






腾讯云智CSIG面试题目总结(因为博主是java三年转go一年,所以两种语言都会考察)
1.描述一下输入url到获得页面的过程
-
DNS解析:浏览器首先会检查本地缓存中是否有该域名的DNS记录,如果没有则向本地DNS服务器发起查询请求,如果本地DNS服务器也没有该域名的DNS记录,则会向根DNS服务器发起查询请求,直到找到对应的IP地址。
-
建立TCP连接:浏览器通过IP地址和端口号与服务器建立TCP连接。在此期间,浏览器和服务器会进行一些握手工作,如SYN、SYN-ACK、ACK等。
-
发送HTTP请求:建立TCP连接后,浏览器会向服务器发送HTTP请求,请求中包含请求方法、请求头、请求体等信息。
-
服务器处理请求并返回响应:服务器接收到请求后,会根据请求的内容进行相应的处理,并返回HTTP响应,响应中包含状态码、响应头、响应体等信息。
-
浏览器解析渲染页面:浏览器接收到响应后,会根据响应头中的Content-Type来确定响应体的类型,并进行相应的解析和渲染,最终呈现给用户的是一个完整的页面。在此过程中,浏览器还会下载页面所需的其他资源,如CSS、JS、图片等。
-
断开TCP连接:当浏览器接收完所有的响应数据后,会向服务器发送一个FIN包,表示断开TCP连接。服务器接收到FIN包后也会发送一个FIN包,表示同意断开连接,此时TCP连接关闭。
2.TCP和UDP介绍一下, 讲讲应用场景
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是两种常见的传输层协议,它们在网络通信中扮演着重要的角色。
TCP是一种面向连接的、可靠的协议。它通过三次握手建立连接,保证数据传输的可靠性,能够检测丢失的数据包并进行重传,确保数据的有序性,能够对数据进行流量控制和拥塞控制。TCP适用于对数据传输可靠性要求较高的应用场景,如文件传输、电子邮件等。
UDP是一种无连接的、不可靠的协议。它不需要建立连接,也不会对数据传输进行确认和重传,因此传输效率较高,但是数据传输的可靠性和有序性无法保证。UDP适用于对数据传输实时性要求较高的应用场景,如音视频传输、游戏等。
下面是TCP和UDP的一些常见应用场景:
TCP的应用场景:
- 文件传输:TCP能够保证数据传输的可靠性和有序性,适合用于文件传输。
- 电子邮件:TCP能够保证邮件传输的可靠性,确保邮件不会丢失或损坏。
- 网页浏览:TCP能够保证网页内容的完整性和有序性,确保网页能够正确地显示。
UDP的应用场景:
- 音视频传输:UDP传输效率高,对实时性要求高的音视频传输非常适合。
- 游戏:游戏中需要快速响应用户操作,UDP能够提供较低的延迟和较高的传输效率,适合用于游戏传输。
- DNS查询:DNS查询通常只需要发送一个请求,不需要建立长连接,使用UDP能够提高查询效率。
3.Spring AOP原理和实现
Spring AOP(面向切面编程)是 Spring 框架的一个核心特性,用于在应用程序中实现横切关注点的模块化。它通过将横切逻辑从业务逻辑中分离出来,使得代码更加模块化、可维护和可重用。
Spring AOP 的原理和实现主要涉及以下几个方面:
-
切面(Aspect):切面是横切逻辑的模块化单元,它定义了在哪些连接点上执行什么样的横切逻辑。在 Spring AOP 中,切面通常由一个 Java 类表示,并使用注解或 XML 配置进行声明。
-
连接点(Join Point):连接点是应用程序中可以插入切面的点。在 Spring AOP 中,连接点通常是方法调用或方法执行时的特定位置。例如,当一个方法被调用时,该方法的调用就是一个连接点。
-
切入点(Pointcut):切入点是一组连接点的集合,它定义了哪些连接点应该被切面处理。切入点可以使用表达式语言或正则表达式进行定义,以匹配特定的连接点。
-
通知(Advice):通知是切面在特定连接点执行的动作。在 Spring AOP 中,有以下几种类型的通知:
- 前置通知(Before Advice):在连接点之前执行的通知。
- 后置通知(After Advice):在连接点之后执行的通知,无论连接点是否正常执行完成。
- 返回通知(After Returning Advice):在连接点正常执行完成后执行的通知。
- 异常通知(After Throwing Advice):在连接点抛出异常后执行的通知。
- 环绕通知(Around Advice):包围连接点的通知,在连接点之前和之后都可以执行自定义的逻辑。
-
代理(Proxy):Spring AOP 通过代理来实现横切逻辑的织入。当一个被代理的对象的方法被调用时,代理对象会拦截方法调用,并在合适的连接点上执行切面的逻辑。
Spring AOP 的实现主要依赖于动态代理技术。在运行时,Spring 框架使用 JDK 动态代理或 CGLIB 动态代理创建一个代理对象,该代理对象将切面逻辑织入到目标对象的方法调用中。JDK 动态代理基于接口进行代理,而 CGLIB 动态代理则可以代理没有实现接口的类。
总结起来,Spring AOP 的原理是通过动态代理技术,在特定的连接点上将切面逻辑织入到目标对象的方法调用中,从而实现横切关注点的模块化。这使得应用程序的代码更加清晰、可维护,并且提高了代码的复用性。
4.MySQL慢查询和调优的办法?/你一般怎么对MySQL进行调优?
MySQL慢查询是指执行时间较长的SQL语句,可能会导致系统性能下降。为了解决慢查询问题,可以采取以下几种调优办法:
-
使用索引:索引是提高查询效率的重要手段,可以加速数据的查找和过滤。在设计数据库表时,根据查询的需求合理地创建索引。
-
优化查询语句:通过分析慢查询日志或使用
EXPLAIN命令来查看查询计划,找出慢查询的原因。优化查询语句的方式包括避免全表扫描、减少不必要的连接和子查询、合理使用JOIN等。 -
调整服务器参数:MySQL有很多配置参数可以调整,以适应不同的应用场景。常见的参数包括
innodb_buffer_pool_size(InnoDB缓冲池大小)、key_buffer_size(MyISAM索引缓冲区大小)、query_cache_size(查询缓存大小)等。根据实际情况,适当调整这些参数的值。 -
分析表结构和数据量:检查表的设计是否合理,避免冗余字段和重复数据。如果表中数据量过大,可以考虑分表或分区技术来减轻查询压力。
-
使用数据库连接池:数据库连接的建立和关闭是比较耗时的操作,使用连接池可以减少连接的创建和销毁次数,提高性能。
-
定期优化数据库:定期进行数据库维护工作,如表碎片整理、索引重建等,以保持数据库的良好状态。
-
使用缓存技术:对于经常被查询的数据,可以使用缓存技术(如Redis、Memcached)将数据缓存起来,减少对数据库的访问次数。
-
增加硬件资源:如果以上方法无法满足需求,可以考虑增加服务器的硬件资源,如CPU、内存、磁盘等,提升系统的整体性能。
需要注意的是,不同的应用场景和数据库架构可能需要采取不同的调优策略,因此在实际操作中,需要根据具体情况进行分析和优化。同时,定期监控数据库性能,并及时处理慢查询问题,是保持数据库高效运行的重要工作。
5.TCP三次握手和四次挥手的流程(八股文,许多人的面经里面出现过)
三次握手和四次挥手是在TCP(传输控制协议)中建立和终止连接时所采用的流程。下面是它们的具体流程:
三次握手(建立连接):
- 客户端向服务器发送一个SYN(同步)包,其中包含一个随机生成的初始序列号。
- 服务器收到SYN包后,回复一个SYN-ACK(同步-确认)包,其中包含确认号(ACK)为客户端的初始序列号加一,并且也包含一个随机生成的初始序列号。
- 客户端收到服务器的SYN-ACK包后,发送一个确认包ACK给服务器,确认号为服务器的初始序列号加一。
通过这个三次握手过程,客户端和服务器都确认了彼此的接收能力和发送能力,建立了可靠的连接。
四次挥手(终止连接):
- 客户端发送一个FIN(结束)包,表示客户端不再发送数据。
- 服务器收到FIN包后,回复一个ACK包,确认收到客户端的结束请求。
- 服务器发送一个FIN包,表示服务器也不再发送数据。
- 客户端收到服务器的FIN包后,回复一个ACK包,确认收到服务器的结束请求。
通过这个四次挥手过程,客户端和服务器都确认彼此已经完成数据的发送,并且可以安全地关闭连接。
需要注意的是,三次握手和四次挥手过程中的ACK(确认)号都是用来确认收到对方数据的序列号加一。这样可以确保双方都知道对方已经收到了哪些数据,从而保证可靠的数据传输和连接的正常关闭。
6.挥手中服务端等待客户端响应超时怎么解决(附加问题)
当服务器在挥手过程中等待客户端响应超时时,可以采取以下几种解决方法:
-
调整超时时间:服务器可以调整等待客户端响应的超时时间。如果超时时间设置得太短,可能会导致误判客户端未响应;而设置得太长,则可能延迟连接的关闭。根据具体情况,可以适当调整超时时间,以平衡连接关闭的效率和可靠性。
-
重传挥手请求:服务器可以尝试重新发送挥手请求给客户端,以确保客户端能够正常响应。可以设置多次重传的机制,每次重传之间间隔一段时间,直到收到客户端的响应或达到最大重传次数为止。
-
强制关闭连接:如果服务器在等待客户端响应超时后,确定客户端无法响应或已经失去响应能力,服务器可以主动关闭连接,丢弃未响应的数据。这样可以避免长时间占用服务器资源,并及时释放连接资源。
-
检查网络状况:服务器还可以检查网络状况,包括网络延迟、丢包率等指标。如果发现网络存在异常,可以尝试修复或切换到其他可用的网络路径,以提高挥手过程的可靠性和稳定性。
需要注意的是,针对挥手过程中等待客户端响应超时的解决方法,应根据具体的系统环境和需求来选择和实施。同时,为了确保连接的可靠关闭,服务器和客户端之间应遵循TCP协议规定的挥手流程,并进行适当的错误处理和异常情况处理。
7.MySQL引擎的比较(这个一般只需要知道前两个)
MySQL是一个流行的关系型数据库管理系统,支持多种引擎。每个引擎都有其自己的优点和适用场景。下面是一些常见的MySQL引擎及其比较:
- MyISAM引擎
MyISAM是MySQL最早的引擎之一。它是一个非事务性、表锁定的引擎,适用于读操作频繁、写操作较少的应用程序。MyISAM支持全文索引和压缩表功能,但不支持外键约束、事务和行级锁。
- InnoDB引擎
InnoDB是MySQL默认的存储引擎。它是一个事务性、行锁定的引擎,适用于高并发、写操作频繁的应用程序。InnoDB支持外键约束、事务和行级锁,但不支持全文索引和压缩表功能。
- MEMORY引擎
MEMORY是一个内存型引擎,它将数据存储在内存中,适用于对读写速度要求很高的应用程序。MEMORY引擎不支持事务、行级锁和外键约束,但支持哈希索引。
- NDB Cluster引擎
NDB Cluster是MySQL的分布式集群引擎,适用于高可用性、高并发、大规模数据的应用程序。NDB Cluster支持事务、行级锁和外键约束,但不支持全文索引和哈希索引。
总的来说,选择哪种引擎取决于应用程序的具体需求。如果应用程序需要高并发、事务性和行级锁,那么InnoDB是一个很好的选择;如果应用程序需要快速读写、不需要事务和行级锁,那么MyISAM或MEMORY可能更适合;如果应用程序需要高可用性和分布式集群,那么NDB Cluster是一个好的选择。
[博主注]关于全文检索:支持全文检索的引擎是MyISAM和InnoDB,但它们实现全文检索的方式不同。
在MyISAM中,全文检索是通过创建全文索引来实现的。全文索引会对需要进行全文检索的列进行分词,并将分词后的结果存储在倒排索引中。当进行全文检索时,MySQL会根据关键词在倒排索引中的位置来查找匹配的行。
在InnoDB中,全文检索是通过插件来实现的。该插件使用了与MyISAM不同的算法,可以提供更好的性能和更高的准确度。与MyISAM不同,InnoDB中的全文索引是基于词组而不是单词的,这意味着它可以更好地处理短语搜索和近义词。
需要注意的是,虽然InnoDB支持全文检索,但它的全文检索功能比MyISAM要复杂,因此在使用InnoDB进行全文检索时需要更多的配置和优化。
8.MySQL隔离级别(老生常谈八股文)
MySQL支持多种隔离级别,用于控制并发事务的行为。以下是MySQL中常见的隔离级别:
-
读未提交(Read Uncommitted):最低级别的隔离级别,事务可以读取其他事务未提交的数据。这可能导致脏读(Dirty Read),即读取到未提交的数据。很少使用,因为它可能会导致脏读,即读取到未提交的数据。只有在对数据一致性要求非常低的情况下才能使用。
-
读已提交(Read Committed):保证一个事务只能读取到已经提交的数据。但是,在同一事务内,多次读取同一数据可能会得到不同的结果,因为其他事务可能在此期间对数据进行了修改。是MySQL默认的隔离级别,适用于大多数应用场景。它可以避免脏读,但可能会出现不可重复读和幻读问题。
-
可重复读(Repeatable Read):保证在同一事务中多次读取同一数据时,结果始终保持一致。其他事务对数据的修改只有在当前事务提交后才可见。适用于对数据一致性要求较高的场景,例如财务系统等。它可以避免脏读和不可重复读,但可能会出现幻读问题。
-
串行化(Serializable):最高级别的隔离级别,通过强制事务串行执行来避免并发问题。它可以防止脏读、不可重复读和幻读(Phantom Read),但会降低并发性能。适用于对数据一致性要求非常高的场景,例如银行转账等。它可以避免脏读、不可重复读和幻读,但会降低并发性能。
可以使用以下语句设置隔离级别:
SET TRANSACTION ISOLATION LEVEL <隔离级别>;
例如,要将隔离级别设置为可重复读:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
[博主注]名词解释:什么是 脏读 ,幻读, 不可重复读?
当多个事务并发执行时,可能会出现以下数据一致性问题:
-
脏读(Dirty Read):脏读指一个事务读取到了另一个事务未提交的数据。例如,事务A修改了某个数据,但还没有提交,此时事务B读取到了这个未提交的数据。如果事务A最终回滚,那么事务B读取到的数据是无效的。
-
不可重复读(Non-repeatable Read):不可重复读指在一个事务内,多次读取同一数据时得到了不同的结果。例如,事务A首先读取了某个数据,然后事务B修改了该数据并提交,事务A再次读取同一数据时,得到了与之前不同的结果。
-
幻读(Phantom Read):幻读指在一个事务内,多次查询同一个范围的数据时,得到了不同数量的结果。例如,事务A首先查询了某个范围内的数据,然后事务B插入了符合该范围的新数据并提交,事务A再次查询同一范围的数据时,得到了比之前更多的结果。
具体解释如下:
-
脏读:事务A读取到了事务B未提交的数据,导致事务A读取到的数据是不一致的,可能是无效的数据。
-
不可重复读:事务A在同一事务内多次读取同一数据,但是在此期间,其他事务对该数据进行了修改并提交,导致事务A每次读取到的结果不一致。
-
幻读:事务A在同一事务内多次查询同一个范围的数据,但是在此期间,其他事务插入了符合该范围的新数据并提交,导致事务A每次查询时得到的结果数量不一致。
这些问题的出现是由于并发事务引起的,而不同的隔离级别提供了不同的解决方案来避免或减少这些问题的发生。例如,可重复读隔离级别通过锁定读取的数据来避免脏读和不可重复读,而串行化隔离级别通过强制事务串行执行来避免所有这些问题的发生。
9.讲一下GET方法和POST方法
GET方法是用于从服务器获取资源的一种请求方法。当客户端发送GET请求时,它会向服务器传递一些参数,这些参数通常附加在URL的末尾。服务器根据这些参数返回相应的资源。GET请求是幂等的,即多次发送同样的GET请求会得到相同的结果,并不会对服务器产生影响。GET方法通常用于获取数据,例如浏览网页或检索信息。
举个例子,如果要获取一个名为example.com的网页,可以使用GET方法发送以下请求:
GET /index.html HTTP/1.1
Host: example.com
POST方法用于向服务器提交数据的一种请求方法。与GET不同,POST请求将数据放在请求体中,而不是作为URL参数传递。POST请求通常用于向服务器提交表单数据、上传文件等操作。POST请求不是幂等的,即多次发送同样的POST请求会对服务器产生不同的影响。
以下是一个使用POST方法提交表单数据的示例:
POST /submit-form HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
username=johndoe&password=secretpassword
在这个例子中,请求体中包含了用户名和密码等表单数据,服务器可以根据这些数据进行相应的处理。
发送POST请求时,通常会先发送请求头(header),收到状态码是100,然后再发送请求体(body)。
在发送POST请求之前,客户端会构建一个HTTP请求,其中包括请求行、请求头和请求体。请求头中包含了一些元数据,用于描述请求的属性和附加信息,例如Content-Type、Content-Length等。这些信息可以帮助服务器正确处理请求。
接下来,客户端会将请求头和请求体一起发送到服务器。请求体中包含了实际的数据,例如表单数据、上传的文件等。请求体的格式和内容根据具体的应用场景和需求而定。
服务器在接收到完整的请求后,会解析请求头和请求体,并根据其中的信息进行相应的处理。服务器可以根据Content-Type字段确定请求体的格式,以正确解析其中的数据。
需要注意的是,发送POST请求时,请求头和请求体之间通常会有一个空行作为分隔符,用于告知服务器请求头的结束和请求体的开始。
综上所述,发送POST请求时,首先发送请求头,然后再发送请求体,以便服务器能够正确理解和处理请求。
10.Linux常用命令你知道哪些?(如果你不是干运维的,只需略懂即可)
以下是一些常用的 Linux 命令:
ls:列出当前目录下的文件和文件夹。cd:切换目录。例如,cd /path/to/directory将进入指定路径的目录。pwd:显示当前所在的目录路径。mkdir:创建新的目录。例如,mkdir new_directory将在当前目录下创建一个名为new_directory的新目录。rm:删除文件或目录。例如,rm file.txt将删除名为file.txt的文件。cp:复制文件或目录。例如,cp file.txt /path/to/directory将复制 “file.txt” 到指定路径的目录。mv:移动文件或目录,也可用于重命名文件或目录。例如,mv file.txt /path/to/directory将移动 “file.txt” 到指定路径的目录。cat:显示文件内容。例如,cat file.txt将显示名为 “file.txt” 的文件内容。grep:在文件中搜索指定的模式。例如,grep "pattern" file.txt将在 “file.txt” 中搜索匹配 “pattern” 的行。chmod:修改文件或目录的权限。例如,chmod 755 file.txt将 “file.txt” 设置为所有者具有读、写和执行权限,其他用户具有读和执行权限。
11.chown:修改文件或目录的所有者。例如,chown user:group file.txt将 “file.txt” 的所有者更改为指定的用户和组。tar:创建或提取 tar 归档文件。例如,tar -cvf archive.tar file1 file2将创建一个名为 “archive.tar” 的 tar 归档文件,并将 “file1” 和 “file2” 添加到其中。unzip:解压缩 zip 压缩文件。例如,unzip archive.zip将解压缩名为 “archive.zip” 的压缩文件。ssh:通过 SSH 协议远程登录到另一台计算机。例如,ssh username@hostname将使用指定的用户名和主机名建立 SSH 连接。top:显示当前运行的进程和系统资源使用情况。df:显示磁盘空间使用情况。du:显示目录或文件的磁盘使用情况。man:查看命令的帮助文档。例如,man ls将显示有关 “ls” 命令的详细信息。
11.GoLang中如何设计测试用例
设计测试用例是软件开发中非常重要的一步,它可以帮助我们验证代码的正确性、健壮性和可靠性。下面是关于如何设计测试用例的一些建议,适用于 Go 语言的测试。
-
选择合适的测试框架:Go 语言内置了一个轻量级的测试框架
testing,它提供了一系列的函数和工具来编写和运行测试用例。你可以使用这个框架来进行单元测试和集成测试。 -
根据功能点设计用例:根据你要测试的功能点,设计测试用例。确保每个测试用例都覆盖到了代码的不同分支和边界条件。
-
编写测试函数:在 Go 中,测试用例是通过编写以
Test开头的函数来实现的。测试函数应该接受一个*testing.T类型的参数,用于报告测试的状态和结果。在测试函数中,你可以调用被测试的函数,并使用t.Error或t.Fail方法来判断测试是否通过。 -
使用断言进行验证:在测试函数中,使用断言来验证代码的行为是否符合预期。Go 语言提供了
testing包中的*testing.T类型的方法,例如t.Logf、t.Errorf和t.Fatalf,它们可以用于输出日志和错误信息,以及标记测试失败。 -
组织测试代码:将测试用例组织成逻辑上相关的测试集合。你可以使用
testing包中的TestSuite或TestMain函数来实现。测试集合可以帮助你更好地管理和运行测试用例。 -
运行测试:使用命令行工具或集成开发环境 (IDE) 来运行测试。在项目根目录下执行
go test命令,Go 会自动查找并运行所有以Test开头的函数。 -
分析测试结果:测试运行完成后,可以查看测试报告和日志,分析测试结果。如果有测试失败,可以通过日志和错误信息来定位问题,并进行修复。
下面是一个简单的示例代码和对应的测试用例,使用了 testing.T 方法进行断言和验证。
// 示例代码:计算两个整数的和
func Add(a, b int) int {
return a + b
}
// 示例测试用例
func TestAdd(t *testing.T) {
// 正常情况下的测试
result := Add(2, 3)
expected := 5
if result != expected {
t.Errorf("Add(2, 3) = %d; expected %d", result, expected)
}
// 测试负数相加
result = Add(-2, -3)
expected = -5
if result != expected {
t.Errorf("Add(-2, -3) = %d; expected %d", result, expected)
}
// 测试一个正数和零相加
result = Add(5, 0)
expected = 5
if result != expected {
t.Errorf("Add(5, 0) = %d; expected %d", result, expected)
}
}
在上面的示例中,我们定义了一个简单的函数 Add,用于计算两个整数的和。然后,我们编写了一个名为 TestAdd 的测试函数,它接受一个 *testing.T 类型的参数。
在 TestAdd 函数中,我们使用了 t.Errorf 方法来判断测试是否通过。如果测试失败,它会输出错误信息,指示实际结果与预期结果不符。
要运行这个测试用例,你可以在命令行中切换到包含这个代码文件的目录,并执行 go test 命令。Go 会自动查找并运行所有以 Test 开头的函数。
[博主注]: 还有个函数开头是Example的是示例代码, 也可以写在测试用例中, 用来做代码提示.当你使用这个函数时候, IDE将会提示你在这个函数上面写的注释内容信息.
例如我定义一个 对数据源数据进行分片处理函数:
type WSlice[T int64 | int32 | int16 | int8 | int] []T
// SplitIntSlice 对数据源数据进行分片处理
func (slice WSlice[T]) SplitIntSlice(sliceNum int) map[int][]T {
// 分片小于等于0, 则默认五个分片
if sliceNum <= 0 {
sliceNum = 5
}
// 每个分片的数据量
l := len(slice) / sliceNum
// 不能整除剩余的元素数量
balance := len(slice) % sliceNum
// Map<Integer, List<EbOrder>>
m := make(map[int][]T)
if l > 0 {
i := 0
for ; i < l; i++ {
m[i] = slice[i*sliceNum : (i+1)*sliceNum]
}
// 把最后取余的放进去
if len(slice)%sliceNum != 0 {
m[i+1] = slice[len(slice)-balance:]
}
} else {
m[0] = slice
}
return m
}
写一个Example开头的函数用来做示例
func ExampleWSlice_SplitIntSlice() {
var s64 = WSlice[int64]{1, 2, 8, 15, 6, 99, 351, 4564, 77699}
fmt.Println(s64.SplitIntSlice(3))
var s8 = WSlice[int8]{1, 8, 6, 9, 8}
fmt.Println(s8.SplitIntSlice(2))
// Output: map[0:[1 2 8] 1:[15 6 99] 2:[351 4564 77699]]
//map[0:[1 8] 1:[6 9] 3:[8]]
}
执行这个函数会输出以下内容, 注意注释的地方书写方式
=== RUN ExampleWSlice_SplitIntSlice
--- PASS: ExampleWSlice_SplitIntSlice (0.00s)
PASS
12.Spring事务和事务隔离级别(本质前面的[MySQL隔离级别]一样)
在Spring中,事务是通过@Transactional注解来定义的。@Transactional注解可以应用于方法级别,也可以应用于类级别。当应用于类级别时,所有类中的方法都将具有相同的事务属性。
Spring支持多种事务隔离级别,包括:
-
读未提交(READ_UNCOMMITTED):允许事务读取未提交的数据更改。这是最低的隔离级别,因为它会导致脏读、不可重复读和幻读等问题。
-
读已提交(READ_COMMITTED):只允许事务读取已经提交的数据更改。这个隔离级别可以避免脏读问题,但是仍然可能会遇到不可重复读和幻读问题。
-
可重复读(REPEATABLE_READ):保证在同一事务中多次读取同一数据时,其结果始终相同。这个隔离级别可以避免脏读和不可重复读问题,但仍然可能会遇到幻读问题。
-
序列化(SERIALIZABLE):最高的隔离级别,完全禁止不同事务之间的并发执行。这个隔离级别可以避免所有并发问题,但是会影响性能。
在Spring中,默认的事务隔离级别是读已提交(READ_COMMITTED)。如果需要使用其他隔离级别,可以在@Transactional注解中指定隔离级别,例如:@Transactional(isolation = Isolation.READ_UNCOMMITTED)。
13.ConcurrentHashmap的原理
ConcurrentHashMap是Java中线程安全的哈希表实现,它是对HashMap的并发优化版本。在多线程环境下,ConcurrentHashMap提供了高效的并发读写操作,并保证数据的一致性和正确性。
ConcurrentHashMap的原理如下:
-
分段锁:ConcurrentHashMap内部使用了一种叫做"分段锁"的机制。它将整个哈希表分成了多个段(Segment),每个段维护着一个独立的哈希表。不同的线程可以同时访问不同的段,从而实现了并发读写操作。每个段内部使用了独立的锁来控制并发访问,因此只有当两个线程同时访问同一个段时才会发生竞争。
-
Hash定位和数据存储:ConcurrentHashMap使用哈希算法来定位元素在哈希表中的位置。当插入或获取元素时,首先根据元素的哈希值找到对应的段,然后在该段的哈希表中进行操作。每个段维护着一个Entry数组,每个Entry包含一个键值对。
-
并发控制:在并发写操作时,ConcurrentHashMap使用了一种称为"锁分段"的策略。即只锁定需要修改的段,而不是整个哈希表。这样可以最大程度地提高并发性能。在读操作时,不需要加锁,可以实现高效的并发读取。
-
扩容:ConcurrentHashMap在扩容时,会对每个段进行独立的扩容操作。这样可以减小扩容的粒度,减少了扩容过程中的竞争,并且不会影响到其他段的并发访问。
总结起来,ConcurrentHashMap通过分段锁、哈希定位和数据存储、并发控制以及独立的段扩容等机制,实现了高效的并发读写操作。它是在多线程环境下进行高效并发操作的首选数据结构之一。
14.TCP/IP协议的拥塞控制,为什么要先指数增长再线性增长?
TCP/IP协议是现代计算机网络中最为常用的协议之一,其中TCP协议负责实现可靠的数据传输,而IP协议负责实现数据的路由和转发。拥塞控制是TCP协议中的一个重要机制,用于避免网络拥塞和提高网络的可靠性。
在TCP协议中,拥塞控制是通过动态调整发送窗口大小来实现的。具体来说,当网络出现拥塞时,TCP协议会减小发送窗口的大小,以降低数据发送的速率,从而避免网络拥塞的进一步恶化。而当网络恢复正常时,TCP协议会逐渐增加发送窗口的大小,以提高数据发送的速率。
为了更好地实现拥塞控制,TCP协议采用了先指数增长再线性增长的方式来动态调整发送窗口大小。具体来说,当网络出现拥塞时,TCP协议将发送窗口大小减小为原来的一半,这被称为“拥塞窗口减小”(Congestion Window Reduction,CWR)。而当网络恢复正常时,TCP协议会通过指数增长的方式逐步增加发送窗口大小,直到网络出现拥塞为止。此后,TCP协议将发送窗口大小线性增长,以逐步提高数据发送的速率。
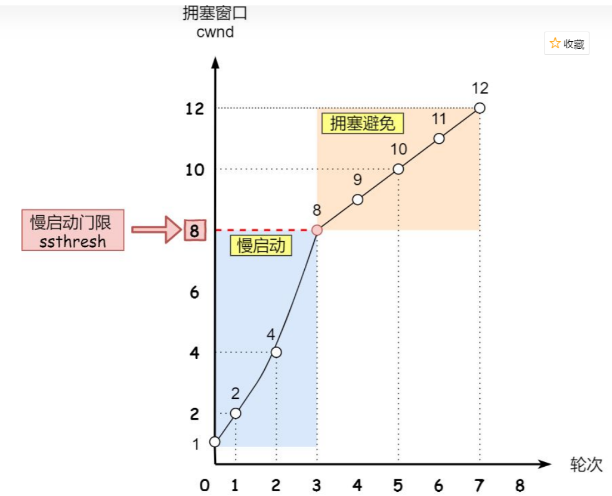
下载文件开始时候略慢, 然后速度越来越快就是这个原因.
在下载文件时,TCP协议通过拥塞窗口(Congestion Window)来控制数据发送的速率。初始阶段,TCP会使用一个较小的拥塞窗口大小进行传输,这被称为慢启动(Slow Start)阶段。在慢启动阶段,TCP会以指数增长的方式逐渐增加拥塞窗口的大小,从而提高数据发送的速率。
当拥塞窗口达到一定阈值时,TCP会进入拥塞避免(Congestion Avoidance)阶段。在拥塞避免阶段,TCP会以线性增长的方式逐渐增加拥塞窗口的大小,以更稳定地控制数据发送的速率。
因此,在开始下载文件时,TCP协议会以较小的拥塞窗口大小开始传输,导致速度相对较慢。随着时间的推移,拥塞窗口逐渐增大,数据发送的速率也随之增加,从而使得下载速度逐渐加快。
需要注意的是,下载速度的快慢还受到其他因素的影响,例如网络带宽、服务器性能、网络拥塞程度等。但TCP协议中的拥塞控制机制确实会导致下载速度开始较慢,然后逐渐加快的现象。
15.说一下panic()和recover()
Go语言中的recover函数用于从panic中恢复。在Go语言中,当发生panic时,程序会立即停止执行当前函数的剩余代码,并开始向上层调用栈传播panic,直到遇到一个recover函数。
recover函数可以捕获并处理panic,使程序能够继续执行而不是终止。它返回一个被panic传递的值(也就是panic的参数),如果没有发生panic,recover函数会返回nil。
需要注意的是,recover函数只有在defer语句中调用才有效。defer语句用于在函数返回之前执行一些操作,包括调用recover函数。通常,我们将recover放置在defer语句中以确保在发生panic时能够进行恢复。
下面是一个简单的示例,演示了如何使用recover函数从panic中恢复:
package main
import "fmt"
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered from panic:", r)
}
}()
panic("Oops! Something went wrong.")
fmt.Println("This line will not be executed.")
}
在上述示例中,panic函数触发了一个panic,然后程序执行到defer语句。defer中的匿名函数通过调用recover函数捕获了panic,并打印出相应的信息。由于恢复了panic,程序继续执行,输出"Recovered from panic: Oops! Something went wrong.",而后面的代码不会被执行。
通过使用recover函数,我们可以在Go语言中更好地处理和控制panic,从而实现程序的健壮性和可靠性。
16.defer的执行顺序
首先明确这是洋葱模型, 也可以理解为压栈的"后入先出",也就是说,最后一个defer语句会最先执行,而第一个defer语句会最后执行。
下面是一个简单的示例,演示了defer语句的执行顺序:
package main
import "fmt"
func main() {
defer fmt.Println("First defer")
defer fmt.Println("Second defer")
defer fmt.Println("Third defer")
fmt.Println("Hello, world!")
}
在上述示例中,我们在main函数中定义了三个defer语句,分别输出"First defer"、“Second defer"和"Third defer”。然后,在fmt.Println("Hello, world!")之后,程序退出main函数并执行defer语句。由于defer语句的执行顺序是"后进先出",因此输出的结果如下:
Hello, world!
Third defer
Second defer
First defer
需要注意的是,defer语句只有在函数返回之前才会执行。如果程序发生了panic,那么defer语句也会被执行,但是它们的执行顺序与正常情况下可能会不同。在这种情况下,最后一个defer语句仍然会最先执行,但是其他defer语句的执行顺序可能会与正常情况下不同。
17.HTTPS握手流程
HTTPS握手流程主要是进行SSL/TLS握手,其目的是在客户端和服务器之间建立一个安全的加密连接。以下是HTTPS握手的基本流程:

-
客户端发起请求:客户端(通常是Web浏览器)向服务器发送一个“ClientHello”消息,这个消息包含了客户端支持的SSL/TLS版本、支持的加密算法列表(Cipher Suite)以及一个客户端生成的随机数(Client Random)。
-
服务器响应:服务器收到客户端的“ClientHello”消息后,会从客户端提供的加密算法列表中选择一个加密算法,并从中选择一个SSL/TLS版本,然后生成一个自己的随机数(Server Random)。然后,服务器会将这些信息以及服务器的证书(包含公钥)一起打包成“ServerHello”消息发送给客户端。
-
客户端验证服务器证书:客户端收到“ServerHello”消息后,会验证服务器的证书是否由受信任的证书颁发机构(CA)签发,以及证书的有效期等信息。
-
生成预主密钥:如果服务器证书验证通过,客户端会生成一个新的随机数(Pre-Master Secret),然后使用服务器证书中的公钥进行加密,然后发送给服务器。
-
生成会话密钥:服务器收到客户端发送的加密过的Pre-Master Secret后,使用自己的私钥解密得到Pre-Master Secret。然后,客户端和服务器根据Client Random、Server Random以及Pre-Master Secret,通过一定的算法生成同样的会话密钥(Session Key)。
-
完成握手:客户端和服务器互相发送“Finished”消息,表示握手完成。接下来的通信都将使用之前生成的会话密钥进行加密。
以上就是HTTPS握手的基本流程,这个过程保证了客户端和服务器之间的通信是安全的,防止了中间人攻击。
18.GoLang的GMP模型(八股文,点击链接看这个就行了)
需要先明确这三个概念
GMP是goalng的线程模型,包含三个概念:内核线程(M),goroutine(G),G的上下文环境(P)
G:goroutine协程,基于协程建立的用户态线程
M:machine,它直接关联一个os内核线程,用于执行G
P:processor处理器,P里面一般会存当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度


19.进程间的通信方式
进程间的通信(Inter-Process Communication,IPC)是指在不同进程之间传递数据或信号的一种机制。有多种方法可以实现进程间的通信,包括:
-
管道(Pipe):管道是最早的IPC形式,它允许具有亲缘关系的进程之间进行通信。管道有两种类型,无名管道和有名管道。无名管道主要用于父子进程间的通信,而有名管道则可以用于任何进程间的通信。
-
消息队列(Message Queue):消息队列是一种链表结构,由内核维护。进程可以向消息队列中添加消息,也可以从中读取消息。
-
信号(Signal):信号是一种异步的通信方式,用于提醒进程某个事件已经发生。例如,当进程试图除以零时,会收到一个信号。
-
共享内存(Shared Memory):共享内存是最快的IPC方式,因为进程直接读写同一段内存区域。但是,由于多个进程可能同时操作这段内存,因此需要某种同步机制,如信号量。
-
套接字(Socket):套接字可以用于不同机器之间的进程通信。套接字支持TCP和UDP协议,可以实现不同主机之间的进程间通信。
-
信号量(Semaphore):信号量主要用于进程间的同步,而不是通信。进程可以使用信号量来控制对共享资源的访问。
-
共享文件(File Sharing):进程可以通过读写同一文件来进行通信。这种方式的优点是简单易用,缺点是需要磁盘I/O,效率较低。
每种通信方式都有其自身的特点,适用于不同的场景。在实际使用中,需要根据应用的具体需求来选择合适的通信方式。
20.在MySQL查询时候什么情况可能会破坏使用索引
在MySQL查询中,有几种情况可能会破坏使用索引,导致全表扫描:
-
使用了不等于(!=或<>)的查询条件:这会导致MySQL无法使用索引,因为它需要查找所有的数据来找出不满足条件的行。
-
使用了LIKE操作符,但是前缀是通配符:例如,LIKE ‘%abc’。如果通配符在前面,MySQL无法使用索引,因为它无法确定查找的起始点。
-
对索引列进行计算或函数操作:如果在WHERE子句中对索引列进行了函数操作或者计算,那么MySQL就不能使用索引。例如,WHERE YEAR(date) = 2021,或者WHERE id/2 = 100。
-
使用了OR操作符连接的条件:如果使用OR操作符来连接多个条件,且这些条件涉及的列都是索引列,那么MySQL可能无法使用索引。
-
索引列的数据类型和比较值的数据类型不匹配:如果数据类型不匹配,MySQL可能会进行隐式类型转换,这可能导致无法使用索引。
-
MySQL认为全表扫描更快:如果表的数据量很小,或者大部分行都满足查询条件,那么MySQL可能会选择全表扫描,而不是使用索引。
-
使用JOIN操作时,ON或者USING子句中的条件没有使用索引列:这种情况下,MySQL可能无法使用索引进行表连接。
每个数据库的优化器可能会有不同的行为,上述情况并不是绝对的,也可能会因为MySQL的版本、配置等因素产生不同的结果。在实际使用中,可以使用EXPLAIN命令来查看查询计划,分析是否使用了索引,以及如何优化查询。
21.为什么查询内存比查询磁盘快
查询内存比查询磁盘快的原因主要有以下几点:
-
物理结构:内存是基于半导体技术,数据存储和读取都是通过电信号的方式进行,而磁盘则是基于磁性材料,数据的读取和写入需要通过机械臂寻找数据的物理位置,这个过程相对来说要慢很多。
-
数据访问方式:内存的数据访问是随机的,即无论访问哪个地址,速度都是一样的。而磁盘的数据访问则是顺序的,即连续读取数据的速度要比随机读取数据的速度快。
-
寻址时间:内存的寻址时间通常在纳秒级别,而磁盘的寻址时间通常在毫秒级别,这是一个数量级的差距。
-
并发能力:现代计算机系统中的内存通常都支持多通道并发访问,而磁盘的并发访问能力则相对较弱。
22.说一下java中的AIO,BIO,NIO
AIO,BIO,NIO这三个词是Java中用来描述I/O模型的,分别代表Asynchronous I/O(异步I/O),Blocking I/O(阻塞I/O),Non-blocking I/O(非阻塞I/O)。
-
BIO(Blocking I/O):这是最传统的I/O处理模型。在此模型中,当一个线程发起一个I/O操作,例如读取数据,它必须等待操作系统完成这个操作才能继续执行。这就是所谓的阻塞,线程在等待数据的过程中被阻塞。这种模式的优点是编程模型简单,缺点是I/O效率低,因为线程在处理I/O的时候不能做其他事情。
-
NIO(Non-blocking I/O):这是Java 1.4之后引入的一种新的I/O处理模型。在这个模型中,线程发起一个I/O操作后并不需要等待操作系统完成,它可以继续做其他事情。当数据准备好后,线程会收到通知。这就是所谓的非阻塞,线程在等待数据的过程中可以做其他事情。这种模式的优点是可以提高I/O效率,缺点是编程模型相对复杂。
-
AIO(Asynchronous I/O):这是Java 7之后引入的一种新的I/O处理模型。在这个模型中,线程发起一个I/O操作后,操作系统会在后台完成这个操作,当操作完成后,操作系统会通知线程。这就是所谓的异步,线程在等待数据的过程中可以做其他事情。这种模式的优点是可以进一步提高I/O效率,缺点是编程模型更复杂。
23.Go协程如何通信的?channel底层是如何实现的?
Go语言中的协程(goroutine)通信主要通过channel来实现,这是一种特殊的类型,可以让数据在不同的goroutine之间进行传递。Go语言的设计者们遵循了“不要通过共享内存来通信,而应该通过通信来共享内存”的理念。
Channel的主要操作有两个:发送(<-chan)和接收(chan<-)。发送操作在有值可以发送时进行,接收操作在有值可以接收时进行。如果channel中没有值,那么接收操作就会阻塞,直到有值可以接收。如果channel已满,那么发送操作就会阻塞,直到有空间可以发送。
Channel的底层实现:
-
数据结构:Channel的底层是一个数据结构,包括一个用于存储数据的环形队列和一些状态信息,例如队列的长度和容量,以及指向等待读写的goroutine队列的指针等。
-
发送和接收:当一个值被发送到channel时,Go会检查是否有goroutine在等待接收,如果有,它会直接将值复制到接收方,然后唤醒接收方的goroutine。如果没有等待接收的goroutine,但channel的队列还有空间,那么值就会被放入队列。如果队列也满了,那么发送方的goroutine就会被阻塞,直到有空间或者有接收方。接收操作的逻辑与此类似。
-
关闭:Channel可以被关闭,一旦关闭,所有后续的发送操作都会立即返回一个错误。所有等待接收的goroutine会被唤醒并收到一个零值(例如 : int = 0 ,string = “”)和一个表示channel已关闭的信号(false)。
-
同步与并发:Channel的所有操作都是并发安全的,多个goroutine可以同时对同一个channel进行发送和接收操作,Go语言会通过锁和原子操作来保证同步。
[博主注]: 一个经典的例题: 使用Go语言协程和channel实现交替打印数组元素
func main() {
printNumber(10)
}
func printNumber(n int) {
c1 := make(chan bool)
wg := sync.WaitGroup{}
wg.Add(2)
go func(n int) {
defer wg.Done()
for i := 0; i <= n; i++ {
c1 <- true
if i%2 == 0 {
fmt.Println(i)
}
}
}(n)
go func(n int) {
defer wg.Done()
for i := 0; i <= n; i++ {
<-c1
if i%2 != 0 {
fmt.Println(i)
}
}
}(n)
wg.Wait()
}
24.有缓冲通道和无缓冲通道
在Go语言中,通道(channel)可以分为两种类型:有缓冲通道和无缓冲通道。
-
无缓冲通道:无缓冲的通道是指在发送和接收操作上没有缓冲的通道。当一个值被发送到无缓冲通道时,发送操作会阻塞,直到有其他goroutine执行接收操作。当从无缓冲通道接收值时,接收操作会阻塞,直到有其他goroutine执行发送操作。这种特性使得无缓冲通道成为goroutine之间同步的好工具。创建无缓冲通道的语法是
ch := make(chan type)。 -
有缓冲通道:有缓冲的通道是指在发送和接收操作上有缓冲空间的通道。当发送操作发生时,只有在缓冲区满时,发送操作才会阻塞。类似地,只有在缓冲区空时,接收操作才会阻塞。这种通道可以用来异步传递数据:可以把它看作是一个并发安全的队列。创建有缓冲通道的语法是
ch := make(chan type, capacity),其中capacity是通道的缓冲区大小。
25.GoLang中空结构体的作用
不包含任何字段的结构体叫做空结构体 struct{}
定义:
var et struct{}
et := struct{}{}
type ets struct {} / et := ets{} / var et ets
特性:
所有的空结构体的地址都是同一地址,都是zerobase的地址,且大小为0
使用场景:
- 用于保存不重复的元素的集合,Go的map的key是不允许重复的,用空结构体作为value,不占用额外空间。有点类似java的HashSet
- 用于channel中信号传输,当我们不在乎传输的信号的内容的时候,只是说只要用信号过来,通知到了就行的时候,用空结构体作为channel的类型
- 作为方法的接收者,然后该空结构体内嵌到其他结构体,实现继承
26.HTTP和HTTPS有什么区别
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)是用于在客户端和服务器之间传输数据的协议。它们之间的主要区别在于安全性和数据传输方式。
-
安全性:HTTP是一种不安全的协议,数据在传输过程中以明文形式发送,容易被攻击者截获并窃取敏感信息。而HTTPS通过使用SSL(Secure Sockets Layer)或TLS(Transport Layer Security)协议对数据进行加密和身份验证,确保数据在传输过程中的机密性和完整性,提供更高的安全性。
-
数据传输方式:HTTP使用TCP(Transmission Control Protocol)作为传输层协议,数据传输速度较快,但不具备数据完整性和加密功能。而HTTPS在HTTP的基础上加入了SSL/TLS协议,通过在传输层与应用层之间添加一个安全层,对数据进行加密和解密操作,确保数据的完整性和安全性。
-
默认端口:HTTP默认使用80端口进行通信,而HTTPS默认使用443端口。
-
证书要求:为了建立HTTPS连接,服务器需要获得一个数字证书,该证书由受信任的第三方机构颁发,用于验证服务器的身份。这样可以防止中间人攻击和伪装等安全威胁。
总结起来,HTTPS相对于HTTP提供了更高的安全性,通过加密和身份验证确保数据传输的机密性和完整性。因此,在涉及敏感信息(如个人身份信息、银行账号等)传输的场景中,使用HTTPS更为安全可靠。
27.MySQL的索引结构为什么使用B+树而不是普通二叉树?
相关文章: MySQL 简单了解B+树
MySQL使用B+树(B+ Tree)作为索引结构,而不是普通二叉树,主要有以下几个原因:

-
磁盘IO效率:B+树是一种多叉树,每个节点可以存储多个键值对,相比于二叉树,B+树的高度更低,减少了磁盘IO次数。在数据库中,数据通常存储在磁盘上,频繁的磁盘IO操作会影响查询性能。通过减少磁盘IO次数,B+树能够提高查询效率。
-
顺序访问性能:B+树的内部节点只存储键值对的索引信息,而叶子节点存储了完整的键值对,且叶子节点之间通过指针连接成链表。这种结构使得B+树具有很好的顺序访问性能,可以快速地进行范围查询和排序操作。
-
范围查询支持:由于B+树的叶子节点形成一个有序链表,可以方便地进行范围查询。例如,在查询一个区间范围内的数据时,只需要找到起始位置和结束位置的叶子节点,然后沿着链表遍历即可。
-
数据块的利用率:数据库系统中,为了减少磁盘IO次数,通常会以数据块(Page)为单位进行读写操作。B+树的节点设计得比较大,可以容纳更多的键值对,从而提高了数据块的利用率,减少了磁盘IO次数。
-
索引的稳定性:B+树的特点是平衡性和有序性,插入和删除操作相对复杂,但是通过维护平衡性和有序性,可以保证索引的稳定性。这对于数据库系统来说非常重要,因为索引的稳定性能够提供更可靠的查询性能和数据一致性。
总之,使用B+树作为索引结构能够提供高效的磁盘IO访问、支持范围查询、提高数据块利用率以及保证索引的稳定性,适合处理大规模数据存储和查询的数据库系统。
28.Linux怎么查看端口占用
在 Linux 系统中,你可以使用以下命令来查看端口的占用情况:
-
使用 netstat 命令:
netstat -tuln这会列出当前系统上所有正在监听的 TCP 和 UDP 端口以及对应的进程。
-
使用 ss 命令:
ss -tulnss 命令是 netstat 的替代工具,功能更强大,执行速度更快。
-
使用 lsof 命令:
lsof -i :端口号将 “端口号” 替换为你要查询的具体端口号。该命令会显示占用该端口的进程信息。
-
使用 fuser 命令:
fuser 端口号/tcp或
fuser 端口号/udp将 “端口号” 替换为你要查询的具体端口号,同时指定协议类型。该命令会显示占用该端口的进程 ID。
这些命令都需要以管理员权限运行,以便获取完整的端口信息。
29.简单描述下共享内存的原理
30.一致性哈希算法
一致性哈希算法被广泛应用于分布式系统和负载均衡的实现中。以下是一些使用一致性哈希算法的常见库和框架:
-
hashicorp/memberlist:这是一个由HashiCorp开发的库,提供了一致性哈希环的实现。它可以用于构建分布式系统中的成员列表,并支持自动故障检测和重新平衡。 -
go-redis/redis:Redis是一个流行的内存数据库,它使用一致性哈希算法来实现数据的分片和负载均衡。Go语言中的Redis客户端库go-redis/redis也支持一致性哈希算法,可以将数据分散到多个Redis节点上。 -
go-memcached:这是一个Memcached客户端库,用于与Memcached服务器进行交互。该库使用一致性哈希算法来选择要存储或检索数据的服务器节点。 -
nginx:虽然不是Go语言的库,但Nginx是一个常用的Web服务器和反向代理,它使用一致性哈希算法来实现负载均衡。通过配置Nginx的upstream模块,可以将请求分发到多个后端服务器。
31.某个节点负载过高怎么办
32.知道分布式系统中的CAP理论吗?介绍一下
CAP理论是分布式系统设计中的一个重要理论,它提出了在一个分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三个目标无法同时满足的问题。

具体来说,CAP理论认为,在一个分布式系统中,当发生网络分区(即网络故障导致节点之间无法通信)时,为了保证系统的可用性和性能,必须允许部分节点继续对外提供服务。而在此时,为了保持一致性,系统需要所有节点之间达成一致的状态,但由于网络分区的存在,无法进行全局一致性的协调。
因此,CAP理论指出,分布式系统设计者需要在一致性、可用性和分区容忍性之间做出权衡选择。根据CAP理论的原则,分布式系统可以满足以下两种模式:
-
CP模式:在网络分区的情况下,系统保持一致性(Consistency)和分区容忍性(Partition tolerance),但牺牲了可用性(Availability)。这意味着系统在发生网络分区时,会暂停对外服务,直到分区问题解决并保持一致性后才恢复服务。这种模式适用于对数据一致性要求较高的场景,如金融交易系统。
-
AP模式:在网络分区的情况下,系统保持可用性(Availability)和分区容忍性(Partition tolerance),但可能牺牲一致性(Consistency)。这意味着系统在发生网络分区时,仍然可以继续对外提供服务,但不保证所有节点之间的数据一致性。这种模式适用于对实时性要求较高的场景,如社交媒体应用。
CAP理论的目的是帮助分布式系统设计者更好地理解和权衡系统设计中的各种因素,以便根据具体需求选择合适的设计方案。它提醒我们,在分布式系统设计中不存在一种完美的解决方案,而是需要根据实际情况进行取舍和权衡。
33.强一致和最终一致分别用在什么场景
34.zk为什么要搞强一致性
35.paxos算法了解过吗
36.redis结构设计
37.redis的数据结构String和zset
38.有了解netty吗
39.hashmap为什么要用链表
40.为什么要有链表到红黑树
41.java栈和堆在程序运行的时候具体存放什么
42.golang 协程, channel 锁, 并发的理解
43.数组和切片的区别?
44.select 的底层数据结构?
45.map 是线程安全的?怎么保证线程安全?
46.Go 有什么锁?互斥锁和读写锁的区别?
47.Context 了解吗?
48.说一说 GMP 模型?怎么调度的?
49.TLS 协议的整体流程?
50.非对称加密和对称加密的区别?了解 RSA 的原理吗?
51.进程间通信有什么方式?
52.不同类型的 channel 读写有什么结果?
53.说一说 epoll,怎么选择 epoll 和 select?
54.了解 SQL 注入吗?
55.怎么实现一个分布式限流器?
写在最后
一些可以参考的go面试题目总结















 2795
2795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









