







朴素贝叶斯算法与上篇中写到到生成学习算法的思想是一致的。它不需要像线性回归等算法一样去拟合各种假设的可能,只需要计算各种假设的概率,然后选择概率最高的那种假设分类类别。其中还添入了一个贝叶斯假定:在给定目标值y时属性值x之间相互独立。这样的分类算法被称为朴素贝叶斯分类器(Naive Bayes classifier) 。
1、朴素贝叶斯算法
在朴素贝叶斯算法的模型里,给定的训练集为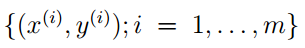
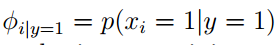
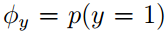
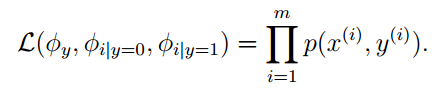
最大化联合似然概率函数可得到:
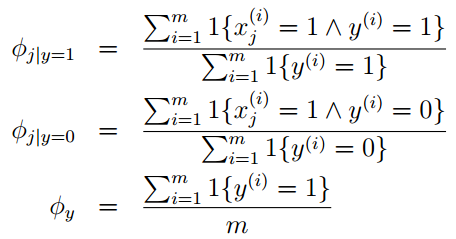
然后我们就可以对新的数据进行预测。预测公式为:
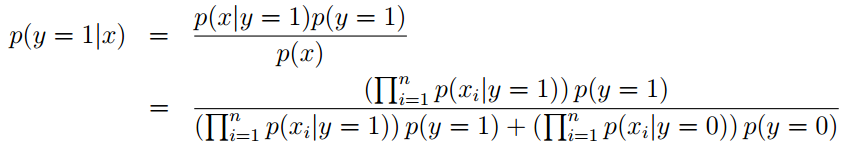
如果x只取两种值,则p(x|y)服从伯努力分布。如果 x取多种值,则p(x|y)服从多项分布。当x的取值是连续的时候,可以将y值区间离散化,再分别对各个区间分类命名为特定值。
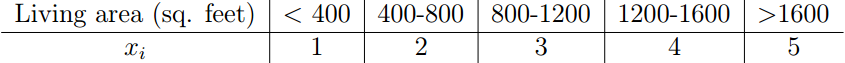
2、拉普拉斯平滑
在给定的训练集中,假设x的取值有k种{1,…,k},所以φi = p(z = i)。在未使用拉普拉斯平滑的情况下,
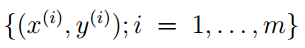
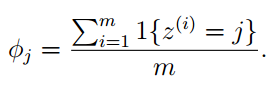
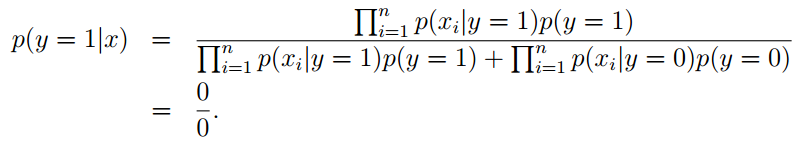
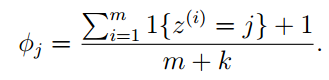
3、Naive Bayes和Multinomial event model的比较
在垃圾邮件的分类中,先设定一个垃圾词语字典索引,然后通过对邮件中是否含有垃圾词语字典索引中的词判断一封邮件是垃圾邮件的概率。在Naive Bayes中只需计算每个训练邮件文本中是否含有垃圾词语字典索引中的某一个词来计算垃圾邮件的概率,而在Multinomial event model中需要考虑垃圾字典索引中的某一个词在每个训练邮件文本中出现的次数来计算垃圾邮件的概率。
例如,一封邮件是“a nip...”,垃圾词语字典索引为{a,....,nip,....}(a为字典中第1个词语,nip为第35000个词语)。所以对于Naive Bayes来说,可表示为如下矩阵(矩阵第1元素为1,第35000个元素也为1)
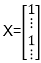
而在Multinomial event model中,表示为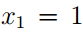
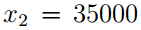
















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









