






本文内容来自 https://blog.csdn.net/UbuntuTouch/article/details/99481016 ,有删减和文字修正。
在开始使用ES之前, 请安装好ES & Kibana. 本文仅以win10下的 ElasticSearchS 7.7 版本为例, 不涉及linux系统部分.
ES里的接口都是通过REST接口来实现的,通过HTTP的PUT/GET/POST/DELETE来实现数据的Create/Read/Update/Delete操作,并以JSON数据格式返回。
检查ES及Kibana是否运行正常
浏览器访问 http://localhost:9200 查看ES的状态:
浏览器访问 http://localhost:5601 打开Kibana操作界面(会自动跳转到 http://localhost:5601/app/kibana#/home ), 在欢迎界面的"Try our sample data"和"Explore on my own" 两个按钮中随便选择一个即可。
点击左下角的Dev Tools打开操作界面:
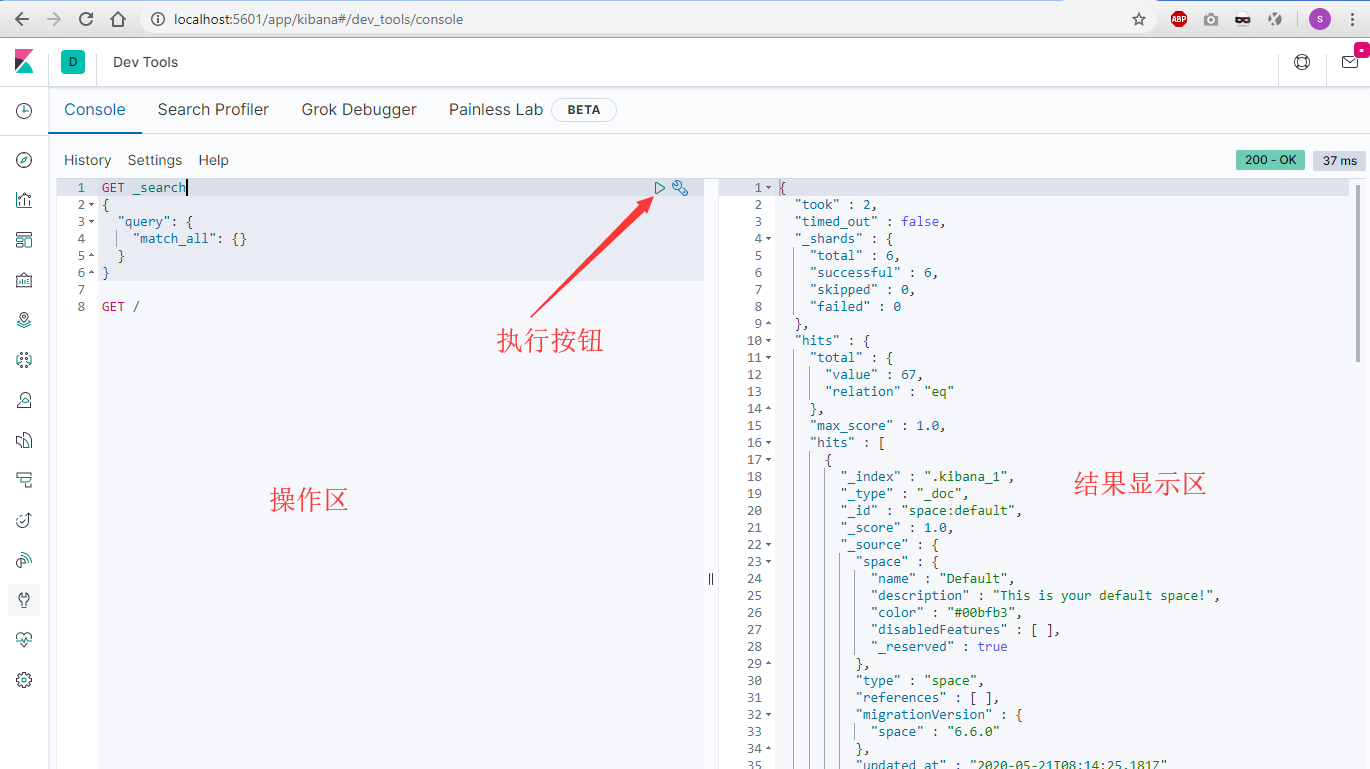
上图是操作界面,右上角的三角按钮是执行当前请求按钮,右边是执行结果显示区。
查看ES信息
就像我们之前在浏览器其中输入地址 http://localhost:9200 看到的效果一样,我们直接输入命令
GET /
执行后可以看到:
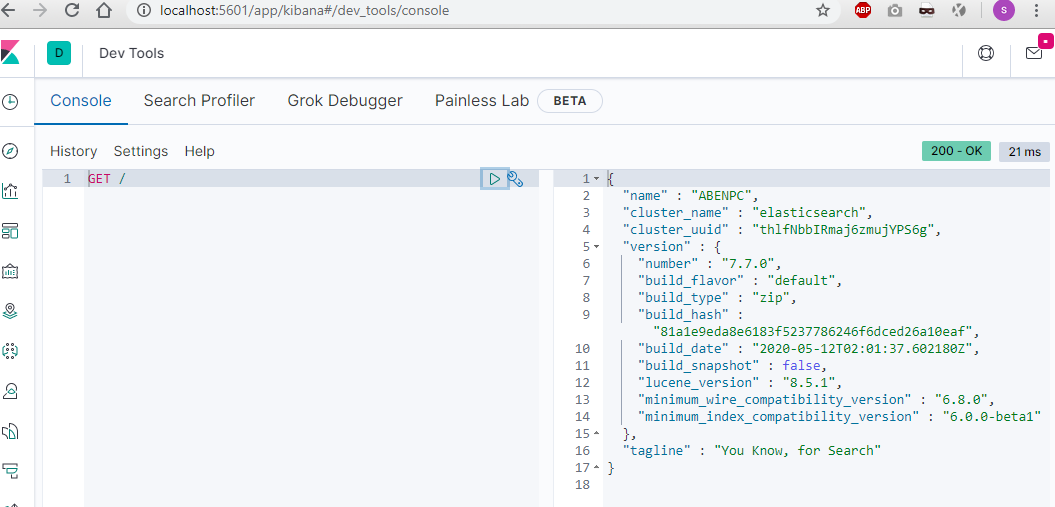
依次显示的是节点名称,集群名称, 集群id,版本号等信息。
在输入时, Kibana会自动提示可以使用的命令

创建一个索引及文档
现在我们来创建一个叫 twitter 的索引(index),并插入一个文档(document)。 在传统的关系型数据库(RDBMS)中, 需要使用专用的语句(DDL)来建立数据库、表,然后才能插入相应的记录。但是对于ES来说, 没有这个必要。我直接在操作区输入一下代码:
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
在右边结果显示区可以看到以下信息:
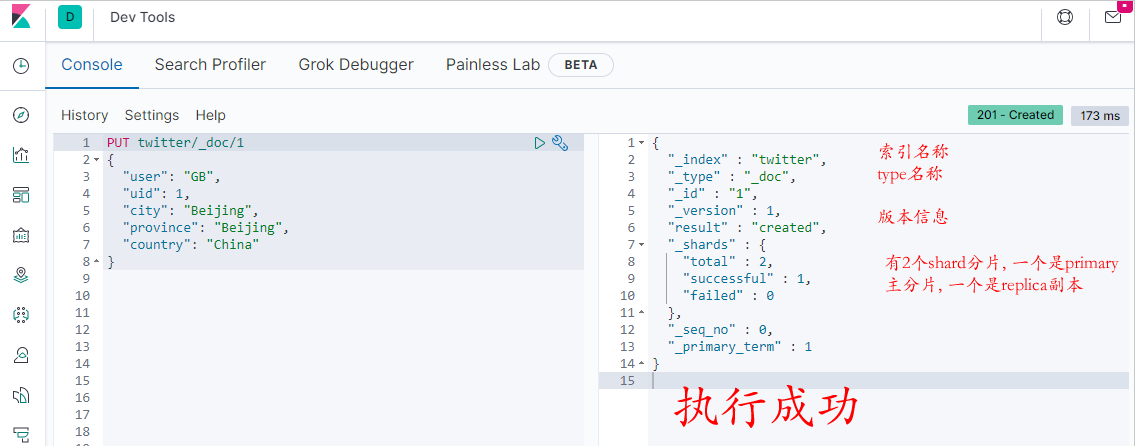
我们已经成功地创建了一个叫做twitter的index。通过这样的方法,我们可以自动创建一个index。如果你不喜欢自动创建index,可以修改如下的一个设置:
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
详细设置请参阅 链接 。如果你你想禁止自动创建索引, 您必须配置action.auto_create_index以允许这些创建以下索引的组件 :
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": ".monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*"
}
如果使用Logstash或Beats,则应在上面的设置 action.auto_create_index 中添加其他索引名称,也可以在config/elasticsearch.yml里进行配置。
通过上面的方法写入到ES的文档,不会在搜索结果中立即显示。这是因为在ES的设计中,有一个叫做 refresh 的操作。它可以使更改可见以进行搜索的操作。通常会有一个refresh timer来定时完成这个操作。这个周期为1秒。这也是我们通常所说的ES可以实现秒级的搜索。当然这个timer的周期也可以在索引的 设置 中进行配置。如果想要写入文档立即显示在搜索结果中,我们可以用如下的方法强制让ES立即进行刷新(refresh):
PUT twitter/_doc/1?refresh=true
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
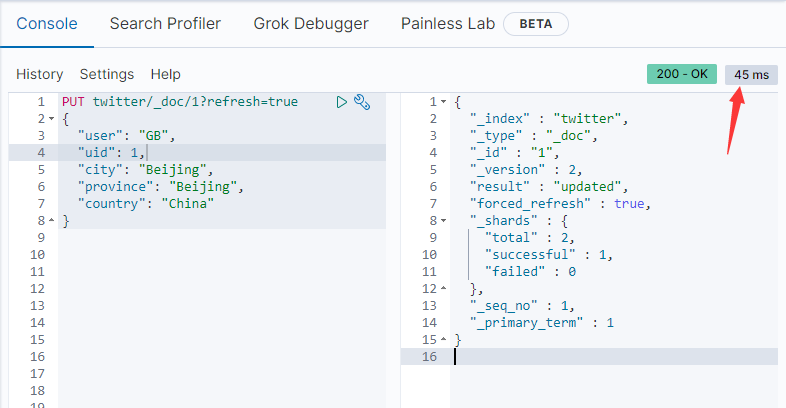
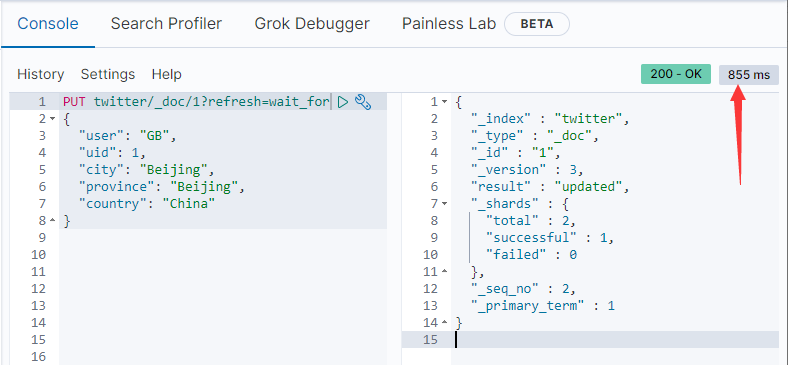
频繁的强制刷新操作会导致ES运行速度变慢。另外一种方式是通过设置 refresh=wait_for 。这相当于一个同步的操作,它需要等待下一个refresh周期发生完后,才返回执行结果。这样可以确保我们在调用上面的接口后,马上可以搜索到刚才录入的文档:
PUT twitter/_doc/1?refresh=wait_for
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
当然我们会发现执行的时间变长了:
更多关于refresh的信息, 请参阅“ Elasticsearch中的refresh和flush操作指南 ”。
上面的文档新增的操作, 创建了一个被叫做 _doc 的 type 。自从ES 6.0以后,一个index只能有一个type。如果我们创建另外一个type的话,系统会抛出错误。在返回信息中有一个 版本 ( _version )的key,默认从1开始,每次更新之后都会增加1。比如我们输入:
POST twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Shenzhen",
"province": "Guangdong",
"country": "China"
}

现在的版本号已经增加到4。每次执行POST或PUT操作后,版本号都会增加1。
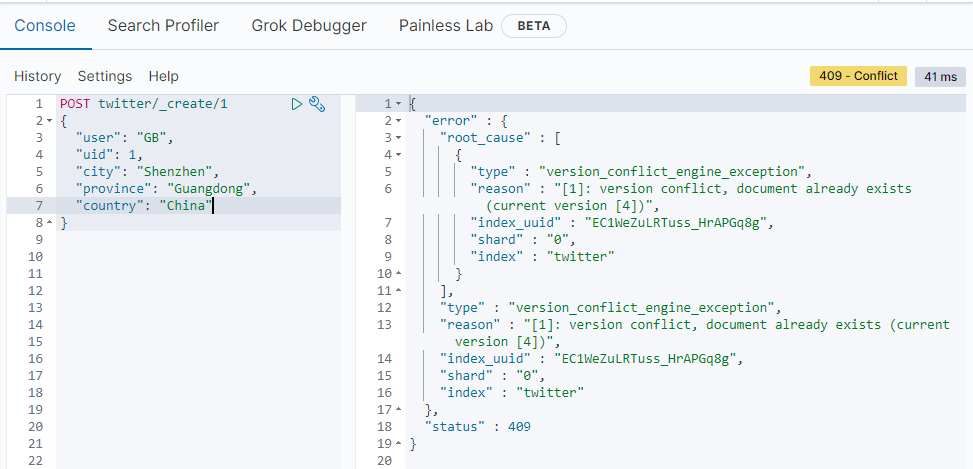
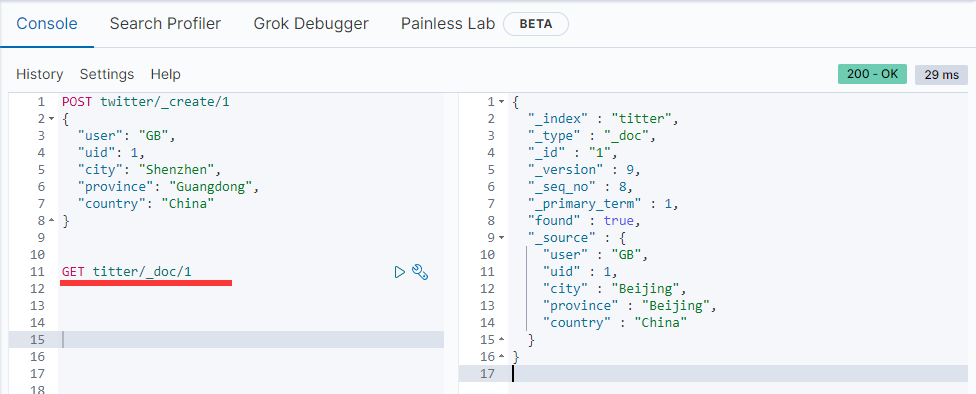
我们还可以使用 _create 接口来实现新增操作:
PUT twitter/_create/1
{
"user": "GB",
"uid": 1,
"city": "Shenzhen",
"province": "Guangdong",
"country": "China"
}
如果文档已经存在,就会返回错误:
也可以在 _doc 请求时带上参数 op_type 以实现与 _create 方法同样的操作:
PUT twitter/_doc/1?op_type=create
{
"user": "双榆树-张三",
"message": "今儿天气不错啊,出去转转去",
"uid": 2,
"age": 20,
"city": "北京",
"province": "北京",
"country": "中国",
"address": "中国北京市海淀区",
"location": {
"lat": "39.970718",
"lon": "116.325747"
}
}
op_type的值有2个: index, create
Kibana的操作界面可以直接复制出来curl的命令:

自动生成ID
上面创建新文档的操作中,我们都指定了文档的id,在实际操作中没必要这样做,反而会因为需要取判断id是否已存在而影响操作速度。ES可以自动帮我们生成一个唯一的id, 但是不能用前面的PUT请求方式, 必须使用POST。why? 因为REST中定义的POST请求是新增操作,而PUT是修改操作。e.g:
POST my_index/_doc
{
"content": "this is really cool"
}
返回结果:
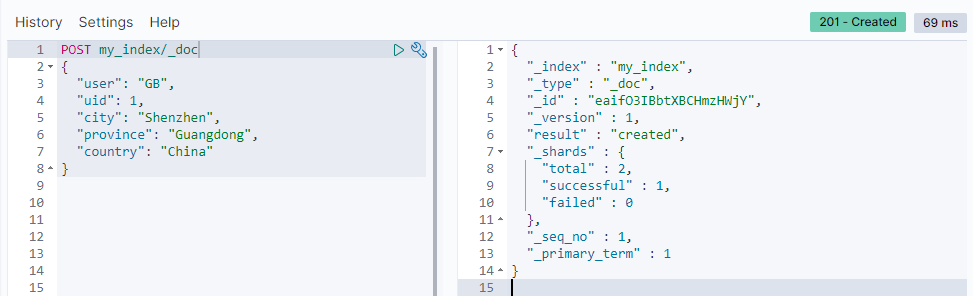
ES已经自动帮我们分配了一个ID。
查看文档
GET twitter/_doc/1
如果文档不存在:

获取部分信息
如果我们只对 source 的内容感兴趣,可以使用:
GET twitter/_doc/1/_source
这样我们直接得到了 source 的信息:

上面的写法已经不推荐, 建议使用新的写法: GET twitter/_doc/1?_source
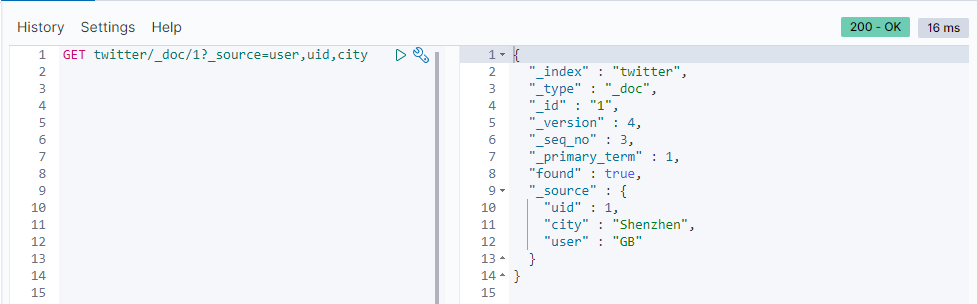
我们也可以只获取source的部分字段:
GET twitter/_doc/1?_source=user,uid,city
使用_mget接口请求多个文档
首先我们在twitter新增一个id为2的文档:
PUT twitter/_doc/2
{
"user": "Aben",
"uid": 1,
"city": "Guangzhou",
"province": "Guangdong",
"country": "China"
}
方法1: 输入命令:
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1
},
{
"_index": "twitter",
"_id": 2
}
]
}
也可以只获得部分字段:
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1,
"_source":["uid","city"]
},
{
"_index": "twitter",
"_id": 2,
"_source":["uid","province"]
}
]
}

方法2:
使用命令:
GET twitter/_doc/_mget
{
"ids": ["1", "2"]
}
注意:此方法在7.7版本下会警告:
#! Deprecation: [types removal] Specifying types in multi get requests is deprecated.
修改文档
方法1: PUT + doc 全数据更新
按照REST的要求,PUT操作用来修改数据。
PUT twitter/_doc/1
{
"user": "Aben2",
"uid": 1,
"city": "Hefei",
"province": "Anhui",
"country": "China",
"location":{
"lat":"29.084661",
"lon":"111.335210"
}
}

查询数据:
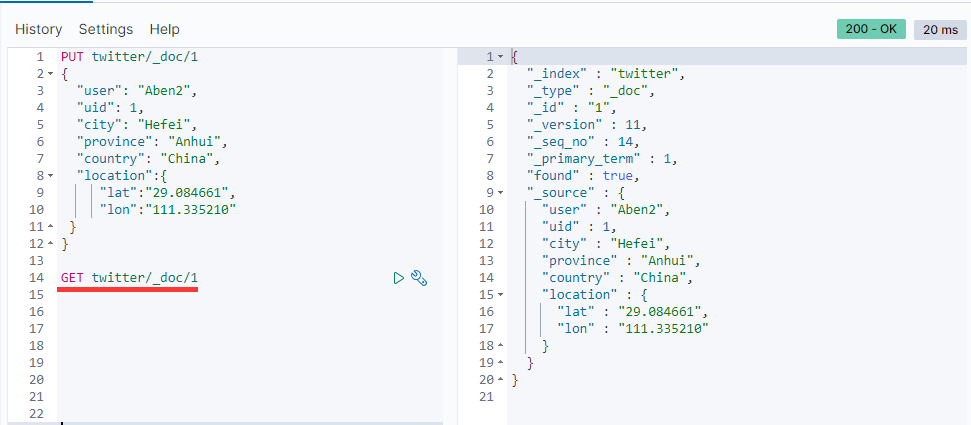
注意: 使用PUT的_doc方法操作, 必须把所有的项目都传入, 否则会丢失数据
方法2: POST + update 部分数据更新
POST twitter/_update/1
{
"doc":{
"city":"Chengdu",
"province":"Sichuan"
}
}
执行后GET一下看看数据是否更新。
按条件查询批量更新
在关系型数据库中,我们通常是对数据库进行搜索,然后才进行修改。在这种情况下,通常事先并不知道文档的id,需要通过查询的方式来进行查询,然后再修改。ES也提供了相应的REST接口。
POST twitter/_update_by_query
{
"query": {
"match": {
"user": "Aben2"
}
},
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;ctx._source.country = params.country",
"lang": "painless",
"params": {
"city": "上海",
"province": "上海",
"country": "中国"
}
}
}
上面这段代码, 会搜索'user'='Aben2'的文档, 并按照script.source的更新操作, 把source.params的数据更新到文档。

我们前面设置的是id=1的文档符合条件, 现在去看看文档信息:

对于那些名字是中文字段的文档来说,在painless语言中,直接打入中文字段名字,并不能被认可。我们可以使用如下的方式来操作:
POST edd/_update_by_query
{
"query": {
"match": {
"姓名": "张彬"
}
},
"script": {
"source": "ctx._source["签到状态"] = params["签到状态"]",
"lang": "painless",
"params" : {
"签到状态":"已签到"
}
}
}
UPSERT一个文档
我们前面给的update数据的操作,如果指定ID的文档不存在,ES会返回错误: 'document missing'。 术语 upsert 表示更新或插入,即如果存在则更新文档,否则插入新文档,这类似于mysql中的replace。
doc_as_upsert 参数检查具有给定ID的文档是否已经存在,并将提供的doc与现有文档合并。 如果不存在具有给定ID的文档,则会插入具有给定文档内容的新文档。
下面的示例使用 doc_as_upsert 合并到ID为3的文档中,或者如果不存在则插入一个新文档:
POST /twitter/_update/3
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}
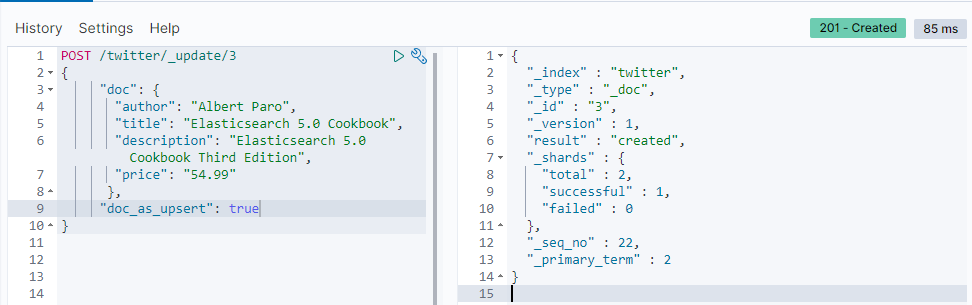
检查一个文档是否存在
有时候我们想知道一个文档是否存在,我们可以使用如下的方法:
HEAD twitter/_doc/1
这个HEAD接口可以很方便地告诉我们在twitter的索引里是否有一id为1的文档:

上面的返回值表明id为1的文档是存在的。
删除一个文档
如果我们想删除一个文档的话,我们可以使用如下的命令:
DELETE twitter/_doc/1
在上面的命令中,我们删除了id为1的文档:
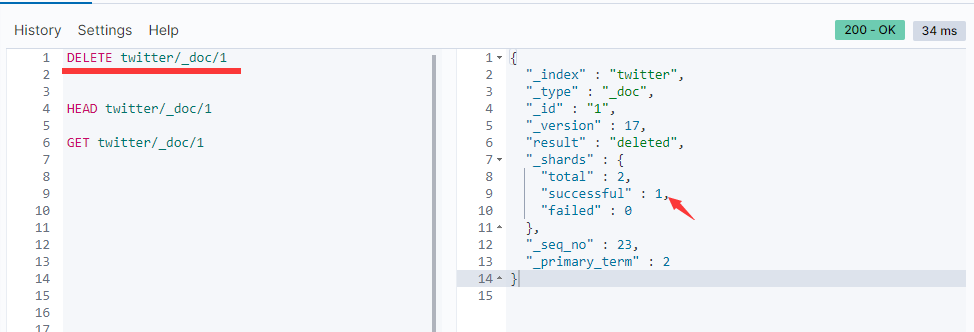
在关系数据库中,通常是对数据库进行搜索,然后才进行删除。在这种情况下,我们通常事先并不知道文档的id。我们需要通过查询的方式来进行查询,然后进行删除。ES也提供了相应的REST接口。
POST twitter/_delete_by_query
{
"query": {
"match": {
"city": "上海"
}
}
}

这样我们就把所有的city是上海的文档都删除了。
删除一个index
删除一个index是非常直接的。我们可以直接使用如下的命令来进行删除:
DELETE twitter

当我们执行完这一条语句后,所有的在twitter中的文档都被删除。
批处理命令
上面我们已经了解了如何使用REST接口来创建一个index,并为之创建,读取,修改,删除文档(CRUD)。因为每一次操作都是一个REST请求,对于大量的数据进行操作的话,这个显然比较慢。ES提供了一个批量处理的命令。这样我们通过一次REST请求,就可以完成很多的操作。这无疑是一个非常大的好处。下面,我们来介绍一下这个 bulk 命令。
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
在上面的命令中,我们使用了 bulk 指令来完成我们的操作。在输入命令时,我们需要特别的注意: 千万不要添加除了换行以外的空格,否则会导致错误 。在上面我们用 index 来创建一个文档。为了方便,我们在每一个文档里,特别指定了每个文档的id。当执行完我们的批处理bulk命令后,我们可以看到:
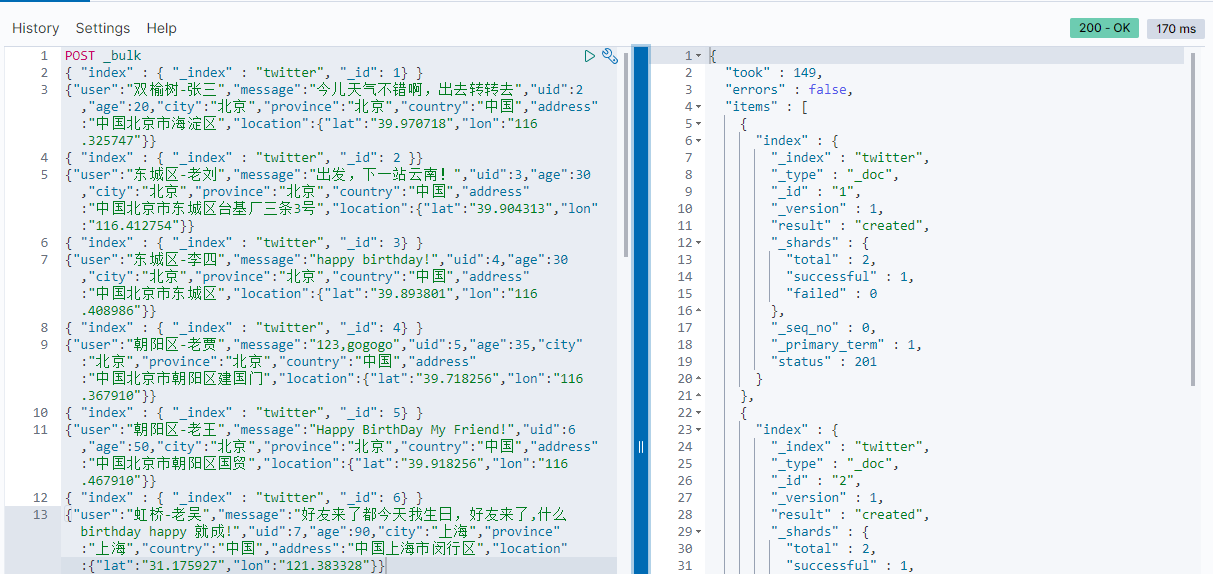
显然,我们的创建是成功的。而且上面的命令还可以执行多次,相当于 UPSERT 的(插入/更新)批量操作而不会出现因为数据已存在而插入失败。在实际的使用中,我们必须注意的是:一个好的起点是批量处理1000到5,000个文档,总有效负载在5MB到15MB之间。如果我们的payload过大,那么可能会造成请求的失败。如果你想更进一步探讨的话,你可以使用文件 accounts.json 来做实验。
如果你想查询到所有的输入的文档,我们可以使用如下的命令来进行查询:
POST twitter/_search
也可以使用 GET twitter/_search
这是一个查询的命令,在以后的章节中,我们将再详细介绍。通过上面的指令,我们可以看到所有的已经输入的文档。
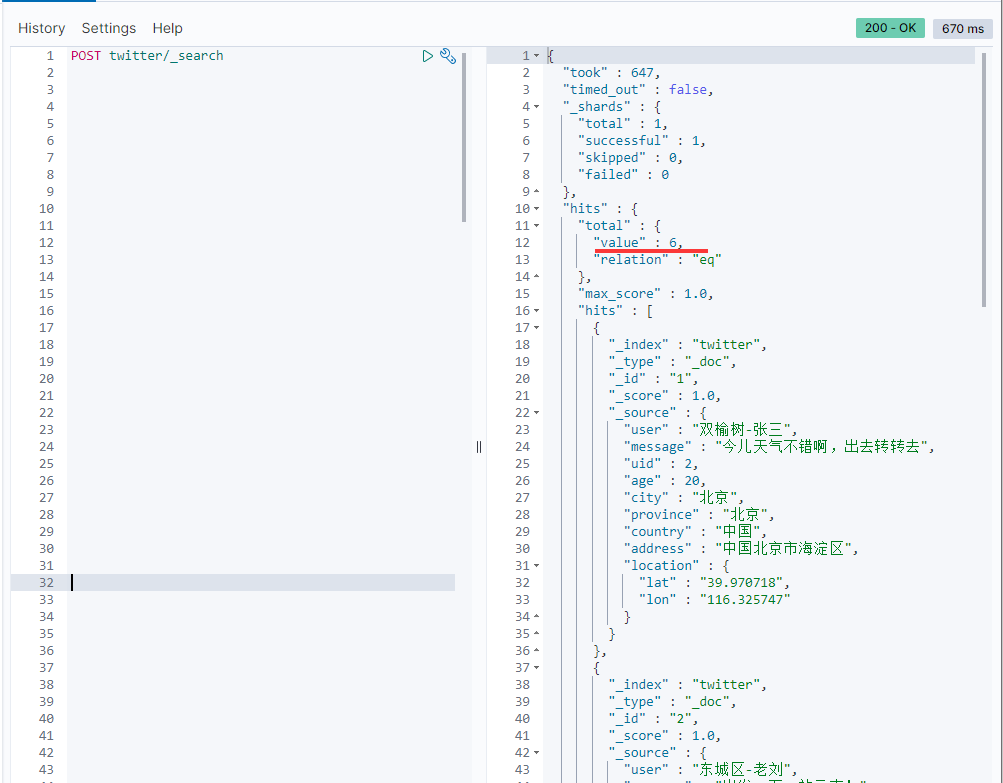
上面的结果显示,已经有6条文档记录了。
我们可以通过使用_count命令来查询有多少条数据:
GET twitter/_count
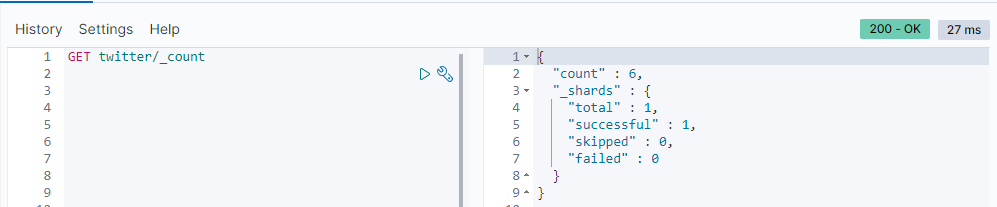
上面我们已经使用了 index 来创建6条文档记录。我也可以尝试其它的命令,比如 create :
POST _bulk
{ "create" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
在上面的第一个记录里,使用了 create 来创建一个id为1的记录。因为之前已经创建过了,所以我们可以看到如下的信息:
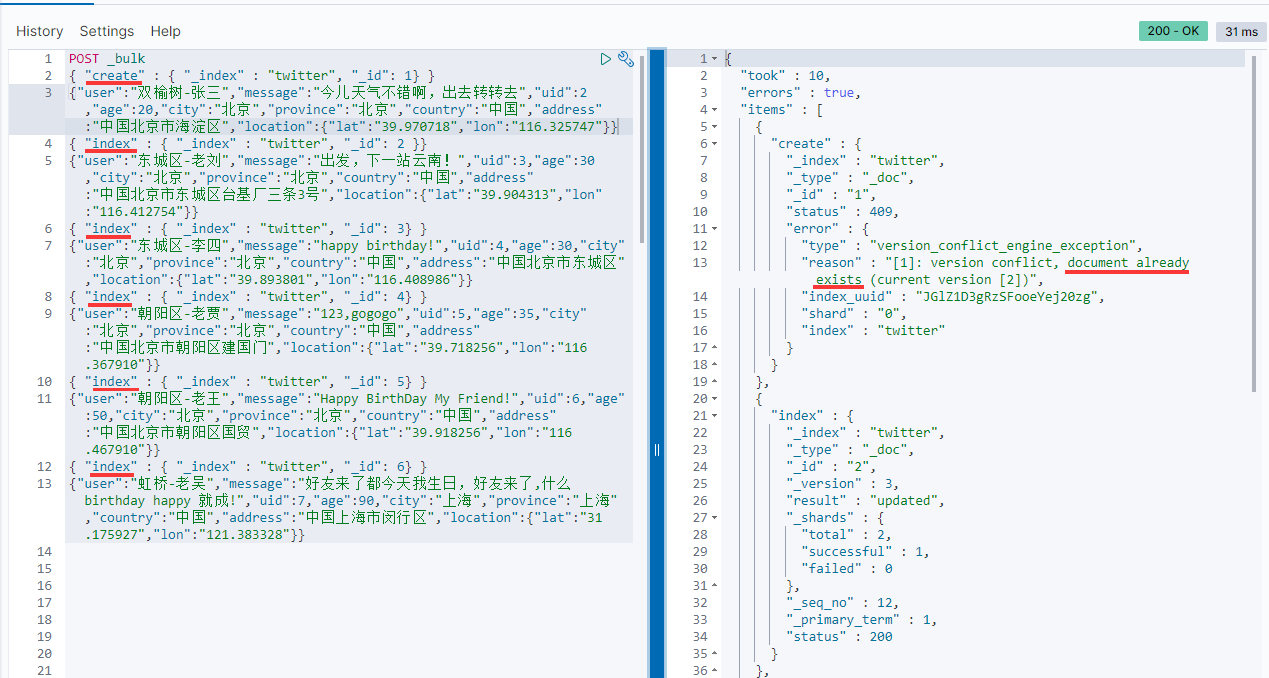
从上面的信息,我们可以看出来 index 和 create 的区别。 index 总是可以成功,它可以覆盖之前的已经创建的文档,但是 create 则不行,如果已经有以那个id为名义的文档,就不会成功。
我们可以使用delete来删除一个已经创建好的文档:
POST _bulk
{ "delete" : { "_index" : "twitter", "_id": 1 }}

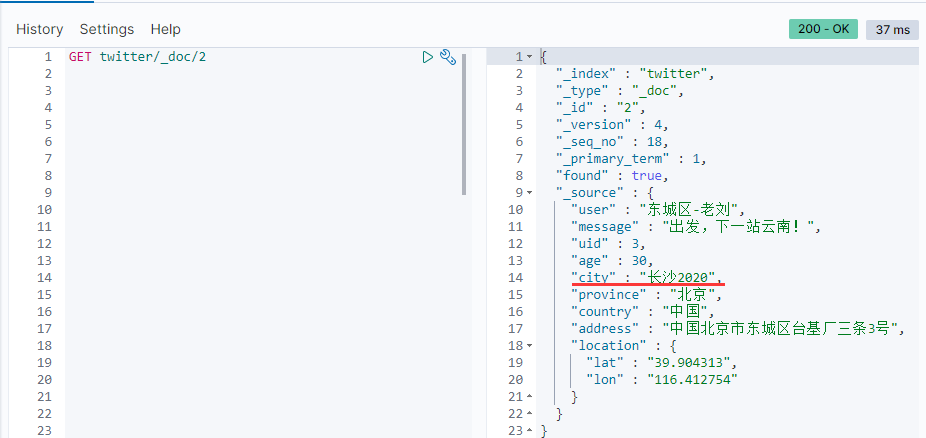
现在我们来查询一下id=1的文档:
GET twitter/_doc/1

显然,我们已经把id为1的文档成功删除了。
我们也可以使用 update 来更新一个文档。
POST _bulk
{ "update" : { "_index" : "twitter", "_id": 2 }}
{"doc": { "city": "长沙2020"}}
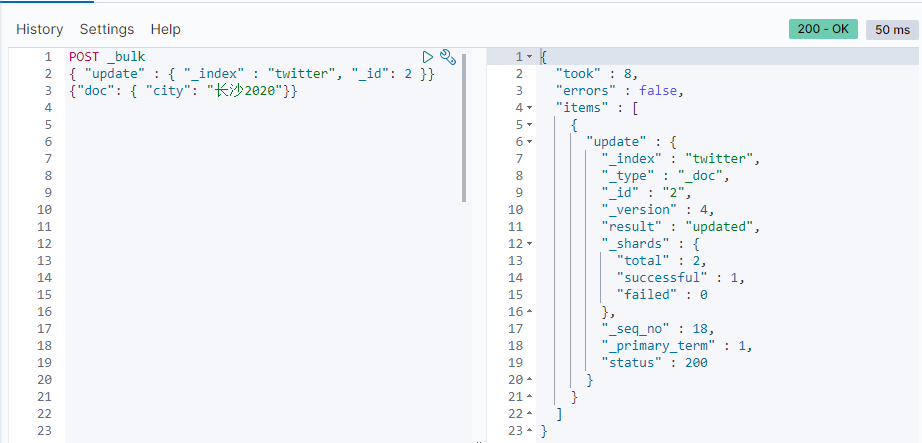
我们现在来查看一下数据:
注意:通过bulk API为数据编制索引时,您不应在集群上进行任何查询/搜索。 这样做可能会导致严重的性能问题。
Open/Close Index 打开/关闭索引
ES支持索引的在线/离线模式。 使用离线模式时,在群集上几乎没有任何开销地维护数据。 关闭索引后,将阻止读/写操作。 当您希望索引重新联机时,只需打开它即可。 但是,关闭索引会占用大量磁盘空间。 您可以通过将 cluster.indices.close.enable 的默认值从true更改为false来禁用关闭索引功能,以避免发生意外。
POST twitter/_close
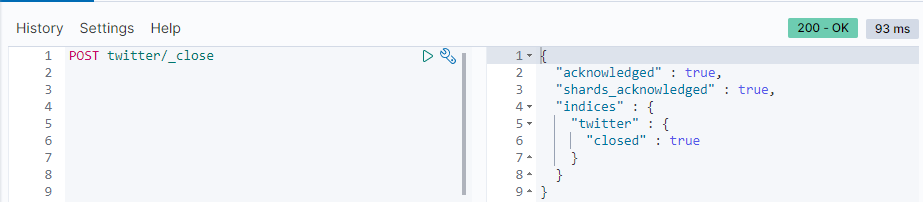
一旦twitter索引被关闭了,那么我们再访问时会出现如下的错误:
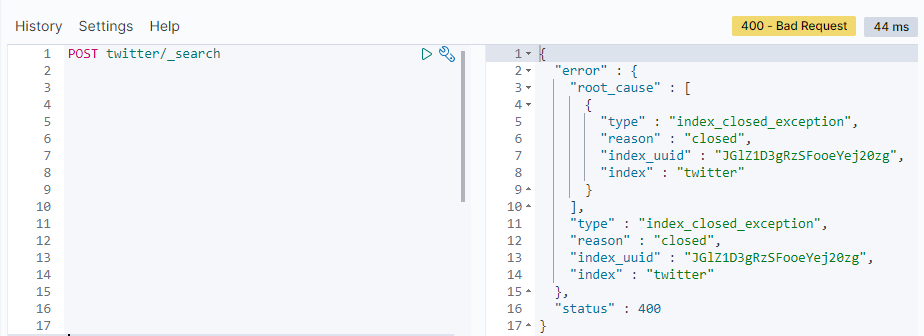
我们可以通过_open接口来重新打开这个index:
POST twitter/_open

Freeze/Unfreeze index 冻结/解冻索引
冻结索引(freeze index)在群集上几乎没有开销(除了将其元数据保留在内存中),并且是只读的。 只读索引被阻止进行写操作,例如 docs-index 或 force merge 。 请参阅 冻结索引 和 取消冻结索引 。
冻结索引受到限制,以限制每个节点的内存消耗。 每个节点的并发加载的冻结索引数受 search_throttled 线程池中的线程数限制,默认情况下为1。 默认情况下,即使已明确命名冻结索引,也不会针对冻结索引执行搜索请求。 这是为了防止由于误将冻结的索引作为目标而导致的意外减速。 如果要包含冻结索引做搜索,必须使用查询参数 ignore_throttled=false 来执行搜索请求。
我们可以使用如下的命令来对twitter索引来冻结:
POST twitter/_freeze
在执行上面的命令后,我们再对twitter进行搜索:

我们搜索不到任何的结果。按照我们上面所说的,我们必须加上 ignore_throttled=false 参数来进行搜索:
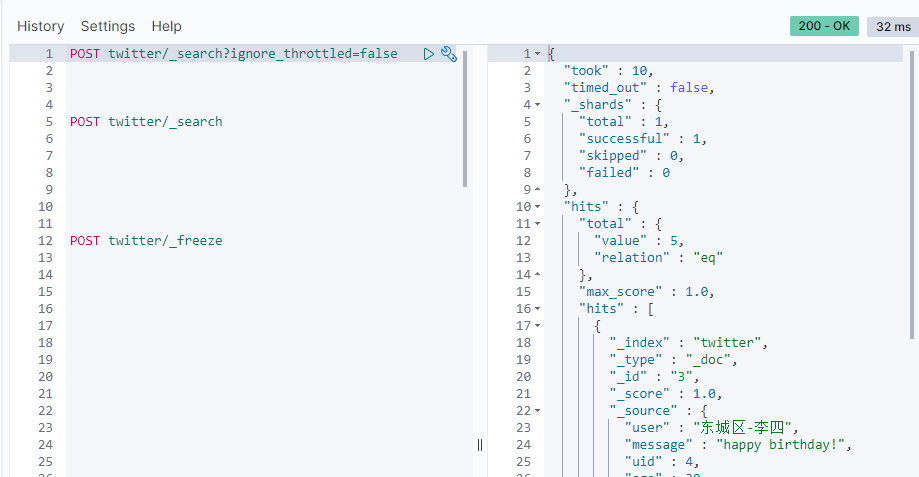
显然对于一个frozen的索引来说,我们是可以对它进行搜索的。我们可以通过如下的命令来对这个已经冻结的索引来进行解冻:
POST twitter/_unfreeze

一旦我们的索引被成功解冻,那么它就可以像我们正常的索引来进行操作了,而不用添加参数 ignore_throttled=false 来进行访问。
总结
执行当前代码块, 可以使用快捷键: Ctrl + Enter















 2494
2494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









