







前言
在我们之前学习的数据结构中,在执行查找操作时总要进行或多或少的遍历操作,随着数据量的增加,查找所需的时间也会越来越多。而在实际运用中往往所需查找的数据量都非常庞大,如何在数以亿计的数据中快速找到所需数据呢?哈希表这一数据结构就会发挥至关重要的作用了。那么哈希表到底是啥,它是如何实现的,又该如何使用,本篇文章将会带你深入研究这些东西。
一、概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在
查找一个元素时,必须要经过关键
码的多次比较
。
顺序查找时间复杂度为
O(N)
,平衡树中为树的高度,即
O( 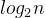 )
,搜索的效率取决于搜索过程中元素的比较次数。
)
,搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素
。
如果构造一种存储结构,通过某种函
数
(hashFunc)
使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快
找到该元素
。
当向该结构中:插入元素根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放搜索元素对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希
(
散列
)
方法,
哈希方法中使用的转换函数称为哈希
(
散列
)
函数,构造出来的结构称为哈希表
(Hash
Table)(
或者称散列表
)
例如:数据集合
{1
,
7
,
6
,
4
,
5
,
9}
;
哈希函数设置为:
hash(key) = key % capacity
; capacity
为存储元素底层空间总的大小

注意:如果插入元素是35,由于35%10=5,hash(35)=5,这就会导致35的哈希值与5的哈希值一致了,这样不同元素共用一个哈希地址就被称为哈希冲突,要尽量避免
二、哈希冲突
对于两个数据元素的关键字 a和b
,有
a!=b
,但有:
Hash(a) == Hash(b)
,即:
不同关键字通过相同哈
希哈数计算出相同的哈希地址,该种现象称
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









