







一、Storm概述
Storm是免费开源的分布式实时计算系统。实时性主要在于两方面:一方面所有运算处理都是在内存中进行,节点之间采用效率非常高的zeroMQ进行数据传输,中间数据不落地保存,避免了额外文件IO导致的时间损耗;另一方面Storm就是针对流数据处理,可以对源源不断的来源数据进行实时处理,省去了数据采集时间。Storm与Hadoop最大的区别在于Storm是针对流数据处理,而Hadoop是针对批数据进行处理,两者应用方向很大不同。目前Storm的应用非常广泛,大部分的应用场景是针对访问或操作日志进行分析处理,获取实时的统计数据,用于实时的服务监控或者相关的实时推荐。
二、Storm特性
编程模型简单:api简单方便,提供spout和bolt原语。
可扩展性:在集群中,计算任务在服务器,进程,线程方面并行运行,可以灵活水平扩展。
高可靠性:ack机制,保证消息至少可以处理一次。
高容错性:stateless and fail-fast。工作进程怪掉之后可以自动重启。如果节点挂掉,自动在其它节点重新启动工作进程。
支持多种编程语言:由于topology的定义和接口采用Thrift定义,Thrift可以支持各种语言,因此理论上Storm可以支持各种语言。
本地模式:快速开发和测试
三、Storm结构
Storm集群主要包括主控节点Nimbus和工作节点Supervisor,Nimbus和Supervisor之间通过zookeeper通信。
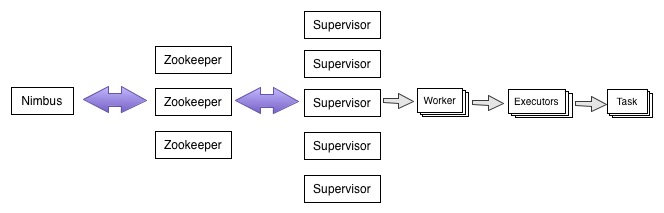
Nimbus:主控节点,用于提交任务,分配集群任务,集群监控等。
Zookeeper:集群中协调,公有数据存储(心跳信息、集群状态和集群配置信息, 任务分配信息)。
Supervisor:工作节点,负责从Zookeeper读取Nimbus分配的任务,管理自己的Worker进程。
Worker:工作进程,需要分配独立的端口,可通过conf.setNumWorker(int)配置;
Executor:工作线程,执行具体任务,可通过builder.setSpout(id,spout,parallelism_hint)配置,parallelism_hint即为线程数量。
Task:工作任务,主要是指Spout和Bolt实例,可以通过builder.setSpout(id,spout,parallelism_hint).setNumTasks(int)配置,如果不设置,则默认task数=executor。
Worker,Executor,Task详细关系可见Understanding the Parallelism of a Storm Topology
四、Topology
Storm的集群部署和程序(Topology)开发是独立的,程序完成之后,只需要配置相关的工作进程数,线程数以及任务数量等信息,Storm会自动将程序分配部署到工作节点,这对开发者来说是透明的。

Topoloy:应用程序的逻辑拓扑结构,包括各个组件以及组件之间的关联。
Spout :数据源组件,从外部获取流数据并转换为内部数据结构Tuple,发送给对应的Bolt。
Bolt:数据处理组件,针对数据进行运算处理,可以生成中间结果Tuple,发送到后续Bolt。
Tuple:数据单元,数据列表,可以包括多个Field,每个Field包括名字和数值,Tuple可以支持各种对象,只需要对象实现serializer接口。
Steam Group:数据流的分组方式,表示数据在Spout和Bolt之间的流转方式,主要包括以下几种方式:
Shuffle Grouping:随机选择⼀个Task来发送。
Field Grouping:根据Tuple的Fields进行控制,具有相同Fields的Tuple被发送到相同的Task。
All Grouping:⼲播发送,将每⼀个Tuple发送到所有的Task。
Global Grouping:所有的Tuple会被发送到某个Bolt中的id最⼩的那个Task。
None Grouping:不关⼼Tuple发送给哪个Task来处理,等价于Shuffle Grouping。
Direct Grouping:直接将Tuple发送到指定的Task来处理。
五、ACKER机制
acker机制是为了确保每条从spout发出的消息以及后续产生的消息都能够被完全处理,默认不开启acker功能,需要指定在spout中生成msgId,如实例所示。在具体介绍acker之前需要理解清楚几个概念:
1)Tuple tree是指从Spout发出的消息以及后续消息形成的有向图,Spout发出的Tuple为根tuple。后续的tuple都会保存根tuple的相关信息。
2)acker是一种隐形的后台任务,可以配置多个,用于监控tuple tree是否已经完成处理。
3)Spout的ack()和fail(),当Spout发出的消息以及后续消息都完全处理后(包括中间任务失败或者超时),acker会调用ack()或者fail()。
4)Bolt没有ack()和fail()方法,它通过collector.ack()或者collector.fail()方法通知上游,实质上可认为是通知acker,因为上游任务并不会处理。
5)Bolt执行完相关逻辑之后,就立即结束了,无需关注Tuple tree是否已经完全处理。
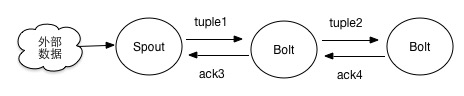
整个tuple tree的监控是通过acker实现的,acker为每个spout的tuple保存一个ack-val的校验值,初始值为0,然后每发射一个tuple/ack一个tuple,tuple的id都要跟这个校验值异或一下;如上图所示完整校验顺序为 ack-val = ID(Tuple1) XOR ID(Tuple2) XOR ID(ack3) XOR ID(ack4)。其中ID(Tuple1)=ID(ack3),ID(Tuple2)=ID(ack4),相同的值异或是为0的,但是因为Bolt每次先发送新的tuple,再ack上一个tuple,即ack-val先和新的tuple进行异或,再与旧的回复异或,使得ack-val只能在完全处理之后才会为0。当ack-val为0或者超时时,acker调用spout的ack或者fail方法。
六、源码实例
代码的功能是随即产生一个字符串,对字符串分解为耽搁
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.storm</groupId>
<artifactId>stormcase</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>stormcase</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
public class SourceDataSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private AtomicInteger counter;
public void nextTuple() {
Utils.sleep(500);
String list[] = new String[] { "java", "python", "c++", "go" };
Random random = new Random();
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 10; i++) {
int index = random.nextInt(list.length);
builder.append(list[index]).append(",");
}
collector.emit(new Values(builder.toString()), counter.getAndIncrement());
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
counter = new AtomicInteger();
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void ack(Object msgId) {
System.out.println("===ack:" + msgId);
}
}
public class WordSplitBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getString(0);
System.out.println("===wordSplit receive:" + line);
String words[] = StringUtils.split(line, ",");
for (String word : words) {
collector.emit(input, new Values(word));
}
collector.ack(input);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
private JedisPool pool;
private Jedis jedis;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
String host = (String) stormConf.get("redis.host");
Integer port = Integer.valueOf((String)stormConf.get("redis.port"));
pool = new JedisPool(new JedisPoolConfig(), host, port);
jedis = pool.getResource();
}
public void execute(Tuple input) {
String word = input.getString(0);
System.out.println("***wordCount receive:" + word);
jedis.incr(word);
collector.ack(input);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
if (pool != null) {
pool.close();
}
}
}public class App {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("data-spout", new SourceDataSpout(), 2);
builder.setBolt("wordsplit-bolt", new WordSplitBolt(), 2).shuffleGrouping("data-spout");
builder.setBolt("wordcount-bolt", new WordCountBolt(), 2).shuffleGrouping("wordsplit-bolt");
Config conf = new Config();
conf.put("redis.host", "127.0.0.1");
conf.put("redis.port", "6379");
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Test-Toplogie", conf, builder.createTopology());
Utils.sleep(10000);
cluster.shutdown();
}
}七、参考
http://storm.apache.org/index.html
http://lbxc.iteye.com/blog/1966997
http://www.cnblogs.com/Scott007/p/3320938.html?utm_source=tuicool&utm_medium=referral
http://xumingming.sinaapp.com/410/twitter-storm-code-analysis-acker-merchanism/















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









