







Python基础知识
1. 数据类型
1.1 数值
- 加减乘运算的时候,只要有浮点数参与,结果就是浮点数
- 除法运算,结果都为浮点数
1.2 字符串
字符串也属于一种序列,因此也可以进行序列的操作,如索引、切片等
1.2.1 单引号、双引号、三引号
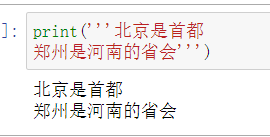
使用三引号可以在字符串内换行,换行时相当于自动添加换行符
print('''北京是首都
郑州是河南的省会''')
1.2.2 转义字符
| 转义字符 | 说明 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
1.3 布尔值
1.4 空值 None
- None同时也是关键字
- None被输出的时候显示为一个字符串"None"
1.5 类型转换
| 函数 | 说明 |
|---|---|
| bool() | 转换为布尔值 |
| str() | 转换为字符串 |
| int() | 转换为整数,浮点数转化时只取整数位的数字,不进行进位退位计算 |
| float() | 转换为浮点数 |
0值、None 和空字符串转换为布尔值后都是False
1.6 运算符
1.6.1 算术运算符
只用于数值
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 1 + 1; a + b |
| - | 减 | 10 - 5; a - b -c |
| * | 乘 | 4 * 2 相当 4 × 2 |
| / | 除 | 4 / 2 相当于 4 ÷ 2 |
| // | 取整除 | 10 // 4 结果是 2 |
| % | 取模 | 10 % 4 相当于 10 - (10 // 4) × 4 |
| ** | 指数 | 2 ** 3 相当于 2 * 2 * 2,也就是2的3次方 |
| () | 小括号 | 提高运算优先级,比如: (2 + 8) * 3 |
1.6.2 字符串、布尔值运算
字符串和布尔值只可用加法和乘法,但不能使用减法和除法等其他运算
1.6.3 赋值比较运算符
| 赋值运算符 | 作用 | 使用 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c = a 等效于 c = c a |
| 比较运算符 | 作用 | 使用 |
|---|---|---|
| == | 等于 | 100 == 100 |
| != | 不等于 | 100 != 99 |
| > | 大于 | 2 > 1 |
| < | 小于 | 1 < 2 |
| >= | 大于等于 | 3 >= 2 |
| <= | 小于等于 | 2 <= 3 |
1.6.4 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | |
|---|---|---|---|
| and | x and y | 任意一个是False,结果就是False | True and False 结果为False |
| or | x or y | 任意一个是True,结果就是True; | True or False 结果为True |
| not | not x | 将条件取反 | not False 结果为True |
2. 流程控制
if、elif、while后面的总是跟着一个表达式,这个表达式的结果必须是True或者False,如果表达式运算出来的结果不是一个布尔值,则会自动将结果转换为布尔值。0值、None 和空字符串转换为布尔值后都是False
count = 0
if count: #相当于--> if count is True:
print("条件成立")
else:
print("条件不成立")
>>> 条件不成立
2.1 条件判断
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
2.2 循环语句
2.2.1 while循环
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
2.2.2 for循环
for <variable> in <sequence>:
<statements>
else:
<statements>
while与for循环区别:while可以无限次循环,for循环的次数取决于穷举序列的元素个数
2.2.3 break、continue与pass语句
- break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行
- continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环
- pass语句不做任何事情,一般用做占位语句,为了保持程序结构的完整性
2.3 异常处理

| 常见异常 | 含义 |
|---|---|
| BaseException | 新的所有异常类的基类 |
| Exception | 所有异常类的基类,但继承BaseException |
| AssertionError | assert语句失败 |
| FileNotFoundError | 试图打开一个不存在的文件或目录 |
| AttributeError | 试图访问的对象没有属性 |
| NameError | 使用一个还未赋值对象的变量 |
| IndexError | 当一个序列超出了范围 |
| SyntaxError | 当解析器遇到一个语法错误时引发 |
| KeyboardInterrupt | Ctrl+C被按下,程序被强行终止 |
| TypeError | 传入的对象类型与要求不符 |
| OSError | 当系统函数返回一个系统相关的错误,包括I/O故障,如“找不到文件”或“磁盘已满”时,引发此异常 |
3. 数据结构
3.0 序列

3.1 字符串
3.1.1 字符串格式化
3.1.1.1 %格式化
print('我的名字叫%s,我今年%d岁了。'%('张三',12))
>>> '我的名字叫张三,我今年12岁了。'
| 符号 | 说明 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字 |
| %.f | 指定精度(f前面输入)的浮点数占位符 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
3.1.1.2 format格式化函数
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
>>> a = 'my name is {name},my adress is {city}' #设定指定名称
>>> a.format(name='adam',city='beijing')
print(a) # 'my name is adam,my adress is beijing'
| 格式 | 描述 |
|---|---|
| {:.2f} | 保留小数点后两位 |
| {:+.2f} | 带符号保留小数点后两位 |
| {:+.2f} | 带符号保留小数点后两位 |
| {:.0f} | 不带小数 |
| {:0>2d} | 数字补零 (填充左边, 宽度为2) |
| {:x<4d} | 数字补x (填充右边, 宽度为4) |
| {:x<4d} | 数字补x (填充右边, 宽度为4) |
| {:,} | 以逗号分隔的数字格式 |
| {:.2%} | 百分比格式 |
| {:.2e} | 指数记法 |
| {:>10d} | 右对齐 (默认, 宽度为10) |
| {:<10d} | 左对齐 (宽度为10) |
| {:^10d} | 中间对齐 (宽度为10) |
3.1.2 字符串的索引与切片
索引位置均从0开始,反向位置从-1开始
切片⬇
‘str’[开始位置:结束位置:步长]
3.1.3 字符串函数
| 函数 | 说明 |
|---|---|
| .format() | 格式化 |
| .strip() | 去除空格 |
| .lstrip() | 去除左侧空格 |
| .rstrip() | 去除右侧空格 |
| .upper() | 替换大写 |
| .lower() | 替换小写 |
| .capitalize() | 首字母大写 |
| .title() | 每个单词首字母大写 |
| .islower() | 判断是否全小写 |
| .isupper() | 判断是否全大写 |
| .isdigit() | 判断是否全数字 |
| .stratswith() | 判断是否以…开头 |
| .endswith() | 判断是否以…结尾 |
| .find() | 搜索字符串中内容,并返回索引 ,找不到时返回-1 |
| .index() | 搜索字符串中内容,并返回索引,找不到时报错 |
| .count() | 返回在字符串中出现次数 |
| .replace(被替换,替换内容,n) | 替换字符串内替换前n个内容 |
| len() | 返回字符串长度 |
3.2 元祖
- 元祖和字符串一样不可变,也可以迭代循环,可以按索引访问,可以切片访问
- 元祖在元素大于1的情况下可以不使用括号
t = 1,2,3
a,b,c = t
print(a,b,c)
>>> 1 2 3
3.3 列表
列表可以理解为可变的元组,它的使用方式跟元组差不多,区别就是列表可以动态的增加、修改、删除元素。
3.3.1 复制、浅拷贝、深拷贝
| 操作 | 命令 | 说明 |
|---|---|---|
| 复制 | b = a | 直接复制,a改变时,b也改变 |
| 浅拷贝 | b = a.copy() | a改变时,b不改变;但只能 copy第一层,当列表深层发生变化时,b依然改变 |
| 深拷贝 | b = a.deepcopy() | a改变时,b不改变; |
names = ["小明", "小红", ["张三", "李四", "王五"], "小黑", "小黄", "小白"]
names2 = names.copy() #浅拷贝
names[2][1] = "Lisi" #原列表改变深层数据
print(names)
print(names2) #浅拷贝列表也发生改变
>>>['小明', '小红', ['张三', 'Lisi', '王五'], '小黑', '小黄', '小白']
>>>['小明', '小红', ['张三', 'Lisi', '王五'], '小黑', '小黄', '小白']
3.3.2 列表函数
| 函数 | 说明 |
|---|---|
| .append() | 尾部添加元素 |
| .insert(索引,插入对象) | 在特定位置添加元素 |
| .extend(列表) | 以列表形式插入多个元素 |
| .pop() | 随机(输入索引后可指定)删除元素并返回删除对象 |
| del | 删除元素 |
| .remove(删除的元素) | 根据元素直接删除第一个匹配到的元素 |
| .clear() | 清空列表 |
| .reverse() | 反转列表排序 |
| sort() | 从小到大排序 |
| sort(reverse=True,key) | 从大到小排序,key可以定义由哪部分排序 |
| .copy() | 拷贝列表 |
3.3.3 列表表达式
[i for i in range(10)]
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
3.4 字典
- 字典没有顺序,”键“区分大小写
- dict(含嵌套的序列)可强制转化为字典
| 函数 | 说明 |
|---|---|
| .items() | 用以遍历字典 |
| .get(key, default=None) | 返回指定键的值,键不在字典中返回默认值 None 或者设置的默认值 |
| .keys() | 用以遍历”键“ |
| .values() | 用以遍历”值“ |
3.5 集合
集合,是一个无序的、不重复的序列,一般用来删除重复数据,还可以计算交集、并集等。
a = set()
b = set()
a.add('123')
a.add('456')
b.add('456')
b.add('789')
print(a - b) # {'123'} 差集
print(a & b) # {'456'} 交集
print(a | b) # {'789', '456', '123'} 并集
print(a ^ b) # {'123', '789'} 异或
| 函数 | 说明 |
|---|---|
| .add() | 添加元素 |
| .remove() | 移除元素,如没有则报错 |
| .discard() | 移除元素,没有不报错 |
| .pop() | 随机(输入索引后可指定)删除元素并返回删除对象 |
| .intersection() | 求交集 |
| .union() | 求并集 |
| .issubset() | 求是否子集 |
| .issuperset | 求是否是父集 |
4. 函数、类、模块
| 代码 | 说明 |
|---|---|
| def | 定义函数 |
| return() | 返回值 |
| lambda x : expression | 匿名函数 |
| class | 定义类 |
| def __init__() | 定义类的初始化参数 |
| isinstance() | 判断对象与类的关系 |
| @classmethod | 类方法声明 |
| @property | 用以创建只读属性,会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改 |
| if __name__ == “__main__” | 当模块被直接运行时,以下代码块将被运行,当模块是被导入时,代码块不被运行 |
4.1 函数
参数是有顺序的,如果传参,要么按顺序传,要么就连着参数名一起传
参数可以设置默认值,但有传参的情况下,以传参为最后值
lambda是Python中的关键字,它的作用就是用来定义匿名函数,匿名函数的函数体一般只有一行代码,省略了函数名和返回值语句
4.2 类与面向对象
- 面向过程:根据业务逻辑从上到下写代码。
- 面向对象:将变量与函数、属性绑定到一起,分类进行封装,每个程序只要负责分配给自己的功能,这样能够更快速的开发程序,减少了重复代码。

类是创建对象的模板,对象是类的实例
类的每一个方法的第一个参数是self ,但在调用的时候却不需要传参数给它。它是类方法和普通函数的区别,这个self代表的是实例自身
使用**__init__ 函数来接收初始化参数**,这样就可以把属性的值作为参数在初始化对象的时候就传给它。
4.3 模块和包管理
最小化导入原则:应导入尽量小的包
当导入的模块与自定义模块名称冲突时,优先调用自定义模块
常用内置模块
时间模块——datetime
| 函数 | 说明 |
|---|---|
| from datetime import datetime | 导入模块 |
| datetime.now() | 现在时间点 |
| .strftime(string[, format]) | 转化为特定格式的字符串 |
| .strptime(string[, format]) | 按照特定时间格式将字符串转换(解析)为时间类型 |
| . timestamp() | 时间戳 |
| .year (day、month、hour、minites、seconds) | 返回具体的时间单位值 |
时间模块——time
| 函数 | 说明 |
|---|---|
| .import time | 导入模块 |
| time.time() | 返回当前时间戳 |
| time.sleep() | 将当前的程序暂停若干秒数 |
随机模块——random
| 函数 | 说明 |
|---|---|
| random.random() | 随机浮点数,范围[0.0, 1.0) |
| random.randint(1, 100) | 生成1到100之间的随机整数 |
| random.choice([list]) | 从序列中随机抽出一个元素 |
| random.choices([list], k=n)) | 从序列中随机抽出k个元素,注意抽出来的元素可能会重复 |
| random.choice([list]) | 跟choices函数类似,但它是不重复的随机抽样 |
| random.shuffle(lst) | 将一个序列随机打乱,注意这个序列不能是只读的 |
操作系统接口——os
os函数
| 函数 | 说明 |
|---|---|
| import os | 导入 |
| os.getcwd() | 获取当前目录的路径 |
| os.mkdir(path) | 创建指定目录,但只能在一级目录下创建新目录 |
| os.makedirs(path) | 创建多级目录 |
| os.listdir() | 返回一个列表,该列表包含了 path 中所有文件与目录的名称 |
| os.sep | 目录分隔符 |
os.path函数
| 函数 | 说明 |
|---|---|
| os.path.abspath(’./’) | 显示当前目录的绝对路径 |
| os.path.isdir(path) | 如果 path是现有的目录,则返回 True。 |
| os.path.isfile() | 如果 path是现有的常规文件,则返回 True |
| os.path.join(path, *paths) | 合理地拼接一个或多个路径部分。 |
| os.path.dirname("") | 返回文件路径 path 的目录名称 |
| os.path.basename("") | 返回路径 path 的基本名称,文件名或是最后一级的目录名 |
系统相关参数及函数——sys
| 函数 | 说明 |
|---|---|
| import sys | 导入 |
| sys.path | 返回Python查找包的路径顺序 |
| sys.argv | 启动的时候传递给Python脚本的命令行参数 |
5. 办公自动化
5.0 绝对路径与相对路径

如上图,txt文件夹中含有《1.txt》文档
则《1.txt》的路径有以下两种方式表示
- 绝对路径
path = "D:\temp\txt\1.txt"
- 相对路径
path = "txt\1.txt"
注意:路径有可能是"u"开头,导致路径内字符产生了转义效果,\u表示其后是UNICODE编码。这时应在字符串前加r,进行反转义,如下:
pd.read_csv(r"User_Behavior Data\User Behavior Data.csv")
5.1 打开文件
打开文件有两种方式
f = open('1.txt','r',encoding='utf-8').read()
with open('1.txt','r',encoding='utf-8') as f:
f.read()
with语句在每次使用完后,无论是否产生异常,都会自动将文件关闭
在使⽤完后,应将⽂件关闭,如果不关闭,其他的程序将⽆法使⽤这个⽂件
5.2 文件操作函数及字符
| 函数 | 说明 |
|---|---|
| open() | 打开文件 |
| close() | 关闭文件 |
| read() | 读取文件 |
| write() | 写入文件 |
| readlines() | 逐行读取文档,配合for循环使用 |
open函数的mode参数可⽤的模式如下:
| 字符 | 含义 |
|---|---|
| ‘r’ | 读取(默认) |
| ‘w’ | 写⼊,并先截断⽂件 |
| ‘x’ | 排它性创建,如果⽂件已存在则失败 |
| ‘a’ | 写⼊,如果⽂件存在则在末尾追加 |
| ‘b’ | ⼆进制模式 |
| ‘t’ | ⽂本模式(默认) |
| ‘+’ | 打开⽤于更新(读取与写⼊) |
5.3 csv文件操作
| 字符 | 含义 |
|---|---|
| import csv | 导入 |
| reader() | 构造reader对象,可通过for循环遍历每行 |
| DictReader() | 构造字典型reader,可通过索引打印每列 |
| writer() | 写入生成列表 |
| writeheader() | 写表头 |
| writerow() | 写每一行 |
5.4 excel文件操作
要处理excel⽂件 ,我们需要使⽤借助第三⽅库,Python中能够处理excel⽂件格式的库有很多
- xlrd:⽤于读取 Excel ⽂件;
- xlwt:⽤于写⼊ Excel ⽂件;
- xlutils:⽤于操作 Excel ⽂件的实⽤⼯具,⽐如复制、分割、筛选等;
注意:这⼏个库只能处理xls格式的excel⽂件,对于⽐较新的excel版本,⽂件名通常是xlsx,需要先将其转存为xls⽂件。
5.4.1 读取excel——xlrd
| 函数 | 说明 |
|---|---|
| xlrd.open_workbook | 打开excel,返回xlrd.book.Book格式数据 |
| xlrd.xldate_as_datetime(cell.value,0) | 数值型转化为日期 |
xlrd.book.Book数据属性
| 函数 | 说明 |
|---|---|
| .nsheets | 返回表数量 |
| .sheets() | 返回所有表,生成一个列表 |
| .sheet_names() | 返回所有表名称 |
| .sheet_by_name() | 根据名称获取表(sheet格式数据) |
| .sheet_by_index() | 根据索引获取表 |
sheet格式数据属性
| 函数 | 说明 |
|---|---|
| .name | 返回单个表名称 |
| .nrows | 表中行数 |
| .ncols | 表中列数 |
| .row() | 根据索引返回列 |
| .col() | 根据索引返回行 |
| .row_values() | 根据索引返回行值 |
| .col_values() | 根据索引返回列值 |
| .cell(行索引,列索引) | 获取单元格(Cell格式) |
| .cell_value(行索引,列索引) | 单元格数值 |
| .cell_ctype(行索引,列索引) | 单元格数值类型 |
Cell格式数据属性
| 函数 | 说明 |
|---|---|
| Cell.value | 单元格数值 |
| Cell.ctype | 单元格数值的类型 |
单元格数值类型
| Type symbol | ctype值 | Python类型y |
|---|---|---|
| XL_CELL_EMPTY | 0 | 空字符串 |
| XL_CELL_TEXT | 1 | 字符串 |
| XL_CELL_NUMBER | 2 | float |
| XL_CELL_DATE | 3 | float |
| XL_CELL_BOOLEAN | 4 | int; 1表示True, 0表示False |
| XL_CELL_ERROR | 5 | 错误 |
| XL_CELL_BLANK | 6 | 空 |
5.4.2 写入excel——xlwt模块
| 函数 | 说明 |
|---|---|
| xlwt.Workbook() | 创建excel,返回xlwt.Workbook.Workbook格式数据 |
xlwt.Workbook.Workbook格式数据属性
| 函数 | 说明 |
|---|---|
| .add_sheet(表名,cell_overwrite_ok=True) | 添加表并命名,Worksheet格式 |
| wd.save(’./data_files/test_write.xls’) | 保存文件并命名 |
Worksheet格式数据属性
| 函数 | 说明 |
|---|---|
| .write(行索引,列索引,值) | 写入单元格值 |
| .row() | 行,Row格式 |
| .col() | 列,Column l格式 |
5.5 处理word
pip install python-docx
| 函数 | 说明 |
|---|---|
| from docx import Document | 导入Document包 |
| from docx.enum.text import WD_PARAGRAPH_ALIGNMENT | 导入包,文档设置的常量 |
| from docx.shared import Mm,RGBColor | 导入包,文档设置单位和颜色,此处导入毫米 |
| Document() | 创建文档,Document格式 |
Document格式数据属性
| 函数 | 说明 |
|---|---|
| .add_heading(标题,n) | 添加标题,n代表标题级别,Paragraph格式 |
| .add_paragraph(内容) | 添加段落 |
| .add_paragraph(内容,style=‘List Number’) | 添加有序列表 |
| .add_paragraph(内容,style='List Bullet) | 添加无序列表 |
| .add_table(rows=1,cols=3) | 添加表格 |
| .add_picture(地址,width=Mm(5)) | 添加图片 |
| .add_page_break() | 添加分页符 |
| .save() | 保存文档并命名 |
Paragraph格式数据属性
| 函数 | 说明 |
|---|---|
| .paragraph_format.alignment | 段落格式-对齐 |
| .paragraph_format.left_indent | 缩进 |
| .add_run().bold=True | 追加段落内容,加粗字体 |
| .font.name | 设置字体样式 |
| .font.size | 设置字体大小 |
| .font.color.rgb = RGBColor(0,0,0,) | 设置字体颜色 |
| .italic=True | 设置斜体 |
| .underline=True | 下划线 |
WD_PARAGRAPH_ALIGNMENT 常量
| 常量 | 说明 |
|---|---|
| CENTER | 居中 |
| LEFT | 靠左 |
| RIGHT | 靠右 |














 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









