







今天李善平突然在课上讲起人工智能,把蔡登的课程计划批判了一番。机器学习已经远远把70年代的计算机技术抛在后头,但是从数学角度来讲实际上应当是另外一个分支。他那个时候的人工智能课程(90年代初),肯定要讲一阶谓词,讲A*,而现在呢?都在讲数理统计,最大似然,最小二乘,梯度下降。红黑树的前身,2-3-4树,虽然在书中没有明确指出,想必也是60年代斯坦福计算机系的产物。
百度百科
2-3-4 树把数据存储在叫做元素的单独单元中。它们组合成节点。
每个节点都是下列之一:
2-节点,就是说,它包含 1 个元素和 2 个儿子;
3-节点,就是说,它包含 2 个元素和 3 个儿子;
4-节点,就是说,它包含 3 个元素和 4 个儿子。
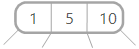
(4节点的例子:小于1的元素沿着最左路径往下递归插入,1-5之间的元素在第二条路径插入,5-10,10以上的元素在后面两条路径)
每个儿子都是(可能为空)一个子 2-3-4 树。根节点是其中没有父亲的那个节点;它在遍历树的时候充当起点,因为从它可以到达所有的其他节点。叶子节点是有至少一个空儿子的节点。
同B树一样,2-3-4 树是有序的:每个元素必须大于或等于它左边的和它的左子树中的任何其他元素。每个儿子因此成为了由它的左和右元素界定的一个区间。
性质
1、除了第一次,永远在叶子节点插入,而叶子节点一定是有数据非空的。
2、为了保障性质1,路径上的所有4-节点请分裂成三个2-节点,并将中间的2-节点插入父节点。
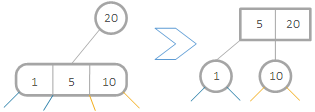
由上两条可得
3、所有叶子节点到根的距离相等。
第三条性质是2-3-4树能达到平衡的原因,它可以从前面两条推导得出,也是红黑树的根本性质。因为红黑树采用了一种比较巧妙的方式将2-3-4树加以改造,这也造成红黑树插入效率能达到1.02Log(n)。
代码
num代表元素个数
item代表元素
child代表儿子,永远比元素多一个
leaf代表叶子节点
typedef struct BSTNode* BLink;
struct BSTNode
{
int num; // 1, 2, 3
Item item[3];
BLink child[4];
bool leaf;新节点的写法:
BLink _new_node(Item item, int num, BLink c0, BLink c1, BLink c2, BLink c3)
{
BLink new_node = (BLink)malloc(sizeof(BSTNode));
new_node->item[0] = item, new_node->num = num;
new_node->child[0] = c0, new_node->child[1] = c1, new_node->child[2] = c2, new_node->child[3] = c3;
new_node->leaf = (c0 == NULL);
return new_node;
}将一个4-节点分裂成三个2-节点:
BLink _split(BLink h)
{
BLink l, r;
l = _new_node(h->item[0], 1, h->child[0], h->child[1], 0, 0);
r = _new_node(h->item[2], 1, h->child[2], h->child[3], 0, 0);
h->item[0] = h->item[1], h->num = 1;
h->child[0] = l, h->child[1] = r, h->leaf = false;
return h;
}假如第k个儿子节点发生分裂,那么插入到父节点
BLink _merge(BLink h, int k)
{
BLink l = h->child[k]->child[0], r = h->child[k]->child[1];
for(int i = h->num - 1; i >= k; -- i)
{
h->item[i + 1] = h->item[i];
h->child[i + 2] = h->child[i + 1];
}
h->item[k] = h->child[k]->item[0];
h->child[k] = l, h->child[k + 1] = r;
++ h->num;
return h;
}插入:使用了类似插入排序的做法
假如遇见叶子节点,那么大胆的插入吧!
假如在插入完毕后,发现子节点变成了4-节点,那么将其分裂-插入父节点。具体见代码。
BLink _insert(BLink h, Item item)
{
if(h == NULL)
{
return _new_node(item, 1, 0, 0, 0, 0);
}
int v = KEY(item);
if(h->leaf)
{
int i;
for(i = h->num; i > 0; -- i)
{
if(v < h->item[i - 1].key)
{
h->item[i] = h->item[i - 1];
}
else break;
}
h->item[i] = item, h->num ++;
}
else
{
int i = h->num - 1;
for(; i >= 0; -- i)
{
if(v < h->item[i].key)
{
h->item[i + 1] = h->item[i];
}
else
{
break;
}
}
h->child[i + 1] = _insert(h->child[i + 1], item);
for(int i = 0; i <= h->num; ++ i)
{
if(h->child[i] && h->child[i]->num == 3)
{
h->child[i] = _split(h->child[i]);
h = _merge(h, i);
break;
}
}
}
return h;
}总结
2-3-4树不需要旋转。但是分裂插入很麻烦!非常麻烦!very麻烦!(和左小右大的二叉树比起来)我还没写删除操作,就已经码了100多行。在递归调用上,和后来的红黑树相比也会发现有一些区别,原因是分裂的代码不能放在函数的开始。为什么?写过就知道。而且写法复杂是小事情,最关键的地方是,它失去了二叉平衡树的美感,那种统一的操作,又额外添加了插入移动的开销。















 9639
9639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









