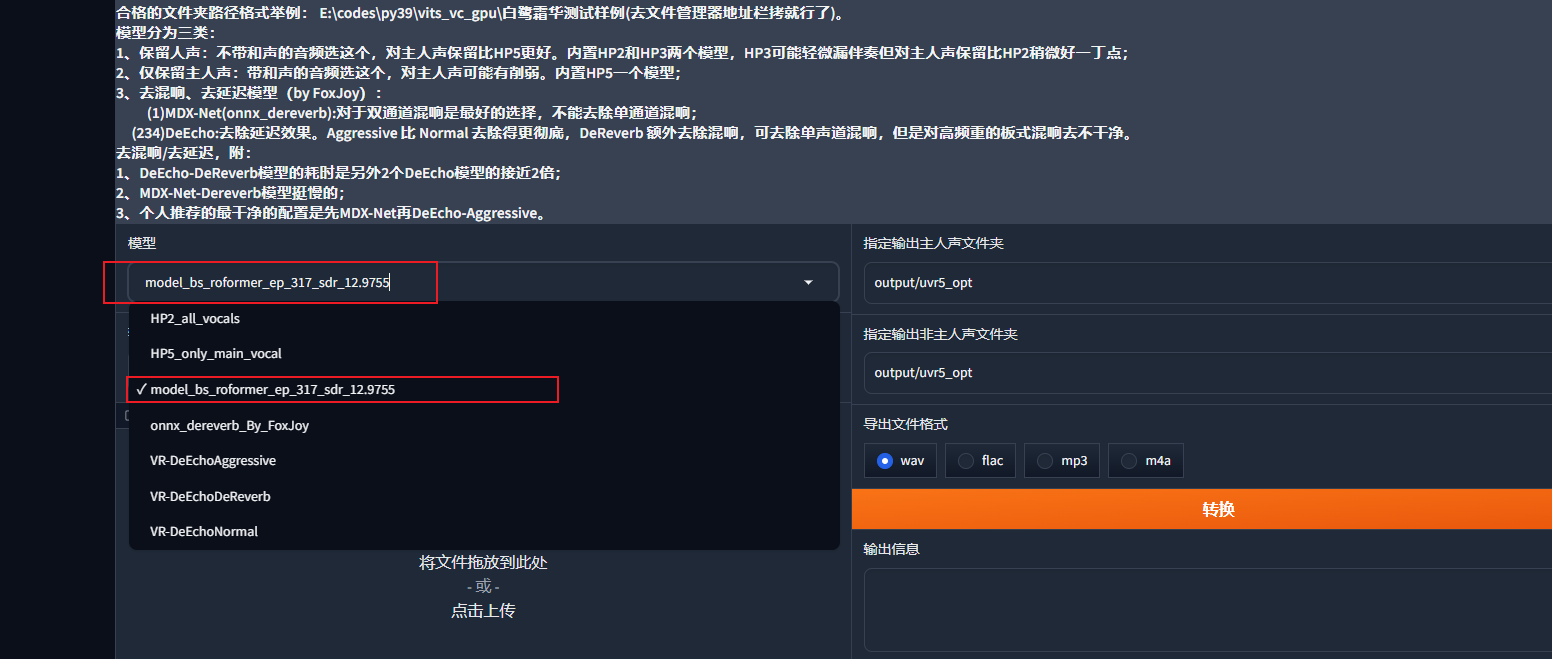
然后点击转换,即开始提纯人声
完整图一览
开始后可以在控制台查看运行状态(就是打开GPT-SoVITS的运行台)
也可以在webui界面查看
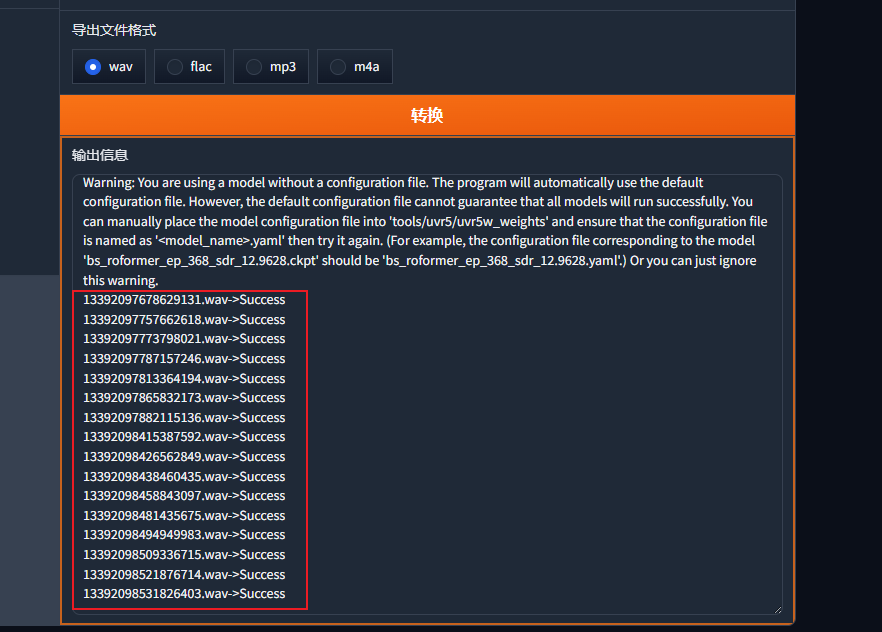
第一遍提取人声结束后
进入输出目录,会看到两种文件
一种文件名会带_other,是分离出来的伴奏音乐或者杂音
另一种文件名会带_vocals,是分离出来的纯人声,是我们要的
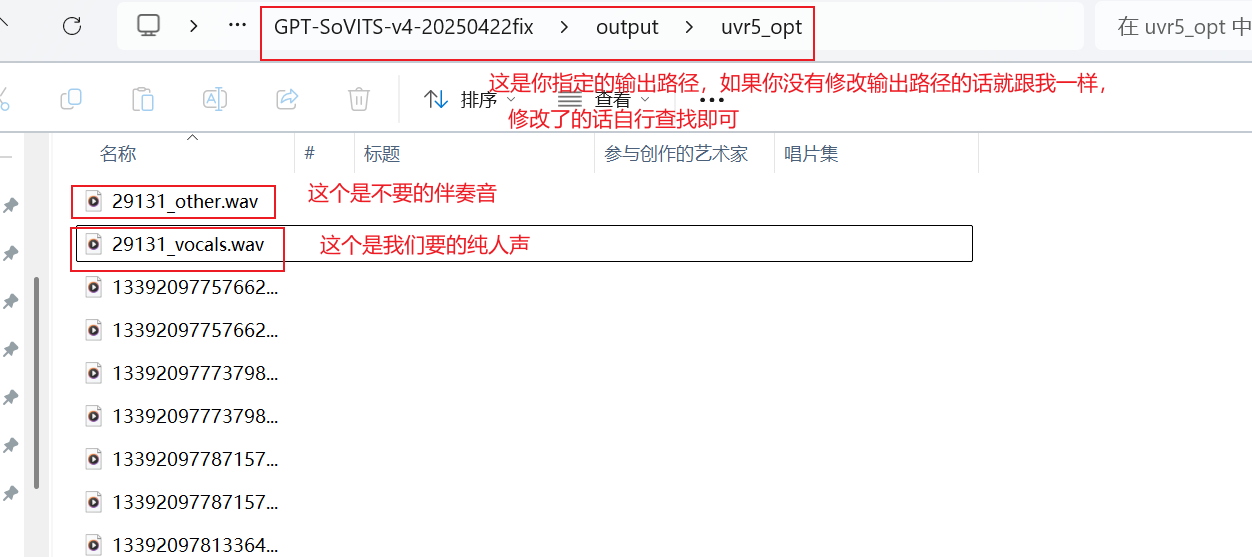

把所有带_other的音频素材全部删掉,然后将剩余的纯人声转移至新建的音频文件夹(千万别删错了)
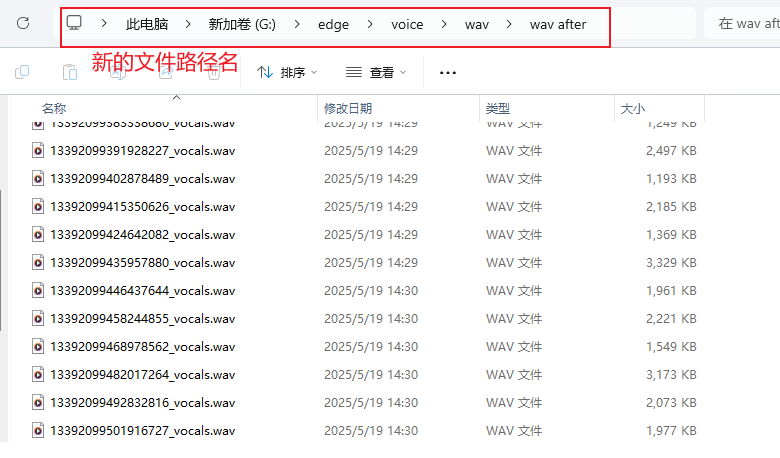
第二遍:去除混响,选择模型onnx_dereverb_By_FoxJoy
混响可以理解为录音时的回音,也可以理解成降噪,去除混响后的音频文件会是更加纯净的人声,有助于模型训练学习
同样的我们稍作等待即可

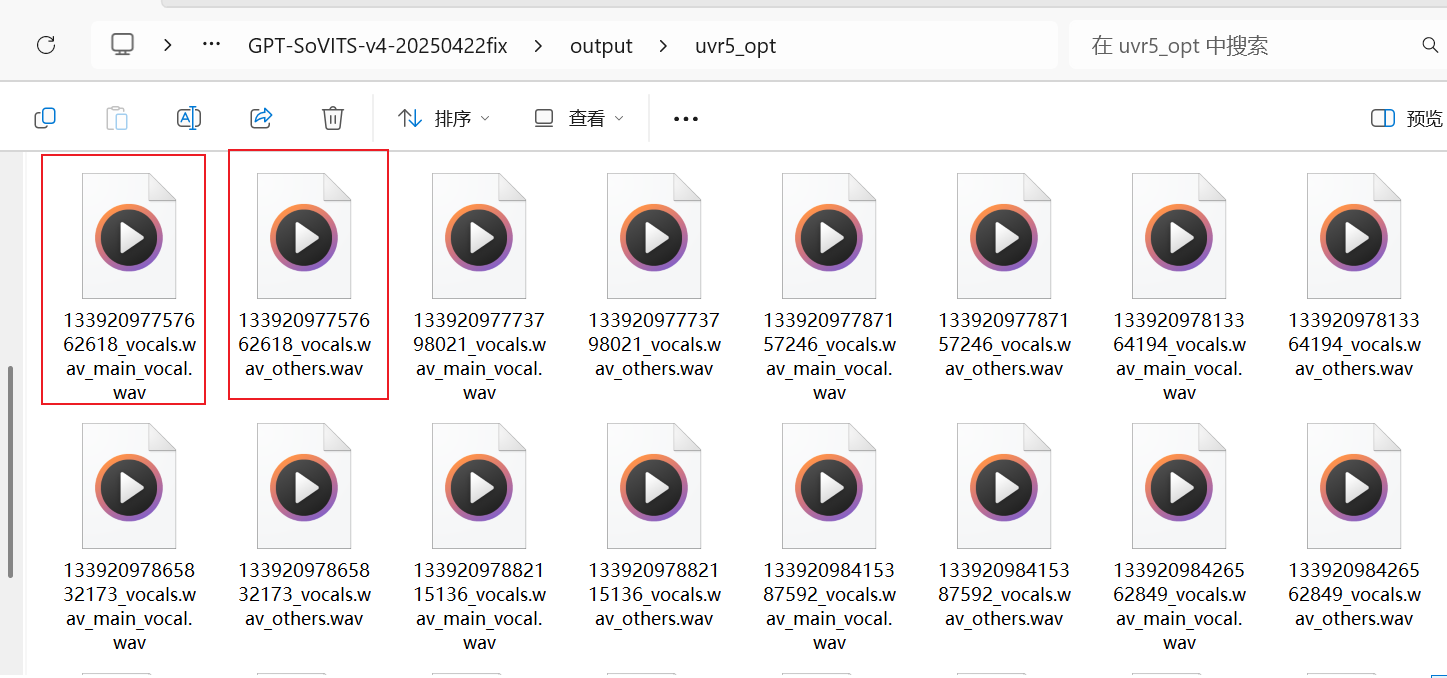
完成后,我们进入输出文件夹
可以看到带有_main名字的文件名和_other的文件名
同样的,把带_other的文件全部删掉,那是不需要的混响音
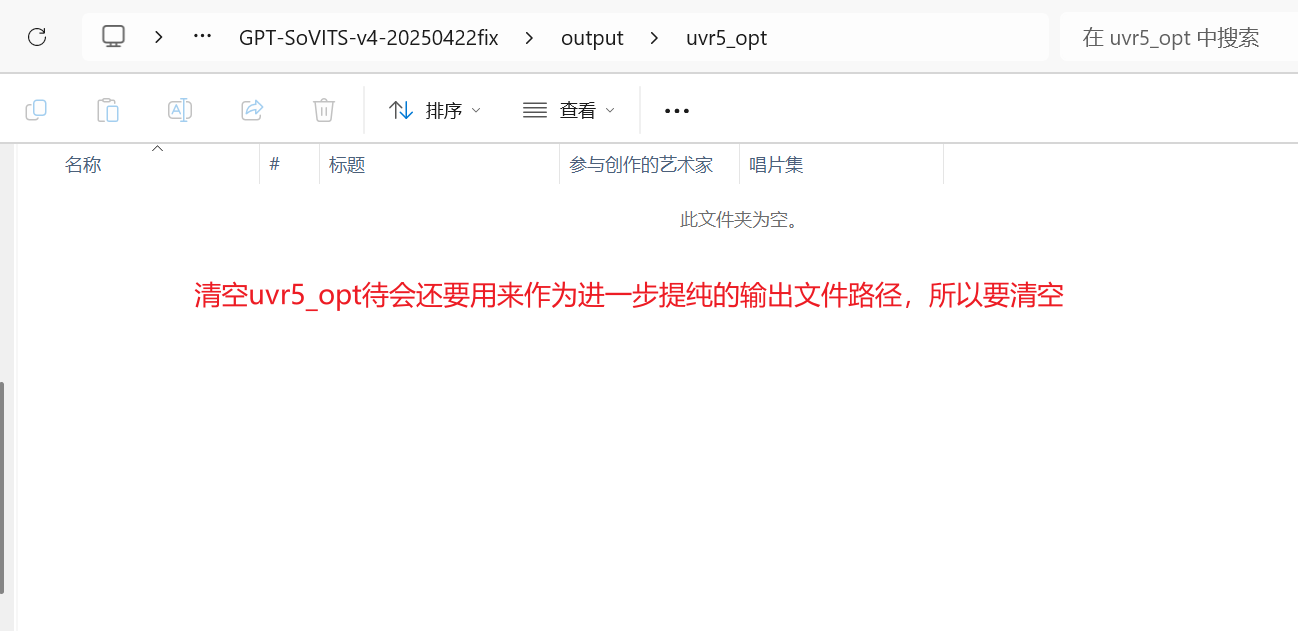
然后再建一个新的文件夹,将uvr5_opt文件夹下剩余的音频文件全部移过去,为第三次提纯做准备
第三遍:去除混响,选择模型VR-DeEchoAggressive
操作都大差不差,这是第三次提纯,同样是去除混响
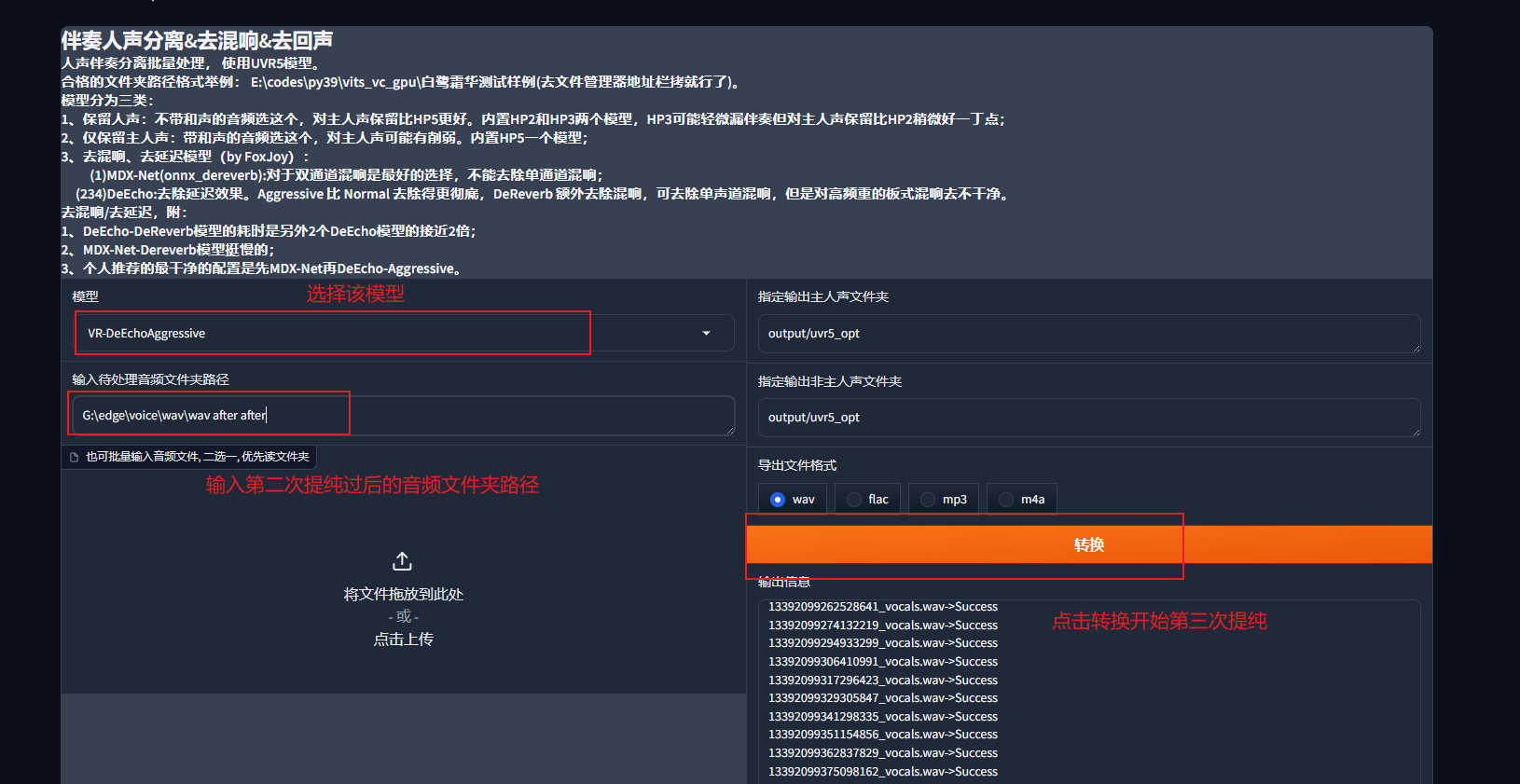
继续等待完成即可
完成后,会有文件名带有instrument_的音频文件,还有vocal_的音频文件
instrument_的音频文件为提纯后的杂音,删除即可
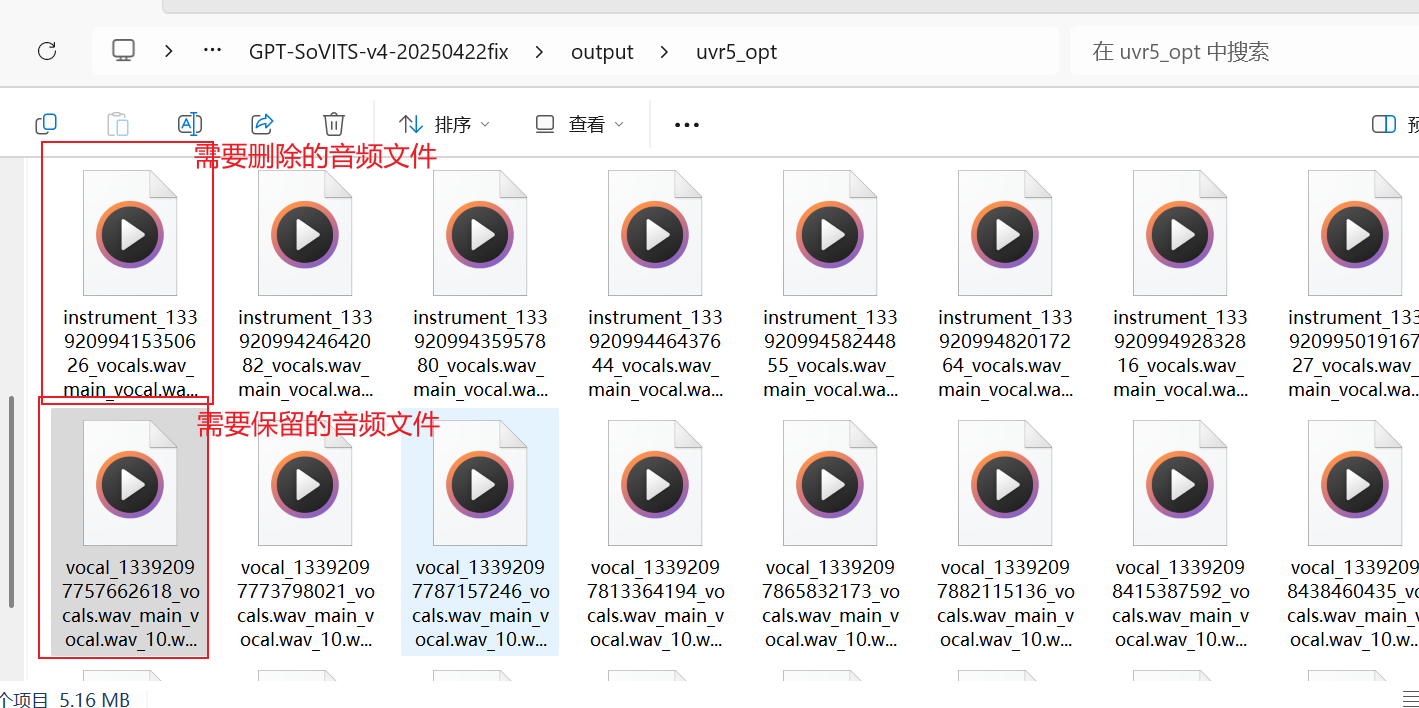
然后全部转移到新文件夹
到这一步我们的人声提取就完成了,我们得到了去除杂音和混响的干人声
可以关闭人声分离webui了,防止自己搞不清工具界面和节省显存
第二步:语音切分
首先先要理解为什么要切割音频
-
显存限制:TTS模型通常以固定长度的音频片段为输入,长音频直接训练会导致显存溢出(OOM)。切割后,每段音频长度适配模型输入(例如3~10秒)
-
数据标准化:避免一句话包含过多静音或杂音,提升训练效率和质量。便于文本与音频的严格对齐(强制对齐工具对短句效果更好)
-
音量均衡:切割前统一音量(如-9dB到-6dB)可防止部分片段过响或过轻,影响声学模型稳定性
一段完美的音频应该是没有任何噪音杂音混响等,音量统一在-9dB到-6dB之间
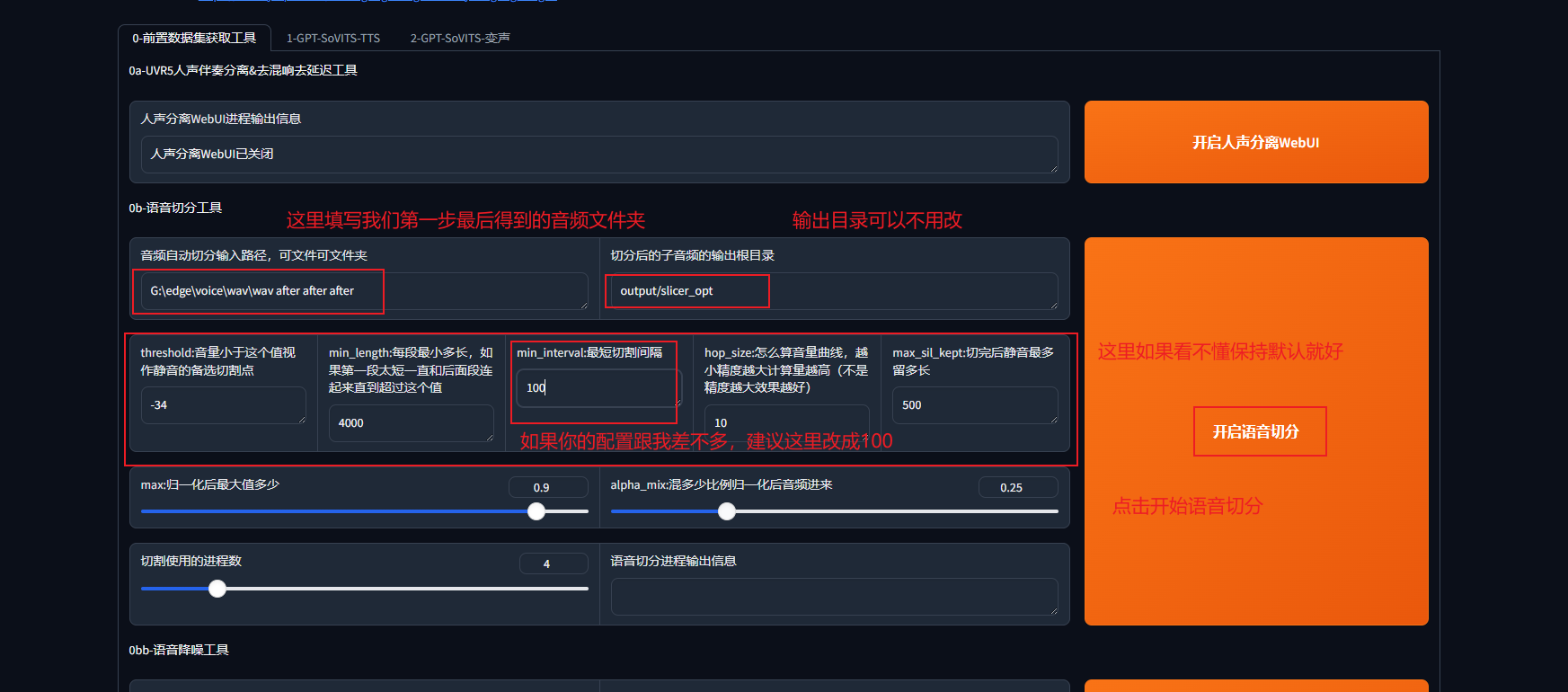
点击开始语音切分
完成后进入输出路径进行查看
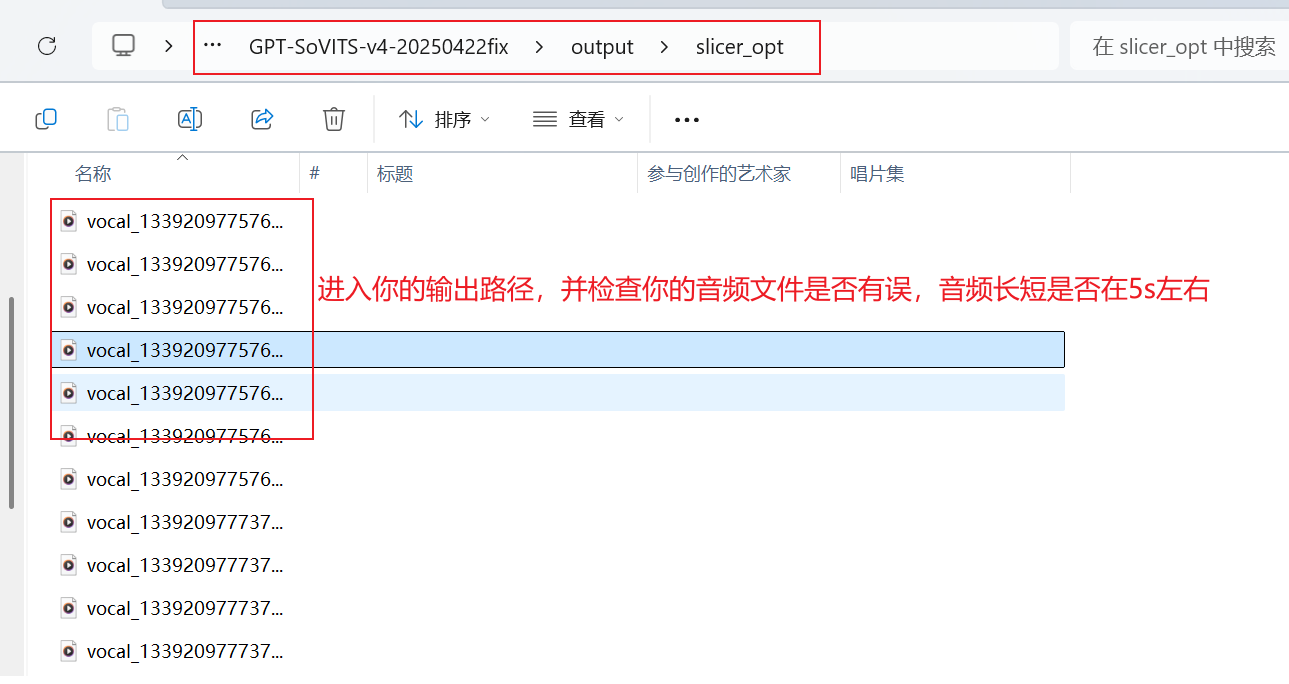
音频文件音质正常,长度在5s左右,则语音切分完毕
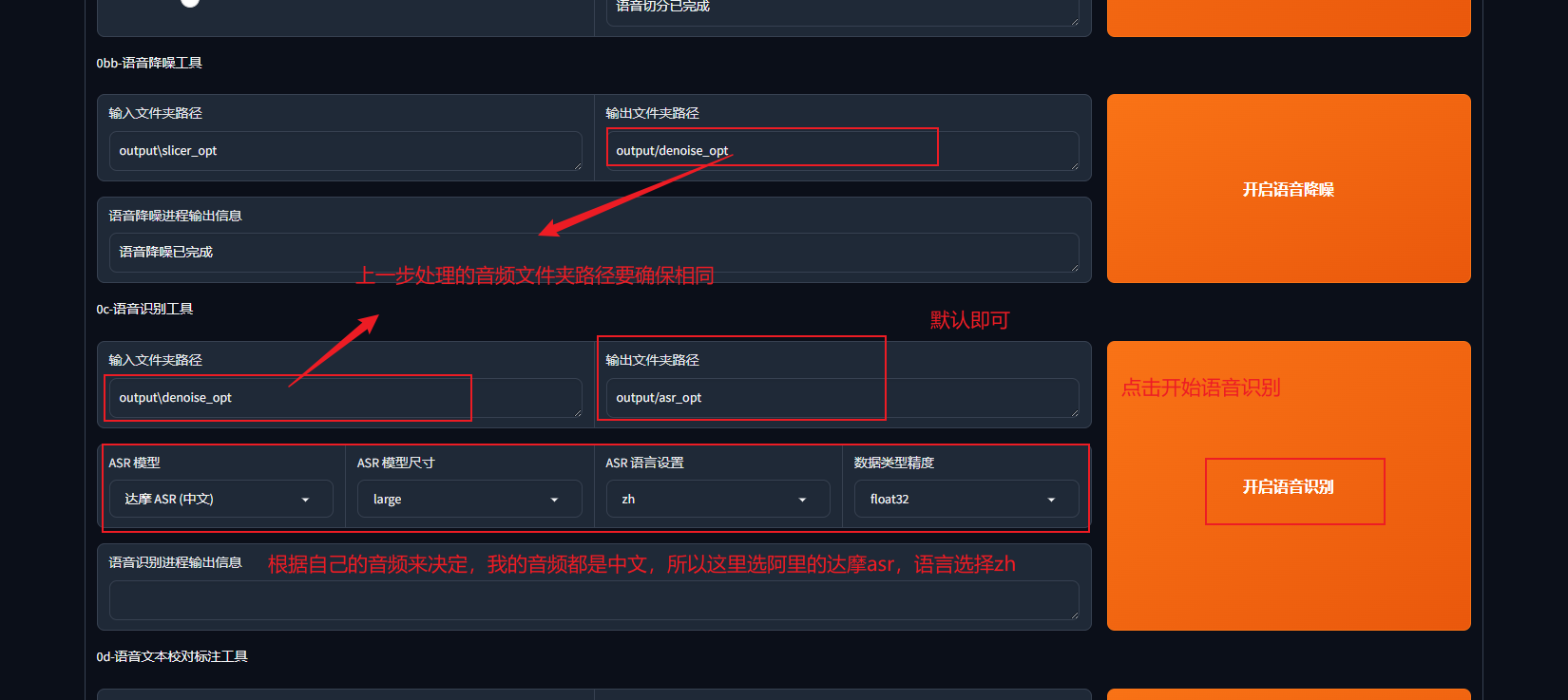
第三步:语音降噪
这一步同样是为了提纯你的音频素材,如果你的音频素材非常赶紧,例如录音麦的干声,或者gal解包出来的wav原文件可以省略这一步骤,但如果不放心则点击语音降噪
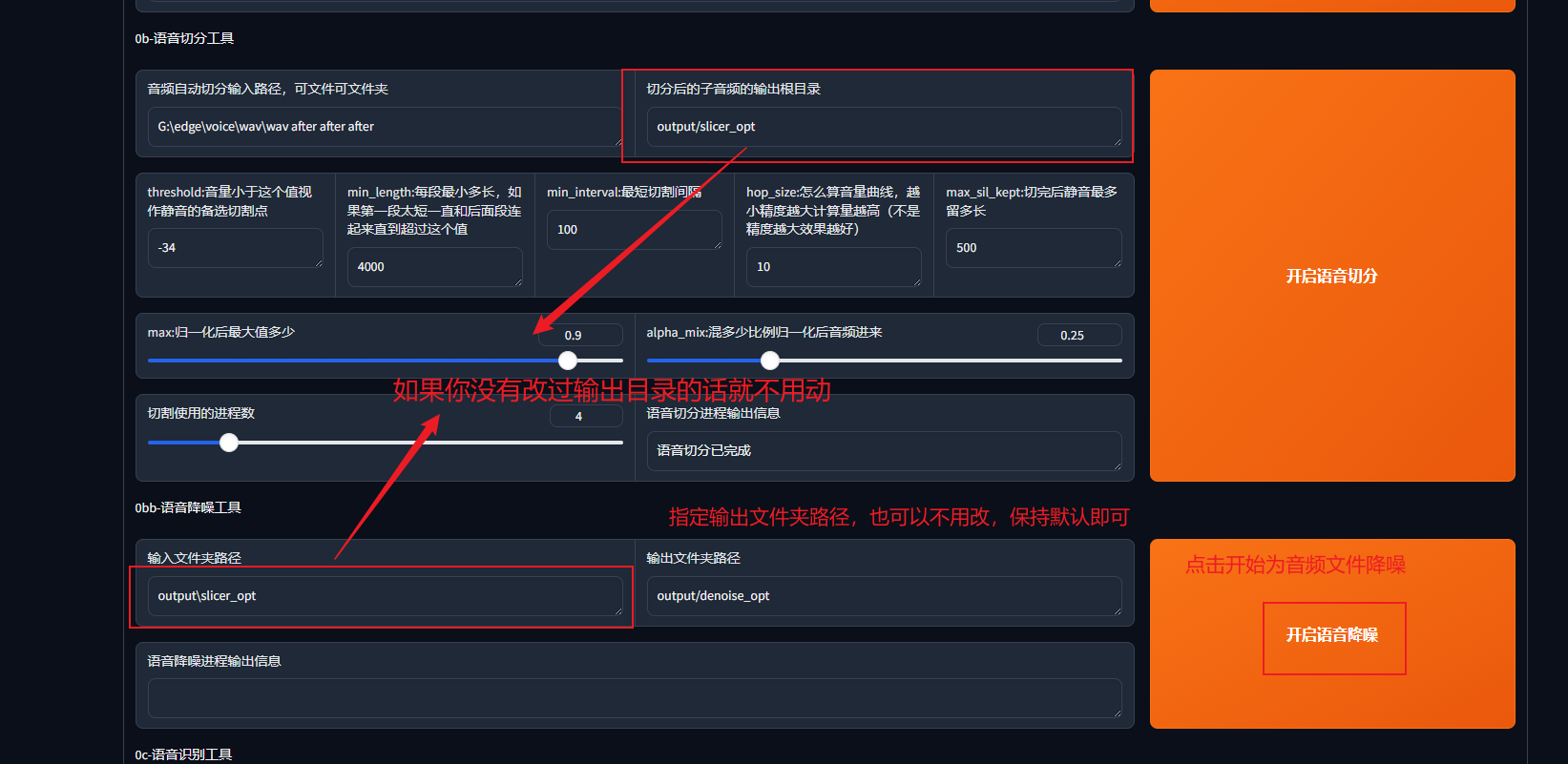
检查音频文件
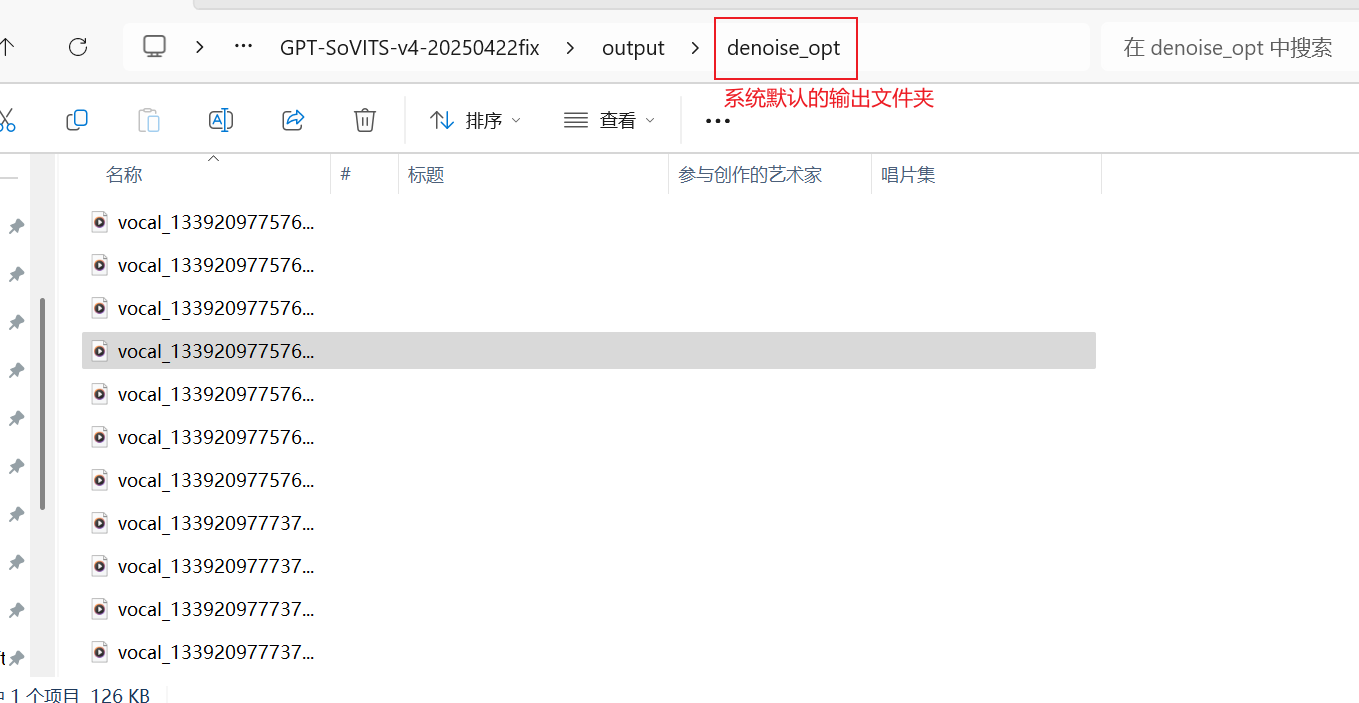
至此语音降噪完毕
第四步:语音识别
这一步也可以成为ai标注
为什么要做标注,因为训练的时候是根据你的音频文件还有你的文本文件来进行训练的
相当于你需要叫模型,这一个字是这样读的(然后给出你的文本和音频)
这个语音识别只是一个辅助工具,帮你大概的识别出人物所讲出的句子
你文本的句子准确度越高,训练出来的模型质量也会越好
检查语音识别后的文件
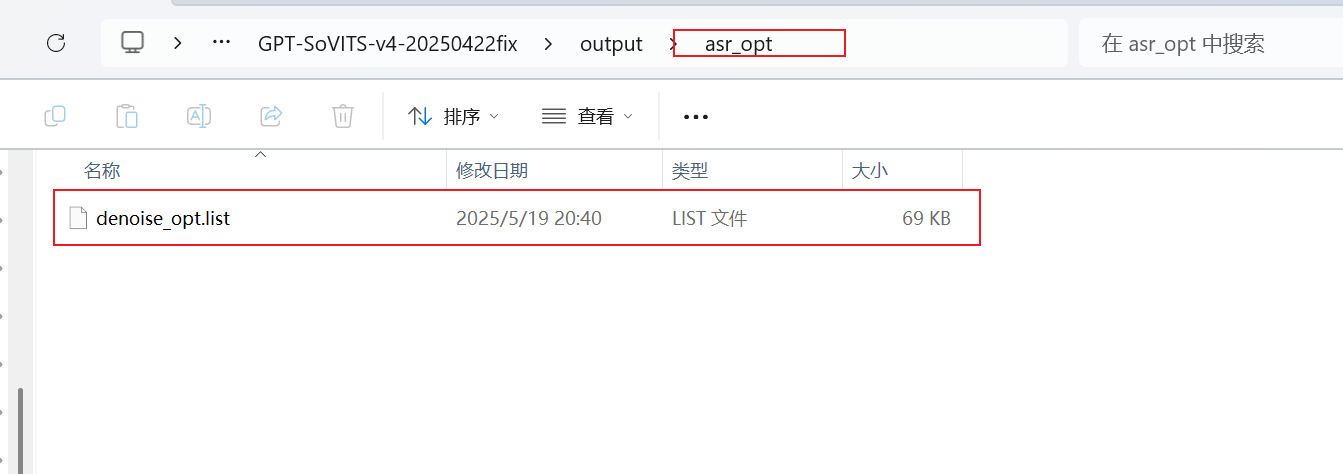
到这一步,我们就有了ai出来的文本和处理好的音频素材了
最后一步:音频标注
上一步语音识别只是一个大概,是ai出来的文本,还需要手动来校准

稍作等待后,就会出现新的音频标注webui界面,会自动跳转游览器,如果没有跳转,在游览器中输入http://localhost:9871/即可
这一步就是在教模型这个字要怎么念的其中一个过程
每校对完一页就点击submit text提交文本,否则你翻到下一页的话,文本是不会保存的
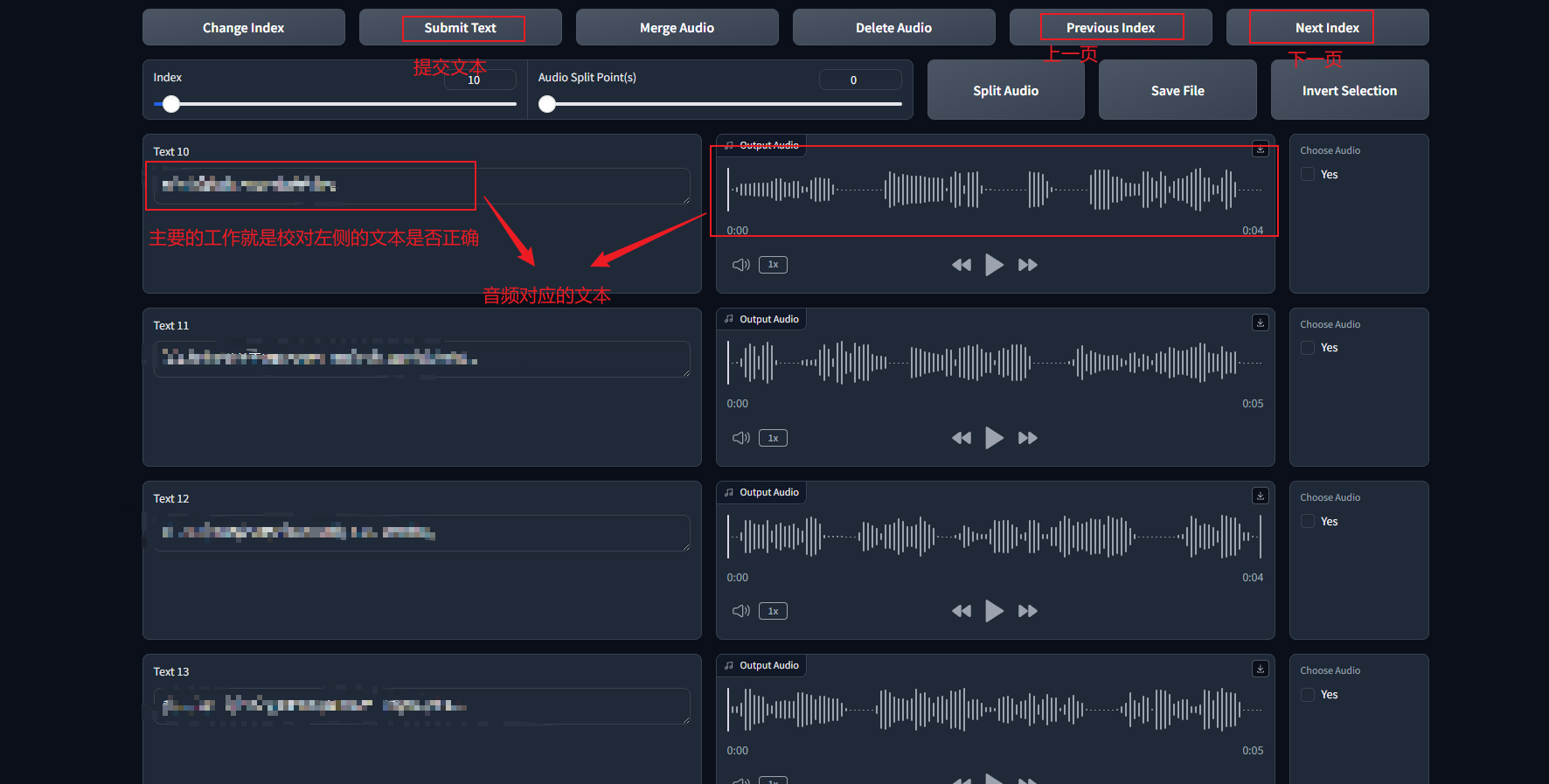
这一步需要相当的耐心,你的语料越大,需要校对的文本也就越多
文本修正的越好,你训练出来的模型质量也会越好
但你如果太懒或者语料实在太多搞不过来也可以省略这一步
追求完美的可以完成这一步
还是那句话,你数据处理的越好,训练出来的模型效果也会越好(追求完美的话)
全部处理完后,数据就处理完毕了,接下来就是微调和训练我们的模型了
模型微调训练
这一步就是制作模型了
从主页面切换到子页面
第一步:训练集格式化
这一阶段的目标是将原始音频和文本数据转化为模型可训练的格式化数据
| 步骤 | 核心功能 | |
|---|---|---|
| 1Aa-文本分词与特征提取 | 文本→分词+语义特征 | |
| 1Ab-语音自监督特征提取 | 音频→HuBERT声学特征 | |
| 1Ac-语义Token提取 | 音频→SoVITS专属的离散语义Token |
大多数参数和路径动不用改,改我标的几个即可
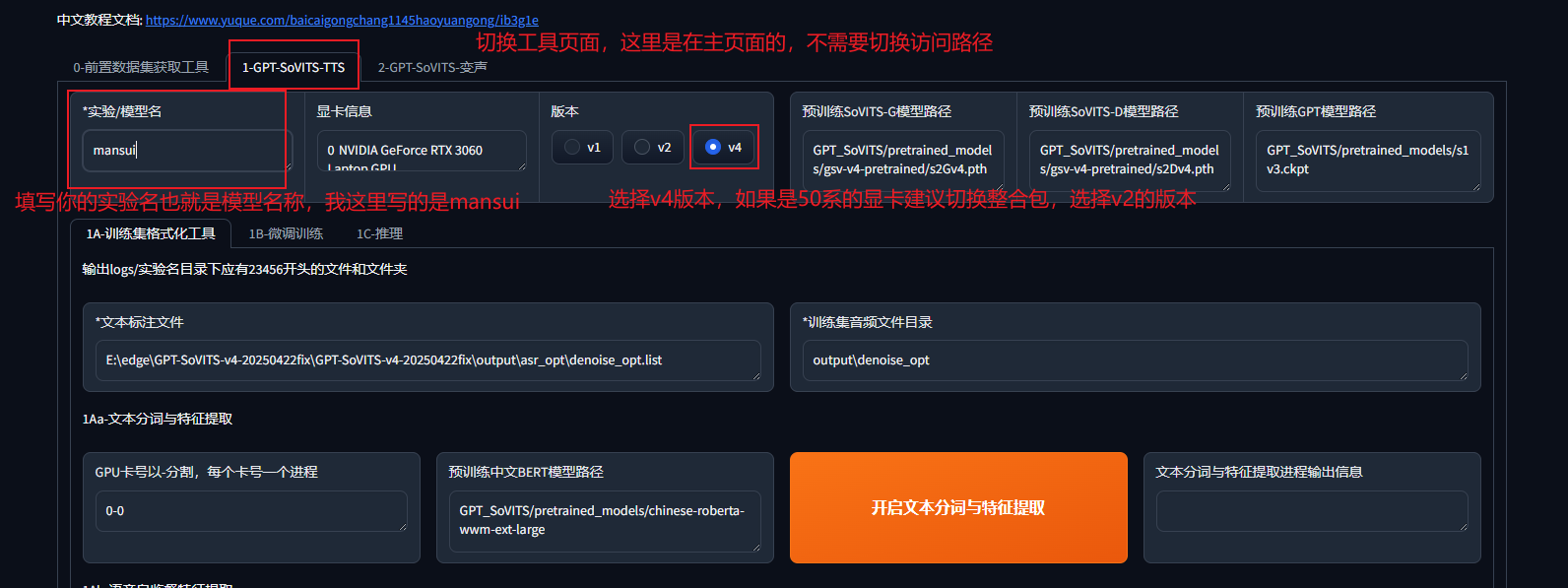
(这里如果显卡信息出不来有可能是50系显卡的bug)
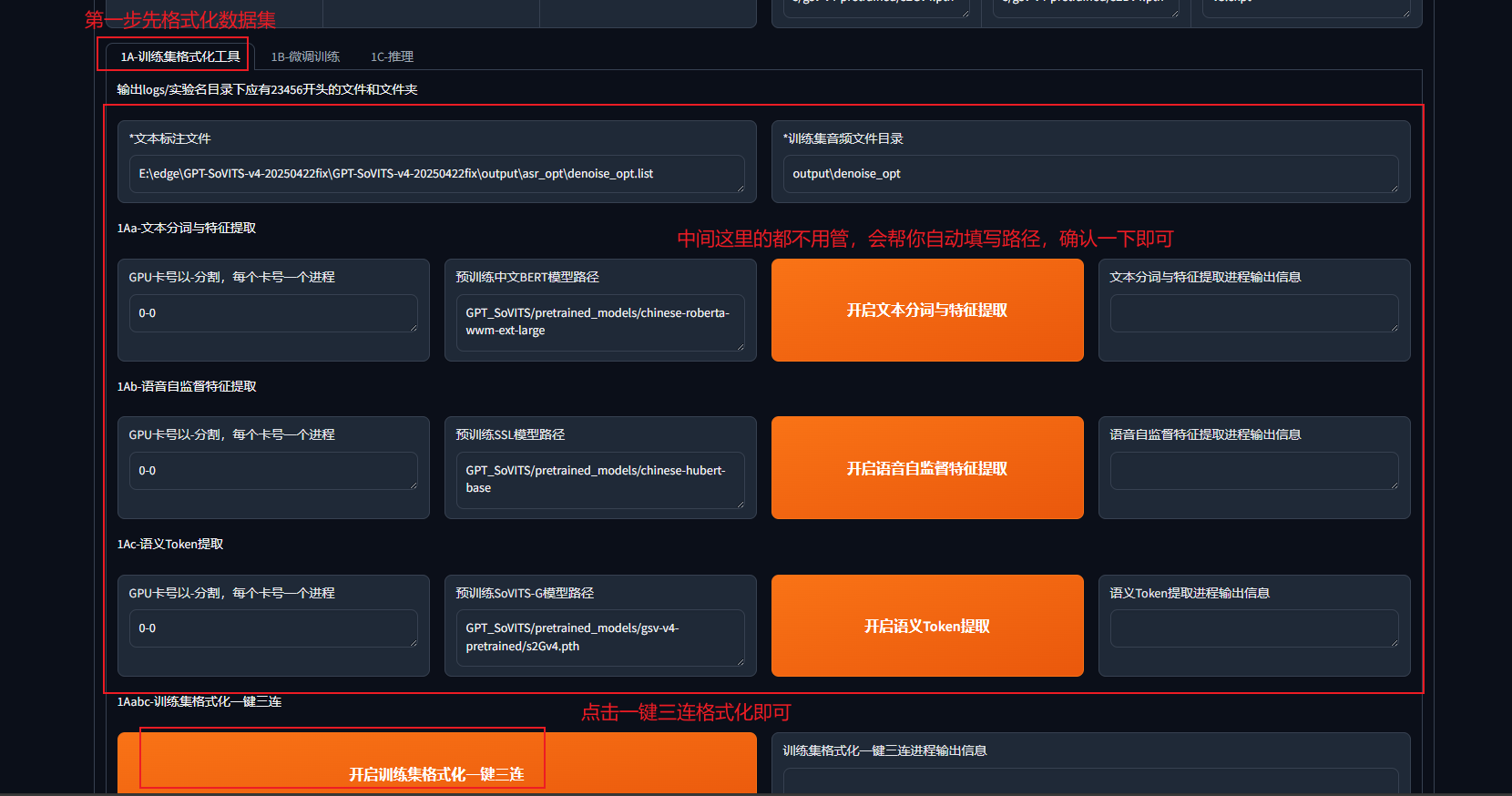
完成后

进入项目文件
检查logs里有无格式化的训练集
确认无误后,格式化训练集就制作完成了
第二步:微调模型
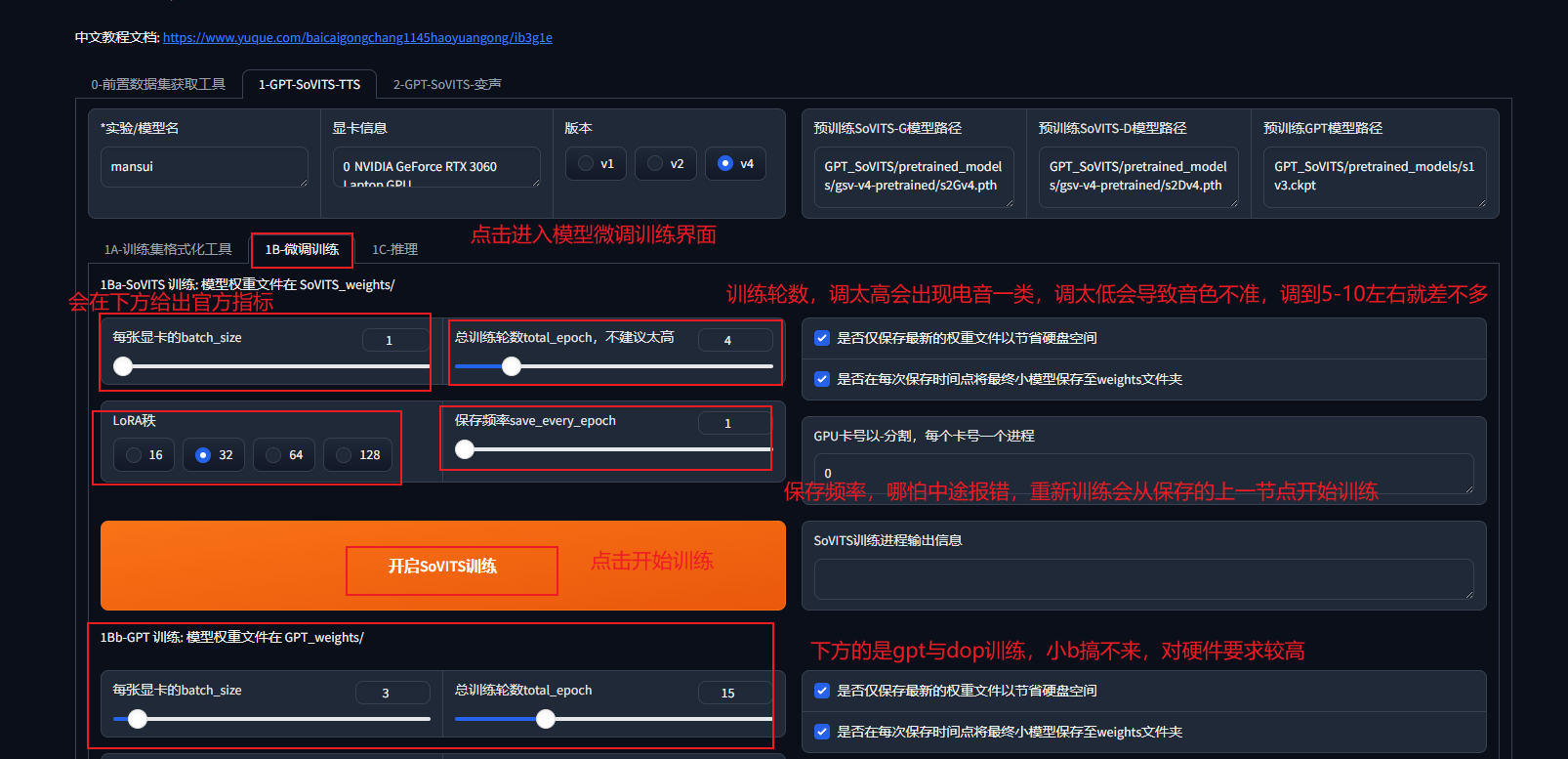
点击开始SoVITS训练后开始等待
batch_size在合理的范围内越高,训练模型的速度就越快,下面给出一张官方的指标
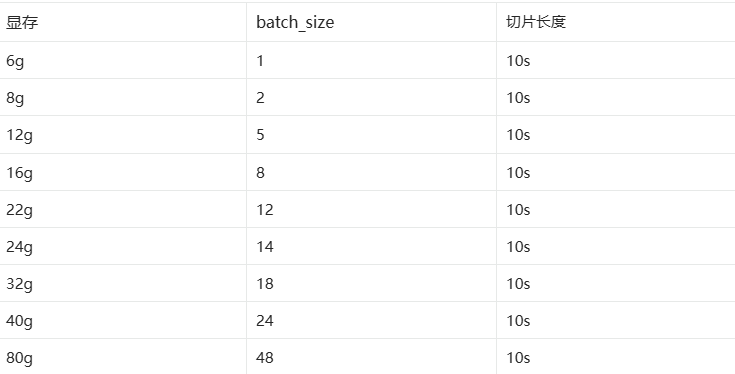
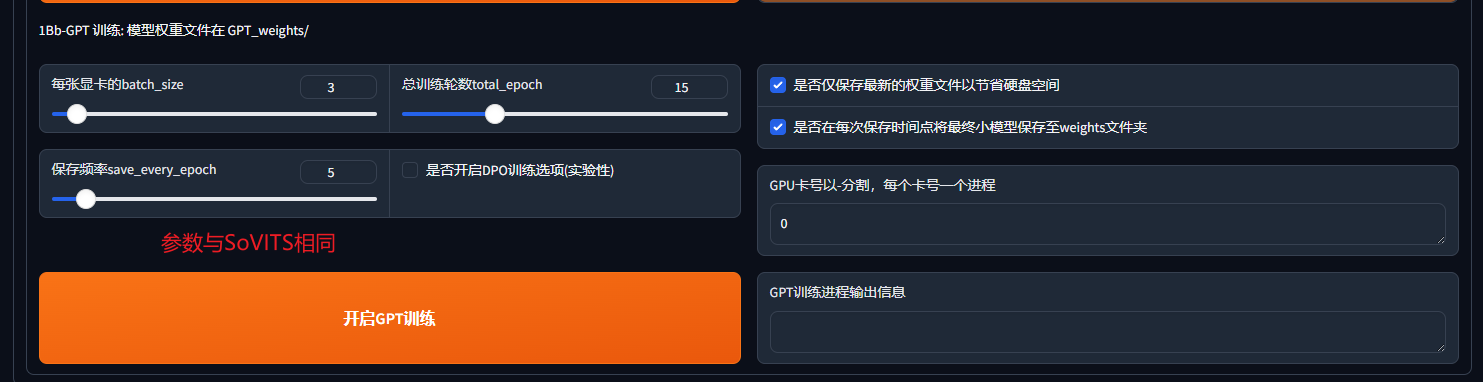
除了SoVITS训练,还有GPT训练,GPT训练可以开启dpo模式
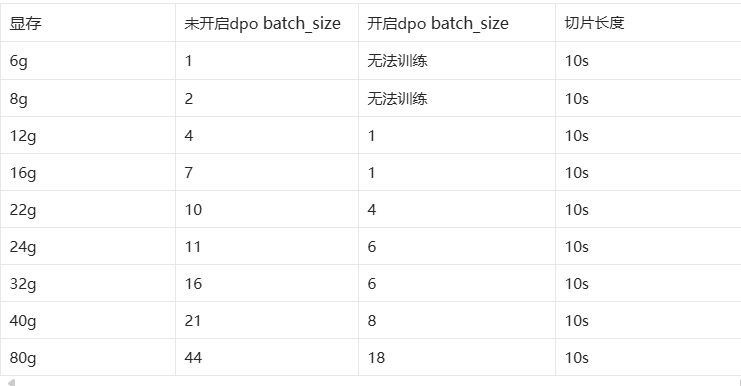
GPT的dpo模式可以大幅提升模型的效果,但是小b硬件不允许,所以在本教程不做演示
(等我成为高手了把你们都吊起来打.jpg)
下面放出官方的指标进行参考
当控制台输出
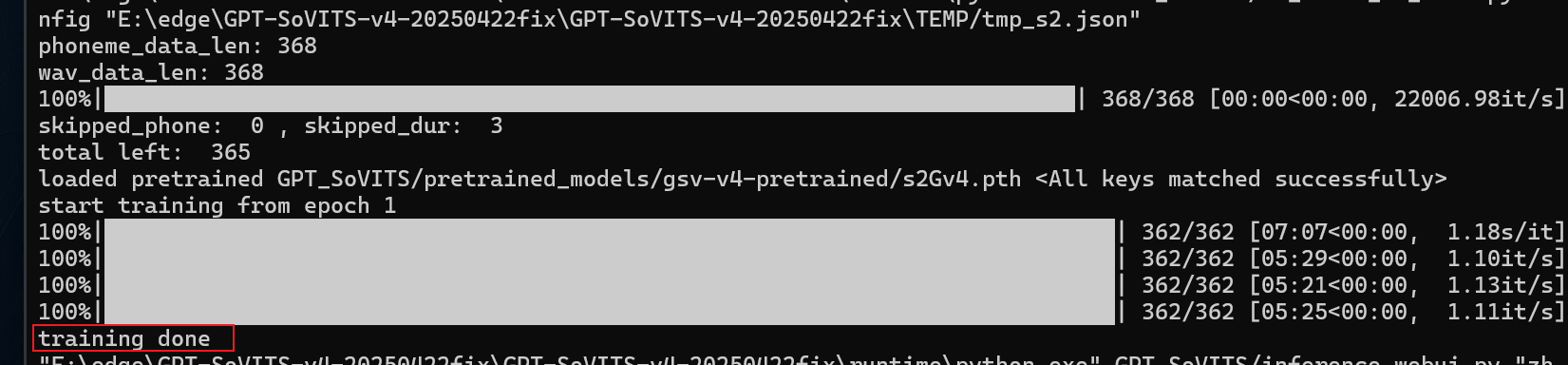
就证明模型已经训练好了
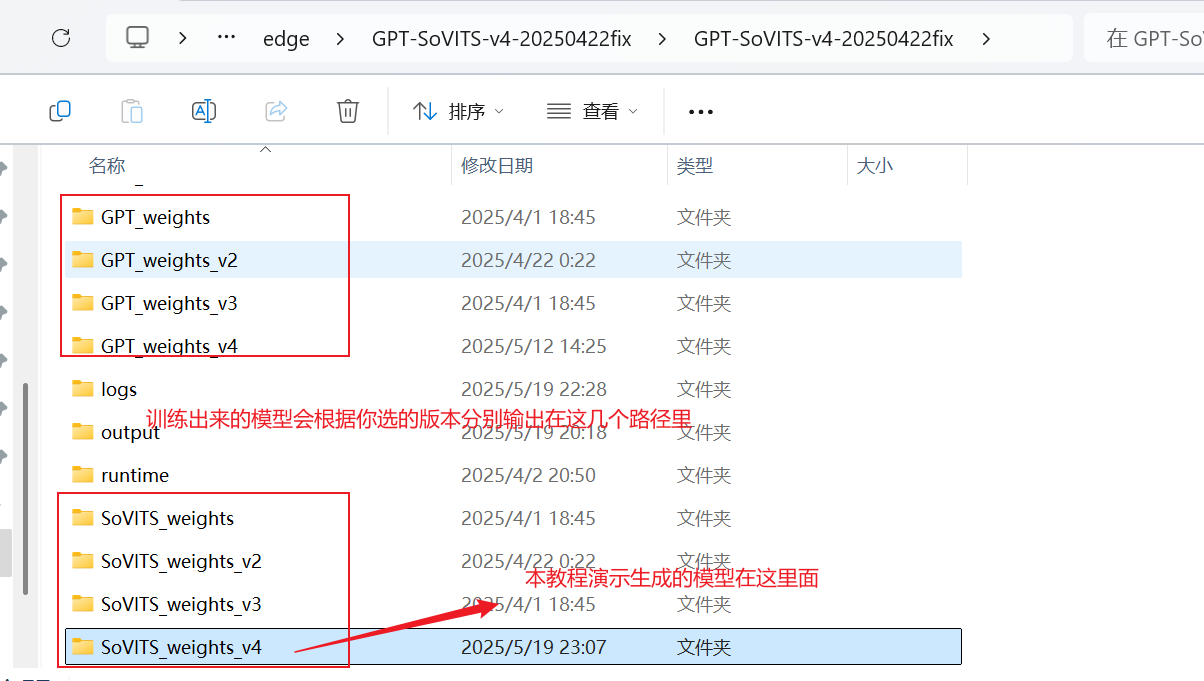
简单说一下模型的保存路径
开启TTS推理
这一步就可以验证你的模型效果了
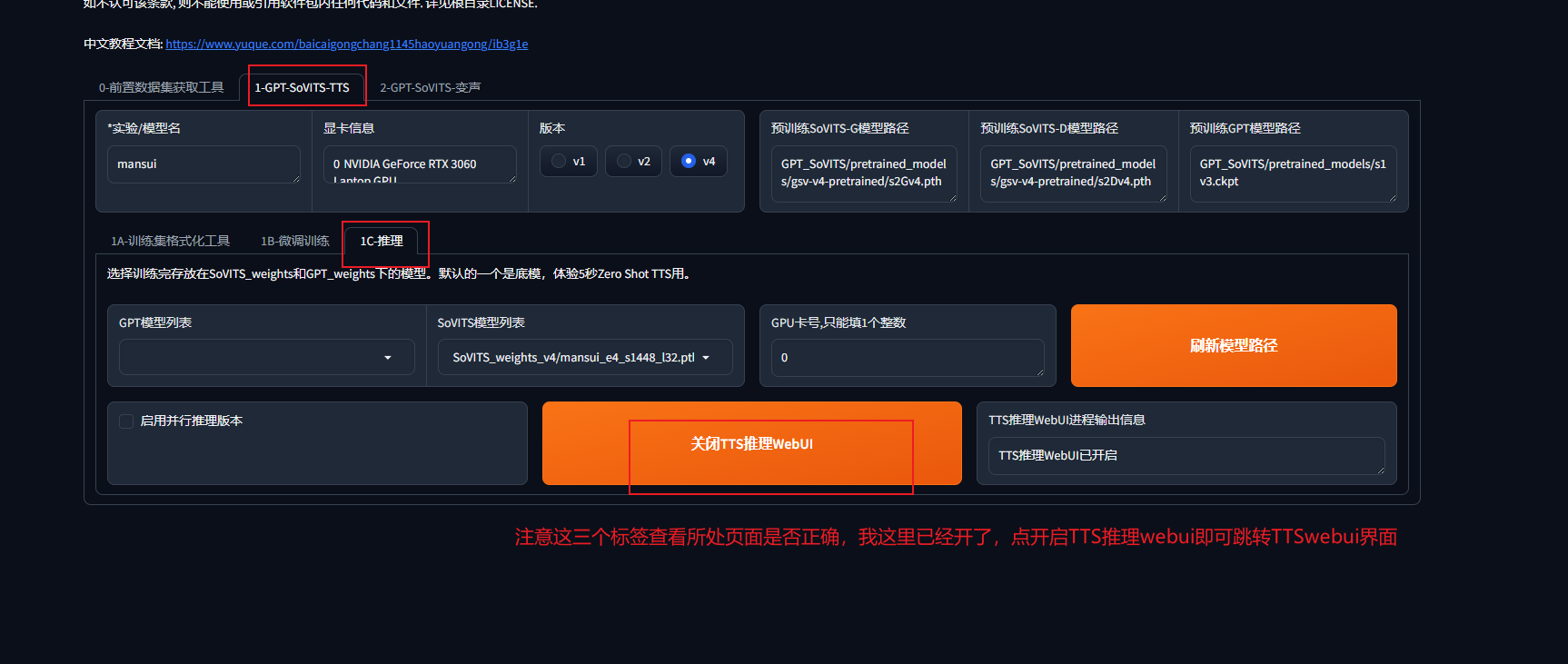
等待一会游览器会自动跳转,如果没有自动跳转的话在游览器访问http://localhost:9872/即可
进入TTSwebui界面
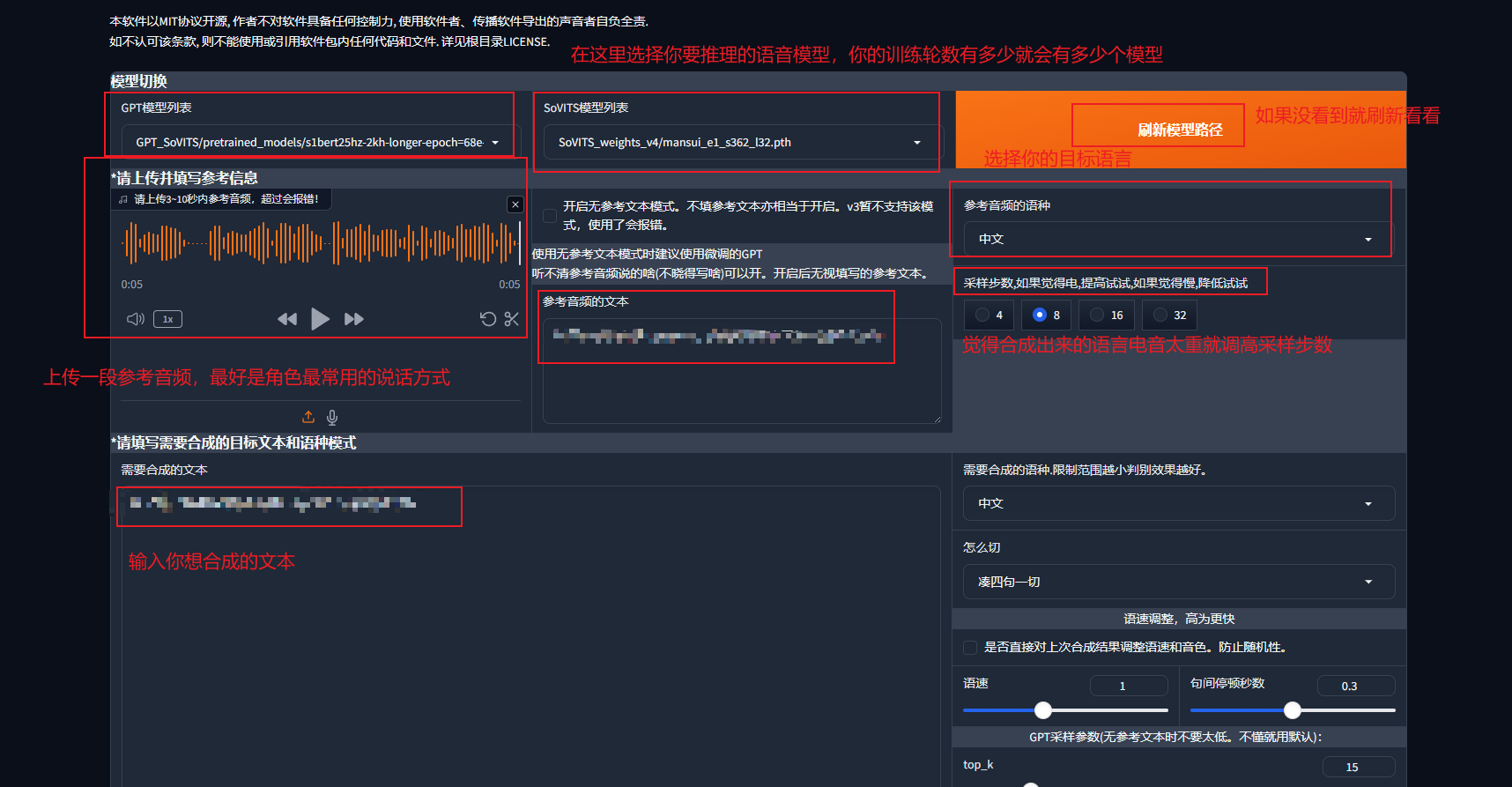
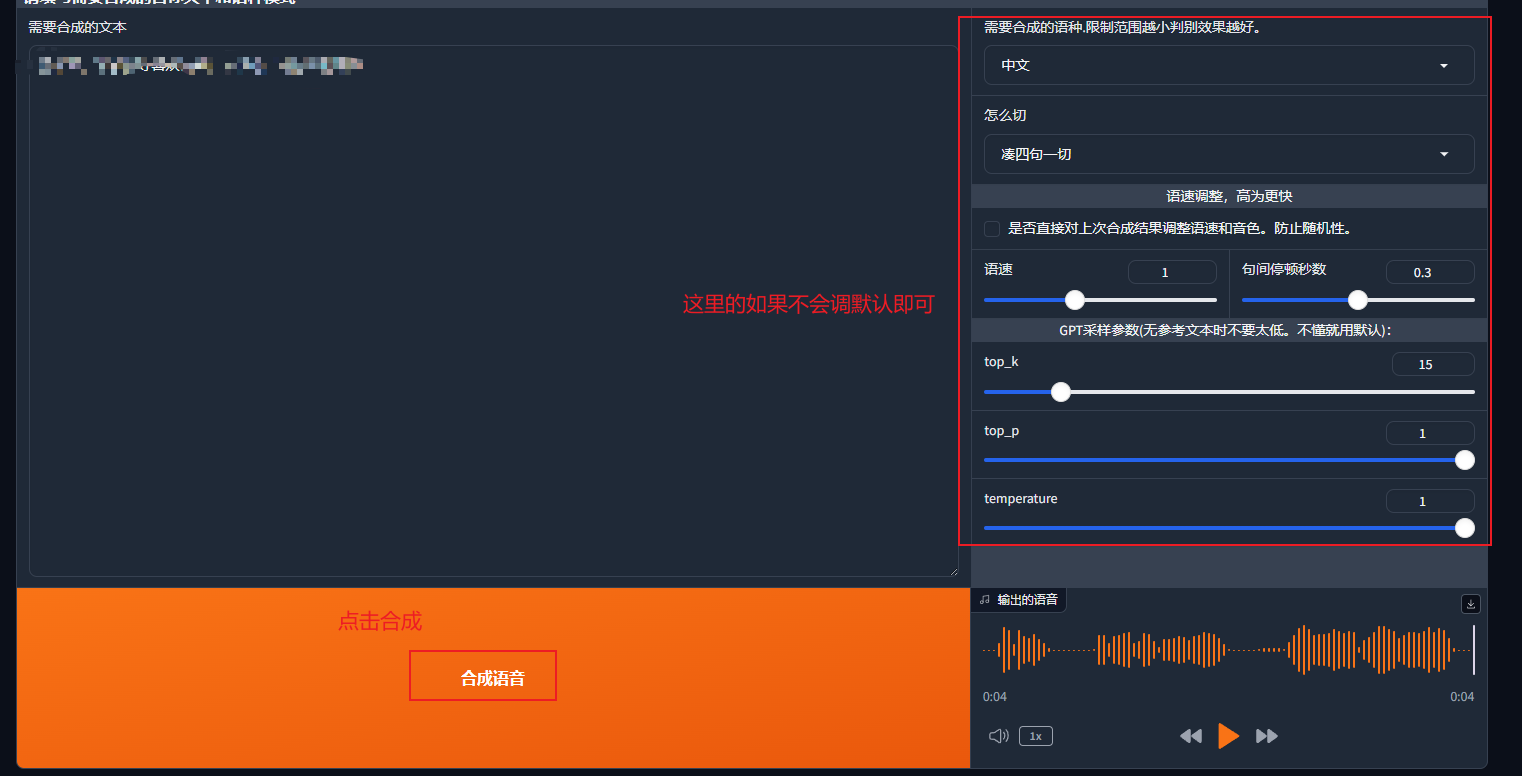
到这里就可以合成出你想要的语音啦
本教程制作不易点个赞再走吧,我会把相关的资源连接都放在下面,有需要的自取
如涉及侵权,请联系小b,三个工作日内删帖
相关连接
GPT-SoVITS的官方指南
小b的github模型仓库(制作不易,点个start再走吧谢谢喵)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









