







计算机小白读论文的记录,应该会有很多错误,所以不建议作为参考,欢迎各位大佬指正。
论文链接:[2404.16030] MoDE: CLIP Data Experts via Clustering (arxiv.org)
背景
CLIP简介
mode框架继承了clip的核心思想,所以先简单介绍一下clip。
CLIP(Contrastive Language-Image Pre-training)是由OpenAI在2021年发布的一种多模态预训练神经网络。它的核心思想是使用大量图像和文本的配对数据作为训练集,通过对比学习的方式来预训练一个模型,使其能够理解图像和文本之间的关系。CLIP在零样本学习场景下表现出色,它在不使用ImageNet数据集的任何一张图片进行训练的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手。
CLIP训练集规模
因为后面有将mode与clip在不同规模上进行对比的实验,所以我们先来了解一下clip的训练集规模。
OpenAI CLIP(原始模型):WIT400M
Open CLIP(CLIP模型的开源实现):LAION-400M和LAION-2B
Mate CLIP(改进了数据集和训练方法):400M和2.5B图像-文本对
MoDE(Mixture of Data Experts)框架继承了CLIP的核心思想,即通过对比学习来训练视觉-语言模型,并在此基础上引入了“数据专家”的概念,通过聚类和模型集成来提高模型的性能和训练效率。
目的
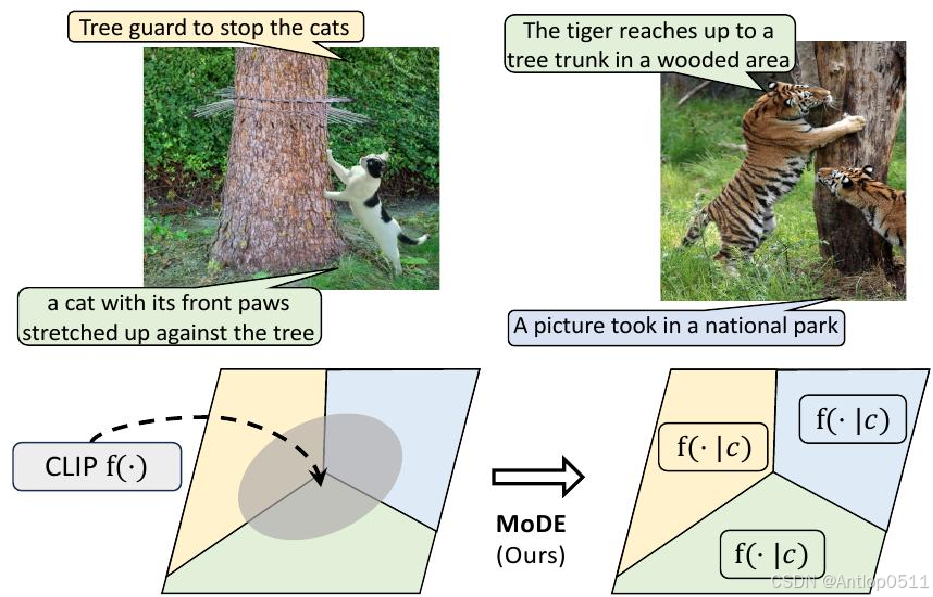
1.首先是为了解决clip预训练中存在的问题,由于配对的文本通常描述有限的视觉内容,因此常见的情况是,两张相似的图像具有截然不同的文本描述,尤其是在充满噪声的网络爬取数据中。当这些图像-文本对在同一个批次中采样时,其他图像的文本会变成假阴性。
以左边这张图猫的图片为例,上面这个描述和下面这个描述都是合理的,但当两张这样的图片在同一个批次中采样的时候,其中一个文本描述会很容易被视为负样本。
2.在训练集中加入难负样本,通常被证实是可以提高模型的性能的。
例如对于下面这两张猫和老虎的图片来说,假如猫的图像文本对是正样本,由于两张图片具有一定的相似性,老虎的图文本对也会容易被认为是正样本,这就是一个难负样本。
Mode框架通过聚类,将假阴性样本分到不同的簇中,并将具有相似语义的样本配对,从而减轻假阴性文本带来的噪声,并增加了同一个簇中难负样本的数量,进而提高模型的表现。(比如将猫的这两个文本描述分到不同的簇中,将猫和老虎的这两个文本描述分到一起)
下图中,是否分到同一个簇可以根据颜色来看,相同颜色的会被分到同一个簇
贡献
• 研究了CLIP预训练中的高质量负样本,特别是网络爬取的图像-文本对中的假阴性噪声。
• 提出了通过聚类学习 CLIP 数据专家系统的MoDE框架,且MoDE框架能在推理时自适应地集成数据专家以用于下游任务。
• 通过大量的实验研究表明,MoDE 在零样本迁移基准测试中取得了显著效果,同时训练成本较低。MoDE 可以灵活地纳入新的数据专家,因此有利于持续预训练。
方法
整体框架
这是MoDE的框架图,总体可以分为左边的数据专家预训练模块和右边的推理时任务适应模块。
首先,将训练数据,也就是图像-文本对,通过两步聚类分成几个不相交的子集;然后,每个聚类都通过对比学习的方式来训练一个模型。这样,每个模型都由一个集群中的训练数据进行专门化,这也是为什么叫做数据专家。当应用于下游任务(例如图像分类)时,任务元数据首先与
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









