






摘要:
1,Treap的介绍
2,Treap节点的插入
3,Treap节点的删除
4,Treap和笛卡尔树的区别
1,Treap的介绍
Treap又叫树堆,属于一种自平衡二叉搜索树,是由单词Tree和Heap构成,是一种具有二叉搜索树和堆两种数据结构的特性。在前面我们讲过《笛卡尔树》,它也是一种具有二叉搜索树和堆的两种数据结构的特性,关于它俩的区别我们后面在介绍。
我们知道如果随机使用一组数据创建二叉搜索树,则二叉搜索树很可能会退化成一个链表,增加了操作的时间复杂度。这个时候我们可以给每个节点随机生成一个优先级,这个优先级要满足堆的特性。因为是随机生成的,所以从概率上来说退化成链表的可能性就非常小。
Treap在节点插入和删除的时候也会进行旋转,因为它不是高度平衡的,所以Treap比我们前面讲的《AVL树》要简单很多,在讲解之前我们先来看下Treap的节点类。
Java 代码:
class TreapNode {
int key, priority;
TreapNode left, right;
public TreapNode(int key) {
this.key = key;
// 节点优先级,满足堆的特性,随机生成的
this.priority = new Random().nextInt();
this.left = this.right = null;
}
}C++ 代码:
struct TreapNode {
int key, priority;
TreapNode *left = nullptr;
TreapNode *right = nullptr;
// 节点优先级priority,满足堆的特性,随机生成的
TreapNode(int key) : key(key), priority(rand()) {}
};节点类中有一个优先级priority,它是随机生成的,要满足堆的特性,这里我们使用最大堆,堆顶元素是优先级最高的。
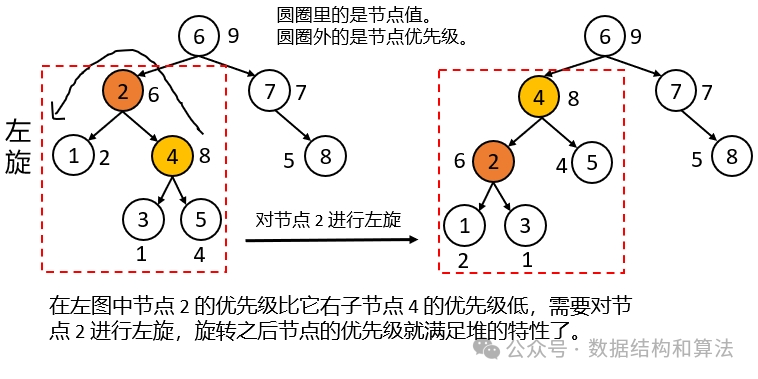
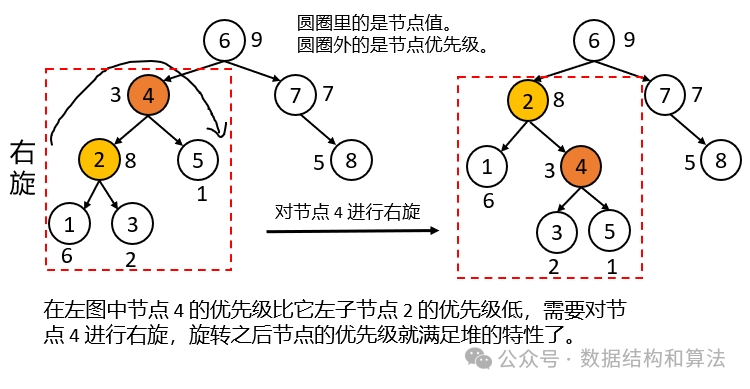
再来看下节点的旋转,旋转不会改变二叉搜索树的特性,但会改变堆的特性,旋转的目的就是把优先级高的节点往上调整,优先级低的节点往下调整,这和我们前面讲的《数据结构堆》类似,不过在堆中是直接交换,不是通过旋转。
















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











