







1、快速掌握Elasticsearch节点知识,增删查改后台过程。
节点,分片和副本的关系
如果你的索引也如常见的那样是偏向查询使用的,那你可以通过增加副本的数目来提升查询性能,但也要为此 _增加额外的硬件资源_。
一个拥有两个主分片一份副本的索引可以在四个节点中横向扩展
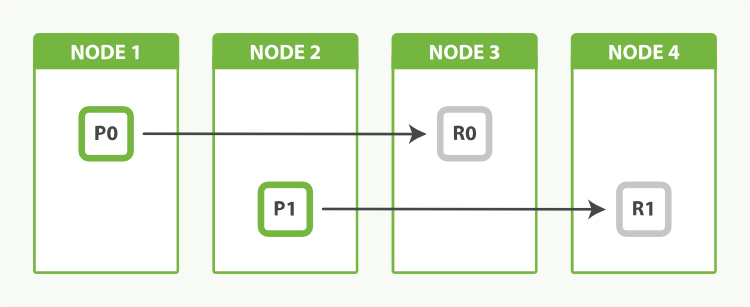
通过调整副本数来均衡节点负载

![]()
事实上节点 3 持有两个副本分片,然而没有主分片并不重要。副本分片与主分片做着相同的工作;它们只是扮演着略微不同的角色。没有必要确保主分片均匀地分布在所有节点中。
节点角色分工
Master节点
1)Master节点控制Elasticsearch集群,并负责在集群范围内创建/删除索引,跟踪哪些节点是集群的一部分,并将分片分配给这些节点。主节点一次处理一个集群状态,并将状态广播到所有其他节点,这些节点需要响应并确认主节点的信息。
2)在elasticsearch.yml中,将nodes.master属性设置为true(默认),可以将节点配置为有资格成为主节点的节点。
3)对于大型生产集群,建议拥有一个专用主节点来控制集群,并且不服务任何用户请求。
Data节点
1)数据节点用来保存数据和倒排索引。默认情况下,每个节点都配置为一个data节点,并且在elasticsearch.yml中将属性node.data设置为true。如果您想要一个专用的master节点,那么将node.data属性更改为false。
Client节点
1)如果将node.master和node.data设置为false,则将节点配置为客户端节点,并充当负载平衡器,将传入的请求路由到集群中的不同节点。
2)若你连接的是作为客户端的节点,该节点称为协调节点(coordinating node)。协调节点将客户机请求路由到集群中对应分片所在的节点。对于读取请求,协调节点每次选择不同的分片来提供请求以平衡负载。
3)在我们开始审查发送到协调节点的CRUD请求如何通过集群传播并由引擎执行之前,让我们看看Elasticsearch如何在内部存储数据,以低延迟为全文搜索提供结果。
write/create

delete/update
每个分段(segment)都有一个.del文件与它相关联。当发送删除请求时,该文档未被真正删除,而是在.del文件中标记为已删除。此文档可能仍然能被搜索到,但会从结果中过滤掉。当分段合并时(我们将在后续的帖子中包括段合并),在.del文件中标记为已删除的文档不会被包括在新的合并段中。
read
读操作由两个阶段组成:
- 查询阶段(Query Phase)
- 获取阶段(Fetch Phase)

搜索相关性(Search Relevance)
相关性由Elasticsearch给予搜索结果中返回的每个文档的分数确定。用于评分的默认算法为tf / idf(术语频率/逆文档频率)。
2、细致掌握Elasticsearch的各种高级核心知识点,包括乐观锁并发控制,mget+bulk批处理,零停机场景下重建索引,dynamic mapping模板定制,分词器定制。
乐观锁的原因和控制
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
es大部分场景下都是一个读多写少的系统,如果按照悲观锁的策略,会大大降低es的吞吐。
解决办法:
如果仅仅增量的累加或者累减操作,不关注顺序,关注最终结果,我们可以使用es服务端保证冲突重试就行,这样非常方便的就解决了并发冲突问题,如果关注增量顺序,比如索引和更新操作默认采用的最后的数据覆盖以前的数据,如果冲突了我们可以使用version字段来处理冲突问题,此外version可以使用es内部维护的version值,也可以使用我们外部应用传过来的值,并指定version去使用乐观锁进行更新。
https://blog.csdn.net/u010454030/article/details/60969509
mget和bulk
mget就是可以一个请求获得不同index或者不同type,多个doc id的方法。bulk就是批量插入数据。
https://www.cnblogs.com/pyspark/p/8717300.html
零停机重建索引(https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-aliases.html)
使用的技术:别名和reindex
背景:
索引 别名 就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。别名 带给我们极大的灵活性,允许我们做下面这些:
- 在运行的集群中可以无缝的从一个索引切换到另一个索引
- 给多个索引分组 (例如,
last_three_months) - 给索引的一个子集创建
视图
即使你认为现在的索引设计已经很完美了,在生产环境中,还是有可能需要做一些修改的。
做好准备:在你的应用中使用别名而不是索引名。然后你就可以在任何时候重建索引。别名的开销很小,应该广泛使用。
步骤:
1.创建索引 my_index_v1 ,然后将别名 my_index 指向它
PUT /my_index_v1
PUT /my_index_v1/_alias/my_index
2.我们用新映射创建索引 my_index_v2
3.reindex接口把旧索引数据搬到新索引
Reindex does not attempt to set up the destination index. It does not copy the settings of the source index. You should set up the destination index prior to running a _reindex action, including setting up mappings, shard counts, replicas, etc.
POST _reindex
{
"source": {
"index": "source",
"size": 5000
},
"dest": {
"index": "dest",
"routing": "=cat"
}
}
4.将别名指向新的索引
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
ps:routing路由机制的总结
实际上,如果不明确指明使用路由机制,实际上路由机制也是在发挥作用的,只是默认的路由值是文档的id而已。而个性化路由的需求主要是和业务相关的。默认的路由(如果是自动的生成的id)直观上会把所有的文档随机分配到一个分片上,而个性化的路由值就是和业务相关的了。这也会造成一些潜在的问题,比如user123本身的文档就非常多,有数十万个,而其他大多数的用户只有几个文档,这样的话就会导致user123所在的分片较大,出现数据偏移的情况,特别是多个这样的用户处于同一分片的时候,现象会更明显。具体的使用还是要结合实际的应用场景来选择的。
Dynamicmapping动态映射和自定义的时候可以决定分词器
当 Elasticsearch 遇到文档中以前 未遇到的字段,它用 dynamic mapping 来确定字段的数据类型并自动把新的字段添加到类型映射。自定义动态映射:https://www.elastic.co/guide/cn/elasticsearch/guide/current/custom-dynamic-mapping.html#custom-dynamic-mapping
3、深入理解Elasticsearch的各种核心原理,包括分布式架构原理,分布式文档系统原理,分布式搜索引擎原理,内核级原理。
我的理解,分布式架构原理是指节点角色,路由,分片和副本的解释?分布式文档系统是指存储层使用的是基于本地文件的分片和副本的解释?分布式搜索引擎是指增删查改过程?内核级原理是指下面这个?cordination node->route->primary node->memory buffer and trans log cache->sync to replicas->return total success->refresh to file cache at primary/replicas every 1s(can search)->flush file cache evey 30s to disk segement file and trans log commit to disk every 5s(so if server down maybe lost 5s data)->clear trans log every 30s and segement merge
PS:分布式搜索引擎->elasticsearch(它和分布式文档系统是不同维度的,不能与之比较。不过它主要使用基于本地文件,那可以和hbase这种基于共享存储系统比较,详看https://blog.csdn.net/abcd1101/article/details/89072484)
ps:可以通过 NFS gateway 将HDFS挂在到es 数据结点,然后为每个结点分配一个目录。 不过elasticsearch这样的准实时搜索引擎并不适合使用HDFS作存储,延时太大,对性能影响太大
纵向的架构:
















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









