










一、开场白
实际工作中经常遇到一个问题Redis与MySQL双写一致性如何保证? 其实就是在问缓存和数据库在双写场景下,一致性是如何保证的?今天将跟大家一起来探讨如何回答这个问题。
二、谈谈一致性
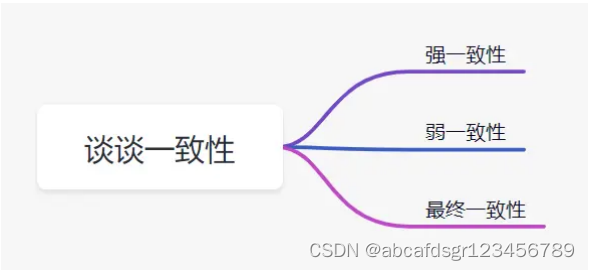
一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,一致只会迟到,但绝不会缺席
三、三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存模式:
- 旁路缓存模式:它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
- 读写穿透
- 异步缓存写入
1、旁路缓存模式的读请求流程如下:
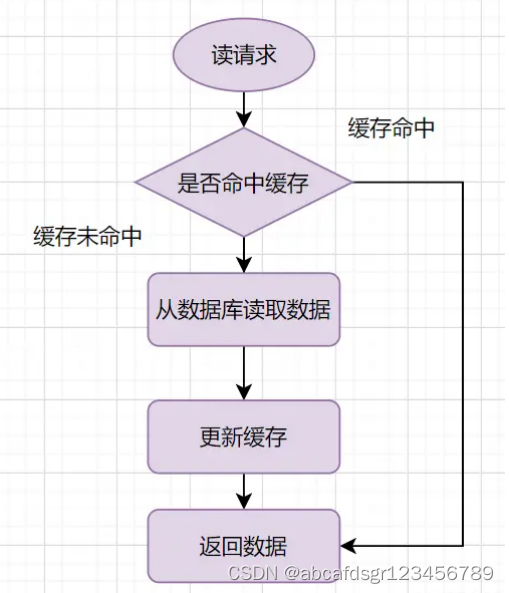
小结:缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
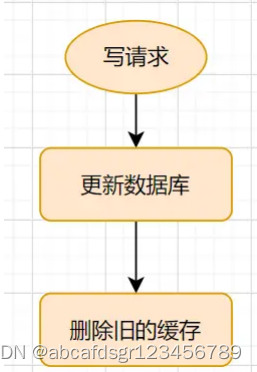
2、旁路缓存模式的写请求流程如下:
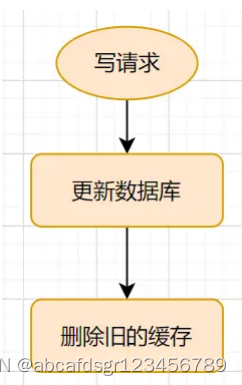
小结:更新的时候,先更新数据库,然后再删除缓存
四、读写穿透
读写穿透中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
读写穿透的读请求流程如下:
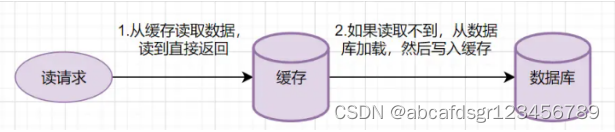
小结:从缓存读取数据,读到直接返回。如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
这个简要流程是不是跟旁路缓存模式很像呢?其实读写穿透就是多了一层抽象缓存层,流程如下:
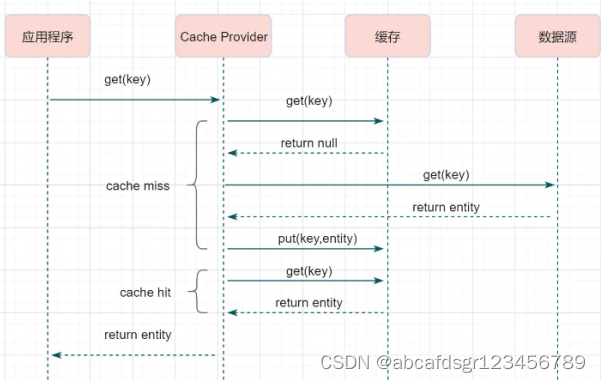
小结:读写穿透实际只是在旁路缓存模式之上进行了一层封装,它会让程序代码变得更简洁,同时也减少数据源上的负载。
读写穿透的写请求流程如下:
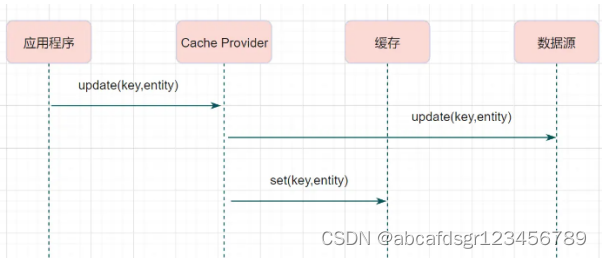
小结:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。这种缓存读写策略在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能
五、异步缓存写入
异步缓存写入跟读写穿透有相似的地方,都是由抽象缓存层来负责缓存和数据库的读写。它
两又有个很大的不同:读写穿透是同步更新缓存和数据的,异步缓存写入则是只更新缓存,
不直接更新数据库,通过批量异步的方式来更新数据库。
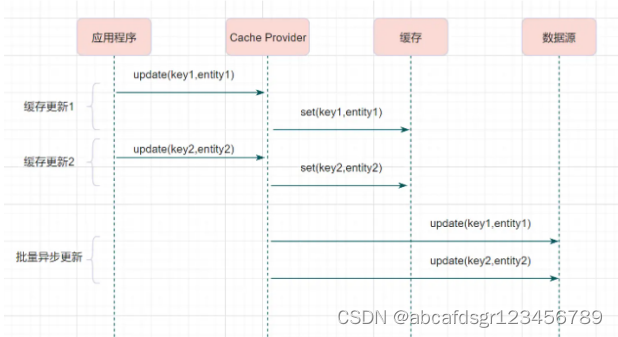
小结:这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool(缓冲池)机制就使用到这种模式。Redis 和 MySQL 的更新策略用的是旁路缓存模式,另外两种策略主要应用在计算机系统里
六、操作缓存的时候,删除缓存呢,还是更新缓存?
一般业务场景,我们使用的就是旁路缓存模式模式。 有些小伙伴可能会问, 旁路缓存模式
在写入请求的时候,为什么是删除缓存而不是更新缓存呢?
我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?
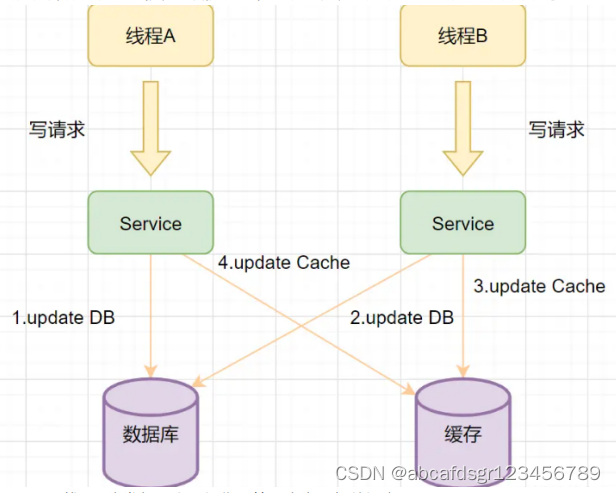
我们先来看个例子:
1、 线程A先发起一个写操作,第一步先更新数据库
2、线程B再发起一个写操作,第二步更新了数据库
3、由于网络等原因,线程B先更新了缓存
4、线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不
一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
更新缓存相对于删除缓存,还有两点劣势:
- 如果你写入的缓存值,是经过复杂计算才得到的话。更新缓存频率高的话,就浪 费性能啦。
- 在写数据库场景多,读数据场景少的情况下,数据很多时候还没被读取到,又被
更新了,这也浪费了性能呢(实际上,写多的场景,用缓存也不是很划算了)
七、缓存缓存延时双删
1、先删
旁路缓存模式缓存模式中,有些小伙伴还是有疑问,在写入请求的时候,为什么是先操作数
据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
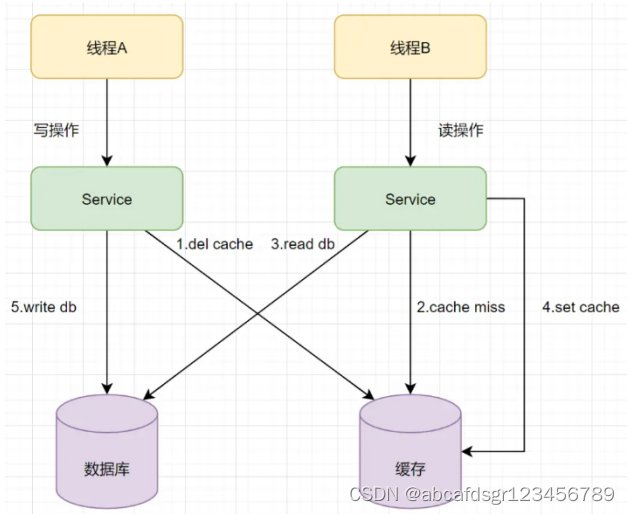
A、线程A发起一个写操作,第一步del cache
B、 此时线程B发起一个读操作,cache miss
C、线程B继续读DB,读出来一个老数据
D、然后线程B把老数据设置入cache
E、线程A写入DB最新的数据
这样就有问题啦,缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新
数据。因此,旁路缓存模式缓存模式,选择了先操作数据库而不是先操作缓存(后删)。
2、后删
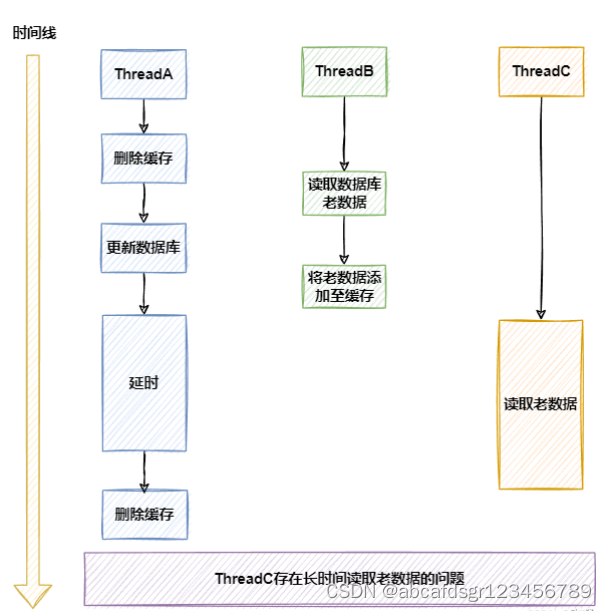
这样可以在一定程度上解决两个线程并发下的缓存与mysq不一致的问题,但是在线程数超过两个,达到三个的时候,仍有可能出现数据库数据与缓存数据不一致的问题,无法保证最终一致性。
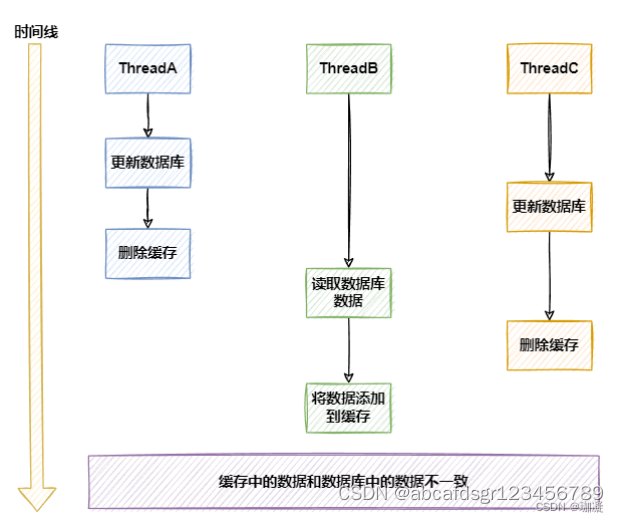
线程A修改数据,删除缓存后,线程B读取数据库数据,放入缓存前,线程C修改了数据,在线程C未删除缓存后,线程B操作缓存写入,导入数据库缓存不一致
3、延时后删
在并发场景下,只要延时时间合适,一定可以避免线程B将错误数据加载到缓存中的场景
(缓存删除前一直读缓存数据,缓存删除后,读事务提交后的数据,出现后删中三线程并发
下的缓存与mysql数据不一致场景的可能性不大),可以保证最终一致性。
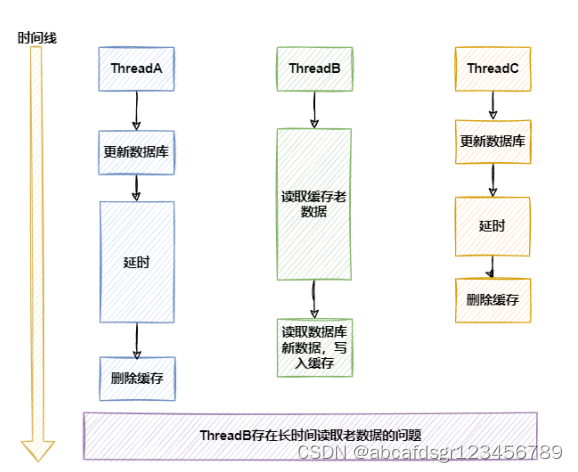
这个休眠一会,一般多久呢?都是1秒?这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。但是在延时删除期间,线程B会长时间读取到旧数据,这在一些场景下无法接受的
4、延时双删
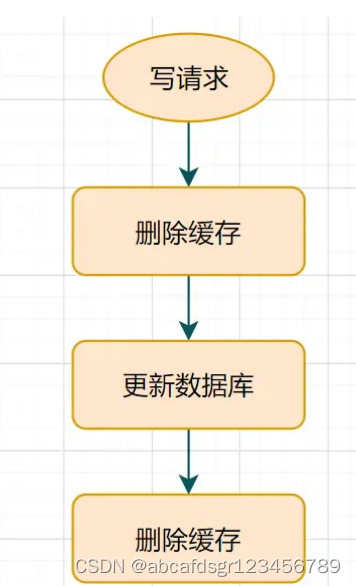
A、先删除缓存
B、再更新数据库
C、休眠一会,再次删除缓存。
小结:极端情况下,延时双删,也无法避免某个线程长时间读取老数据的问题,但是通常删除缓存与更新数据库操作的间隔比较短,所以出现这种场景的概率不是很大
5、删除缓存重试机制
不管是延时双删还是旁路缓存模式的先操作数据库再删除缓存,如果第二步的删除缓存失败
呢,删除失败会导致脏数据
删除失败就多删除几次呀,保证删除缓存成功呀,所以可以引入删除缓存重试机制
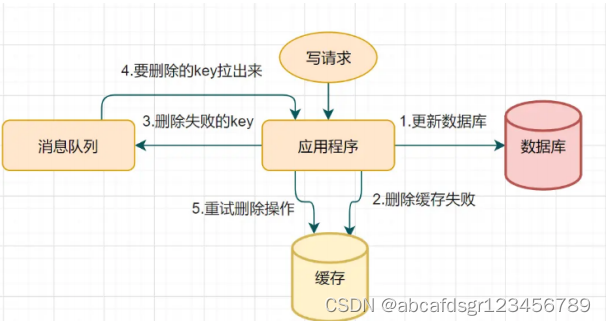
A、 写请求更新数据库
B、 缓存因为某些原因,删除失败
C、把删除失败的key放到消息队列
D、消费消息队列的消息,获取要删除的key
E、 重试删除缓存操作
6、读取binlog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。其实,还可以通过数据库的
binlog来异步淘汰key。
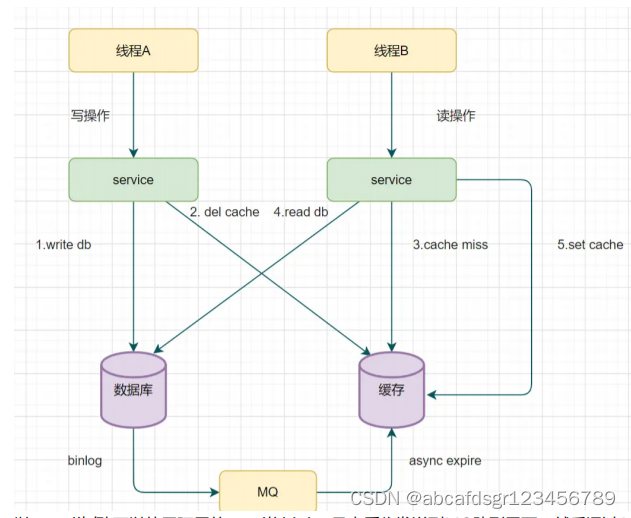
以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK
机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
https://github.com/alibaba/canal
八、zset (有序集合)
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结
构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内
部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排
序权重。它的内部实现用的是一种叫做「跳跃列表」的数据结构。
zset 中最后一个 value 被移除后,数据结构自动删除,内存被回收。
zset 可以用来存粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉
丝列表按关注时间进行排序。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们可
以对成绩按分数进行排序就可以得到他的名次。
> zadd books 9.0 "think in java"
(integer) 1
> zadd books 8.9 "java concurrency"
(integer) 1
> zadd books 8.6 "java cookbook"
(integer) 1
> zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> zcard books # 相当于 count()
(integer) 3
> zscore books "java concurrency" # 获取指定 value 的 score
"8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题
> zrank books "java concurrency" # 排名
(integer) 1
> zrangebyscore books 0 8.91 # 根据分值区间遍历 zset
1) "java cookbook"
2) "java concurrency"
> zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代
表 infinite,无穷大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> zrem books "java concurrency" # 删除 value
(integer) 1
> zrange books 0 -1
1) "java cookbook"
2) "think in java"
九、跳跃列表
zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较
复杂。因为 zset 要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的链表结构。
我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到特
定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入
点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,那
该怎么办?
想想一个创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公
司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划
分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安
排。公司规模进一步扩展,需要再增加一个层级 —— 部门,每个部门会从组长列表中推选
出一个代表来作为部长。部长们之间还会有自己的高层会议安排。
跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑
选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级
代表,再串起来。最终就形成了金字塔结构。
想想你老家在世界地图中的位置:亚洲–>中国->安徽省->安庆市->枞阳县->汤沟镇->田
间村->xxxx号,也是这样一个类似的结构。
十、断尾求生 —— 简单限流
限流算法在分布式领域是一个经常被提起的话题,当系统的处理能力有限时,如何阻止计划
外的请求继续对系统施压,除了控制流量,限流还有一个应用目的是用于控制用户行为,避免垃圾请求。比如在 UGC社区,用户的发帖、回复、点赞等行为都要严格受控,一般要严格限定某行为在规定时间内允许的次数,超过了次数那就是非法行为。对非法行为,业务必须规定适当的惩处策略。
- 如何使用 Redis 来实现简单限流策略?
首先我们来看一个常见 的简单的限流策略。系统要限定用户的某个行为在指定的时间里只能允许发生 N 次,如何使用 Redis 的数据结构来实现这个限流的功能? - 解决方案
这个限流需求中存在一个滑动时间窗口,想想 zset 数据结构的 score 值,是不是可以通过
score 来圈出这个时间窗口来。而且我们只需要保留这个时间窗口,窗口之外的数据都可以
砍掉。那这个 zset 的 value 填什么比较合适呢?它只需要保证唯一性即可,用 uuid 会比
较浪费空间,那就改用毫秒时间戳吧。用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 保存下来。同一个用户同一种行为用一个 zset 记录。为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。通过统计滑动窗口内的行为数量与阈值 max_count 进行比较就可以得出当前的行为是否允
许。用Java代码表示如下:
public class SimpleRateLimiter {
private Jedis jedis;
public SimpleRateLimiter(Jedis jedis) {
this.jedis = jedis;
}
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = String.format("hist:%s:%s", userId, actionKey);
long nowTs = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.zadd(key, nowTs, "" + nowTs);
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
Response<Long> count = pipe.zcard(key);
pipe.expire(key, period + 1);
pipe.exec();
pipe.close();
return count.get() <= maxCount;
}
public static void main(String[] args) {
Jedis jedis = new Jedis();
SimpleRateLimiter limiter = new SimpleRateLimiter(jedis);
for(int i=0;i<20;i++) {
System.out.println(limiter.isActionAllowed("laoqian", "reply", 60, 5));
}
}
}
这段代码整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全
部清理掉,只保留窗口内的记录。zset 集合中只有 score 值非常重要,value 值没有特别
的意义,只需要保证它是唯一的就可以了。因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
十一、一毛不拔 —— 漏斗限流
漏斗限流是最常用的限流方法之一,顾名思义,这个算法的灵感源于漏斗(funnel)的结
构。漏斗的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。如果漏嘴流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率。下面我们使用Java代码来描述单机漏斗算法。
public class FunnelRateLimiter {
static class Funnel {
int capacity;
float leakingRate;
int leftQuota;
long leakingTs;
public Funnel(int capacity, float leakingRate) {
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
}
void makeSpace() {
long nowTs = System.currentTimeMillis();
long deltaTs = nowTs - leakingTs;
int deltaQuota = (int) (deltaTs * leakingRate);
if (deltaQuota < 0) { // 间隔时间太长,整数数字过大溢出
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
}
if (deltaQuota < 1) { // 腾出空间太小,最小单位是1
return;
}
this.leftQuota += deltaQuota;
this.leakingTs = nowTs;
if (this.leftQuota > this.capacity) {
this.leftQuota = this.capacity;
}
}
boolean watering(int quota) {
makeSpace();
if (this.leftQuota >= quota) {
this.leftQuota -= quota;
return true;
}
return false;
}
}
private Map<String, Funnel> funnels = new HashMap<>();
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate) {
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null) {
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
}
return funnel.watering(1); // 需要1个quota
}
}
小结:Funnel 对象的 make_space 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。问题来了,分布式的漏斗算法该如何实现?能不能使用 Redis 的基础数据结构来搞定?我们观察 Funnel 对象的几个字段,我们发现可以将 Funnel 对象的内容按字段存储到一个hash 结构中,灌水的时候将 hash 结构的字段取出来进行逻辑运算后,再将新值回填到
hash 结构中就完成了一次行为频度的检测。但是有个问题,我们无法保证整个过程的原子性。从 hash 结构中取值,然后在内存里运算,再回填到 hash 结构,这三个过程无法原子化,意味着需要进行适当的加锁控制。而一旦加锁,就意味着会有加锁失败,加锁失败就需要选择重试或者放弃。如果重试的话,就会导致性能下降。如果放弃的话,就会影响用户体验。同时,代码的复杂度也跟着升高很多。
十二、Redis-Cell
https://github.com/brandur/rediscell
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提
供了原子的限流指令。有了这个模块,限流问题就非常简单了。该模块只有1条指令cl.throttle,它的参数和返回值都略显复杂,接下来让我们来看看这个指令具体该如何使用。
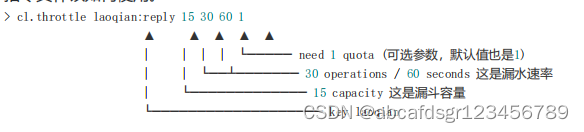
上面这个指令的意思是允许「用户回复行为」的频率为每 60s 最多 30 次(漏水速率),漏斗
的初始容量为 15,也就是说一开始可以连续回复 15 个帖子,然后才开始受漏水速率的影
响。我们看到这个指令中漏水速率变成了 2 个参数,替代了之前的单个浮点数。用两个参
数相除的结果来表达漏水速率相对单个浮点数要更加直观一些。

在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周到,
连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想阻
塞线程,也可以异步定时任务来重试。
十三、凌波微步 —— 探索「跳跃列表」内部结构
Redis 的 zset 是一个复合结构,一方面它需要一个 hash 结构来存储 value 和 score 的对
应关系,另一方面需要提供按照 score 来排序的功能,还需要能够指定 score 的范围来获
取 value 列表的功能,这就需要另外一个结构「跳跃列表」。
zset 的内部实现是一个 hash 字典加一个跳跃列表 (skiplist)。hash 结构在讲字典结构时已
经详细分析过了,它很类似于 Java 语言中的 HashMap 结构。
1、基本结构

上图中的跳跃列表一共有四层,Redis 的跳跃表共有 64 层,容纳 2^64 个元素应该不成问
题。每一个 kv 块对应的结构如下面的代码中的zslnode结构,kv header 也是这个结构,
只不过 value 字段是 null 值——无效的,score 是 Double.MIN_VALUE,用来垫底的。
kv 之间使用指针串起来形成了双向链表结构,它们是 有序 排列的,从小到大。不同的 kv
层高可能不一样,层数越高的 kv 越少。同一层的 kv 会使用指针串起来。每一个层元素的
遍历都是从 kv header 出发。
struct zslnode {
string value;
double score;
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map<string, zslnode*> ht; // hash 结构的所有键值对
}
2、跳跃表描述:
- 一个跳跃列表由几层组成
- 底层包含所有元素
- 每一层都是一个有序链表
- 在层 i 中的元素按某个固定的概率 p (通常为0.5或0.25)出现在层 i+1 中(也就是 说高层中的元素必然在低层)
- 第i层的某个元素可以向下访问与它有相同值的下层节点
level 4:1
level 3:1-----4—6
level 2:1—3-4—6-----9
level 1:1-2-3-4-5-6-7-8-9-10
3、查找过程
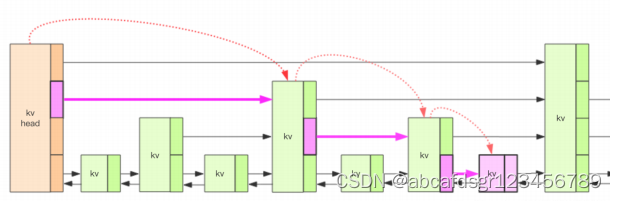
A、如果要定位到全紫色的kv,需要从header的最高层遍历找到第一个节点(最后一个比我
小的元素),然后从这个节点开始降一层再遍历找到第二个节点(最后一个比我小的元
素),然后一直降到最底层进行便利就找到了期望的节点(最底层的最后一个比我小的元
素)
B、将中间经过的一系列节点称为"搜索路径",他是从最高层一直到最底层的每一层最后一
个比我小的元素节点列表
C、有了这个搜索路径就可以插入新节点了,跳跃列表使用随机算法其实是来分配新节点插
入的层数
4、随机层数
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
A、对于每一个新插入的节点,都需要调用一个随机算法分配一个合理的层数;直观上期忘
的目标是50%的Level1,25%的Level2,12.5%的Level3,一直到最顶层2^-63,每一层的
晋升概率是50%(上一层概率的50%)
B、Redis标准源码中的晋升概率只有25%,也就是代码中的ZSKIPLIST_P的值;所以官方的(Redis官方)的跳跃列表更加扁平化,层高相对较低,在单个层上需要遍历的节点数量会稍微多一些
C、因为层数一般不高,所以在遍历的时候从顶层开始往下遍历会非常浪费;跳跃列表会记
录当前的最高层书maxLevel,遍历是从这个maxLevel开始遍历性能就会提高很多
5、插入过程
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
// 存储搜索路径
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 存储经过的节点跨度
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
// 逐步降级寻找目标节点,得到「搜索路径」
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 如果score相等,还需要比较value
while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))){
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
// 正式进入插入过程
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
// 随机一个层数
level = zslRandomLevel();
// 填充跨度
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新跳跃列表的层高
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,ele);
// 重排一下前向指针
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 重排一下后向指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
首先我们在搜索合适插入点的过程中将「搜索路径」摸出来了,然后就可以开始创建新节点
了,创建的时候需要给这个节点随机分配一个层数,再将搜索路径上的节点和这个新节点通
过前向后向指针串起来。如果分配的新节点的高度高于当前跳跃列表的最大高度,就需要更
新一下跳跃列表的最大高度。
6、删除过程
删除过程和插入过程类似,都需先把这个「搜索路径」找出来。然后对于每个层的相关节点
都重排一下前向后向指针就可以了。同时还要注意更新一下最高层数maxLevel。
7、更新过程
当我们调用 zadd 方法时,如果对应的 value 不存在,那就是插入过程。如果这个 value
已经存在了,只是调整一下 score 的值,那就需要走一个更新的流程。假设这个新的 score
值不会带来排序位置上的改变,那么就不需要调整位置,直接修改元素的 score 值就可以
了。但是如果排序位置改变了,那就要调整位置。那该如何调整位置呢?
/* Remove and re-insert when score changes. */
if (score != curscore) {
zskiplistNode *node;
serverAssert(zslDelete(zs->zsl,curscore,ele,&node));
znode = zslInsert(zs->zsl,score,node->ele);
/* We reused the node->ele SDS string, free the node now
* since zslInsert created a new one. */
node->ele = NULL;
zslFreeNode(node);
/* Note that we did not removed the original element from
* the hash table representing the sorted set, so we just
* update the score. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
*flags |= ZADD_UPDATED;
}
return 1;
一个简单的策略就是先删除这个元素,再插入这个元素,需要经过两次路径搜索。Redis 就
是这么干的。 不过 Redis 遇到 score 值改变了就直接删除再插入,不会去判断位置是否需
要调整,从这点看,Redis 的 zadd 的代码似乎还有优化空间。关于这一点,读者们可以继
续讨论。
8、如果 score 值都一样呢?
在一个极端的情况下,zset 中所有的 score 值都是一样的,zset 的查找性能会退化为 O(n)
么?Redis 作者自然考虑到了这一点,所以 zset 的排序元素不只看 score 值,如果 score
值相同还需要再比较 value 值 (字符串比较)。
9、元素排名是怎么算出来的?
前面我们啰嗦了一堆,但是有一个重要的属性没有提到,那就是 zset 可以获取元素的排名
rank。那这个 rank 是如何算出来的?如果仅仅使用上面的结构,rank 是不能算出来的。
Redis 在 skiplist 的 forward 指针上进行了优化,给每一个 forward 指针都增加了 span
属性,span 是「跨度」的意思,表示从当前层的当前节点沿着 forward 指针跳到下一个节
点中间跳过多少个节点。Redis 在插入删除操作时会小心翼翼地更新 span 值的大小。
struct zslforward {
zslnode* item;
long span; // 跨度
}
struct zslnode {
String value;
double score;
zslforward*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
这样当我们要计算一个元素的排名时,只需要将「搜索路径」上的经过的所有节点的跨度
span 值进行叠加就可以算出元素的最终 rank 值。














 5813
5813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









