








线性回归
线性回归(Linear Regression)作为Machine Learning 整个课程的切入例子确实有独到的地方,以简单的例子为出发点,将学习任务的主干串起来。问题的建模可以简单如下图所示:
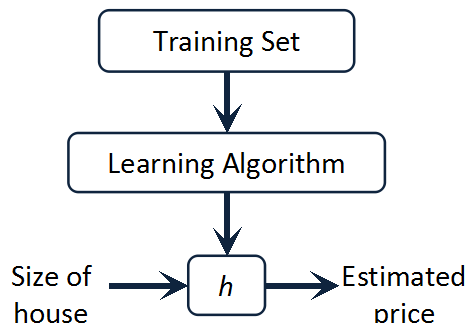
线性回归可以分为单变量线性回归(Linear Regression with One Variable)以及多变量线性回归(Linear Regression with Multiple Variables)。这篇我们先从单变量线性回归入手。
我们以房屋交易问题为例,问题就是:
给定一批已知的房子大小和价格的对应关系数据,如何对一个给定大小的房子进行估值?
假使我们回归问题的训练集(Training Set) 如下表所示:

我们用来描述这个回归问题的标记如下:

我们需要做的是怎样“学习”到一个假设h(函数),从而对于给定的房子大小能输出估值。
对于单变量线性回归来说就是下面四个点:
1. 假设(Hypothesis):线性回归的假设就是数据呈线性分布

2. 参数(Parameters): 学习的过程也就是参数拟合的过程,参数是

3. 代价函数(Cost Functions): 进行参数选择(拟合)的标准,这里选取的是最小均方误差。

4. 将参数回归转换到误差最小化的优化问题上来

为了解最小化问题(4),再引入梯度下降法(Gradient Descent Algorithm)。

梯度下降背后的思想是:开始时我们随机选择一个参数的组合(ø0,ø1,....,øn),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。持续这样做直到找到一个局部最小值(Local Minimum),因为我们并没有尝试完所有的参数组合,所以并不能确定我们得到的局部最小值是不是全局最小值(Global Minimum),选择不同的初始参数组合,可能会找到不同的局部最小值:

其中alpha是学习速率(Learning Rate),它决定了我们沿着能让代价函数下降程度最大的方向乡下迈出的步子有多大。虽然步长是固定的,但是当逼近一个(局部)最小值时,梯度会变小,因而梯度下降法在靠近极值点时会自动将“步子”迈小一点。不过一个比较好的初始值(能够让目标函数值下降的值)还是有必要的。















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









