







这个模块是预测程序执行时间的基础。要预测程序执行时间,需要了解两个方面的信息
(1)程序信息:程序的复杂程度
(2)运行环境信息:运行程序的系统当前的状况
其中,程序信息在本设计中,用时间权值来估计。 参考文献资料,设计出一套不同操作占用的时钟数权重指标,并且在特定的网格计算环境中进行了测试和验证。下表中WT列表示权重系数,此值是各个操作占用的时钟数与“+”操作占用的时钟数的比值。
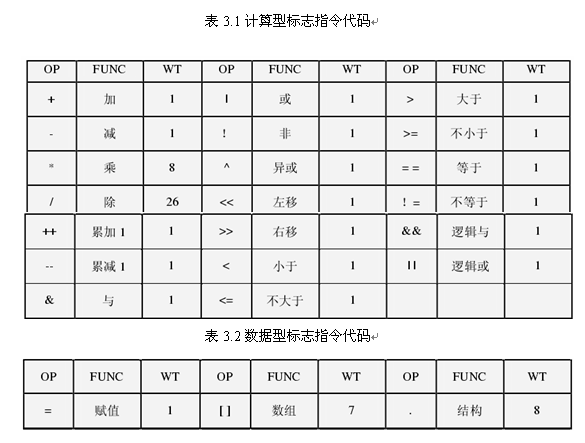
关于程序代码分析,目前只是一个粗略的分析过程,得到的分析结果不是十分精确,主要的设计思想是:
采用程序遍历的方法,统计程序代码中的各种指令数目,参照上表中的WT值,得到程序代码的总WT值,作为衡量该程序代码运算量的参数。程序中的分支部分参照参考文献的做法,其具体实现方案为:
识别出表表中列出的操作代码以后,则将相应的累加器递加。这种情况适用于严格的顺序结构的代码。但是对于分支结构代码,如if{}else{}或switch{case 1,case 2,...,case n},如果前提条件为假,一些分支代码则不会执行,在这种情况下,这些分支代码不应统计在内。不幸的是,只有在运行时才能确定分支条件到底是真还是假,而且条件的真假也可能随着程序的执行而发生变化。我们用概率来处理这种情况,对于if{}else{}语句,每个分支被执行的概率为1/2,switch{case l , case 2,..., case n}语句中每个分支的执行概率为1/n。现在考虑循环语句,情况变得较为复杂一些。如果编译时能够决定迭代的总次数m,则循环体中的每条语句均被计数m次,但是对于while{}来说,我们无法得知其何时才会终结,也就无从知晓其迭代次数,此时就要借助于经验了,我们取其迭代次数为1或100。从算法的执行效果来看,确实达到了判定程序密集类型的目标。
这样,由于充分考虑了循环结构中的所有运算量,因此得到的参数里已经包含了该程序时间复杂度的信息,所以不需要再单独计算代码的时间复杂度。
用C++编写一个分析C程序的算法,以下源代码在VISUAL STUDIO 2008中调试通过:
- #include <stdio.h>
- #include <ctype.h>
- #include <string.h>
- #include <conio.h>
- #include <stdlib.h>
- #define PRO_MAX_LEN 20480 //源程序最大长度
- #define STR_MAX_LEN 300 //标识符最大长度
- #define STB_MAX_LEN 10000 //单词表最大容量
- #define BLOCK_MAX_NUM 1000 //最多块数
- #define KEYWORD_LEN 32 //保留字个数
- #define OP_LEN 51 //指令代码的个数
- int 循环体默认计数 = 50; //循环体 无法判断循环次数时,默认循环 “循环体默认计数” 次
- int if块分支数(int if位置,int *if终点);
- char proBuffer[PRO_MAX_LEN] = ""; //存储程序代码的全局缓冲区
- char wordget[STR_MAX_LEN]; //标识符 或 常量
- char wordTab[STB_MAX_LEN][STR_MAX_LEN]; //符号表
- float 单词表长度=0;
- char 块名表[BLOCK_MAX_NUM][STR_MAX_LEN],顺序块名表[BLOCK_MAX_NUM][STR_MAX_LEN];
- int 块开始位置[BLOCK_MAX_NUM],块结束位置[BLOCK_MAX_NUM],块表长度=0,顺序块开始位置[BLOCK_MAX_NUM],顺序块结束位置[BLOCK_MAX_NUM];
- float 块权值[BLOCK_MAX_NUM];
- bool 是否发现语法错误 = false;
- char 关键字表[KEYWORD_LEN][10]={ //保留字表 C语言一共有32个保留字[关键字]
- "auto"/*0*/, "break"/*1*/, "case"/*2*/, "char"/*3*/, "const"/*4*/,
- "continue"/*5*/, "default"/*6*/, "do"/*7*/, "float"/*8*/, "else"/*9*/,
- "enum"/*10*/, "extern"/*11*/, "float"/*12*/, "for"/*13*/, "goto"/*14*/,
- "if"/*15*/, "int"/*16*/, "long"/*17*/, "register"/*18*/, "return"/*19*/,
- "short"/*20*/, "signed"/*21*/, "sizeof"/*22*/, "static"/*23*/, "struct"/*24*/,
- "switch"/*25*/, "typedef"/*26*/, "union"/*27*/, "unsigned"/*28*/, "void"/*29*/,
- "volatile"/*30*/, "while"/*31*/};
- char 操作指令表[OP_LEN][10]={ //指令代码的个数
- "+", "-", "*", "/", "|",
- "!", "^", "<<", ">", ">=",
- "==", "!=", "++", "--", "&",
- ">>", "<", "<=", "&&", "||",
- "=", "[", ".", "fopen", "fclose",
- "fgets", "fptf", "scanf", "fputs", "fread",
- "fwrite", "fscanf", "printf", "+=" };
- double 指令相对权值[OP_LEN]={0.01,0.01,0.08,0.26,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.07,0.08,8.67,2.98,1.59,4.02,28.91,1.73,2.33,2.86,3.48,36.88,0.01};
- bool 是否输出详情 = false;
- FILE *fin, *fout;
- char ch;
- float 指针;
- int 单词表指针 = 0;
- float 权值总数 = 0;
- bool 是否为数字(char *str)
- {
- int i=0;
- while(str[i]!='/0')
- {
- if(!isdigit(str[i]))
- return false;
- i++;
- }
- return true;
- }
- int 返回字串长度(char *str)
- {
- int i=0;
- while(str[i] != '/0') i++;
- return i;
- }
- int 字串变数字(char *str)
- {
- int i=0,sum=0,temp,j=0,len;
- len = 返回字串长度(str);
- while( i < len )
- {
- temp=(int)str[i];
- temp-=48;
- for(j=i;j<len-1;j++)
- {
- temp *= 10;
- }
- sum += temp;
- i++;
- }
- return sum;
- }
- void 发现语法错误()
- {
- 是否发现语法错误 = true;
- if(是否输出详情)
- {
- printf("/n发现语法错误/n");
- }
- //exit(0);
- }
- bool 读入程序()
- {
- char c;
- if ((fin=fopen("Test.c","r")) == NULL)
- {
- if(是否输出详情)
- {
- printf("Cannot open infile/n");
- }
- return false;
- }
- int i = 0;
- while((c = fgetc(fin)) != EOF)
- {
- if(i >= PRO_MAX_LEN-1)
- {
- if(是否输出详情)
- {
- printf("/n程序代码太长,无法处理/a");
- }
- return 0;
- }
- proBuffer[i++] = c;
- }
- fclose(fin); //关闭文件
- proBuffer[i++] = '/0';
- return true;
- }
- bool 读入程序1(char *source)
- {
- char c;
- int i = 0;
- while((c = source[i]) != '/0')
- {
- proBuffer[i++] = c;
- }
- proBuffer[i++] = '/0';
- return true;
- }
- char 获得字符(int point)
- {
- char ch;
- if(point < PRO_MAX_LEN && proBuffer[point] != '/0')
- {//如果当前下标合法且当前字符为结束标记则取字符增游标
- ch = proBuffer[point];
- //if (ch == '/n')
- // errorLine ++;
- return ch;
- }
- ch = '/0';
- return ch;
- }
- char 获得非空字符(int *point)//读到文件末尾 返回'/0' 否则返回当前指针所指最近的一个非空字符
- {
- char c;
- do
- {
- c=获得字符(*point);
- if(isspace(c))
- {
- *point+=1;
- }
- if(c=='/0') //读到文件末尾
- {
- c = '/0';
- return c;
- }
- }while(isspace(c)); //直到获得一个非空白字符
- return c;
- }
- void 预处理()
- {
- int lines=0;
- char tmp[PRO_MAX_LEN]; //先将处理结果保存到临时空间,这样虽然浪费空间但是节约
- //时间
- int tmpp = 0; //这个临时空间的末尾指针
- char flg;
- char flg1;
- char tmpc;
- int point = 0;
- //去掉注释
- //注释有两种 一种是C++风格的// 另一种是C风格的/**/
- do
- {
- flg = 获得字符(point);
- point++;
- if(flg == '/')
- {
- flg = 获得字符(point);
- point++;
- switch(flg)
- {
- case '/'://如果‘/’后面接一个‘/’ 就是注释
- do
- {
- flg = 获得字符(point);
- point++;
- }while(!(flg == '/n' || flg == '/0'));// || ch == '/0'));//注释一直到行尾或文件结束
- if(flg == '/n')
- point--; //归还换行
- break;
- case '*':
- do
- {
- flg = 获得字符(point); //flg=前一个字符
- point++;
- tmpc = flg;
- //为了保证出错处理程序能正确定位出错位置 保留注释中的换行
- if(tmpc == '/n')
- tmp[tmpp++] = tmpc;
- flg1 = 获得字符(point);//flg1=后一个字符
- }while(flg != '/0' && !( tmpc == '*' && flg1 == '/'));
- flg = 获得字符(point);
- point++;
- if (flg == '/0')
- {
- //ProcError(5);===========================================================================------------------
- //"注释丢失'*/'"
- }
- break;
- default:
- //不是任何一种注释
- point--;
- point--;
- flg = 获得字符(point);
- point++;
- tmp[tmpp++] = flg;
- flg = 获得字符(point);
- point++;
- tmp[tmpp++] = flg;
- }
- }
- else
- {
- tmp[tmpp++] = flg;
- }
- }while(flg != '/0');
- tmp[tmpp] = '/0';
- strcpy(proBuffer,tmp);
- }
- bool 获得单词(int *point)
- {
- int code, value;
- char judge; //这里有个技巧
- int i = 0; //辅助
- ch = 获得非空字符(point);//获取一个非空字符 赋值给ch
- if(ch == '/0') return false;//读到了文件尾,则退出
- if (isalpha(ch) || ch == '_')
- {
- judge='L'; //如果ch是“字母”或者“下划线” judge 赋值为L (letter)
- }
- else if (isdigit(ch))
- {
- judge='D'; //如果ch是“数字” judge 赋值为D (digit)
- }else
- {
- judge=ch;
- }
- switch(judge)
- {
- case 'L': //ch 是字母时
- {
- *point+=1;
- while(isalnum(ch) || ch == '_') //只要ch是字母、数字、下划线 则循环()
- { //标识符
- wordget[i++] = ch; //将ch放到wordget中去形成单词
- ch=获得字符(*point);
- *point+=1;
- }
- wordget[i] = '/0';//成字符串
- *point-=1; //回退一个字符
- /*
- code = Reserve(wordget);//对wordget字符串查找保留字表 若是一个保留字-返回其编码 否则返回0
- if(code == 0)//wordget这个单词不是一个保留字
- {
- value = InsertId(wordget);//将str串以标识符插入符号表,并返回符号表指针(如果str在符号表中存在 则返回存在的指针)
- pDu->kind = ID; //这个单词的类型为“标识符” ID 33
- pDu->value = value; //其值为 在符号表中的指针位置
- }
- else//wordget这个单词是一个保留字
- {
- pDu->kind = code; //类型为保留字在保留字表中的位置
- pDu->value = -1; //其值为-1
- if(0 == strcmp("for", wordget))
- {
- //printf("dddddff:%d--%d",forstart(point),point);
- printf("发现一个for循环,/"(/"开始位置%d,/"{/"位置:%d,/"}/"位置:%d:/n",point,forstart(point),forblock(forstart(point)));
- getBlocksoWT(forstart(point),forblock(forstart(point)),pDu,fin, fout);
- }
- }
- updatesoWT(wordget);
- */
- return true;
- }
- case 'D': //ch是数字时
- *point+=1;
- while(isdigit(ch))//只要下一个字符是数字 则和这个数字连成一个单词
- {
- wordget[i++] = ch;
- ch=获得字符(*point);
- *point+=1;
- }
- wordget[i] = '/0';//成字串
- *point-=1;
- /*
- value = InsertConst(wordget);//将str串以常数插入常量表,并返回常数表指针(如果str在常量表中存在 则返回存在的指针)
- pDu->kind = CONST; //类型为“常量” 34
- pDu->value= value; //其值为wordget在常量表中的指针位置
- */
- return true;
- //以下为ch为一下符号的情况( ) [ ] . , ! != ~ sizeof < << <= > >> >= = == & && &= | || |= ?: + ++ +=
- // - -> -- -= * *= / /= % %= >>= <<= ^ ^=
- case '"': //ch是"时 接下来的应该是个字符串
- //字符串常量
- do
- {
- wordget[i++] = ch;
- *point+=1;
- ch=获得字符(*point);
- }while(ch != '"' && ch != '/0');// 将“”中的字符串 放入到wordget中去
- wordget[i++] = ch;
- wordget[i] = '/0';//变成字串
- *point+=1;
- /*
- if(ch == '/0')
- {
- printf("%s",wordget);
- ProcError(3); //不正确的字符串表达
- pDu->kind = ERROR; //类型0
- pDu->value = 0; //值 0
- }
- else
- {
- value = InsertConst(wordget); //将wordget串以常数插入常量表,并返回常数表指针
- pDu->kind = CONST; //类型 常数
- pDu->value = value; //值 在常数表中的位置
- }
- */
- return true;
- //字符常量
- case '/''://ch是'时 接下来的应该是个字符常量
- wordget[i++] = ch; // '
- ch=获得字符(++*point);
- wordget[i++] = ch;
- if(ch == '//') // '/n'
- {//如果是转义字符则要多接收一个字符
- ch=获得字符(++*point); // ch = '
- wordget[i++] = ch;
- }
- ch=获得字符(++*point);
- wordget[i++] = ch;
- wordget[i] = '/0';//编程字串 '/n'/0
- *point+=1;
- /*
- if(ch != '/'')//'号不配对 则不对
- {//'/b'
- printf("%s",wordget);
- ProcError(2); //非法的字符
- pDu->kind = ERROR;
- pDu->value = 0;
- }
- else
- {
- value = InsertConst(wordget); //将wordget串以常数插入常量表,并返回常数表指针
- pDu->kind = CONST;
- pDu->value = value;
- }*/
- return true;
- case '(':
- case ')':
- case '[':
- case ']':
- case '.':
- case ',':
- case '~':
- case '?':
- case ':':
- case ';':
- case '{':
- case '}':
- case '#':
- wordget[i++] = ch;
- wordget[i] = '/0';
- *point+=1;
- /*
- pDu->kind = DIVIDE; //界符
- pDu->value = -1; //界符的时候 -1
- */
- return true;
- case '!':
- //!=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch=='=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '<':
- // << <=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '<' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '>':
- // >> >=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '>' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '=':
- // ==
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '&':
- // && &=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- //if (ch == '&' || ch == '=') wordget[i++] = ch;
- if (ch !=' ') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '|':
- // || |=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '|' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '+':
- // ++ +=
- wordget[i++] = ch;
- ch=获得字符(++(*point));
- if (ch == '+' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '-':
- // -- -= ->
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '-' || ch == '=' || ch == '>') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '*':
- // ** *=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '*' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '/':
- // /=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '%':
- // %=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '^':
- // ^=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '/0':
- return false;
- default:
- //ProcError(1);
- return false;
- }
- //updatesoWT(wordget);
- //pDu->kind = OPERAT;
- *point+=1;
- return true;
- }
- void 寻找程序块名(int 开始左括号位置)
- {
- }
- int 返回右括号配对(int 右括号位置)
- {
- int flag = 0;//表示开始默认搜索(
- int i = 右括号位置-1;
- while(i > 0)
- {
- if(0 == strcmp(")", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp("(", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp("(", wordTab[i])&&flag==0)
- {
- return i;
- }
- i--;
- }
- return -1;
- }
- int 返回左括号配对(int 左括号位置)
- {
- int flag = 0;//表示开始默认搜索)
- int i = 左括号位置+1;
- while(i < 单词表长度)
- {
- if(0 == strcmp("(", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp(")", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp(")", wordTab[i])&&flag==0)
- {
- return i;
- }
- i++;
- }
- return -1;
- }
- int 返回左大括号配对(int 左大括号位置)
- {
- int flag = 0;//表示开始默认搜索}
- int i = 左大括号位置+1;
- while(i < 单词表长度)
- {
- if(0 == strcmp("{", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp("}", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp("}", wordTab[i])&&flag==0)
- {
- return i;
- }
- i++;
- }
- return -1;
- }
- void 分割程序()
- {
- int flag = 0;//表示开始默认搜索{
- int i = 0;
- while(i<单词表长度)
- {
- if(0 == strcmp("{", wordTab[i])&&flag==0)//发现一级{
- {
- if(0 == strcmp(")", wordTab[i-1]))//只有{前紧跟着()的才是一个块,块一般是指函数
- {
- int ff = 返回右括号配对(i-1)-1;
- strcpy(块名表[块表长度], wordTab[ff]);
- 块开始位置[块表长度]=i;
- 块结束位置[块表长度]=返回左大括号配对(i);
- //printf("发现一个块,块名字:%s,块开始位置:%d,结束位置:%d",wordTab[ff],i,返回左大括号配对(i));
- if(是否输出详情)
- {
- printf("/n发现一个块,块名字:%s,块开始位置:%d,结束位置:%d",块名表[块表长度],块开始位置[块表长度],块结束位置[块表长度]);
- }
- 块表长度++;
- flag++;//表示开始搜索这个{匹配的}
- }
- }
- if(0 == strcmp("{", wordTab[i])&&flag>0)//发现非一级{
- {
- flag++;
- }
- if(0 == strcmp("}", wordTab[i])&&flag>1)
- {
- flag--;
- }
- if(0 == strcmp("}", wordTab[i])&&flag==1)
- {
- flag--;
- }
- i++;
- }
- }
- void 插入单词表(char *str)
- {
- strcpy(wordTab[单词表指针++], str);
- //return (pointCTB-1);
- }
- void 建立单词表()
- {
- int 指针 = 0;
- while(获得单词(&指针))
- {
- 插入单词表(wordget);
- 单词表长度++;
- }
- }
- int 查关键字表(char *str)
- {
- int i;
- for(i=0; i<KEYWORD_LEN; ++i) //从保留字表中查找str串
- {
- if(0 == strcmp(关键字表[i], str))
- return i;
- }
- return -1;
- }
- int 查函数名表(char *str)
- {
- int i;
- for(i = 0; i < 块表长度; ++i) //从函数名表中查找str串
- {
- if(0 == strcmp(顺序块名表[i], str))
- return i;
- }
- return -1;
- }
- float 查指令表返回权值(char *str)
- {
- int i;
- int 位置 = -1;
- for(i=0; i<OP_LEN; ++i) //从保留字表中查找str串
- {
- if(0 == strcmp(操作指令表[i], str))
- 位置 = i;
- }
- if(位置 == -1)
- {
- return -1;
- }else
- {
- return 指令相对权值[位置];
- }
- }
- int 分析for起点(int for位置)
- {
- int 分析点 = for位置+1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点=返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析for终点(int for位置)
- {
- int 分析点 = 分析for起点(for位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else if(0 == strcmp("if", wordTab[分析点]))
- {
- int if的终点;
- if块分支数(分析点,if的终点);
- return if的终点;
- }
- else if(0 == strcmp("for", wordTab[分析点]))
- {
- return 分析for终点(分析点);
- }
- else
- {//for后面没有{}块 只跟一条语句
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }
- return 分析点;
- }
- }
- int 分析for条件点(int for位置)
- {
- int 分析点 = for位置 + 1;
- while(0 != strcmp(";", wordTab[分析点]))
- {//找到第一个";"
- 分析点++;
- }
- 分析点++;
- while(0 != strcmp(";", wordTab[分析点]))
- {//找到第二个";"
- 分析点++;
- }
- return 分析点;
- }
- int 分析for循环次数(int for位置)
- {
- int 分析点 = for位置+1;
- int 开始条件,结束条件,次数;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- /**
- for(i=0;i<n;i++) 只能分析一下这个情况下的循环次数,并且只有n是一个常数的时候才分析
- */
- if( (0 == strcmp(wordTab[分析点+1], wordTab[分析点+5])) && (0 == strcmp(wordTab[分析点+5], wordTab[分析点+9])) && 是否为数字(wordTab[分析点+3]) && 是否为数字(wordTab[分析点+7]) && ((0 == strcmp("++", wordTab[分析点+10]))||(0 == strcmp("--", wordTab[分析点+10]))))
- {
- 结束条件 = 字串变数字(wordTab[分析点+7]);
- 开始条件 = 字串变数字(wordTab[分析点+3]);
- if(0 == strcmp("++", wordTab[分析点+10]))
- {
- 次数 = 结束条件-开始条件;
- }else
- {
- 次数 = 开始条件-结束条件;
- }
- if(次数>0)
- return 次数;
- else
- return 0;//起始条件都不满足 则这个循环不开始
- }else//其他的情况不好分析,默认循环“循环体默认计数”次,这个参数应该是个可以调整的多次调整以得到最好的预测结果
- {
- return 循环体默认计数;
- }
- }else
- {
- 发现语法错误();
- return -1;
- }
- }
- int 分析if起点(int if位置)
- {
- int 分析点 = if位置+1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点=返回左括号配对(分析点) + 1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 块后面一个单词(int 块起点)
- {
- int 分析点;
- 分析点 = 块起点;//此时分析点在if条件括号后面一个单词
- if(0==strcmp("{",wordTab[分析点]))
- {//if语句后面有{}
- 分析点=返回左大括号配对(分析点);
- }else
- {//if语句后面直接接一个语句的
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }//循环完后 分析点 指向;
- }
- return ++分析点;
- }
- int if块分支数(int if位置,int *if终点)
- {
- int 分支 = 1;
- int 块结束下一位置 = 块后面一个单词(分析if起点(if位置));
- while(0==strcmp("else",wordTab[块结束下一位置]))
- {
- 分支++;
- if(0 == strcmp("if",wordTab[块结束下一位置+1]))
- {
- 块结束下一位置 = 块后面一个单词(分析if起点(块结束下一位置+1));
- }else
- {
- 块结束下一位置 = 块后面一个单词(块结束下一位置+1);
- break;
- }
- }
- *if终点 = 块结束下一位置-1;
- if(分支 == 1) 分支 = 2;
- return 分支;
- }
- int 分析while起点(int while位置)
- {
- int 分析点 = while位置 + 1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点 = 返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析while终点(int while位置)
- {
- int 分析点 = 分析while起点(while位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else
- {//for后面没有{}块 只跟一条语句
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }
- return 分析点;
- }
- }
- int 分析switch起点(int switch位置)
- {
- int 分析点 = switch位置 + 1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点 = 返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析switch终点(int switch位置)
- {
- int 分析点 = 分析switch起点(switch位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else
- {
- 发现语法错误();
- return -1;
- }
- }
- int switch分支数(int switch起点,int switch终点)
- {
- int 分析点 = switch起点;
- int sum=0;
- while(分析点 <= switch终点)
- {
- if(0 == strcmp("case", wordTab[分析点]))
- {
- sum++;
- }
- 分析点++;
- }
- return sum;
- }
- float 顺序分析(int 起点,int 终点)
- {
- float 该块权值 = 0.0;
- int 当前分析点=起点;
- while(当前分析点 < 终点)
- {
- switch(查关键字表(wordTab[当前分析点]))
- {
- case 13://for
- {
- int forend = 分析for终点(当前分析点);
- int forbegin = 分析for起点(当前分析点);
- if(forbegin != -1)
- {
- int div= 分析for条件点(当前分析点);
- int times = 分析for循环次数(当前分析点);
- int forblockWT = 顺序分析(div,forend);
- int forst = 顺序分析(当前分析点+1,div);
- 该块权值 += forst;
- 该块权值 += times * forblockWT;
- 当前分析点 = forend;
- if(是否输出详情)
- {
- printf("/nfor语句的起点:%d 终点:%d 这个FOR语句的循环次数:%d,该for语句块的权值:%d,总权值 = 条件权值 + for语句块的权值 * 循环次数(%d = %d + %d * %d)",forbegin,forend,times,forblockWT,该块权值,forst,forblockWT,times);
- }
- //该块权值 += 顺序分析(当前分析点,div) + 分析for循环次数(当前分析点) * (顺序分析(div,forend));
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- break;
- }
- case 15://if
- {
- if(0 != strcmp("else",wordTab[当前分析点-1])){
- //如果当前IF是一个if块的第一个if,而不是分支中的 else if
- int if结束点 = 0 ;
- int if起点 = 分析if起点(当前分析点);
- int if分支数 = if块分支数(当前分析点,if结束点);
- if(if起点 != -1)
- {
- if(是否输出详情)
- {
- printf("/n发现一个if,该if开始位置:%d 分支数为%d,-----",if起点,if分支数);
- printf("/n该if块结束位置为:%d,",if结束点);
- }
- 该块权值 += 顺序分析(if起点,if结束点)/if分支数;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- 当前分析点 = if结束点;
- }
- break;
- }
- case 31://while
- {
- int whilebegin = 分析while起点(当前分析点);
- if(whilebegin != -1)
- {
- int whileend = 分析while终点(当前分析点);
- if(是否输出详情)
- {
- printf("/nwhile语句的起点:%d 终点:%d ",whilebegin,whileend);
- }
- 该块权值 += 循环体默认计数 * 顺序分析(whilebegin,whileend);
- 当前分析点 = whileend;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- break;
- }
- case 25://switch
- { int switchbegin = 分析switch起点(当前分析点);
- int switchend = 分析switch终点(当前分析点);
- int fenzhi = switch分支数(switchbegin,switchend);
- if((switchbegin != -1) && (switchend != -1))
- {
- if(是否输出详情)
- {
- printf("/n发现一个switch,该switch开始位置:%d 分支数为%d,-----",switchbegin,fenzhi);
- printf("/n该if块结束位置为:%d,",switchend);
- }
- 该块权值 += (顺序分析(switchbegin,switchend) / fenzhi);
- 当前分析点 = switchend;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- }
- case -1://不是一个关键字
- {
- int temp = 查函数名表(wordTab[当前分析点]);
- if(temp != -1)
- {//如果是一个函数,则用前面分析到的这个函数的权值 作为这个关键字的权值
- if(是否输出详情)
- {
- printf("/n发现一个函数,当前分析点:%d, 函数名:%s:权值: %f/n",当前分析点,wordTab[当前分析点],块权值[temp]);
- }
- 该块权值 += 块权值[temp];
- }
- else if(查指令表返回权值(wordTab[当前分析点]) != -1)
- {
- if(是否输出详情)
- {
- printf("/n当前分析点:%d, 单词:%s:权值: %f=====%f/n",当前分析点,wordTab[当前分析点],查指令表返回权值(wordTab[当前分析点]),该块权值);
- }
- 该块权值 += 查指令表返回权值(wordTab[当前分析点]);
- }
- }
- default:break;
- }
- 当前分析点++;
- }
- return 该块权值;
- }
- int 按函数名查找函数表(char *str)//如果在函数表里 就返回在“块名表”里的位置
- {
- int i;
- for(i=0;i<块表长度;i++)
- {
- if(0 == strcmp(str,块名表[i]))
- {
- return i;
- }
- }
- return -1;
- }
- void 块名表调序(int 新顺序,int 老位置)
- {
- //顺序块名表[新顺序] = 块名表[老位置];
- strcpy(顺序块名表[新顺序],块名表[老位置]);
- strcpy(块名表[老位置],"");
- 顺序块开始位置[新顺序] = 块开始位置[老位置];
- 顺序块结束位置[新顺序] = 块结束位置[老位置];
- }
- void 按函数出现顺序排序()
- {
- int 当前分析点 = 0;
- int i=0,j=0;
- while(当前分析点 < 单词表长度)
- {
- i = 按函数名查找函数表(wordTab[当前分析点]);
- if(i != -1)
- {
- 块名表调序(j,i);
- j++;
- }
- 当前分析点++;
- }
- }
- float getSourceWT(int times,bool isprint)
- {
- 循环体默认计数 = times;
- 是否输出详情 = isprint;
- int i=0;
- char c;
- 读入程序();
- //读入程序1(source);
- //char* csStr = env->GetStringUTFChars(str,NULL);
- //char* csStr = GetStringUTFChars(
- 预处理();
- 建立单词表();
- 分割程序();
- 按函数出现顺序排序();
- for(int i=0;i<块表长度;i++)
- {
- 块权值[i] = 顺序分析(顺序块开始位置[i],顺序块结束位置[i]);
- }
- if(是否输出详情)
- {
- for(int i=0;i<块表长度;i++)
- {
- printf("/n块信息:/n%s:%d---%d/n",顺序块名表[i],顺序块开始位置[i],顺序块结束位置[i]);
- printf("权值:%f",块权值[i]);
- }
- }
- if(是否发现语法错误)
- {
- return -1;
- }
- else
- {
- for(int i=0;i<块表长度;i++)
- {
- if(0==strcmp("main",顺序块名表[i]))
- {
- return 块权值[i];
- }
- }
- //没有main块 ,也算是语法错误
- return -1;
- }
- }
- int main()
- {
- printf("权值---->:%f",getSourceWT(90,false));
- printf("/n写入完毕/n按任意键继续/n"); getch();
- return 0;
- }
getSourceWT(int times,bool isprint)函数中的两个参数:
第一个提供外部修改“默认循环次数”的接口,在以后的预测过程中调整这个数值,以与期望的预测时间更接近
第二个参数方便调试用,如果要查看具体的分析过程,可以设置这个值为真,则在命令管理器中会输出分析过程。
下面是JNI改造:
步骤一:在“C:/c/com/swjtu/sourcemanage”里建立文件SourceScan.java,文件代码如下:
- package com.swjtu.sourcemanage;
- public class SourceScan {
- public static native double getSourceWT(int times,boolean isprint,String source);
- static
- {
- System.loadLibrary("SourceScan");
- }
- }
步骤二:点击“开始”——>“运行”——>cmd 敲命令 Microsoft Windows XP [版本 5.1.2600]
(C) 版权所有 1985-2001 Microsoft Corp.
C:/Documents and Settings/Administrator>cd c:/c
C:/c>cd com/swjtu/sourcemanage
C:/c/com/swjtu/sourcemanage>javac SourceScan .java
C:/c/com/swjtu/sourcemanage>cd c:/c
C:/c>javah com.swjtu.sourcemanage.SourceScan
C:/c>
注:javah命令在c:/c文件夹下生成了com_swjtu_sourcemanage_SourceScan.h头文件,文件代码如下:
- /* DO NOT EDIT THIS FILE - it is machine generated */
- #include <jni.h>
- /* Header for class com_swjtu_sourcemanage_SourceScan */
- #ifndef _Included_com_swjtu_sourcemanage_SourceScan
- #define _Included_com_swjtu_sourcemanage_SourceScan
- #ifdef __cplusplus
- extern "C" {
- #endif
- /*
- * Class: com_swjtu_sourcemanage_SourceScan
- * Method: getSourceWT
- * Signature: (IZLjava/lang/String;)D
- */
- JNIEXPORT jdouble JNICALL Java_com_swjtu_sourcemanage_SourceScan_getSourceWT
- (JNIEnv *, jclass, jint, jboolean, jstring);
- #ifdef __cplusplus
- }
- #endif
- #endif
步骤三:在文件夹“C:/c”建立com_swjtu_sourcemanage_SourceScan.cpp文件,这个文件是上面的经过一些小修改而成的,为可以被JAVA调用的DLL源代码,文件内容如下:
- #include "com_swjtu_sourcemanage_SourceScan.h"
- #include <stdio.h>
- #include <ctype.h>
- #include <string.h>
- #include <conio.h>
- #include <stdlib.h>
- #define PRO_MAX_LEN 20480 //源程序最大长度
- #define STR_MAX_LEN 300 //标识符最大长度
- #define STB_MAX_LEN 10000 //单词表最大容量
- #define BLOCK_MAX_NUM 1000 //最多块数
- #define KEYWORD_LEN 32 //保留字个数
- #define OP_LEN 51 //指令代码的个数
- int 循环体默认计数 = 50; //循环体 无法判断循环次数时,默认循环 “循环体默认计数” 次
- int if块分支数(int if位置,int *if终点);
- char proBuffer[PRO_MAX_LEN] = ""; //存储程序代码的全局缓冲区
- char wordget[STR_MAX_LEN]; //标识符 或 常量
- char wordTab[STB_MAX_LEN][STR_MAX_LEN]; //符号表
- float 单词表长度=0;
- char 块名表[BLOCK_MAX_NUM][STR_MAX_LEN],顺序块名表[BLOCK_MAX_NUM][STR_MAX_LEN];
- int 块开始位置[BLOCK_MAX_NUM],块结束位置[BLOCK_MAX_NUM],块表长度=0,顺序块开始位置[BLOCK_MAX_NUM],顺序块结束位置[BLOCK_MAX_NUM];
- float 块权值[BLOCK_MAX_NUM];
- bool 是否发现语法错误 = false;
- char 关键字表[KEYWORD_LEN][10]={ //保留字表 C语言一共有32个保留字[关键字]
- "auto"/*0*/, "break"/*1*/, "case"/*2*/, "char"/*3*/, "const"/*4*/,
- "continue"/*5*/, "default"/*6*/, "do"/*7*/, "float"/*8*/, "else"/*9*/,
- "enum"/*10*/, "extern"/*11*/, "float"/*12*/, "for"/*13*/, "goto"/*14*/,
- "if"/*15*/, "int"/*16*/, "long"/*17*/, "register"/*18*/, "return"/*19*/,
- "short"/*20*/, "signed"/*21*/, "sizeof"/*22*/, "static"/*23*/, "struct"/*24*/,
- "switch"/*25*/, "typedef"/*26*/, "union"/*27*/, "unsigned"/*28*/, "void"/*29*/,
- "volatile"/*30*/, "while"/*31*/};
- char 操作指令表[OP_LEN][10]={ //指令代码的个数
- "+", "-", "*", "/", "|",
- "!", "^", "<<", ">", ">=",
- "==", "!=", "++", "--", "&",
- ">>", "<", "<=", "&&", "||",
- "=", "[", ".", "fopen", "fclose",
- "fgets", "fptf", "scanf", "fputs", "fread",
- "fwrite", "fscanf", "printf", "+=" };
- double 指令相对权值[OP_LEN]={0.01,0.01,0.08,0.26,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.07,0.08,8.67,2.98,1.59,4.02,28.91,1.73,2.33,2.86,3.48,36.88,0.01};
- bool 是否输出详情 = false;
- FILE *fin, *fout;
- char ch;
- float 指针;
- int 单词表指针 = 0;
- float 权值总数 = 0;
- bool 是否为数字(char *str)
- {
- int i=0;
- while(str[i]!='/0')
- {
- if(!isdigit(str[i]))
- return false;
- i++;
- }
- return true;
- }
- int 返回字串长度(char *str)
- {
- int i=0;
- while(str[i] != '/0') i++;
- return i;
- }
- int 字串变数字(char *str)
- {
- int i=0,sum=0,temp,j=0,len;
- len = 返回字串长度(str);
- while( i < len )
- {
- temp=(int)str[i];
- temp-=48;
- for(j=i;j<len-1;j++)
- {
- temp *= 10;
- }
- sum += temp;
- i++;
- }
- return sum;
- }
- void 发现语法错误()
- {
- 是否发现语法错误 = true;
- if(是否输出详情)
- {
- printf("/n发现语法错误/n");
- }
- //exit(0);
- }
- bool 读入程序()
- {
- char c;
- if ((fin=fopen("Test.c","r")) == NULL)
- {
- if(是否输出详情)
- {
- printf("Cannot open infile/n");
- }
- return false;
- }
- int i = 0;
- while((c = fgetc(fin)) != EOF)
- {
- if(i >= PRO_MAX_LEN-1)
- {
- if(是否输出详情)
- {
- printf("/n程序代码太长,无法处理/a");
- }
- return 0;
- }
- proBuffer[i++] = c;
- }
- fclose(fin); //关闭文件
- proBuffer[i++] = '/0';
- return true;
- }
- bool 读入程序1(const char *source)
- {
- char c;
- int i = 0;
- while((c = source[i]) != '/0')
- {
- proBuffer[i++] = c;
- }
- proBuffer[i++] = '/0';
- return true;
- }
- char 获得字符(int point)
- {
- char ch;
- if(point < PRO_MAX_LEN && proBuffer[point] != '/0')
- {//如果当前下标合法且当前字符为结束标记则取字符增游标
- ch = proBuffer[point];
- //if (ch == '/n')
- // errorLine ++;
- return ch;
- }
- ch = '/0';
- return ch;
- }
- char 获得非空字符(int *point)//读到文件末尾 返回'/0' 否则返回当前指针所指最近的一个非空字符
- {
- char c;
- do
- {
- c=获得字符(*point);
- if(isspace(c))
- {
- *point+=1;
- }
- if(c=='/0') //读到文件末尾
- {
- c = '/0';
- return c;
- }
- }while(isspace(c)); //直到获得一个非空白字符
- return c;
- }
- void 预处理()
- {
- int lines=0;
- char tmp[PRO_MAX_LEN]; //先将处理结果保存到临时空间,这样虽然浪费空间但是节约
- //时间
- int tmpp = 0; //这个临时空间的末尾指针
- char flg;
- char flg1;
- char tmpc;
- int point = 0;
- //去掉注释
- //注释有两种 一种是C++风格的// 另一种是C风格的/**/
- do
- {
- flg = 获得字符(point);
- point++;
- if(flg == '/')
- {
- flg = 获得字符(point);
- point++;
- switch(flg)
- {
- case '/'://如果‘/’后面接一个‘/’ 就是注释
- do
- {
- flg = 获得字符(point);
- point++;
- }while(!(flg == '/n' || flg == '/0'));// || ch == '/0'));//注释一直到行尾或文件结束
- if(flg == '/n')
- point--; //归还换行
- break;
- case '*':
- do
- {
- flg = 获得字符(point); //flg=前一个字符
- point++;
- tmpc = flg;
- //为了保证出错处理程序能正确定位出错位置 保留注释中的换行
- if(tmpc == '/n')
- tmp[tmpp++] = tmpc;
- flg1 = 获得字符(point);//flg1=后一个字符
- }while(flg != '/0' && !( tmpc == '*' && flg1 == '/'));
- flg = 获得字符(point);
- point++;
- if (flg == '/0')
- {
- //ProcError(5);===========================================================================------------------
- //"注释丢失'*/'"
- }
- break;
- default:
- //不是任何一种注释
- point--;
- point--;
- flg = 获得字符(point);
- point++;
- tmp[tmpp++] = flg;
- flg = 获得字符(point);
- point++;
- tmp[tmpp++] = flg;
- }
- }
- else
- {
- tmp[tmpp++] = flg;
- }
- }while(flg != '/0');
- tmp[tmpp] = '/0';
- strcpy(proBuffer,tmp);
- }
- bool 获得单词(int *point)
- {
- int code, value;
- char judge; //这里有个技巧
- int i = 0; //辅助
- ch = 获得非空字符(point);//获取一个非空字符 赋值给ch
- if(ch == '/0') return false;//读到了文件尾,则退出
- if (isalpha(ch) || ch == '_')
- {
- judge='L'; //如果ch是“字母”或者“下划线” judge 赋值为L (letter)
- }
- else if (isdigit(ch))
- {
- judge='D'; //如果ch是“数字” judge 赋值为D (digit)
- }else
- {
- judge=ch;
- }
- switch(judge)
- {
- case 'L': //ch 是字母时
- {
- *point+=1;
- while(isalnum(ch) || ch == '_') //只要ch是字母、数字、下划线 则循环()
- { //标识符
- wordget[i++] = ch; //将ch放到wordget中去形成单词
- ch=获得字符(*point);
- *point+=1;
- }
- wordget[i] = '/0';//成字符串
- *point-=1; //回退一个字符
- /*
- code = Reserve(wordget);//对wordget字符串查找保留字表 若是一个保留字-返回其编码 否则返回0
- if(code == 0)//wordget这个单词不是一个保留字
- {
- value = InsertId(wordget);//将str串以标识符插入符号表,并返回符号表指针(如果str在符号表中存在 则返回存在的指针)
- pDu->kind = ID; //这个单词的类型为“标识符” ID 33
- pDu->value = value; //其值为 在符号表中的指针位置
- }
- else//wordget这个单词是一个保留字
- {
- pDu->kind = code; //类型为保留字在保留字表中的位置
- pDu->value = -1; //其值为-1
- if(0 == strcmp("for", wordget))
- {
- //printf("dddddff:%d--%d",forstart(point),point);
- printf("发现一个for循环,/"(/"开始位置%d,/"{/"位置:%d,/"}/"位置:%d:/n",point,forstart(point),forblock(forstart(point)));
- getBlocksoWT(forstart(point),forblock(forstart(point)),pDu,fin, fout);
- }
- }
- updatesoWT(wordget);
- */
- return true;
- }
- case 'D': //ch是数字时
- *point+=1;
- while(isdigit(ch))//只要下一个字符是数字 则和这个数字连成一个单词
- {
- wordget[i++] = ch;
- ch=获得字符(*point);
- *point+=1;
- }
- wordget[i] = '/0';//成字串
- *point-=1;
- /*
- value = InsertConst(wordget);//将str串以常数插入常量表,并返回常数表指针(如果str在常量表中存在 则返回存在的指针)
- pDu->kind = CONST; //类型为“常量” 34
- pDu->value= value; //其值为wordget在常量表中的指针位置
- */
- return true;
- //以下为ch为一下符号的情况( ) [ ] . , ! != ~ sizeof < << <= > >> >= = == & && &= | || |= ?: + ++ +=
- // - -> -- -= * *= / /= % %= >>= <<= ^ ^=
- case '"': //ch是"时 接下来的应该是个字符串
- //字符串常量
- do
- {
- wordget[i++] = ch;
- *point+=1;
- ch=获得字符(*point);
- }while(ch != '"' && ch != '/0');// 将“”中的字符串 放入到wordget中去
- wordget[i++] = ch;
- wordget[i] = '/0';//变成字串
- *point+=1;
- /*
- if(ch == '/0')
- {
- printf("%s",wordget);
- ProcError(3); //不正确的字符串表达
- pDu->kind = ERROR; //类型0
- pDu->value = 0; //值 0
- }
- else
- {
- value = InsertConst(wordget); //将wordget串以常数插入常量表,并返回常数表指针
- pDu->kind = CONST; //类型 常数
- pDu->value = value; //值 在常数表中的位置
- }
- */
- return true;
- //字符常量
- case '/''://ch是'时 接下来的应该是个字符常量
- wordget[i++] = ch; // '
- ch=获得字符(++*point);
- wordget[i++] = ch;
- if(ch == '//') // '/n'
- {//如果是转义字符则要多接收一个字符
- ch=获得字符(++*point); // ch = '
- wordget[i++] = ch;
- }
- ch=获得字符(++*point);
- wordget[i++] = ch;
- wordget[i] = '/0';//编程字串 '/n'/0
- *point+=1;
- /*
- if(ch != '/'')//'号不配对 则不对
- {//'/b'
- printf("%s",wordget);
- ProcError(2); //非法的字符
- pDu->kind = ERROR;
- pDu->value = 0;
- }
- else
- {
- value = InsertConst(wordget); //将wordget串以常数插入常量表,并返回常数表指针
- pDu->kind = CONST;
- pDu->value = value;
- }*/
- return true;
- case '(':
- case ')':
- case '[':
- case ']':
- case '.':
- case ',':
- case '~':
- case '?':
- case ':':
- case ';':
- case '{':
- case '}':
- case '#':
- wordget[i++] = ch;
- wordget[i] = '/0';
- *point+=1;
- /*
- pDu->kind = DIVIDE; //界符
- pDu->value = -1; //界符的时候 -1
- */
- return true;
- case '!':
- //!=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch=='=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '<':
- // << <=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '<' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '>':
- // >> >=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '>' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '=':
- // ==
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '&':
- // && &=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- //if (ch == '&' || ch == '=') wordget[i++] = ch;
- if (ch !=' ') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '|':
- // || |=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '|' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '+':
- // ++ +=
- wordget[i++] = ch;
- ch=获得字符(++(*point));
- if (ch == '+' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '-':
- // -- -= ->
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '-' || ch == '=' || ch == '>') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '*':
- // ** *=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '*' || ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '/':
- // /=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '%':
- // %=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '^':
- // ^=
- wordget[i++] = ch;
- ch=获得字符(++*point);
- if (ch == '=') wordget[i++] = ch;
- else *point-=1;
- wordget[i]='/0';
- break;
- case '/0':
- return false;
- default:
- //ProcError(1);
- return false;
- }
- //updatesoWT(wordget);
- //pDu->kind = OPERAT;
- *point+=1;
- return true;
- }
- void 寻找程序块名(int 开始左括号位置)
- {
- }
- int 返回右括号配对(int 右括号位置)
- {
- int flag = 0;//表示开始默认搜索(
- int i = 右括号位置-1;
- while(i > 0)
- {
- if(0 == strcmp(")", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp("(", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp("(", wordTab[i])&&flag==0)
- {
- return i;
- }
- i--;
- }
- return -1;
- }
- int 返回左括号配对(int 左括号位置)
- {
- int flag = 0;//表示开始默认搜索)
- int i = 左括号位置+1;
- while(i < 单词表长度)
- {
- if(0 == strcmp("(", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp(")", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp(")", wordTab[i])&&flag==0)
- {
- return i;
- }
- i++;
- }
- return -1;
- }
- int 返回左大括号配对(int 左大括号位置)
- {
- int flag = 0;//表示开始默认搜索}
- int i = 左大括号位置+1;
- while(i < 单词表长度)
- {
- if(0 == strcmp("{", wordTab[i])&&flag>=0)
- {
- flag++;//表示开始搜索这个{匹配的}
- }
- else if(0 == strcmp("}", wordTab[i])&&flag>=1)
- {
- flag--;
- }
- else if(0 == strcmp("}", wordTab[i])&&flag==0)
- {
- return i;
- }
- i++;
- }
- return -1;
- }
- void 分割程序()
- {
- int flag = 0;//表示开始默认搜索{
- int i = 0;
- while(i<单词表长度)
- {
- if(0 == strcmp("{", wordTab[i])&&flag==0)//发现一级{
- {
- if(0 == strcmp(")", wordTab[i-1]))//只有{前紧跟着()的才是一个块,块一般是指函数
- {
- int ff = 返回右括号配对(i-1)-1;
- strcpy(块名表[块表长度], wordTab[ff]);
- 块开始位置[块表长度]=i;
- 块结束位置[块表长度]=返回左大括号配对(i);
- //printf("发现一个块,块名字:%s,块开始位置:%d,结束位置:%d",wordTab[ff],i,返回左大括号配对(i));
- if(是否输出详情)
- {
- printf("/n发现一个块,块名字:%s,块开始位置:%d,结束位置:%d",块名表[块表长度],块开始位置[块表长度],块结束位置[块表长度]);
- }
- 块表长度++;
- flag++;//表示开始搜索这个{匹配的}
- }
- }
- if(0 == strcmp("{", wordTab[i])&&flag>0)//发现非一级{
- {
- flag++;
- }
- if(0 == strcmp("}", wordTab[i])&&flag>1)
- {
- flag--;
- }
- if(0 == strcmp("}", wordTab[i])&&flag==1)
- {
- flag--;
- }
- i++;
- }
- }
- void 插入单词表(char *str)
- {
- strcpy(wordTab[单词表指针++], str);
- //return (pointCTB-1);
- }
- void 建立单词表()
- {
- int 指针 = 0;
- while(获得单词(&指针))
- {
- 插入单词表(wordget);
- 单词表长度++;
- }
- }
- int 查关键字表(char *str)
- {
- int i;
- for(i=0; i<KEYWORD_LEN; ++i) //从保留字表中查找str串
- {
- if(0 == strcmp(关键字表[i], str))
- return i;
- }
- return -1;
- }
- int 查函数名表(char *str)
- {
- int i;
- for(i = 0; i < 块表长度; ++i) //从函数名表中查找str串
- {
- if(0 == strcmp(顺序块名表[i], str))
- return i;
- }
- return -1;
- }
- float 查指令表返回权值(char *str)
- {
- int i;
- int 位置 = -1;
- for(i=0; i<OP_LEN; ++i) //从保留字表中查找str串
- {
- if(0 == strcmp(操作指令表[i], str))
- 位置 = i;
- }
- if(位置 == -1)
- {
- return -1;
- }else
- {
- return 指令相对权值[位置];
- }
- }
- int 分析for起点(int for位置)
- {
- int 分析点 = for位置+1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点=返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析for终点(int for位置)
- {
- int 分析点 = 分析for起点(for位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else if(0 == strcmp("if", wordTab[分析点]))
- {
- int if的终点;
- if块分支数(分析点,if的终点);
- return if的终点;
- }
- else if(0 == strcmp("for", wordTab[分析点]))
- {
- return 分析for终点(分析点);
- }
- else
- {//for后面没有{}块 只跟一条语句
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }
- return 分析点;
- }
- }
- int 分析for条件点(int for位置)
- {
- int 分析点 = for位置 + 1;
- while(0 != strcmp(";", wordTab[分析点]))
- {//找到第一个";"
- 分析点++;
- }
- 分析点++;
- while(0 != strcmp(";", wordTab[分析点]))
- {//找到第二个";"
- 分析点++;
- }
- return 分析点;
- }
- int 分析for循环次数(int for位置)
- {
- int 分析点 = for位置+1;
- int 开始条件,结束条件,次数;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- /**
- for(i=0;i<n;i++) 只能分析一下这个情况下的循环次数,并且只有n是一个常数的时候才分析
- */
- if( (0 == strcmp(wordTab[分析点+1], wordTab[分析点+5])) && (0 == strcmp(wordTab[分析点+5], wordTab[分析点+9])) && 是否为数字(wordTab[分析点+3]) && 是否为数字(wordTab[分析点+7]) && ((0 == strcmp("++", wordTab[分析点+10]))||(0 == strcmp("--", wordTab[分析点+10]))))
- {
- 结束条件 = 字串变数字(wordTab[分析点+7]);
- 开始条件 = 字串变数字(wordTab[分析点+3]);
- if(0 == strcmp("++", wordTab[分析点+10]))
- {
- 次数 = 结束条件-开始条件;
- }else
- {
- 次数 = 开始条件-结束条件;
- }
- if(次数>0)
- return 次数;
- else
- return 0;//起始条件都不满足 则这个循环不开始
- }else//其他的情况不好分析,默认循环“循环体默认计数”次,这个参数应该是个可以调整的多次调整以得到最好的预测结果
- {
- return 循环体默认计数;
- }
- }else
- {
- 发现语法错误();
- return -1;
- }
- }
- int 分析if起点(int if位置)
- {
- int 分析点 = if位置+1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点=返回左括号配对(分析点) + 1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 块后面一个单词(int 块起点)
- {
- int 分析点;
- 分析点 = 块起点;//此时分析点在if条件括号后面一个单词
- if(0==strcmp("{",wordTab[分析点]))
- {//if语句后面有{}
- 分析点=返回左大括号配对(分析点);
- }else
- {//if语句后面直接接一个语句的
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }//循环完后 分析点 指向;
- }
- return ++分析点;
- }
- int if块分支数(int if位置,int *if终点)
- {
- int 分支 = 1;
- int 块结束下一位置 = 块后面一个单词(分析if起点(if位置));
- while(0==strcmp("else",wordTab[块结束下一位置]))
- {
- 分支++;
- if(0 == strcmp("if",wordTab[块结束下一位置+1]))
- {
- 块结束下一位置 = 块后面一个单词(分析if起点(块结束下一位置+1));
- }else
- {
- 块结束下一位置 = 块后面一个单词(块结束下一位置+1);
- break;
- }
- }
- *if终点 = 块结束下一位置-1;
- if(分支 == 1) 分支 = 2;
- return 分支;
- }
- int 分析while起点(int while位置)
- {
- int 分析点 = while位置 + 1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点 = 返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析while终点(int while位置)
- {
- int 分析点 = 分析while起点(while位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else
- {//for后面没有{}块 只跟一条语句
- while(0 != strcmp(";", wordTab[分析点]))
- {
- 分析点++;
- }
- return 分析点;
- }
- }
- int 分析switch起点(int switch位置)
- {
- int 分析点 = switch位置 + 1;
- if(0 == strcmp("(", wordTab[分析点]))
- {
- 分析点 = 返回左括号配对(分析点)+1;
- }else
- {
- 发现语法错误();
- return -1;
- }
- return 分析点;
- }
- int 分析switch终点(int switch位置)
- {
- int 分析点 = 分析switch起点(switch位置);
- if(0 == strcmp("{", wordTab[分析点]))//for块 以{}出现
- {
- return 返回左大括号配对(分析点);
- }
- else
- {
- 发现语法错误();
- return -1;
- }
- }
- int switch分支数(int switch起点,int switch终点)
- {
- int 分析点 = switch起点;
- int sum=0;
- while(分析点 <= switch终点)
- {
- if(0 == strcmp("case", wordTab[分析点]))
- {
- sum++;
- }
- 分析点++;
- }
- return sum;
- }
- float 顺序分析(int 起点,int 终点)
- {
- float 该块权值 = 0.0;
- int 当前分析点=起点;
- while(当前分析点 < 终点)
- {
- switch(查关键字表(wordTab[当前分析点]))
- {
- case 13://for
- {
- int forend = 分析for终点(当前分析点);
- int forbegin = 分析for起点(当前分析点);
- if(forbegin != -1)
- {
- int div= 分析for条件点(当前分析点);
- int times = 分析for循环次数(当前分析点);
- int forblockWT = 顺序分析(div,forend);
- int forst = 顺序分析(当前分析点+1,div);
- 该块权值 += forst;
- 该块权值 += times * forblockWT;
- 当前分析点 = forend;
- if(是否输出详情)
- {
- printf("/nfor语句的起点:%d 终点:%d 这个FOR语句的循环次数:%d,该for语句块的权值:%d,总权值 = 条件权值 + for语句块的权值 * 循环次数(%d = %d + %d * %d)",forbegin,forend,times,forblockWT,该块权值,forst,forblockWT,times);
- }
- //该块权值 += 顺序分析(当前分析点,div) + 分析for循环次数(当前分析点) * (顺序分析(div,forend));
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- break;
- }
- case 15://if
- {
- if(0 != strcmp("else",wordTab[当前分析点-1])){
- //如果当前IF是一个if块的第一个if,而不是分支中的 else if
- int if结束点 = 0 ;
- int if起点 = 分析if起点(当前分析点);
- int if分支数 = if块分支数(当前分析点,if结束点);
- if(if起点 != -1)
- {
- if(是否输出详情)
- {
- printf("/n发现一个if,该if开始位置:%d 分支数为%d,-----",if起点,if分支数);
- printf("/n该if块结束位置为:%d,",if结束点);
- }
- 该块权值 += 顺序分析(if起点,if结束点)/if分支数;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- 当前分析点 = if结束点;
- }
- break;
- }
- case 31://while
- {
- int whilebegin = 分析while起点(当前分析点);
- if(whilebegin != -1)
- {
- int whileend = 分析while终点(当前分析点);
- if(是否输出详情)
- {
- printf("/nwhile语句的起点:%d 终点:%d ",whilebegin,whileend);
- }
- 该块权值 += 循环体默认计数 * 顺序分析(whilebegin,whileend);
- 当前分析点 = whileend;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- break;
- }
- case 25://switch
- { int switchbegin = 分析switch起点(当前分析点);
- int switchend = 分析switch终点(当前分析点);
- int fenzhi = switch分支数(switchbegin,switchend);
- if((switchbegin != -1) && (switchend != -1))
- {
- if(是否输出详情)
- {
- printf("/n发现一个switch,该switch开始位置:%d 分支数为%d,-----",switchbegin,fenzhi);
- printf("/n该if块结束位置为:%d,",switchend);
- }
- 该块权值 += (顺序分析(switchbegin,switchend) / fenzhi);
- 当前分析点 = switchend;
- }
- else
- {
- 当前分析点 = 单词表长度;
- }
- }
- case -1://不是一个关键字
- {
- int temp = 查函数名表(wordTab[当前分析点]);
- if(temp != -1)
- {//如果是一个函数,则用前面分析到的这个函数的权值 作为这个关键字的权值
- if(是否输出详情)
- {
- printf("/n发现一个函数,当前分析点:%d, 函数名:%s:权值: %f/n",当前分析点,wordTab[当前分析点],块权值[temp]);
- }
- 该块权值 += 块权值[temp];
- }
- else if(查指令表返回权值(wordTab[当前分析点]) != -1)
- {
- if(是否输出详情)
- {
- printf("/n当前分析点:%d, 单词:%s:权值: %f=====%f/n",当前分析点,wordTab[当前分析点],查指令表返回权值(wordTab[当前分析点]),该块权值);
- }
- 该块权值 += 查指令表返回权值(wordTab[当前分析点]);
- }
- }
- default:break;
- }
- 当前分析点++;
- }
- return 该块权值;
- }
- int 按函数名查找函数表(char *str)//如果在函数表里 就返回在“块名表”里的位置
- {
- int i;
- for(i=0;i<块表长度;i++)
- {
- if(0 == strcmp(str,块名表[i]))
- {
- return i;
- }
- }
- return -1;
- }
- void 块名表调序(int 新顺序,int 老位置)
- {
- //顺序块名表[新顺序] = 块名表[老位置];
- strcpy(顺序块名表[新顺序],块名表[老位置]);
- strcpy(块名表[老位置],"");
- 顺序块开始位置[新顺序] = 块开始位置[老位置];
- 顺序块结束位置[新顺序] = 块结束位置[老位置];
- }
- void 按函数出现顺序排序()
- {
- int 当前分析点 = 0;
- int i=0,j=0;
- while(当前分析点 < 单词表长度)
- {
- i = 按函数名查找函数表(wordTab[当前分析点]);
- if(i != -1)
- {
- 块名表调序(j,i);
- j++;
- }
- 当前分析点++;
- }
- }
- //float getSourceWT(int times,bool isprint,String str)
- JNIEXPORT jdouble JNICALL Java_com_swjtu_sourcemanage_SourceScan_getSourceWT(JNIEnv * env, jclass c1, jint times, jboolean isprint, jstring str)
- {
- 循环体默认计数 = times;
- 是否输出详情 = isprint;
- int i=0;
- char c;
- //读入程序();
- //读入程序1(source);
- //char* csStr = env->GetStringUTFChars(str,NULL);
- //char* csStr = GetStringUTFChars(
- const char* csStr = env->GetStringUTFChars(str,NULL);
- 读入程序1(csStr);
- 预处理();
- 建立单词表();
- 分割程序();
- 按函数出现顺序排序();
- for(int i=0;i<块表长度;i++)
- {
- 块权值[i] = 顺序分析(顺序块开始位置[i],顺序块结束位置[i]);
- }
- if(是否输出详情)
- {
- for(int i=0;i<块表长度;i++)
- {
- printf("/n块信息:/n%s:%d---%d/n",顺序块名表[i],顺序块开始位置[i],顺序块结束位置[i]);
- printf("权值:%f",块权值[i]);
- }
- }
- if(是否发现语法错误)
- {
- return -1;
- }
- else
- {
- for(int i=0;i<块表长度;i++)
- {
- if(0==strcmp("main",顺序块名表[i]))
- {
- return 块权值[i];
- }
- }
- //没有main块 ,也算是语法错误
- return -1;
- }
- }
- /*
- int main()
- {
- printf("权值---->:%f",getSourceWT(90,false));
- printf("/n写入完毕/n按任意键继续/n"); getch();
- return 0;
- }
- */
步骤四:生成DLL文件 使用命令:cl -IC:/include -LD com_swjtu_sourcemanage_SourceScan.cpp -FeSourceScan.dll如果执行过程中出现找不到头文件错误,则将该头文件所在目录加入到命令中(如-IC:/include,目录名不要有空格),如果执行过程出现打不开lib文件错误,则将相应的文件拷贝到C:/c文件夹下。成功后生成SourceScan.dll,将这个文件拷贝到com文件同目录。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









