







统计分析是数据分析重要的组成部分,它几乎贯穿了整个数据分析的流程。 应用统计方法,将定量与定性结合,进行的研究活动叫统计分析。统计分析除了 包含单一数值型特征的数据集中趋势、离散趋势和峰度与偏度等统计知识外,还 包含了多个特征比较计算等知识。
一、读写文本文件
1、文本文件的读取:
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文 件。
csv 是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字 符分隔文件,文件以纯文本形式存储表格数据(数字和文本)。
注:(1)CSV 文件根据其定义也是一种文本文件;
(2)文本文件是字符分隔文件。
使用read_table来读取文本文件
pandas.read_table(filepath_or_buffer,sep=’\t’,header=’infer’, names=None,index_col=None,dtype=None,engine=None,nrows=None)
使用 read_csv 函数来读取 csv 文件
pandas.read_csv(filepath_or_buffer,sep=’\t’,header=’infer’, names=None,index_col=None,dtype=None,engine=None,nrows=None)
read_table 和 read_csv 常用参数及其说明

read_table 和 read_csv 函数中的 sep 参数是指定文本的分隔符的,如果分隔符 指定错误,在读取数据的时候,每一行数据将连成一片。 header 参数是用来指定列名的,如果是 None 则会添加一个默认的列名。
encoding 代表文件的编码格式,常用的编码有 utf-8、utf-16、gbk、gb2312、 gb18030 等。如果编码指定错误数据将无法读取,IPython 解释器会报解析错 误。
import pandas as pd
from pandas.core.frame import DataFrame
data = pd.read_csv('meal_order_info.csv', sep=',', encoding='gbk')
print(type(data))
# <class 'pandas.core.frame.DataFrame'>
data = pd.read_table('meal_order_info.csv',sep=',',encoding='gbk')
print(data,type(data))
# [945 rows x 21 columns] <class 'pandas.core.frame.DataFrame'>
2.文本文件的存储
文本文件的存储和读取类似,结构化数据可以通过 pandas 中的 to_csv 函数 实现以 csv 文件格式存储文件
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None)
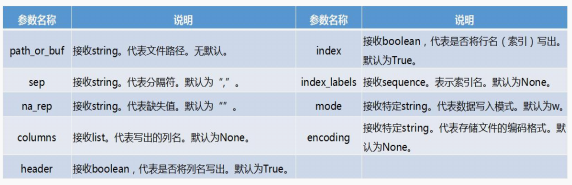
变量名.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None)
二、读写Excel文件
1.Excel 文件读取: pandas 提供了 read_excel 函数来读取“xls”“xlsx”两种 Excel 文件。
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
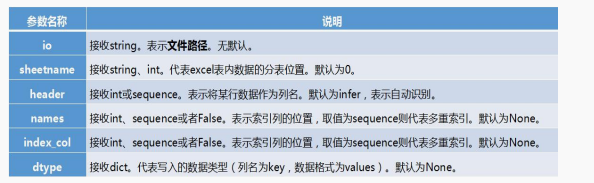
excel = pd.read_excel('output.xlsx')
print('dsafsdf',excel)
2.Excel文件储存:
将文件存储为 Excel 文件,可以使用 to_excel 方法。其语法格式如下。
DataFrame.to_excel(excel_writer=None, sheet_name=‘None’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
to_csv 方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参 数名称为 excel_writer,并且没有 sep 参数,增加了一个 sheetnames 参数用来 指定存储的 Excel sheet 的名称,默认为 sheet1。
import xlrd
import pandas as pd
from pandas import DataFrame
wb = xlrd.open_workbook('meal_order_detail.xlsx')
sheets = wb.sheet_names()
print(sheets)
# ['meal_order_detail1', 'meal_order_detail2', 'meal_order_detail3']
# 总的数据容器
total = DataFrame()
# 循环遍历所有sheet,汇总数据
for i in range(len(sheets)):
data = pd.read_excel('meal_order_detail.xlsx', sheetname=i, index_col=False)
print(type(data)) # <class 'pandas.core.frame.DataFrame'>
print(data.shape[0])
# 汇总数据
total = total.append(data)
print(total.shape)
# 保存
writer = pd.ExcelWriter('output.xlsx')
total.to_excel(writer,'Sheet1')
writer.save()
第二种方法
xls = xlrd.open_workbook('meal_order_detail.xlsx')
names = xls.sheet_names()
#总得数据容器
arr = DataFrame()
for i in range(len(names)):
data = pd.read_excel('meal_order_detail.xlsx',sheetname=i)
arr = arr.append(data)
print(arr.shape)
arr.to_excel('output1.xlsx')















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









