






缺页异常处理源码分析并实践:
本文章是在阅读了相关博客、书本的前提下撰写的,是站在前人的肩膀上对所学内容的汇总,包含了部分个人理解。本文章会放出参考博客的链接。
一、缺页异常知识储备:
CPU访问到的是虚拟地址,通过MMU将虚拟地址转换成物理地址,而MMU上的这种虚拟地址和物理地址的转换关系是需要创建的==(怎么创建?通过触发缺页中断)==,当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射,但那个物理页不可写的时候,MMU将会通知CPU产生了一个缺页异常。
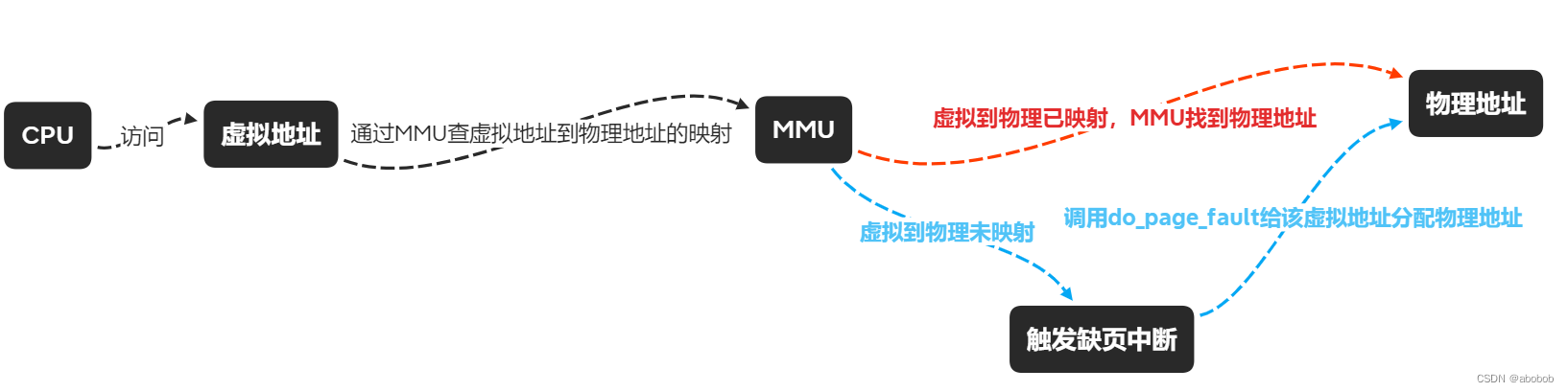
而何时会触发缺页中断呢?在这里可以总结为以下四种情况:
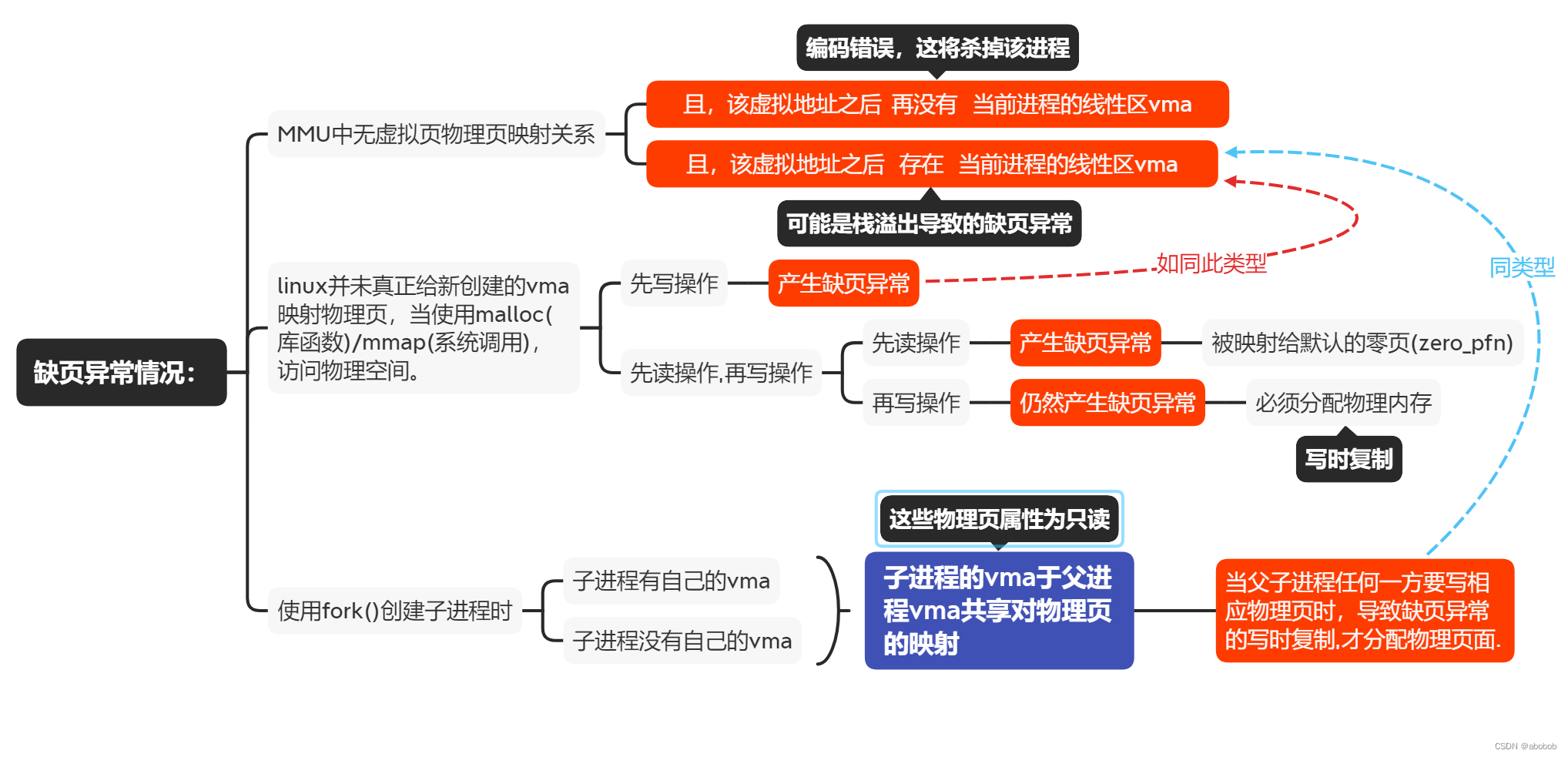
- MMU中无虚拟地址——>物理地址的映射关系;
- linux并未真正给新创建的vma映射物理页,当使用malloc(库函数)/mmap(系统调用),访问物理空间。
- 使用fork()创建子进程后,父子进程任何一方要写相应物理页时,导致缺页异常的写时复制,才分配物理页面。
不到万不得以,Linux是不会轻易交出物理地址的;
本章节参考如下文章:https://zhuanlan.zhihu.com/p/583396235?
二、源码分析:
再有了一定的知识储备后,开始着手对内核中缺页异常源码的阅读和分析,主要是Linux0.11及Linux5.15中源码的分析;
2.1、linux0.11源码分析:
本部分参考了csdn中如下博主的链接:https://blog.csdn.net/THEANARKH/article/details/100549972?
2.1.1、源码展示:
以下为0.11相关源码的注释几自己理解:
void do_no_page(unsigned long error_code,unsigned long address)
{
int nr[4];
unsigned long tmp;
unsigned long page;
int block,i;
//取得线性地址对应页的页首地址,与0xfffff000即减去页偏移;
address &= 0xfffff000;//线性地址对应页的页首地址
//算出离代码段首地址的偏移;
tmp = address - current->start_code;
// tmp大于等于end_data说明是访问堆或者栈的空间时发生的缺页,直接申请一页
//如果缺页的是堆、栈的空间,则直接分配一页新的物理地址。
if (!current->executable || tmp >= current->end_data) {
get_empty_page(address);//直接申请一页,此时current->end_data > tmp+4kb;
return;
}
// 是否有进程已经使用了
/*否则先判断是否有另一个进程和当前进程使用了同一个执行文件。
是的话,则判断是否可以共享*/
if (share_page(tmp))
return;
/*都不满足,则到硬盘中把一页内容加载到内存中,并且修改页表项内容*/
// 获取一页,4kb
/*get_free_page()从操作系统的内存池中分配一个空闲的物理页或虚拟页
oom 通常是 "Out of Memory" 的缩写,表示内存耗尽的情况。
在这里,它表示系统遇到了内存分配失败,无法继续正常运行。*/
if (!(page = get_free_page()))
oom();
/* remember that 1 block is used for header 一块用于开头*/
/*
算出要读的硬盘块号,但是最多读四块。
tmp/BLOCK_SIZE算出线性地址对应页的
页首地址离代码块距离了多少块,然后读取页首
地址对应的块号,所以需要加一。比如距离2块的距离,则
需要读取的块是第三块
*/
block = 1 + tmp/BLOCK_SIZE;//即当前线性地址对应的逻辑硬盘块号;
for (i=0 ; i<4 ; block++,i++)// 查找文件前4块对应的物理硬盘号
nr[i] = bmap(current->executable,block);// bmap算出逻辑块号对应的物理块号
/*bread_page用于从磁盘上读取一个页面(page)的数据*/
bread_page(page,current->executable->i_dev,nr);
/*
tmp是小于end_data的,因为从tmp开始加载了4kb的数据,
所以tmp+4kb(4096)后大于end_data,所以大于的部分需要清0,
i即超出的字节数
*/
i = tmp + 4096 - current->end_data;//i即超出的字节数
tmp = page + 4096;
// page是物理页首地址,加上4kb,从后往前清0
while (i-- > 0) {
tmp--;
*(char *)tmp = 0;//将 tmp 指针所指的内存位置的值设置为 0
/*首先,tmp 被强制类型转换为 char 指针,
这是因为我们想要将这个位置视为一个字符(1 字节),然后将其值设置为 0。
这通常用于清零内存区域,也可以用于将字符数组的内容清零。*/
}
// 建立线性地址和物理地址的映射
if (put_page(page,address))//当页面不再被需要或引用时,相关的代码会调用put_page()函数来减少页面的引用计数。
return;
// 失败则释放刚才申请的物理页
free_page(page);
oom();
}
2.1.2、0.11源码分析:
- 源码调用关系与分析:

do_no_page是linux0.11源码中用于缺页中断具体处理函数;代码逻辑可以简化为三个if语句:
- ①如果缺页的是堆、栈的空间,则直接分配一页新的物理地址。
- ②否则先判断是否有另一个进程和当前进程使用了同一个执行文件。是的话,则判断是否可以共享。
- ③都不满足,则到硬盘中把一页内容加载到内存中,并且修改页表项内容。
①中主要是使用get_empty_page()函数来直接获得一个新的物理地址,并把页对应的物理地址存储在页面项中。其中通过put_page()函数来建立物理地址和虚拟地址之间的关联;其中get_empty()函数以及put_page()函数的源码分析如下:
- get_empty_page():
/*给address分配一个新的页,并且把页对应的物理地址存储在页面项中*/
void get_empty_page(unsigned long address)
{
unsigned long tmp;
if (!(tmp=get_free_page()) || !put_page(tmp,address)) {
free_page(tmp); /* 0 is ok - ignored */
oom();
}
}
- put_page():
/*
* This function puts a page in memory at the wanted address.
* It returns the physical address of the page gotten, 0 if
* out of memory (either when trying to access page-table or
* page.)
*/
/*page是物理地址,address是线性地址。
建立物理地址和线性地址的关联,即给页表和页目录项赋值*/
unsigned long put_page(unsigned long page,unsigned long address)
{
unsigned long tmp, *page_table;
/* NOTE !!! This uses the fact that _pg_dir=0 */
/*用于检查一个页面(通常是虚拟内存页)的地址是否在合法的内存范围内,
以确保不会出现非法内存访问。*/
if (page < LOW_MEM || page >= HIGH_MEMORY)
printk("Trying to put page %p at %p\n",page,address);
/*mem_map 是一个指向页表的指针数组,
用于跟踪系统中每个页面的状态和分配情况。
当内核需要分配一个物理页面用于存储数据时,
它可以使用 mem_map 来查找空闲页面并标记它们为已分配状态。
当页面不再需要时,内核可以将其标记为空闲,以供将来的分配。*/
/*mem_map 还可以用于建立页帧号(通常是页面在物理内存中的索引)
与实际物理地址之间的映射关系。这对于内核来说是很重要的,
因为它需要知道页面在物理内存中的位置*/
//page对应的物理页面没有被分配则说明有问题;
if (mem_map[(page-LOW_MEM)>>12] != 1)
printk("mem_map disagrees with %p at %p\n",page,address);
/*计算页目录项的偏移地址,页目录首地址在物理地址0处。
这里算出偏移地址后,就是绝对地址,与0xffc即四字节对齐*/
page_table = (unsigned long *) ((address>>20) & 0xffc);
if ((*page_table)&1)// 页目录项已经指向了一个有效的页表;
//算出页表首地址,*page_table的高20位是有效地址
page_table = (unsigned long *) (0xfffff000 & *page_table);
else {
//页目录项还没有指向有效的页表,分配一个新的物理页
if (!(tmp=get_free_page()))
return 0;
//把页表地址写到页目录项,tmp为页表的物理地址,或7代表页面是用户级、可读、写、执行、有效
*page_table = tmp|7;
// 页目录项指向页表的物理地址
page_table = (unsigned long *) tmp;
}
/*
address是32位,右移12为变成20位,再与3ff就是取得低10位,
即address在页表中的索引,或7代表该页面是用户级、可读、写、执行、有效
*/
page_table[(address>>12) & 0x3ff] = page | 7;
/* no need for invalidate */
return page;
}
②中主要是通过share_page()函数来判断当前位置的可执行文件是否与其他进程共享;其代码逻辑是依次判断:
- 当前进程是否有可执行文件;
- 当前进程的可执行文件是否已共享;
- 当前进程的可执行文件已共享,则找到不是当前进程,但执行了该可执行文件的进程,并通过try_to_share()去共享该可执行文件的地址;
以下是两个代码的注释:
- share_page():
/*
* share_page() tries to find a process that could share a page with
* the current one. Address is the address of the wanted page relative
* to the current data space.
*
* We first check if it is at all feasible by checking executable->i_count.
* It should be >1 if there are other tasks sharing this inode.
*/
// 判断有没有多个进程执行了同一个可执行文件
static int share_page(unsigned long address)
{
struct task_struct ** p;
if (!current->executable)//如通过当前进程没有可执行文件,则退出
return 0;
/*i_count 通常是一个表示文件引用计数的字段。
这个字段用于跟踪有多少个进程正在共享同一个文件*/
if (current->executable->i_count < 2)//未共享文件;
return 0;
for (p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
if (!*p)
continue;
if (current == *p)
continue;
if ((*p)->executable != current->executable)
continue;
/*找到一个不是当前进程,但都执行了同一个可执行文件的进程*/
//不同进程,但执行了同一个可执行文件;
if (try_to_share(address,*p))//判断是否可以共享;
return 1;
}
return 0;
}
- try_to_share():
/*
* try_to_share() checks the page at address "address" in the task "p",
* to see if it exists, and if it is clean. If so, share it with the current
* task.
*
* NOTE! This assumes we have checked that p != current, and that they
* share the same executable.
*/
// 使得另一个进程的页目录和页表项指向另一个进程的正在使用的物理地址
static int try_to_share(unsigned long address, struct task_struct * p)
{
unsigned long from;
unsigned long to;
unsigned long from_page;
unsigned long to_page;
unsigned long phys_addr;
/*
address是距离start_code的偏移。这里算出这个距离跨了多少个页目录项,
然后加上start_code的页目录偏移就得到address在页目录里的绝对偏移
*/
from_page = to_page = ((address>>20) & 0xffc);
// p进程的代码开始地址(线性地址),取得p进程的页目录项地址,再加上address算出的偏移
from_page += ((p->start_code>>20) & 0xffc);
// 取得当前进程的页目录项地址,页目录物理地址是0,所以这里就是该地址对应的页目录项的物理地址
to_page += ((current->start_code>>20) & 0xffc);
/* is there a page-directory at from? */
// from是页表的物理地址和标记位
from = *(unsigned long *) from_page;
// 没有指向有效的页表则返回
if (!(from & 1))
return 0;
// 取出页表地址
from &= 0xfffff000;
// 算出address对应的页表项地址,((address>>10) & 0xffc)算出页表项偏移,0xffc说明是4字节对齐
from_page = from + ((address>>10) & 0xffc);
// 页表项的内容,包括物理地址和标记位信息
phys_addr = *(unsigned long *) from_page;
/* is the page clean and present? */
// 是否有效和是否是脏的,如果不是有效并且干净的则返回
if ((phys_addr & 0x41) != 0x01)
return 0;
// 取出物理地址的页首地址
phys_addr &= 0xfffff000;
if (phys_addr >= HIGH_MEMORY || phys_addr < LOW_MEM)
return 0;
// 目的页目录项内容
to = *(unsigned long *) to_page;
// 目的页目录项是否指向有效的页表
if (!(to & 1))
// 没有则新分配一页,并初始化标记位
if (to = get_free_page())
*(unsigned long *) to_page = to | 7;
else
oom();
// 取得页表地址
to &= 0xfffff000;
// 取得address对应的页表项地址
to_page = to + ((address>>10) & 0xffc);
// 是否指向了有效的物理页,是的话说明不需要再建立线性地址到物理地址的映射了
if (1 & *(unsigned long *) to_page)
panic("try_to_share: to_page already exists");
/* share them: write-protect */
// 标记位不可写
*(unsigned long *) from_page &= ~2;
// 把address对应的源页表项内容复制到目的页表项中
*(unsigned long *) to_page = *(unsigned long *) from_page;
// 使tlb失效
invalidate();
// 算出页数,物理页引用数加一
phys_addr -= LOW_MEM;
phys_addr >>= 12;
mem_map[phys_addr]++;
return 1;
}
③都不满足,则到硬盘中把一页内容加载到内存中,并且修改页表项内容并通过put_page()函数建立物理地址和虚拟地址之间的关联。主要涉及到get_free_page()、bmap()、bread_page()函数:
- get_free_page()从操作系统的内存池中分配一个空闲的物理页或虚拟页;
- bmap算出逻辑块号对应的物理块号;
- bread_page()用于从磁盘上读取一个页面(page)的数据;
2.1.3、阅读0.11中缺页中断处理源码小结:
在自己虚拟机中结合CSDN相关博客阅读了linux-0.11源码中的相关文件之后,真切的感受到了最原始的缺页中断处理思想,其实就是三个if判断加上一些处理函数。在宏观上对缺页中断处理有了一定的理解,但是对于各个函数细节仍然存在不懂、不理解的地方,对于更细节的代码逻辑仍有疑惑,需要反复看反复学。
2.2、linux5.15源码分析:
本部分参考了知乎中如下文章:https://zhuanlan.zhihu.com/p/583396235;
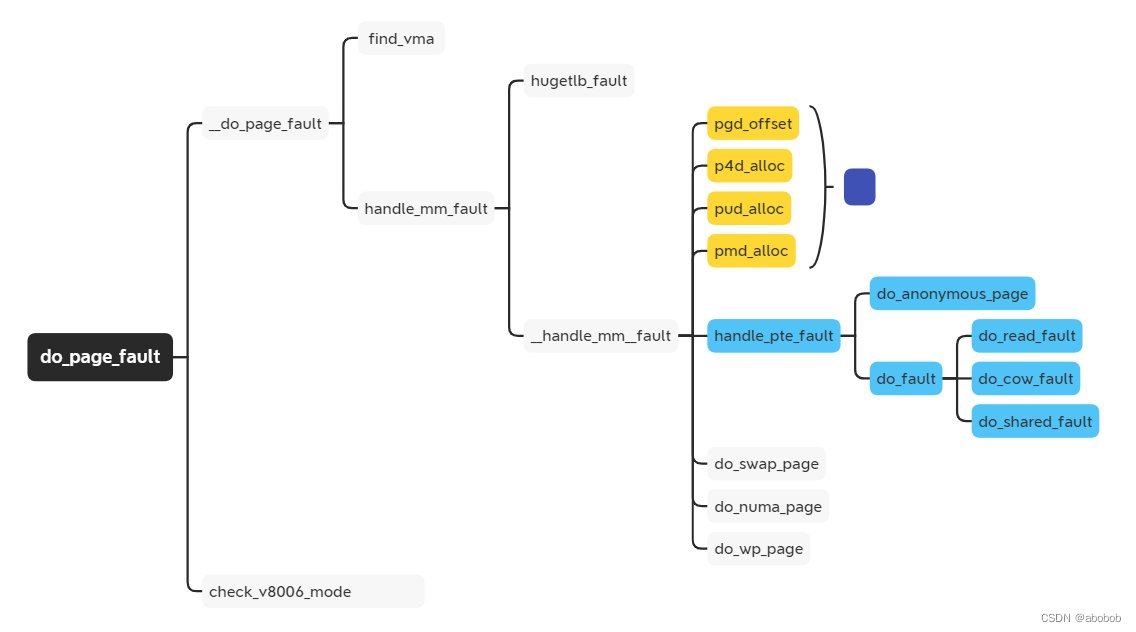
2.2.1、源码展示:
(1)、do_page_fault:
该代码被记录在arch/arm/mm/fault.c文件中;
static int __kprobes//静态函数,用于处理页面错误
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
/*参数:
1、unsigned long addr:页面错误发生的地址;
2、unsigned int fsr:页面错误的状态寄存器;
3、struct pt_regs *regs:包含进程寄存器状态的结构
*/
struct task_struct *tsk;
struct mm_struct *mm;
int sig, code;
vm_fault_t fault;
unsigned int flags = FAULT_FLAG_DEFAULT;
/*调用kprobe_page_fault,检查是否有与 Kprobes(内核探针)相关的页面错误*/
if (kprobe_page_fault(regs, fsr))
return 0;
tsk = current;//tsk指向当前进程task_struct结构;
mm = tsk->mm;//mm指向当前进程的内存地址管理结构体;
/* Enable interrupts if they were enabled in the parent context. */
/*检查在父上下文中是否启用了中断*/
if (interrupts_enabled(regs))//why??????????????????
local_irq_enable();//调用local_irq_enable() 来启用中断;
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
/*如果处于中断上下文或者没有用户上下文,
那么不应该处理页面错误,会跳转到 no_context 标签。*/
if (faulthandler_disabled() || !mm)//判断当前状态;
goto no_context;
/*检查当前进程是否在用户模式下运行,
如果是,将 FAULT_FLAG_USER 标志设置在 flags 变量中。
这表示页面错误是在用户模式下发生的。*/
if (user_mode(regs))
flags |= FAULT_FLAG_USER;//falgs置位
/*检查页面错误是否是写错误(写操作引起的错误)而不是上下文切换错误。
如果是,将 FAULT_FLAG_WRITE 标志设置在 flags 变量中。*/
if ((fsr & FSR_WRITE) && !(fsr & FSR_CM))//fsr是传入的参数,表示页面错误的状态寄存器
flags |= FAULT_FLAG_WRITE;//falgs置位
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr);//记录性能事件,用于跟踪页面错误的发生
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
/*处理页面错误引发的情况,包括加锁*/
if (!mmap_read_trylock(mm)) {
/*如果无法获取内存映射区的读锁,
它会尝试再次获取锁或者根据特定条件跳转到 no_context 标签
这些锁和条件检查用于确保页面错误的处理不会导致死锁或不一致的情况*/
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
/*调用 might_sleep() 来标记可能引发睡眠的情况。
此行为通常用于调试和验证。*/
retry:
mmap_read_lock(mm);//尝试获取内存映射区的读锁,确保在处理页面错误时对内存映射区的访问是同步的
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case, we'll have missed the might_sleep() from
* down_read()
*/
/*might_sleep()这个函数用于标记可能引发睡眠的情况
它用于调试和验证,以确保在合适的情况下发出警告*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
/*在调试 VM 并且不在用户模式下,且未找到异常表项时,
跳转到 no_context 标签。这意味着如果在内核模式下,
或者找到了异常处理表项,将不跳转,继续执行后续代码。*/
if (!user_mode(regs) &&
!search_exception_tables(regs->ARM_pc))
goto no_context;
#endif
}
/*!!!!!调用 __do_page_fault 函数来实际处理页面错误,并将结果存储在 fault 变量中。!!!!!!!!!!*/
fault = __do_page_fault(mm, addr, fsr, flags, tsk, regs);
/* If we need to retry but a fatal signal is pending, handle the
* signal first. We do not need to release the mmap_lock because
* it would already be released in __lock_page_or_retry in
* mm/filemap.c. */
/*处理在页面错误处理期间可能发生的信号处理:*/
/*用于检查在页面错误处理期间是否出现了挂起的致命信号。
如果是这样,将首先处理信号,然后跳到 no_context 标签。*/
if (fault_signal_pending(fault, regs)) {
if (!user_mode(regs))//若在内核态,同样跳到 no_context 标签。
goto no_context;
return 0;
}
/*接下来的条件检查处理页面错误的重试。如果页面错误没有错误标志(VM_FAULT_ERROR),
*并且 flags 变量中包含 FAULT_FLAG_ALLOW_RETRY 标志,那么进入下面的条件块:*/
if (!(fault & VM_FAULT_ERROR) && flags & FAULT_FLAG_ALLOW_RETRY) {
if (fault & VM_FAULT_RETRY) {
flags |= FAULT_FLAG_TRIED;//将 FAULT_FLAG_TRIED 标志设置在 flags 变量中,表示已经尝试过一次。
goto retry;
}
}
/*无论是成功处理页面错误还是进行了重试,
*都需要释放之前获取的内存映射区的读锁,以解锁对内存映射区的访问。*/
mmap_read_unlock(mm);
/*
* Handle the "normal" case first - VM_FAULT_MAJOR
*首先,代码检查了页面错误的一些常见情况,即 "VM_FAULT_MAJOR"。
*通过检查 fault 变量中的位掩码,如果页面错误没有错误标志(VM_FAULT_ERROR),
*不在坏映射(VM_FAULT_BADMAP)和不在坏访问(VM_FAULT_BADACCESS)情况下,
*表示这是一种"正常"情况,直接返回0,不需要进一步处理。
*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0;
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*如果不在用户模式(!user_mode(regs))下,
*说明内核没有足够的上下文来处理页面错误,
*因此跳转到 no_context 标签。
*这是因为内核模式下的错误处理会有不同的要求,
*可能需要特殊处理。
*/
if (!user_mode(regs))
goto no_context;
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, call the OOM killer, and return to
* userspace (which will retry the fault, or kill us if we
* got oom-killed)
*如果页面错误包含 VM_FAULT_OOM 标志,表示系统内存耗尽,
*这时会调用 "OOM killer"(内存耗尽杀手)并返回用户空间。
*用户空间将在这里重试页面错误,或者如果进程已被杀死,则终止当前进程。
*/
pagefault_out_of_memory();
return 0;
}
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to
* successfully fix up this page fault.
*如果页面错误包含 VM_FAULT_SIGBUS 标志,
*表示虽然有一些内存,但无法成功修复此页面错误。
*在这种情况下,会设置 sig 为 SIGBUS,并设置 code 为 BUS_ADRERR。
*/
sig = SIGBUS;
code = BUS_ADRERR;
} else {
/*
* Something tried to access memory that
* isn't in our memory map..
*否则,如果页面错误不包含 VM_FAULT_SIGBUS 标志,
*这意味着尝试访问不在内存映射中的内存,
*这是典型的"段错误"(SIGSEGV)情况。在这种情况下,
*会将 sig 设置为 SIGSEGV,并根据 fault 的不同值设置 code。
*如果 fault 是 VM_FAULT_BADACCESS,则 code 设置为 SEGV_ACCERR,
*否则设置为 SEGV_MAPERR。
*/
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
}
/*
*根据前面的设置,会调用__do_user_fault或__do_kernel_fault处理页面错误。
*如果在用户模式下,会调用 __do_user_fault 来触发用户空间的信号处理程序。
*如果没有足够的上下文来处理错误,会跳转到 no_context 标签,
*然后调用 __do_kernel_fault 来处理错误。
*/
__do_user_fault(addr, fsr, sig, code, regs);
return 0;
no_context:
__do_kernel_fault(mm, addr, fsr, regs);
return 0;
}static int __kprobes//静态函数,用于处理页面错误
/*重点函数*/
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
/*参数:
1、unsigned long addr:页面错误发生的地址;
2、unsigned int fsr:页面错误的状态寄存器;
3、struct pt_regs *regs:包含进程寄存器状态的结构
*/
struct task_struct *tsk;
struct mm_struct *mm;
int sig, code;
vm_fault_t fault;
unsigned int flags = FAULT_FLAG_DEFAULT;
/*调用kprobe_page_fault,检查是否有与 Kprobes(内核探针)相关的页面错误*/
if (kprobe_page_fault(regs, fsr))
return 0;
tsk = current;//tsk指向当前进程task_struct结构;
mm = tsk->mm;//mm指向当前进程的内存地址管理结构体;
/* Enable interrupts if they were enabled in the parent context. */
/*检查在父上下文中是否启用了中断*/
if (interrupts_enabled(regs))//why??????????????????
local_irq_enable();//调用local_irq_enable() 来启用中断;
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
/*如果处于中断上下文或者没有用户上下文,
那么不应该处理页面错误,会跳转到 no_context 标签。*/
if (faulthandler_disabled() || !mm)//判断当前状态;
goto no_context;
/*检查当前进程是否在用户模式下运行,
如果是,将 FAULT_FLAG_USER 标志设置在 flags 变量中。
这表示页面错误是在用户模式下发生的。*/
if (user_mode(regs))
flags |= FAULT_FLAG_USER;//falgs置位
/*检查页面错误是否是写错误(写操作引起的错误)而不是上下文切换错误。
如果是,将 FAULT_FLAG_WRITE 标志设置在 flags 变量中。*/
if ((fsr & FSR_WRITE) && !(fsr & FSR_CM))//fsr是传入的参数,表示页面错误的状态寄存器
flags |= FAULT_FLAG_WRITE;//falgs置位
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr);//记录性能事件,用于跟踪页面错误的发生
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
/*处理页面错误引发的情况,包括加锁*/
if (!mmap_read_trylock(mm)) {
/*如果无法获取内存映射区的读锁,
它会尝试再次获取锁或者根据特定条件跳转到 no_context 标签
这些锁和条件检查用于确保页面错误的处理不会导致死锁或不一致的情况*/
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
/*调用 might_sleep() 来标记可能引发睡眠的情况。
此行为通常用于调试和验证。*/
retry:
mmap_read_lock(mm);//尝试获取内存映射区的读锁,确保在处理页面错误时对内存映射区的访问是同步的
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case, we'll have missed the might_sleep() from
* down_read()
*/
/*might_sleep()这个函数用于标记可能引发睡眠的情况
它用于调试和验证,以确保在合适的情况下发出警告*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
/*在调试 VM 并且不在用户模式下,且未找到异常表项时,
跳转到 no_context 标签。这意味着如果在内核模式下,
或者找到了异常处理表项,将不跳转,继续执行后续代码。*/
if (!user_mode(regs) &&
!search_exception_tables(regs->ARM_pc))
goto no_context;
#endif
}
/*!!!!!调用 __do_page_fault 函数来实际处理页面错误,并将结果存储在 fault 变量中。!!!!!!!!!!*/
fault = __do_page_fault(mm, addr, fsr, flags, tsk, regs);
/* If we need to retry but a fatal signal is pending, handle the
* signal first. We do not need to release the mmap_lock because
* it would already be released in __lock_page_or_retry in
* mm/filemap.c. */
/*处理在页面错误处理期间可能发生的信号处理:*/
/*用于检查在页面错误处理期间是否出现了挂起的致命信号。
如果是这样,将首先处理信号,然后跳到 no_context 标签。*/
if (fault_signal_pending(fault, regs)) {
if (!user_mode(regs))//若在内核态,同样跳到 no_context 标签。
goto no_context;
return 0;
}
/*接下来的条件检查处理页面错误的重试。如果页面错误没有错误标志(VM_FAULT_ERROR),
*并且 flags 变量中包含 FAULT_FLAG_ALLOW_RETRY 标志,那么进入下面的条件块:*/
if (!(fault & VM_FAULT_ERROR) && flags & FAULT_FLAG_ALLOW_RETRY) {
if (fault & VM_FAULT_RETRY) {
flags |= FAULT_FLAG_TRIED;//将 FAULT_FLAG_TRIED 标志设置在 flags 变量中,表示已经尝试过一次。
goto retry;
}
}
/*无论是成功处理页面错误还是进行了重试,
*都需要释放之前获取的内存映射区的读锁,以解锁对内存映射区的访问。*/
mmap_read_unlock(mm);
/*
* Handle the "normal" case first - VM_FAULT_MAJOR
*首先,代码检查了页面错误的一些常见情况,即 "VM_FAULT_MAJOR"。
*通过检查 fault 变量中的位掩码,如果页面错误没有错误标志(VM_FAULT_ERROR),
*不在坏映射(VM_FAULT_BADMAP)和不在坏访问(VM_FAULT_BADACCESS)情况下,
*表示这是一种"正常"情况,直接返回0,不需要进一步处理。
*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0;
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*如果不在用户模式(!user_mode(regs))下,
*说明内核没有足够的上下文来处理页面错误,
*因此跳转到 no_context 标签。
*这是因为内核模式下的错误处理会有不同的要求,
*可能需要特殊处理。
*/
if (!user_mode(regs))
goto no_context;
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, call the OOM killer, and return to
* userspace (which will retry the fault, or kill us if we
* got oom-killed)
*如果页面错误包含 VM_FAULT_OOM 标志,表示系统内存耗尽,
*这时会调用 "OOM killer"(内存耗尽杀手)并返回用户空间。
*用户空间将在这里重试页面错误,或者如果进程已被杀死,则终止当前进程。
*/
pagefault_out_of_memory();
return 0;
}
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to
* successfully fix up this page fault.
*如果页面错误包含 VM_FAULT_SIGBUS 标志,
*表示虽然有一些内存,但无法成功修复此页面错误。
*在这种情况下,会设置 sig 为 SIGBUS,并设置 code 为 BUS_ADRERR。
*/
sig = SIGBUS;
code = BUS_ADRERR;
} else {
/*
* Something tried to access memory that
* isn't in our memory map..
*否则,如果页面错误不包含 VM_FAULT_SIGBUS 标志,
*这意味着尝试访问不在内存映射中的内存,
*这是典型的"段错误"(SIGSEGV)情况。在这种情况下,
*会将 sig 设置为 SIGSEGV,并根据 fault 的不同值设置 code。
*如果 fault 是 VM_FAULT_BADACCESS,则 code 设置为 SEGV_ACCERR,
*否则设置为 SEGV_MAPERR。
*/
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
}
/*
*根据前面的设置,会调用__do_user_fault或__do_kernel_fault处理页面错误。
*如果在用户模式下,会调用 __do_user_fault 来触发用户空间的信号处理程序。
*如果没有足够的上下文来处理错误,会跳转到 no_context 标签,
*然后调用 __do_kernel_fault 来处理错误。
*/
__do_user_fault(addr, fsr, sig, code, regs);
return 0;
no_context:
__do_kernel_fault(mm, addr, fsr, regs);
return 0;
}
在使用了chatgpt代码解读相关功能后,对于do_page_fault()函数有了初步的理解;将其总结为如下几点:
- 不同的条件逻辑判断;
- 如果是内核态出了异常,跳到no_context,进入内核态异常处理,由_do_kernel_fault 来处理内核错误;
- 如果不是内核的缺页异常而是用户进程的缺页异常,调用__do_page_fault()函数来实际处理页面错误,并将结果存储在 fault 变量中;
- 不同的条件逻辑判断;
- __do_user_fault()函数触发用户空间的信号处理程序;
(2)、__do_page_fault():
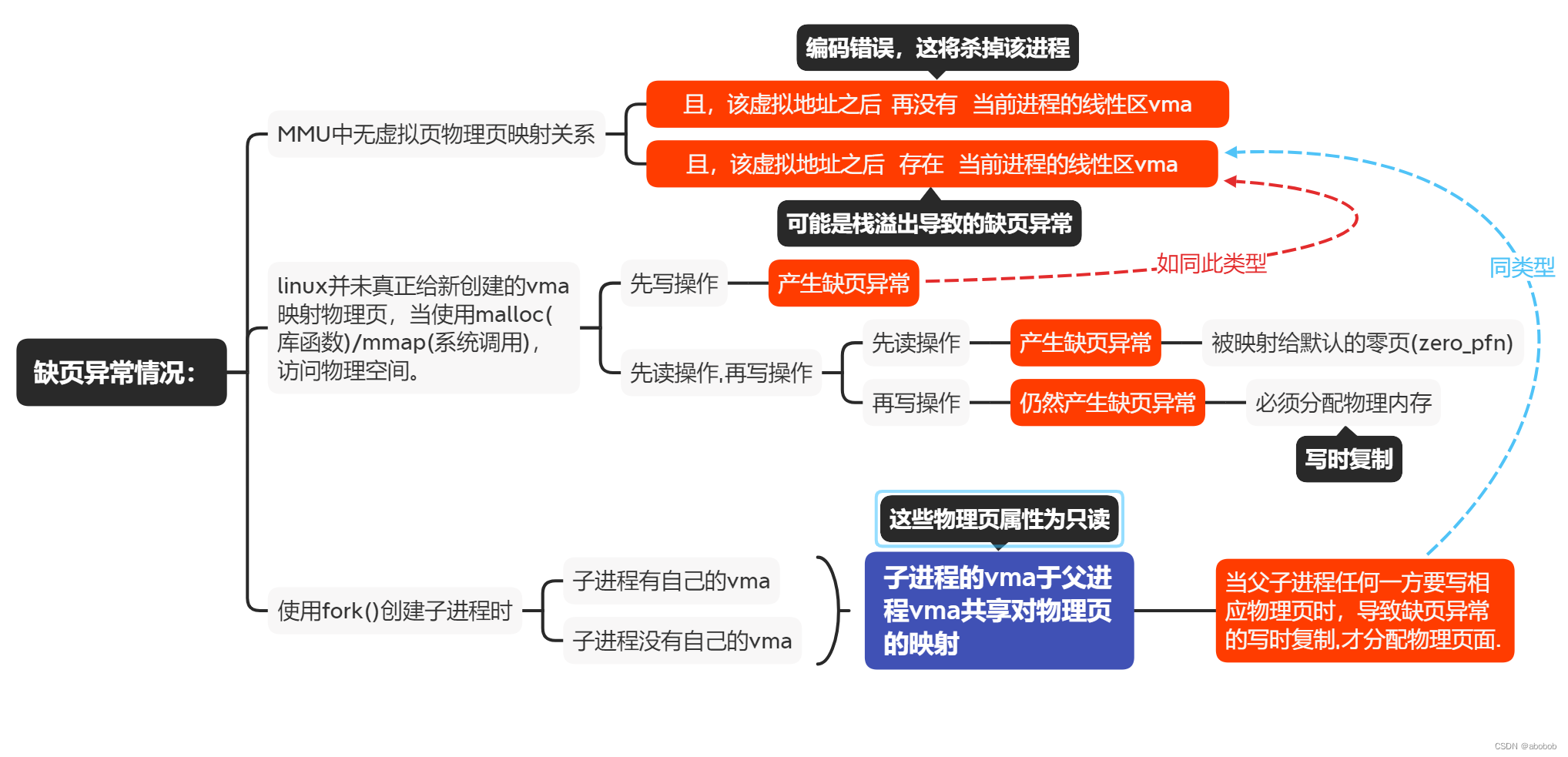
在do_page_fault()函数中,而是用户进程的缺页异常,那么调用__do_page_fault()内部函数来进行实际处理页面错误,该代码被记录在arch/arm/mm/fault.c文件中;为了方便理解,这里先放上用户态缺页异常的几种情况:
static vm_fault_t __kprobes
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
unsigned int flags, struct task_struct *tsk,
struct pt_regs *regs)
/*内存管理结构 mm,访问的地址 addr,错误码 fsr,
标志 flags,进程的任务结构 tsk,处理页面错误时使用的寄存器 regs。*/
{
struct vm_area_struct *vma;//
vm_fault_t fault;
/*搜索出现异常的地址前向最近的的vma
函数开始通过调用 find_vma 函数查找
与给定地址 addr 相关的虚拟内存区域
结构 vma;
*如果没有找到匹配的 vma,
则将 fault 设置为 VM_FAULT_BADMAP,
表示遇到了坏的内存映射,然后跳转到 out 标签。
*/
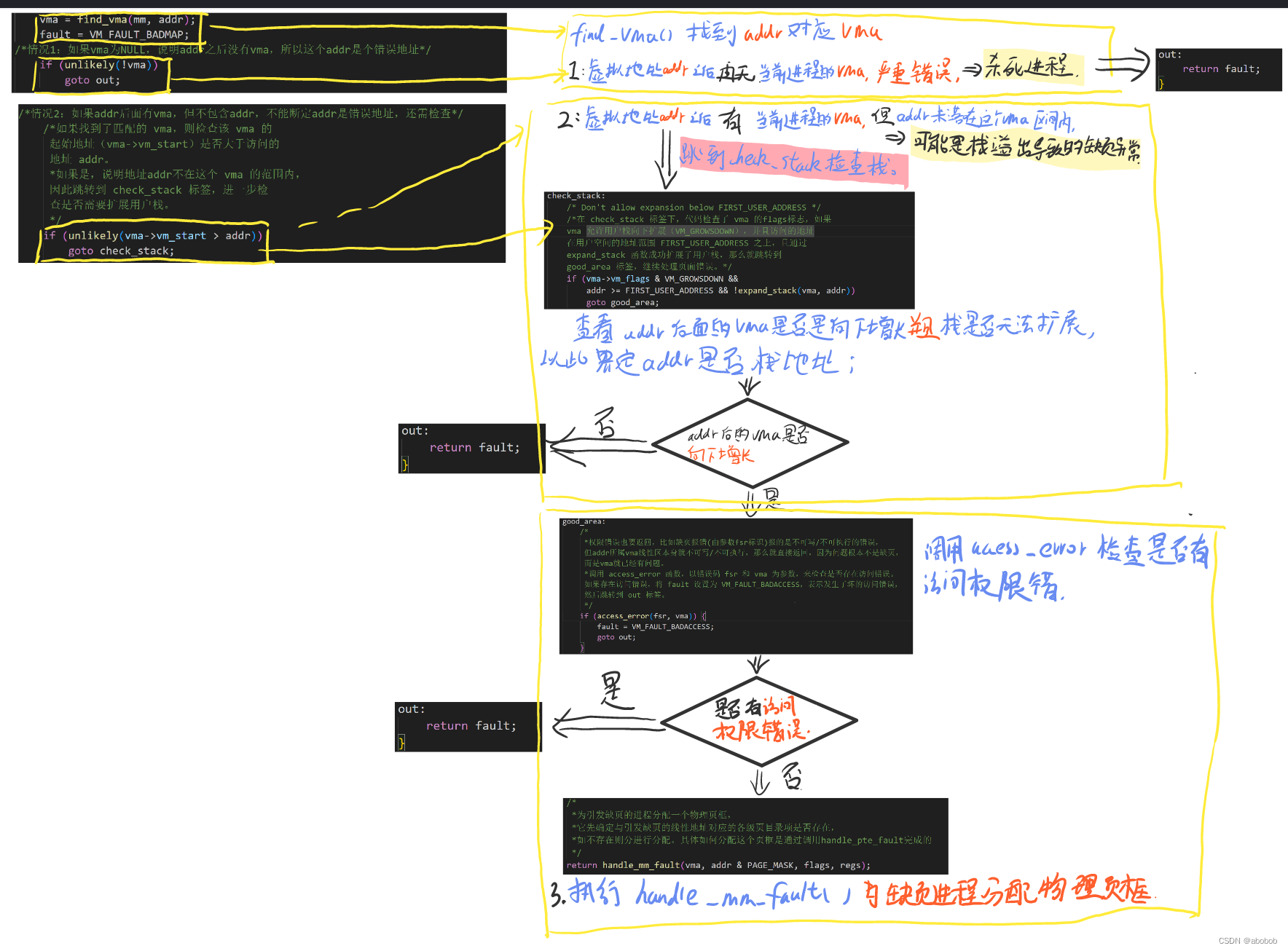
vma = find_vma(mm, addr);
fault = VM_FAULT_BADMAP;
/*情况1:如果vma为NULL,说明addr之后没有vma,所以这个addr是个错误地址*/
if (unlikely(!vma))
goto out;
/*情况2:如果addr后面有vma,但不包含addr,不能断定addr是错误地址,还需检查*/
/*如果找到了匹配的 vma,则检查该 vma 的
起始地址(vma->vm_start)是否大于访问的
地址 addr。
*如果是,说明地址addr不在这个 vma 的范围内,
因此跳转到 check_stack 标签,进一步检
查是否需要扩展用户栈。
*/
if (unlikely(vma->vm_start > addr))
goto check_stack;
/*
* Ok, we have a good vm_area for this
* memory access, so we can handle it.
*如果地址在合法的 vma 范围内,进入 good_area
*标签。这表示已经找到了适当的虚拟内存区域,
*可以继续处理页面错误。
*/
good_area:
/*
*权限错误也要返回,比如缺页报错(由参数fsr标识)报的是不可写/不可执行的错误,
但addr所属vma线性区本身就不可写/不可执行,那么就直接返回,因为问题根本不是缺页,
而是vma就已经有问题。
*调用 access_error 函数,以错误码 fsr 和 vma 为参数,来检查是否存在访问错误。
如果存在访问错误,将 fault 设置为 VM_FAULT_BADACCESS,表示发生了坏的访问错误,
然后跳转到 out 标签。
*/
if (access_error(fsr, vma)) {
fault = VM_FAULT_BADACCESS;
goto out;
}
/*
*为引发缺页的进程分配一个物理页框,
*它先确定与引发缺页的线性地址对应的各级页目录项是否存在,
*如不存在则分进行分配。具体如何分配这个页框是通过调用handle_pte_fault完成的
*/
return handle_mm_fault(vma, addr & PAGE_MASK, flags, regs);
check_stack:
/* Don't allow expansion below FIRST_USER_ADDRESS */
/*在 check_stack 标签下,代码检查了 vma 的flags标志,如果
vma 允许用户栈向下扩展(VM_GROWSDOWN),并且访问的地址
在用户空间的地址范围 FIRST_USER_ADDRESS 之上,且通过
expand_stack 函数成功扩展了用户栈,那么就跳转到
good_area 标签,继续处理页面错误。*/
if (vma->vm_flags & VM_GROWSDOWN &&
addr >= FIRST_USER_ADDRESS && !expand_stack(vma, addr))
goto good_area;
out:
return fault;
}
- 首先,查看缺页异常的这个虚拟地址addr,找它后面最近的vma,如果真的没有找到,那么说明访问的地址是真的错误了,因为它根本不在所分配的任何一个vma线性区;这是一种严重错误,将返回错误码(fault) VM_FAULT_BADMAP,内核会杀掉这个进程;
- 如果addr后面有vma,但addr并未落在这个vma的区间内,这存在一种可能,要知道栈的增长方向和堆是相反的即栈是向下增长,所以也许addr实际上是栈的一个地址,它后面的vma实际上是栈的vma,栈已无法扩展,即访问addr时,这个addr并没有落在vma中,所以更无二级页表映射,导致缺页异常。所以进入check_stack标签,查看addr后面的vma是否是向下增长并且栈是否无法扩展,以此界定addr是不是栈地址,如果是则进入缺页异常处理流程(goto good_area;),否则同样返回错误码(fault)VM_FAULT_BADMAP,内核会杀掉这个进程;
- 权限错误也要返回,比如缺页报错(fsr)报的是不可写,但vma本身就不可写,那么就直接返回,因为问题根本不是缺页,而是vma就已经有问题;返回错误码(fault) VM_FAULT_BADACCESS,这也是一种严重错误,内核会杀掉这个进程;
- ==最后是对确实缺页异常的情况进行处理,调用函数handle_mm_fault,==正常情况下将返回VM_FAULT_MAJOR或VM_FAULT_MINOR,返回错误码fault并加一task的maj_flt或min_flt成员 ;
(3)、handle_mm_fault():
handle_mm_fault,就是为引发缺页的进程分配一个物理页框。
- 如果是大页面,调用 hugetlb_fault函数处理页面错误
- 如果不是大页面,调用 __handle_mm_fault 函数来处理。
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags, struct pt_regs *regs)
{
vm_fault_t ret;
//调用 __set_current_state将当前进程状态设置为 TASK_RUNNING
__set_current_state(TASK_RUNNING);
/*调用count_vm_event和count_memcg_event_mm
增加相应的事件计数器,用于跟踪页面错误的发生*/
count_vm_event(PGFAULT);
count_memcg_event_mm(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section.
调用 check_sync_rss_stat(current) 更新计数器;
*/
check_sync_rss_stat(current);
/*通过 arch_vma_access_permitted 函数检查对虚拟内存区域的访问权限。
如果权限不被允许,函数返回 VM_FAULT_SIGSEGV,表示发生了段错误(Segmentation Fault)。*/
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
/*如果页面错误发生在用户空间(flags & FAULT_FLAG_USER 为真),
*函数调用 mem_cgroup_enter_user_fault() 启用内存控制组(memory cgroup)的OOM(Out-of-Memory)处理机制。
*OOM处理机制用于处理内存不足的情况,确保系统可以更加优雅地处理内存分配失败的情况。
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_enter_user_fault();//处理内存不足的情况
if (unlikely(is_vm_hugetlb_page(vma)))//函数检查虚拟内存区域是否是大页面(Huge Page)
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);//如果是大页面,调用 hugetlb_fault 函数处理页面错误
else
ret = __handle_mm_fault(vma, address, flags);//否则调用 __handle_mm_fault 函数来处理。
/*页面错误发生在用户空间,
函数调用 mem_cgroup_exit_user_fault() 退出内存控制组的OOM处理。*/
if (flags & FAULT_FLAG_USER) {
mem_cgroup_exit_user_fault();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*检查当前任务是否处于内存控制组的OOM状态,
*并且之前的分配错误被优雅地处理(!(ret & VM_FAULT_OOM))
*如果是这样,函数调用 mem_cgroup_oom_synchronize(false)
*来清除OOM状态,确保系统可以平稳地恢复。
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);//清除OOM状态,确保系统可以平稳地恢复。
}
/*用 mm_account_fault 更新页面错误的计数器,并返回错误码 ret,表示处理页面错误的结果。*/
mm_account_fault(regs, address, flags, ret);
return ret;
}
(4)、__handle_mm_fault():
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
unsigned int dirty = flags & FAULT_FLAG_WRITE;//从 flags 中提取出错误标志 FAULT_FLAG_WRITE,用于检查页面错误是否是写错误。
struct mm_struct *mm = vma->vm_mm;
/*指向页表项的指针,用于管理虚拟内存的页表*/
pgd_t *pgd;
p4d_t *p4d;
vm_fault_t ret;
/*获取用于映射虚拟地址到物理内存地址的页表项*/
pgd = pgd_offset(mm, address);//根据虚拟内存地址 (address) 获取一级页表项 (pgd)
p4d = p4d_alloc(mm, pgd, address);//根据一级页表项获取四级页表项 (p4d)
if (!p4d)
return VM_FAULT_OOM;
vmf.pud = pud_alloc(mm, p4d, address);//分配一个指向二级页表项 (pud) 的指针
if (!vmf.pud)
return VM_FAULT_OOM;
retry_pud:
/*
*如果 pud_none(*vmf.pud) 且启用了透明大页面 (THP) (__transparent_hugepage_enabled(vma)),
*则尝试创建巨大页 (create_huge_pud(&vmf)),否则继续处理。如果 create_huge_pud 成功,
*返回 VM_FAULT_FALLBACK,否则继续处理。
*/
if (pud_none(*vmf.pud) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pud_t orig_pud = *vmf.pud;
barrier();
/*如果 pud_trans_huge(orig_pud) 或 pud_devmap(orig_pud),
表示已经存在一个巨大页或者是设备映射,进行相应处理,否则继续。*/
if (pud_trans_huge(orig_pud) || pud_devmap(orig_pud)) {
/* NUMA case for anonymous PUDs would go here */
/*如果页面标记为脏 (dirty) 且 pud_write(orig_pud) 失败,
则尝试处理写保护巨大页 (wp_huge_pud(&vmf, orig_pud))。
如果成功,返回 VM_FAULT_FALLBACK,否则继续。*/
if (dirty && !pud_write(orig_pud)) {
ret = wp_huge_pud(&vmf, orig_pud);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pud_set_accessed(&vmf, orig_pud);//否则,标记巨大页为已访问 (huge_pud_set_accessed),返回 0。
return 0;
}
}
}
vmf.pmd = pmd_alloc(mm, vmf.pud, address);//分配一个指向三级页表项 (pmd) 的指针。
if (!vmf.pmd)
return VM_FAULT_OOM;
/* Huge pud page fault raced with pmd_alloc? */
/*表示二级页表项处于不稳定状态,返回到 retry_pud 标签重新尝试处理。*/
if (pud_trans_unstable(vmf.pud))
goto retry_pud;
/*如果 pmd_none(*vmf.pmd) 且启用了透明巨大页面 (THP),
则尝试创建巨大三级页 (create_huge_pmd(&vmf)),否则继续处理*/
if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
vmf.orig_pmd = *vmf.pmd;
/*如果三级页表项标记为交换 (is_swap_pmd(vmf.orig_pmd)),
则处理与交换页面相关的情况,包括等待页面迁移 (pmd_migration_entry_wait)。*/
barrier();
if (unlikely(is_swap_pmd(vmf.orig_pmd))) {
VM_BUG_ON(thp_migration_supported() &&
!is_pmd_migration_entry(vmf.orig_pmd));
if (is_pmd_migration_entry(vmf.orig_pmd))
pmd_migration_entry_wait(mm, vmf.pmd);
return 0;
}
/*检查页面中间目录项(pmd)是否对应于透明大页面或设备映射页面。
透明大页面是可以提高系统性能的大内存页面,而设备映射页面是内存映射到设备,
允许直接访问设备内存。*/
if (pmd_trans_huge(vmf.orig_pmd) || pmd_devmap(vmf.orig_pmd)) {
/*在第一个if块中,这一行检查pmd条目是否标记为“protnone”,
表示允许访问的保护设置。此外,它检查虚拟内存区域(vma)是否可访问。
如果两个条件都满足,它调用名为do_huge_pmd_numa_page(&vmf)的函数。
这个函数可能处理当发生透明大页面故障并且访问被允许时的情况。*/
if (pmd_protnone(vmf.orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&vmf);
/*如果pmd条目不可写并且页面是脏的(已修改),则执行此代码块。
它检查页面是否可写(!pmd_write(vmf.orig_pmd))并且页面是否脏。
如果两个条件都为真,它调用wp_huge_pmd(&vmf),这可能处理当遇到脏大页面时的情况。
如果ret(wp_huge_pmd(&vmf)的返回值)不包含VM_FAULT_FALLBACK标志,它返回ret。*/
if (dirty && !pmd_write(vmf.orig_pmd)) {
ret = wp_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
/*如果pmd条目可写或页面不是脏的,则执行此代码块。
它调用huge_pmd_set_accessed(&vmf),这可能更新大页面的访问位,
表示已访问该页面。然后,它返回0,表示已成功处理页面故障,而无需从磁盘加载数据。*/
huge_pmd_set_accessed(&vmf);
return 0;
}
}
}
/*如果之前的条件都不满足,代码会回退到处理页面表项(PTE)级别的页面故障。
它调用handle_pte_fault(&vmf)函数,这可能处理常规(非大)页面故障。*/
return handle_pte_fault(&vmf);
}
其中struct vm_fault结构体被定义在/include/linux/mm.h文件中,所包含成员如下:
struct vm_fault {
const struct {
struct vm_area_struct *vma; /* Target VMA */
gfp_t gfp_mask; /* gfp mask to be used for allocations */
pgoff_t pgoff; /* Logical page offset based on vma */
unsigned long address; /* Faulting virtual address */
};
enum fault_flag flags; /* FAULT_FLAG_xxx flags
* XXX: should really be 'const' */
pmd_t *pmd; /* Pointer to pmd entry matching
* the 'address' */
pud_t *pud; /* Pointer to pud entry matching
* the 'address'
*/
union {
pte_t orig_pte; /* Value of PTE at the time of fault */
pmd_t orig_pmd; /* Value of PMD at the time of fault,
* used by PMD fault only.
*/
};
struct page *cow_page; /* Page handler may use for COW fault */
struct page *page; /* ->fault handlers should return a
* page here, unless VM_FAULT_NOPAGE
* is set (which is also implied by
* VM_FAULT_ERROR).
*/
/* These three entries are valid only while holding ptl lock */
pte_t *pte; /* Pointer to pte entry matching
* the 'address'. NULL if the page
* table hasn't been allocated.
*/
spinlock_t *ptl; /* Page table lock.
* Protects pte page table if 'pte'
* is not NULL, otherwise pmd.
*/
pgtable_t prealloc_pte; /* Pre-allocated pte page table.
* vm_ops->map_pages() sets up a page
* table from atomic context.
* do_fault_around() pre-allocates
* page table to avoid allocation from
* atomic context.
*/
};
未完,待续………















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









