






假设100w数据, 会员数量5w, 订单状态8个, 查询某会员某个订单状态的某时间区间内的订单, 以及某个订单状态下的订单数量, 索引如何建?
建数据
先来建个table吧:
USE `test`;
CREATE TABLE `test_index`(
`order_id` int unsigned NOT NULL AUTO_INCREMENT,
`user_id` int unsigned NOT NULL COMMENT '用户id',
`status_id` tinyint NOT NULL COMMENT '状态id: 1-8',
`create_time` int NOT NULL,
PRIMARY KEY(`order_id`)
) ENGINE=InnoDB COMMENT '索引测试';
除了PK, 我们先不建索引.
以每秒写入5个订单进行数据模拟, 先写个存储过程:
USE test;
DROP PROCEDURE IF EXISTS `mysp_test_index`;
DELIMITER $$
CREATE PROCEDURE `mysp_test_index`(IN count int)
BEGIN
DECLARE $order_id_max int DEFAULT 0;-- 用这个来确定新的 create_time
DECLARE $create_time INT;
DECLARE $i INT;
SET $order_id_max = (SELECT MAX(order_id) AS order_id FROM `test_index` );
IF $order_id_max IS NULL THEN
SET $create_time = unix_timestamp('2020-1-1'); -- 设置初始值
ELSE
SET $create_time = (SELECT create_time FROM `test_index` WHERE order_id=$order_id_max) + 1;
END IF;
SET $i = 0;
WHILE $i < count*2 DO
INSERT INTO `test_index`(`user_id`, `status_id`, `create_time`)
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+0 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+0 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+0 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+0 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+0 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+1 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+1 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+1 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+1 AS `create_time`
UNION ALL
SELECT ROUND(rand() * 50000) + 1 AS `user_id`, ROUND(rand() * 7) + 1 AS `status_id`, $create_time + $i+1 AS `create_time`;
SET $i = $i + 2;
END WHILE;
END
$$
DELIMITER ;
调用存储过程, 直接CALL:
CALL mysp_test_index(100000);
执行了10w次, 每次写入10笔订单, 刚好100w笔订单.
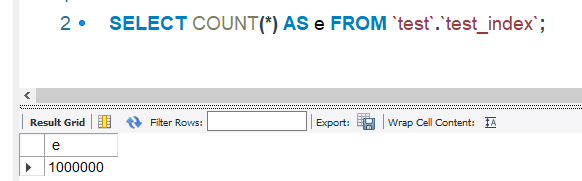
好了, 数据就绪.
查看数据分布
我们先看下插入的时间段:
SELECT from_unixtime(MIN(create_time), '%Y-%m-%d %H:%i') AS t_min
,from_unixtime(MAX(create_time), '%Y-%m-%d %H:%i') AS t_max
FROM `test`.`test_index`;
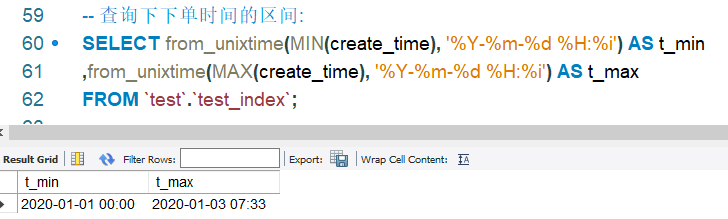
下单时间区间: 2020-01-01 00:00 ~ 2020-01-03 07:33
再来查询一下会员的订单数量分布:
SELECT user_id, COUNT(*) AS e FROM `test`.`test_index` GROUP BY user_id ORDER BY e DESC ;
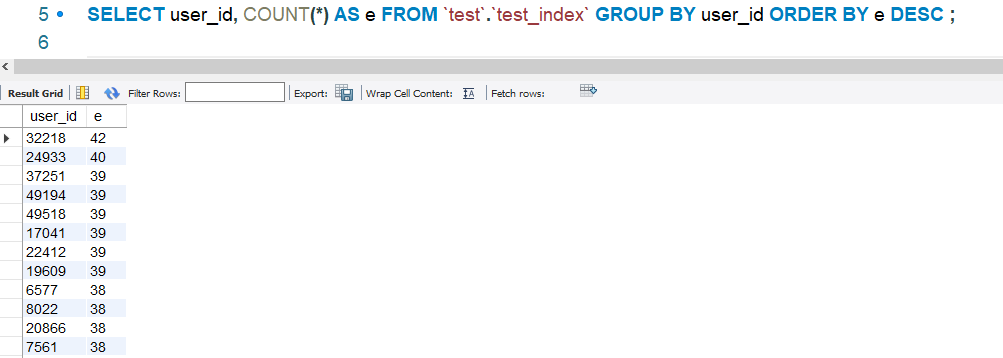
就以订单数量最多的那个用户来查询吧, 这里user_id=32218
建索引, 查询
创建联合索引:
USE test;
ALTER TABLE `test_index`
ADD INDEX IX_user_id_status_id_create_time(`user_id`, `status_id`, `create_time`);
在这个业务场景中, user_id 过滤后的结果是比status_id过滤后的结果数量小很多的.
OK, 来看下第一个问题"查询某会员某个订单状态的某时间区间内的订单"的SQL
SELECT * FROM `test_index`
WHERE user_id=32218 AND status_id=1
AND create_time BETWEEN unix_timestamp('2020-1-1 03:00') AND unix_timestamp('2020-1-3 6:00');
先看下mysql查询引擎对这个SQL的查询优化: 
从上图可以看到, 因为不是唯一索引, 所以走了联合索引的范围扫描.
实际的执行速度还是很快的.
第二个问题, "某个订单状态下的订单数量"
SELECT SQL_NO_CACHE COUNT(*) FROM `test_index` WHERE status_id=1;
查询的执行计划如下, 按目前的索引设置, 因为索引的第一列不是status_id, 会进行整个索引的扫描.
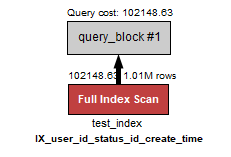
再加上时间区间, 执行计划还是一样的:
SELECT SQL_NO_CACHE COUNT(*) FROM `test_index` WHERE status_id=1
AND create_time BETWEEN unix_timestamp('2020-1-1 03:00') AND unix_timestamp('2020-1-3 6:00');
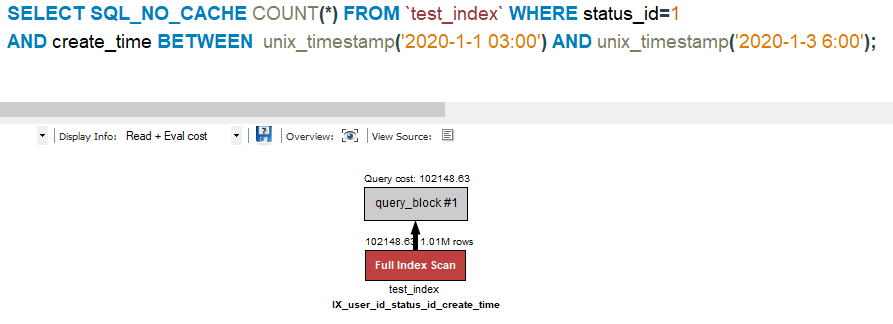
So, 仅仅依靠这一个联合索引, 在很多业务场景下效率还是很慢.
调整索引顺序
我们把user_id和status_id对调
ALTER TABLE `test_index`
DROP INDEX IX_user_id_status_id_create_time,
ADD INDEX IX_status_id_user_id_create_time(`status_id`, `user_id`, `create_time`);
查下查询计划:

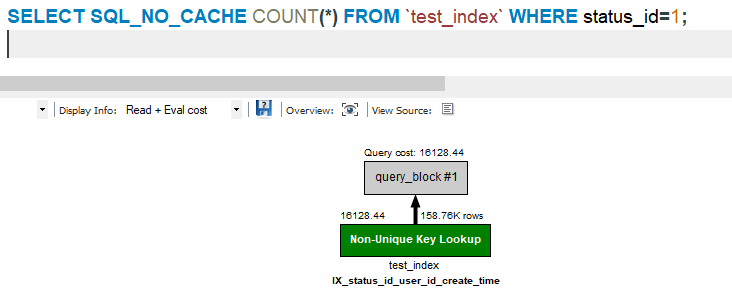

未完待续...















 3326
3326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









