http://www.cnblogs.com/dolphin0520/archive/2011/10/11/2207886.html
转自:http://www.cnblogs.com/Jason-Damon/archive/2012/04/15/2450100.html
比较不错!
今天把Trie树彻底的看了下。发现网上有两篇非常好的文章,通过他们的博客,我对Trie树有了大题的了解。并且通过理解 消化 综合他们的知识,再结合我自己的编程爱好,我也把具体的程序实现了一遍,这样能对Trie树有更加深刻的认识!
他们是:勇幸|Thinking 和 Maik 。 感谢他们。 下面的分析也是从他们的博客摘抄以便理解的。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
好多人说trie的根节点不包含任何字符信息,我所习惯的trie根节点却是包含信息的,而且认为这样也方便,下面说一下它的性质
1. 字符的种数决定每个节点的出度,即branch数组(空间换时间思想)
2. branch数组的下标代表字符相对于a的相对位置
3. 采用标记的方法确定是否为字符串。
4. 插入、查找的复杂度均为O(len),len为字符串长度
其基本操作有:查找 插入和删除(删除全部和删除单个单词)
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被
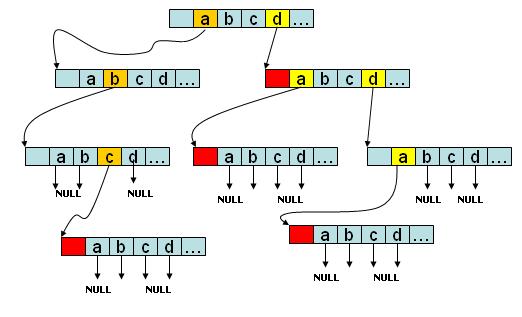
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
1. 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
2. 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3. 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
Trie树是一种非常重要的数据结构,它在信息检索,字符串匹配等领域有广泛的应用,同时,它也是很多算法和复杂数据结构的基础,如后缀树,AC自动机等,因此,掌握Trie树这种数据结构,对于一名IT人员,显得非常基础且必要!(摘抄自:http://dongxicheng.org/structure/trietree/)

#include <iostream>
#include <stack>
using namespace std;
const int sonnum=26, base='a';
struct Trie{
int num; //记录有多少个单词能到达次,也即相同前缀的个位
bool terminal; //判断是否是结束节点
struct Trie *son[sonnum];
Trie()
{
num=1; terminal=false;
memset(son,NULL,sizeof(son));
}
};
Trie* NewTrie()
{
Trie *temp=new Trie();
return temp;
}
void Insert(Trie *root, char *s)
{
Trie *temp=root;
while(*s)
{
if(temp->son[*s-base]==NULL) //不存在 则建立
temp->son[*s-base]=NewTrie();
else
temp->son[*s-base]->num++;
temp=temp->son[*s-base];
s++;
}
temp->terminal=true; //到达尾部,标记一个串
}
bool Search(Trie *root, char *s)
{
Trie *temp=root;
while(*s)
{
if(temp->son[*s-base]!=NULL)
temp=temp->son[*s-base];
else
return false;
s++;
}
return true;
}
void DeleteAll(Trie *root) //删除全部节点
{
Trie *temp=root;
for(int i=0; i<sonnum; i++)
{
if(root->son[i]!=NULL)
DeleteAll(root->son[i]);
}
delete root;
}
bool DeleteWord(Trie *root,char *word) //删除某个单词
{
Trie *current=root;
stack<Trie*> nodes; //用来记录经过的中间节点,供以后自上而下的删除
while(*word && current!=NULL)
{
nodes.push(current); //经过的中间节点压栈
current=current->son[*word-base];
word++;
}
if(current && current->terminal) //此时current指向该word对应的最后一个节点
{
while(nodes.size()!=0)
{
char c=*(--word);
current=nodes.top()->son[c-base]; //取得当前处理的节点
if(current->num==1) //判断该节点是否只被word用,若不是,则不能删除
{
delete current;
nodes.top()->son[c-base]=NULL; //把上层的节点next中指向current节点的指针置为NULL
nodes.pop();
}
else //不能删,只把num相应减1
{
current->num--;
nodes.pop();
while(nodes.size()!=0)
{
char *c=--word;
current=nodes.top()->son[*c-base];
current->num--;
nodes.pop();
}
break;
}
}
return true;
}
else
return false;
}
int main()
{
Trie *root=NewTrie();
Insert(root,"a");
Insert(root,"abandon");
Insert(root,"abandoned");
//不存在的情况
if(Search(root,"abc"))
printf("Found!\n");
else
printf("NotFound!\n");
//存在的情况
if(Search(root,"abandon"))
printf("Found!\n");
else
printf("NotFound!\n");
//能找到 并删除
if(DeleteWord(root,"abandon"))
printf("Delete!\n");
else
printf("NotFound\n");
//找不到
if(DeleteWord(root,"abc"))
printf("Delete!\n");
else
printf("NotFound!\n");
return 0;
}
http://www.cnblogs.com/shuaiwhu/archive/2012/05/05/2484676.html
有时,我们会碰到对字符串的排序,若采用一些经典的排序算法,则时间复杂度一般为O(n*lgn),但若采用Trie树,则时间复杂度仅为O(n)。
Trie树又名字典树,从字面意思即可理解,这种树的结构像英文字典一样,相邻的单词一般前缀相同,之所以时间复杂度低,是因为其采用了以空间换取时间的策略。
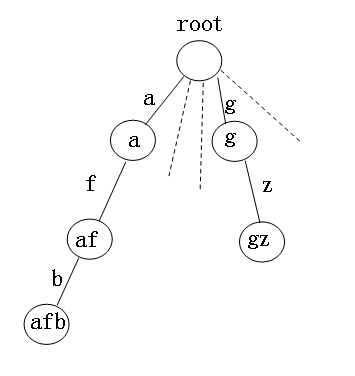
下图为一个针对字符串排序的Trie树(我们假设在这里字符串都是小写字母),每个结点有26个分支,每个分支代表一个字母,结点存放的是从root节点到达此结点的路经上的字符组成的字符串。
将每个字符串插入到trie树中,到达特定的结尾节点时,在这个节点上进行标记,如插入"afb",第一个字母为a,沿着a往下,然后第二个字母为f,沿着f往下,第三个为b,沿着b往下,由于字符串最后一个字符为'\0',因而结束,不再往下了,然后在这个节点上标记afb.count++,即其个数增加1.
之后,通过前序遍历此树,即可得到字符串从小到大的顺序。
实现代码如下(g++、VC++都编译通过):
1 #include <iostream>
2 #include <string.h>
3 using namespace std;
4
5 #define NUM 26
6
7 class Node
8 {
9 public:
10 int count; //记录该处字符串个数
11 Node* char_arr[NUM]; //分支
12 char* current_str; //记录到达此处的路径上的所有字母组成的字符串
13 Node();
14 };
15
16 class Trie
17 {
18 public:
19 Node* root;
20 Trie();
21
22 void insert(char* str);
23 void output(Node* &node, char** str, int& count);
24 };
25
26 //程序未考虑delete动态内存
27 int main()
28 {
29 char** str = new char*[12];
30 str[0] = "zbdfasd";
31 str[1] = "zbcfd";
32 str[2] = "zbcdfdasfasf";
33 str[3] = "abcdaf";
34 str[4] = "defdasfa";
35 str[5] = "fedfasfd";
36 str[6] = "dfdfsa";
37 str[7] = "dadfd";
38 str[8] = "dfdfasf";
39 str[9] = "abcfdfa";
40 str[10] = "fbcdfd";
41 str[11] = "abcdaf";
42
43 //建立trie树
44 Trie* trie = new Trie();
45 for(int i = 0; i < 12; i++)
46 trie->insert(str[i]);
47
48 int count = 0;
49 trie->output(trie->root, str, count);
50
51 for(int i = 0; i < 12; i++)
52 cout<<str[i]<<endl;
53
54 return 0;
55 }
56
57 Node::Node()
58 {
59 count = 0;
60 for(int i = 0; i < NUM; i++)
61 char_arr[i] = NULL;
62 current_str = new char[100];
63 current_str[0] = '\0';
64 }
65
66 Trie::Trie()
67 {
68 root = new Node();
69 }
70
71 void Trie::insert(char* str)
72 {
73 int i = 0;
74 Node* parent = root;
75
76 //将str[i]插入到trie树中
77 while(str[i] != '\0')
78 {
79 //如果包含str[i]的分支存在,则新建此分支
80 if(parent->char_arr[str[i] - 'a'] == NULL)
81 {
82 parent->char_arr[str[i] - 'a'] = new Node();
83 //将父节点中的字符串添加到当前节点的字符串中
84 strcat(parent->char_arr[str[i] - 'a']->current_str, parent->current_str);
85
86 char str_tmp[2];
87 str_tmp[0] = str[i];
88 str_tmp[1] = '\0';
89
90 //将str[i]添加到当前节点的字符串中
91 strcat(parent->char_arr[str[i] - 'a']->current_str, str_tmp);
92
93 parent = parent->char_arr[str[i] - 'a'];
94 }
95 else
96 {
97 parent = parent->char_arr[str[i] - 'a'];
98 }
99 i++;
100 }
101 parent->count++;
102 }
103
104 //采用前序遍历
105 void Trie::output(Node* &node, char** str, int& count)
106 {
107 if(node != NULL)
108 {
109 if(node->count != 0)
110 {
111 for(int i = 0; i < node->count; i++)
112 str[count++] = node->current_str;
113 }
114 for(int i = 0; i < NUM; i++)
115 {
116 output(node->char_arr[i], str, count);
117 }
118
119 }
120 }
http://www.cnblogs.com/cherish_yimi/archive/2009/10/12/1581666.html
文章作者:yx_th000 文章来源:Cherish_yimi (http://www.cnblogs.com/cherish_yimi/) 转载请注明,谢谢合作。
关键词:trie trie树 数据结构
[本文新址:http://www.ahathinking.com/archives/14.html ]
前几天学习了并查集和trie树,这里总结一下trie。
本文讨论一棵最简单的trie树,基于英文26个字母组成的字符串,讨论插入字符串、判断前缀是否存在、查找字符串等基本操作;至于trie树的删除单个节点实在是少见,故在此不做详解。
l Trie原理
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
l Trie性质
好多人说trie的根节点不包含任何字符信息,我所习惯的trie根节点却是包含信息的,而且认为这样也方便,下面说一下它的性质 (基于本文所讨论的简单trie树)
1. 字符的种数决定每个节点的出度,即branch数组(空间换时间思想)
2. branch数组的下标代表字符相对于a的相对位置
3. 采用标记的方法确定是否为字符串。
4. 插入、查找的复杂度均为O(len),len为字符串长度
l Trie的示意图
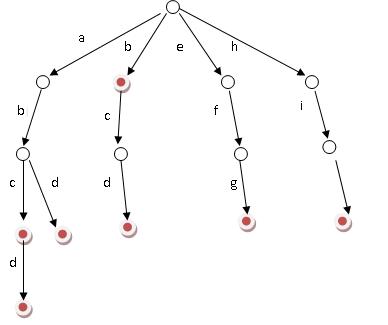
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL
l TrieTrie的优点举例
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
1. 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
2. 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3. 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
解释一下hash为什么不能将建立与查询同时执行,例如有串:911,911456输入,如果要同时执行建立与查询,过程就是查询911,没有,然后存入9、91、911,查询911456,没有然后存入9114、91145、911456,而程序没有记忆功能,并不知道911在输入数据中出现过。所以用hash必须先存入所有子串,然后for循环查询。
而trie树便可以,存入911后,已经记录911为出现的字符串,在存入911456的过程中就能发现而输出答案;倒过来亦可以,先存入911456,在存入911时,当指针指向最后一个1时,程序会发现这个1已经存在,说明911必定是某个字符串的前缀,该思想是我在做pku上的3630中发现的,详见本文配套的“入门练习”。
l Trie的简单实现(插入、查询)

1
2#include <iostream>
3using namespace std;
4
5const int branchNum = 26; //声明常量
6int i;
7
8struct Trie_node
9{
10 bool isStr; //记录此处是否构成一个串。
bool isStr; //记录此处是否构成一个串。
11 Trie_node *next[branchNum];//指向各个子树的指针,下标0-25代表26字符
12 Trie_node():isStr(false)
13 {
{
14 memset(next,NULL,sizeof(next));
15 }
}
16 };
};
17
18class Trie
19{
20public:
21 Trie();
22 void insert(const char* word);
23 bool search(char* word);
24 void deleteTrie(Trie_node *root);
25private:
26 Trie_node* root;
27};
28
29Trie::Trie()
30{
31 root = new Trie_node();
32}
33
34void Trie::insert(const char* word)
35{
36 Trie_node *location = root;
37 while(*word)
38 {
39 if(location->next[*word-'a'] == NULL)//不存在则建立
40 {
41 Trie_node *tmp = new Trie_node();
42 location->next[*word-'a'] = tmp;
43 }
44 location = location->next[*word-'a']; //每插入一步,相当于有一个新串经过,指针要向下移动
45 word++;
46 }
47 location->isStr = true; //到达尾部,标记一个串
48}
49
50bool Trie::search(char *word)
51{
52 Trie_node *location = root;
53 while(*word && location)
54 {
55 location = location->next[*word-'a'];
56 word++;
57 }
58 return(location!=NULL && location->isStr);
59}
60
61void Trie::deleteTrie(Trie_node *root)
62{
63 for(i = 0; i < branchNum; i++)
64 {
65 if(root->next[i] != NULL)
66 {
67 deleteTrie(root->next[i]);
68 }
69 }
70 delete root;
71}
72
73void main() //简单测试
74{
75 Trie t;
76 t.insert("a");
77 t.insert("abandon");
78 char * c = "abandoned";
79 t.insert(c);
80 t.insert("abashed");
81 if(t.search("abashed"))
82 printf("true\n");
83}
学习这个:
Trie树|字典树的简介及实现
Trie,又称字典树、单词查找树,是一种树形结构,用于保存大量的字符串。它的优点是:利用字符串的公共前缀来节约存储空间。
相对来说,Trie树是一种比较简单的数据结构.理解起来比较简单,正所谓简单的东西也得付出代价.故Trie树也有它的缺点,Trie树的内存消耗非常大.当然,或许用左儿子右兄弟的方法建树的话,可能会好点.
其基本性质可以归纳为:
1. 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3. 每个节点的所有子节点包含的字符都不相同。
其基本操作有:查找 插入和删除,当然删除操作比较少见.我在这里只是实现了对整个树的删除操作,至于单个word的删除操作也很简单.
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。(4) 迭代过程……(5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
其他操作类似处理.
/*
Name: Trie树的基本实现
Author: MaiK
Description: Trie树的基本实现 ,包括查找 插入和删除操作(卫星数据可以因情况而异)
*/
#include<algorithm>
#include<iostream>
using namespace std;
const int sonnum=26,base='a';
struct Trie
{
int num;//to remember how many word can reach here,that is to say,prefix
bool terminal;//If terminal==true ,the current point has no following point
struct Trie *son[sonnum];//the following point
};
Trie *NewTrie()// create a new node
{
Trie *temp=new Trie;
temp->num=1;temp->terminal=false;
for(int i=0;i<sonnum;++i)temp->son[i]=NULL;
return temp;
}
void Insert(Trie *pnt,char *s,int len)// insert a new word to Trie tree
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
{
if(temp->son[s[i]-base]==NULL)temp->son[s[i]-base]=NewTrie();
else temp->son[s[i]-base]->num++;
temp=temp->son[s[i]-base];
}
temp->terminal=true;
}
void Delete(Trie *pnt)// delete the whole tree
{
if(pnt!=NULL)
{
for(int i=0;i<sonnum;++i)if(pnt->son[i]!=NULL)Delete(pnt->son[i]);
delete pnt;
pnt=NULL;
}
}
Trie* Find(Trie *pnt,char *s,int len)//trie to find the current word
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
if(temp->son[s[i]-base]!=NULL)temp=temp->son[s[i]-base];
else return NULL;
return temp;
}


























 3612
3612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









