






基于 ES 7.7, 官方文档
主要内容:
- Update index settings: 修改索引的设置
- Get index settings: 获取索引的设置
- Analyze: 分析(分析器, 分词器)
1. 修改索引的设置
PUT /<index>/_settings
{
}
路径参数
<index>
(可选, String) 支持多个索引名称的英文逗号分割,以及通配符的表达式。
如果要修改所有的索引的设置,可以使用_all或者直接忽略该参数。
# 修改单个索引
PUT /index1,index2/_settings
# 同时修改多个索引
PUT /index1,index2/_settings
PUT /user*/_setting
# 同修修改索引的设置
PUT /_all/_settings
PUT /_settings
查询参数
allow_no_indices
(可选, bool) 如果设置为true,则当全部使用通配符*、_all只检索不存在(missing)或者已关闭(closed)的索引时,不会抛出错误。
此参数也适用于指向不存在(missing)或者已关闭(closed)的索引的别名。
默认false。
expand_wildcards
(可选, String) 通配符查询时的范围限制。支持多个条件的逗号分割。
- all: 匹配open和closed的索引, 包括隐藏的
- open: 表示只查询开放中的索引
- closed: 只匹配closed的
- hidden: 隐藏的(hidden)索引,必须和open/closed联合使用
- none: 不接受通配符
默认 open。
flat_settings
(可选, bool) 是否以平面格式返回settings信息。默认false。
ignore_unavailable
(可选, bool) 如果为true, missing或closed的索引不会包括在返回数据中。默认false。
preserve_existing
(可选, bool) 如果为true, 则指定的索引已存在的设置保持不变。默认false。
master_timeout
(可选,时间单位)连接到主节点的等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。
timeout
(可选,时间单位) 等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。
Request body
settings
(可选) 索引配置的选项。参考索引设置(Index Settings)
几个栗子
1. 重置一个设置 (Reset an index setting)
如果要把索引的某一项设置还原为默认值, 只要把这个选项设置为 null 即可。
PUT /twitter/_settings
{
"index" : {
"refresh_interval" : null
}
}
可以在索引模块(Index modules) 中找到可以动态修改的设置的列表, 这些设置都可以在活动的索引(live index)上动态更新。要保持现有设置不被更新,可以在请求参数中把preserve_existing设置为true。
2. 批量索引的使用(Bulk indexing usage)
这个应该是我们在需要批量更新文档时, 先禁用该索引的索引更新工作, 文档更新后再恢复索引更新。因为ES默认会在文档更新后, 在索引周期内(1s)即开始执行索引更新。类似在mysql中我们批量插入数据前, 把索引禁用掉,以提高数据更新和索引更新的性能。 For example, the update settings API can be used to dynamically change the index from being more performant for bulk indexing, and then move it to more real time indexing state. Before the bulk indexing is started, use:
例如, 更新设置api可以动态修改索引的设置以使批量索引更高效, 然后再改回更实时的索引状态。在批量索引开始前, 我们使用:
PUT /twitter/_settings
{
"index":{
"refresh_interval": "-1"
}
}
(另一个优化方式是在没有任何副本的情况下启动索引,然后再添加副本,但是要根据实际情况决定是否适用。)
Then, once bulk indexing is done, the settings can be updated (back to the defaults for example):
当批量索引执行完毕, 再执行如下代码还原设置:
# 官方文档中设置的是 "1s", 其实ES默认就是1s
PUT /twitter/_settings
{
"index":{
"refresh_interval": null
}
}
再执行强制合并(force merge):
# 强制合并分段, 把一个分片的Lucene分段设置为5
POST /twitter/_forcemerge?max_num_segments=5
WHY? 为什么要合并? 官方文档未做说明! TODO 有理解的说一下
3. 更新索引分析(Update index analysis)
索引的分析器(analyzer)是静态设置,不能动态修改,只能在关闭的(closed)索引上定义新的分析器。
要给索引添加一个分析器, 你必须先关闭索引,然后定义分析器,再重新打开索引。
ES 7.15版本新增了提示: 不能关闭数据流(data stream)的写索引(write index)。更多内容参考7.15版本文档
比如, 给索引twitter添加一个分析器content:
# 关闭索引
POST /twitter/_close
# 添加分析器: 一个自定义的名字叫`content`的分析器, 然后可以在mapping中使用
PUT /twitter/_settings
{
"analysis":{
"analyzer":{
"content":{
"type":"custom",
"tokenizer":"whitespace"
}
}
}
}
# 重新打开索引
POST /twitter/_open
关于分析器的简单知识, 本篇第三部分会翻译, 或者参考 这里
2. 获取索引的设置
返回索引的设置信息。原官方英文文档
GET /<index>/_settings
GET /<index>/_settings/<setting>
路径参数
<index>
(可选, String) 支持多个索引名称的英文逗号分割,以及通配符表达式。
如果要修改所有的索引的设置,可以使用_all或者直接忽略该参数。
<setting>
(可选, String) 支持多个配置名称的英文逗号分割,以及通配符表达式。
查询参数
allow_no_indices
(可选, bool) 如果设置为true,则当全部使用通配符 *、_all只检索不存在(missing)或者已关闭(closed)的索引时,不会抛出错误。
此参数也适用于指向不存在(missing)或者已关闭(closed)的索引的别名。
默认true。
expand_wildcards
(可选, String) 通配符查询时的范围限制。支持多个条件的逗号分割。
- all: 匹配open和closed的索引, 包括隐藏的
- open: 表示只查询开放中的索引
- closed: 只匹配closed的
- hidden: 隐藏的(hidden)索引,必须和open/closed联合使用
- none: 不接受通配符
默认 all。
flat_settings
(可选, bool) 是否以平面格式返回settings信息。默认false。
include_defaults
(可选, bool) 如果为true,则返回信息中包含所有的默认的设置。默认 false。
ignore_unavailable
(可选, bool) 如果为true, missing或closed的索引不会包括在返回数据中。默认false。
local
(可选, bool) 如果为true, 则只从本地节点获取信息。默认false, 表示从主节点获取信息。
master_timeout
(可选,时间单位)连接到主节点的等待超时时间。如果在超时时间已过之前没有响应, 则返回错误。 默认是值 30s。
几个栗子
# 获取单个索引的设置
GET /twitter/_settings
# 获取单个索引的设置, 包含所有索引的默认配置
GET /twitter/_settings?include_defaults=true
# 获取多个索引的配置
GET /twitter,twitter1/_settings
# 通配符获取多个索引的配置
GET /twitter*/_settings
# 获取所有索引的设置
GET /_all/_settings
GET /_settings
# 获取索引的部分设置
GET /twitter/_settings/index.number*?include_defaults=true
# 获取索引的部分设置, 包含所有索引的默认配置
GET /twitter/_settings/index.number*?include_defaults=true
3. 分析(Analyze)
获取字符串分析(分词)的结果。原官方英文文档
GET|POST /_analyze
GET|POST /<index>/_analyze
路径参数
<index>
(可选, String) 指定要获取分析器的索引。
如果设置了参数analyzer或field, 也指定了索引,则前者会覆盖这个设置,即: analyzer指定的分析器或field字段mapping中配置的分析器会被调用, 而不会调用该索引的默认分析器。
如果没有指定analyzer和field, 则该api会使用该索引默认的分析器。
如果没有指定索引, 或者指定的索引没有默认的分析器, 则该api会使用标准分析器(standard analyzer)。
查询参数
我觉得这几个参数不应该属于 Query parameter, 而应该属于 Request Body
analyzer
(可选, String) 用于分析给定文本的分析器的名称。它可以是一个内置的分析器, 或者是索引中配置的一个分析器。
如果该参数未指定,则会使用字段中的mapping中定义的分析器。
如果字段未指定,则会使用索引的默认的分析器。
如果索引未指定,或者指定的索引没有默认的分析器,则会使用标准分析器(standard analyzer)。
attributes
(可选, 字符串数组) 用于过滤explain参数输出的token属性数组。TODO
char_filter
(可选, 字符串数组) 在分词器处理之前,预先过滤字符的字符过滤器数组。更多参考字符过滤器(character filters)
explain
(可选, bool) 如果为true, 则返回数据中包含token属性和额外的细节。默认false。
field
(可选, String) 用于指定分析器的字段, 必须指定索引名称。
如果指定了字段, 则仍然会被参数analyzer所指定的分析器覆盖。
如果没有指定, 则使用素银的默认的分析器。
如果没有指定索引,或者指定的索引没有默认的分析器, 则会使用标准分析器。
filter
(可选, 字符串数组) 用于在分词器执行之后的token过滤数组。参考 Token Filters
normalizer
(可选, String) 用于把文本转换为一个单独的token的标准化配置。参考 Normalizers
text
(必填, String或者String数组) 要分析的文本。如果提供的是一个字符串数组, 则被当做一个多值(multi-field)的字段来分析。
tokenizer
(可选, String) 把文本转换为token的分词器。参考Tokenizer。
优先级顺序是:参数
analyzer指定的分析器 > 参数field配置的分析器 > 索引的默认分析器 > 标准分析器
几个栗子
1. 不指定索引(No index specified)
可以使用任何一个内建的分析器分析文本,而不用指定索引。
# 只要指定analyzer即可, 而不需要指定索引
GET /_analyze
{
"analyzer":"standard",
"text": "elastic search"
}
返回的值的tokens是一个json数组:
{
"tokens" : [
{
"token" : "elastic",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "search",
"start_offset" : 8,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
2. 字符串数组
如果参数text给的是一个字符串数组, 则会被当做一个multi-value的字段来分析。
GET /_analyze
{
"analyzer":"standard",
"text": ["elastic search", "ik smart"]
}
返回数据的格式与使用一个字符串当参数时是一致的,都是json数组。(不是一个对应字符串数组的json数组的数组)
ES的
text类型的字段是可以直接存储字符串数组的
{
"tokens" : [
{
"token" : "elastic",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "search",
"start_offset" : 8,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "ik",
"start_offset" : 15,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "smart",
"start_offset" : 18,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
3.自定义分析器
可以使用tokenizers、token过滤器和字符过滤器(char filters)构建一个自定义的临时的分析器。token过滤器使用参数filter。
# 使用的分词器是keyword(不像text那样会分词), 把tokens转为小写
GET /_analyze
{
"tokenizer":"keyword",
"filter": ["lowercase"],
"text": "I am Tom"
}
执行结果, 仅仅是把tokens转成了小写而已:
{
"tokens" : [
{
"token" : "i am tom",
"start_offset" : 0,
"end_offset" : 8,
"type" : "word",
"position" : 0
}
]
}
下面这个例子, 在调用分词器之前使用了char_filter(html_strip)过滤了html标签:
GET /_analyze
{
"tokenizer":"keyword",
"filter": ["lowercase"],
"char_filter": ["html_strip"],
"text": "I am <b>Tom</b>"
}
如果分词器换成 standard:
GET /_analyze
{
"tokenizer":"standard",
"filter": ["lowercase"],
"char_filter": ["html_strip"],
"text": "I am <b>Tom</b>"
}
先把tokens转为小写, 再移除html标签, 最后分词, 执行结果是:
{
"tokens" : [
{
"token" : "i",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "am",
"start_offset" : 2,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "tom",
"start_offset" : 8,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
也可以指定分词器(tokenizers)、token filters、character filters,比如:
GET /_analyze
{
"tokenizer": "whitespace",
"filter": [
"lowercase", {
"type": "stop",
"stopwords": ["a", "is", "this"]
}],
"text": "This is ONLY a test"
}
这个例子中, 我们使用空格(whitespace)分词器, 把tokens转小写, 写设置了三个停止词, 执行结果是:
{
"tokens" : [
{
"token" : "only",
"start_offset" : 8,
"end_offset" : 12,
"type" : "word",
"position" : 2
},
{
"token" : "test",
"start_offset" : 15,
"end_offset" : 19,
"type" : "word",
"position" : 4
}
]
}
4. 指定索引(Specific index)
我们可以使用指定索引的默认的分析器来分析文本:
# 使用指定索引的默认的分析器
GET /twitter/_analyze
{
"text": "this is a test"
}
也可以再自行指定另一个分析器:
# 即使指定了索引, 我们坚持使用另一个分析器 whitespace(空格)
GET /twitter/_analyze
{
"analyzer": "whitespace",
"text": "this is a test"
}
5. 使用从字段的mapping中派生出的分析器(Derive analyzer from a filed mapping) 索引twitter中有一个字段city, 我们可直接指定这个字段, 让api使用这个字段的分析器来分词:
GET /twitter/_analyze
{
"field": "city",
"text": "This is a test"
}
如果字段city没有指定分析器, 则会使用索引twitter指定的分析器; 如果索引twitter没有指定分析器, 则会使用standard分析器。
6. 标准化(Normalizer)
ES7.7还没有提供内置的normalizer, 只能在索引的setting中组合 token filters和character filters作为自定义的normalizer. 参考官方文档 normalizers
可以通过与指定索引相关联的normalizer为关键字字段提供一个normalizer。
GET /<index>/_analyze
{
"normalizer" : "<my_normalizer>",
"text" : "BaR"
}
或者, 不指定索引的情况下, 直接通过指定token filters和char filters来构建一个临时的normalizer:
GET /_analyze
{
"filter": ["lowercase"],
"text": "This is a test"
}
7. 解释分析的过程(explain analyze)
如果你想了解更多细节, 设置参数explain为true(默认是false),api会返回每一个token的属性(attributes)。通过设置attributes选项可以过滤token的属性。
下面的例子, 显示 使用分词器“standard”、token过滤器"snowball"(不推荐使用)来分析文本, 并只显示属性"keyword":
GET /_analyze
{
"tokenizer" : "standard",
"filter" : ["snowball"],
"text" : "detailed output",
"explain" : true,
"attributes" : ["keyword"]
}
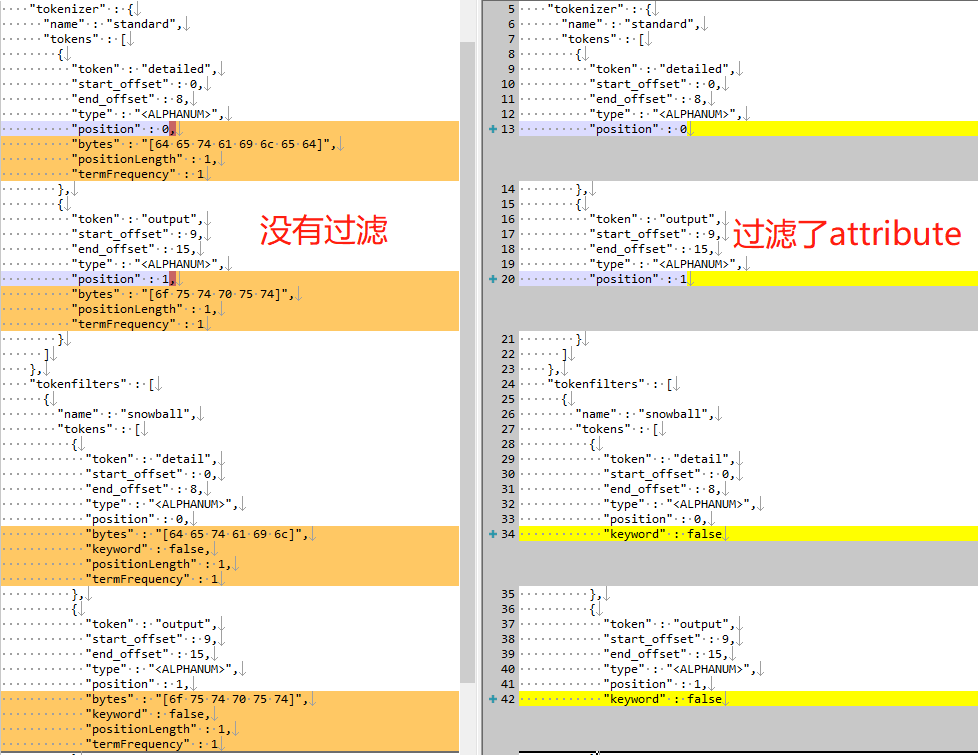
下面的右边是上面代码执行的结果, 左边是没有过滤attributes的结果, 可以查一下差异:
8. 设置token限制
Generating excessive amount of tokens may cause a node to run out of memory. The following setting allows to limit the number of tokens that can be produced:
生成过多的token可能会导致节点内存耗尽。 通过设置index.analyze.max_token_count可以限制生成的token的数量。
我们先查看一下索引的analyze的所有设置:
GET /twitter/_settings/index.analyze.*?include_defaults=true
执行结果:
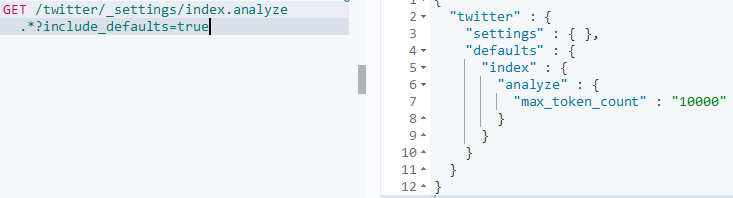
参数index.analyze.max_token_count默认的设置是10000。如果生成的token数量超过这个限制, 就会抛出错误。这个参数可以按索引设置。
那我们现在把索引twitter的这个配置改成 2 吧:
PUT /twitter/_settings
{
"index.analyze.max_token_count": 2
}
然后看一下修改好了没:
GET /twitter/_settings/index.analyze.max_token_count
执行结果:
{
"twitter" : {
"settings" : {
"index" : {
"analyze" : {
"max_token_count" : "2"
}
}
}
}
}
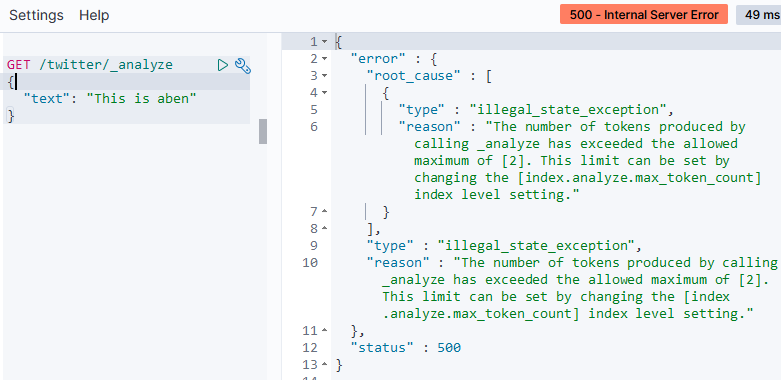
那我们现在再次调用_analyze api接口看会不会报错:
GET /twitter/_analyze
{
"text": "This is aben"
}
我们要分析的这个文本会被拆分成3个token, 这就超出了设置了, 接口抛出了错误:
还原成默认的10000吧:
# 还原设置
PUT /twitter/_settings
{
"index.analyze.max_token_count": null
}
这个
index.analyze.max_token_count参数会影响_analyze接口, 那么会不会影响对该索引的索引操作呢? 如果不小心设置过小, 会导致索引更新失败吗??
last updated at 2021/10/29 23:00















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









