







最后
面试前一定少不了刷题,为了方便大家复习,我分享一波个人整理的面试大全宝典
- Java核心知识整理

Java核心知识
- Spring全家桶(实战系列)

- 其他电子书资料

Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:

-
EhCache 2.x
-
Hazelcast
-
Infinispan
-
Couchbase
-
Redis
-
Caffeine
-
Guava
-
Simple
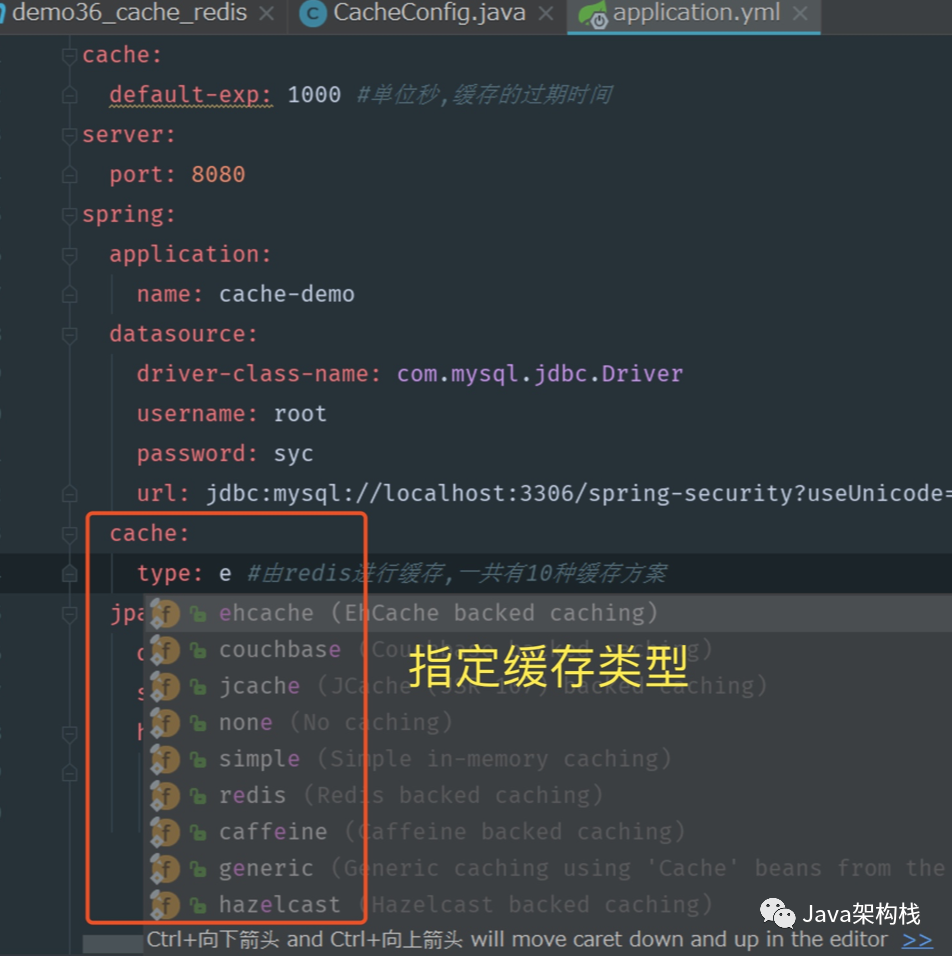
Spring Boot 为我们提供了多种缓存CacheManager配置方案,默认情况下会使用基于内存map的缓存方案ConcurrenMapCacheManager,内部默认是利用ConcurrentHashMap的来实现缓存。
我们可以通过‘spring.cache.type’属性来强制指定到底使用哪种缓存提供商,如果需要在一些环境(比如,测试)中禁用全部缓存也可以使用该属性。
3. Spring Cache原理
Spring Cache是作用在方法上的,其核心实现逻辑如下:
当我们在调用一个缓存方法时,会把该方法参数和返回结果作为一个键值对存放在缓存中;
等到下次利用同样的参数来调用该方法时将不再执行该方法,而是直接从缓存中获取结果进行返回。
所以在使用Spring Cache的时候,我们要确保缓存的方法的幂等性,也就是对于相同的方法参数要有相同的返回结果。
4. Spring Cache的实现方案
Spring对Cache的实现方案有2种方式。
- 基于注解配置方式;
- 基于XML配置方式。
其中基于注解(annotation)的缓存(cache)技术是在Spring 3.1 引入的,它本质上不是一个具体的缓存实现方案(例如 EHCache),而是一个对缓存使用的抽象,通过在已有代码中添加少量关于缓存的注解annotation,就能够达到缓存的效果。
二. Spring Cache注解实现方案详解
1. Spring Cache中常用缓存注解
在Spring Cache中,为我们提供了如下几个常用的缓存相关注解,希望各位可以记住:
- @Cacheable
- @CachePut
- @CacheEvict
- @Caching
2. 注解实现方案的特点
-
通过少量的配置 annotation 注解即可使得已有代码支持缓存;
-
支持 SpEL 表达式,能使用对象的任何属性或者方法来定义缓存的 key 和 condition;
-
支持 AspectJ,并通过其实现任何方法的缓存支持;
-
支持自定义 key 和缓存管理器,具有相当的灵活性和扩展性;
-
提供开箱即用的缓存临时存储方案;
-
支持和主流的专业缓存方案(例如Redis)集成。
接下来我会分别对这几个注解进行详细的介绍。
三. @Cacheable注解
1. 注解作用
可以作用在方法上,也可以标记在一个类上。当标记在一个方法上时表示该方法是支持缓存的,当标记在一个类上时则表示该类所有的方法都是支持缓存的。
2. 用法举例
//单缓存名称:
@Cacheable(value=”cache1”)
//多缓存名称:
@Cacheable(value={”cache1”,”cache2”}
3. 参数介绍
value参数是必须指定的,表示当前方法的返回值是会被缓存在哪个Cache上的,对应Cache的名称。其可以是一个Cache也可以是多个Cache,当需要指定多个Cache时其是一个数组。
3.1 value:缓存的名称
每一个缓存名称代表一个缓存对象。当一个方法填写多个缓存名称时将创建多个缓存对象。
当多个方法使用同一缓存名称时相同参数的缓存会被覆盖。
所以通常情况我们使用“包名+类名+方法名”或者使用接口的RequestMapping作为缓存名称防止命名重复引起的问题。
3.2 key:缓存的 key
key标记了缓存对象中的每一个缓存数据,当我们没有指定该属性时,Spring将使用默认策略生成key,系统会自动按照方法的所有入参生成key,也就是说相同的入参值将会返回同样的缓存结果。
我们也可以利用自定义策略,通过Spring的EL表达式来指定我们的key。这里的EL表达式可以使用方法参数及它们对应的属性。使用方法参数时我们可以直接使用“#参数名”或者“#p参数index”。
4. 示例代码
如下列无论方法存在多少个入参,只要userName值一致,则会返回相同的缓存结果。
/**
* key 是指传入时的参数
*/
@Cacheable(value="users", key="#id")
public User find(Integer id) {
return null;
}
// 表示第一个参数
@Cacheable(value="users", key="#p0")
public User find(Integer id) {
return null;
}
// 表示User中的id值
@Cacheable(value="users", key="#user.id")
public User find(User user) {
return null;
}
// 表示第一个参数里的id属性值
@Cacheable(value="users", key="#p0.id")
public User find(User user) {
return null;
}
除了上述使用方法的参数作为key之外,Spring还为我们提供了一个root对象用来生成key。
当我们要使用root对象的属性作为key时我们也可以将“#root”省略,因为Spring默认使用的就是root对象的属性。如:
// key值为: user中的name属性的值
@Cacheable(value={"users", "xxx"}, key="caches[1].name")
public User find(User user) {
return null;
}
5. condition缓存的条件
有时候我们可能并不希望缓存一个方法的所有返回结果,这时可以通过condition属性可以实现这一功能。condition属性默认为空,表示将缓存所有的调用情形。满足条件后,方法的结果才会被缓存,不填写则认为全部无条件缓存。
使用 SpEL表达式编写条件,返回 true 或者 false,只有为 true 才进行缓存。
//只有用户名长度大于2时参会进行缓存。
@Cacheable(value=”cache1”,condition=”#userName.length()>2”)
四. @CachePut注解
1. 注解作用
主要针对方法配置,能够根据方法的请求参数对其结果进行缓存。和 @Cacheable 不同的是,它每次都会触发真实方法的调用,此注解常被用于更新缓存使用。
2. 参数介绍
2.1 value:缓存的名称
@CachePut(value=”cache1”)
@CachePut(value={”cache1”,”cache2”}
2.2 key:缓存的 key
@CachePut(value=”cache1”,key=”#userName”)
2.3 condition:缓存的条件
写在最后
还有一份JAVA核心知识点整理(PDF):JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算…

…
[外链图片转存中…(img-YnTlNsWk-1715439035511)]















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









