







Spark快速大数据分析-pdf下载(高清带书签):
https://download.csdn.net/download/adam_zs/10276229
scala-2.12.4.msi windows安装文件下载:
https://download.csdn.net/download/adam_zs/10276232
源码下载:
https://download.csdn.net/download/adam_zs/10276227
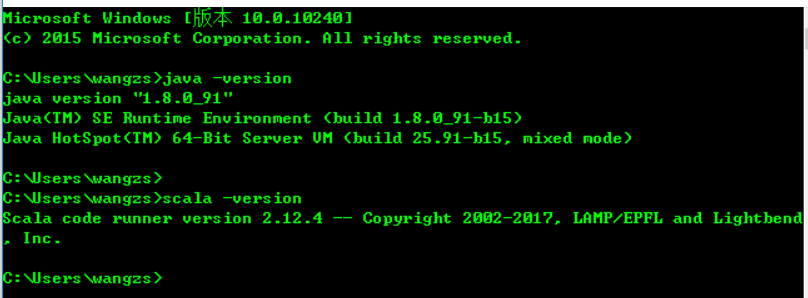
1.windows安装jdk,scala,我用的版本如下图(没有配置请百度一下配置)
2.windows hellword例子
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wangzs</groupId>
<artifactId>spark-book</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spark-book</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<!-- pluginManagement不会引入实际的插件,能够约束plugins下的插件 -->
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- 打包时跳过测试 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
package com.wangzs;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* 单词计数器
*
* @author wangzs
*
*/
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("WordCounter").setMaster("local");
String fileName = "E:/test.txt";
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(fileName, 1);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> result = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer e, Integer acc) throws Exception {
return e + acc;
}
}, 1);
result.map(new Function<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<String, Integer> v1) throws Exception {
return new Tuple2<>(v1._1, v1._2);
}
}).sortBy(new Function<Tuple2<String, Integer>, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Tuple2<String, Integer> v1) throws Exception {
return v1._2;
}
}, false, 1).foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> e) throws Exception {
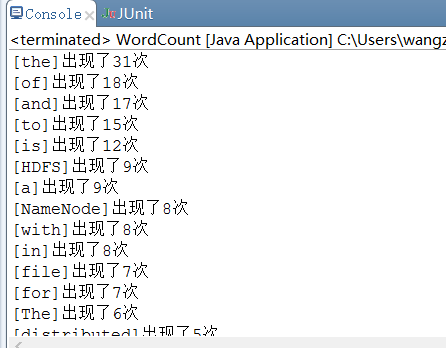
System.out.println("[" + e._1 + "]出现了" + e._2 + "次");
}
});
sc.close();
}
}















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









