







shardingjdbc内核解析和核心源码分析
内核解析
ShardingSphere有3个产品。但是它们的数据分片主要流程是完全一致的。 流程核心由以下几部分组成。
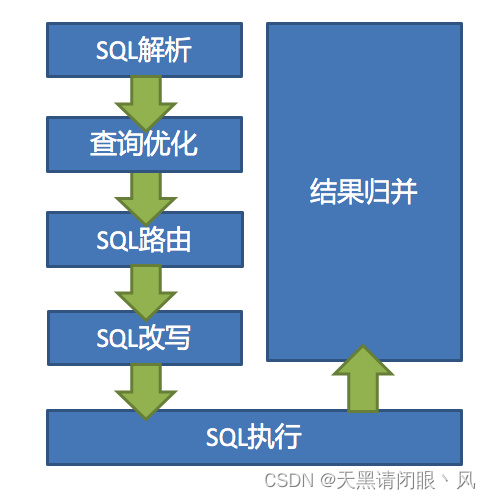
SQL解析和查询优化都是跟具体的数据库产品有关,在5.x新版本中,被统一进了SQL方言里。
解析引擎
相对于其他编程语言,SQL是比较简单的。 不过,它依然是一门完善的编程语言,因此对SQL的语法进行解析,与解析其他编程语言(如:Java语言、C语言、Go语言等)并无本质区别。
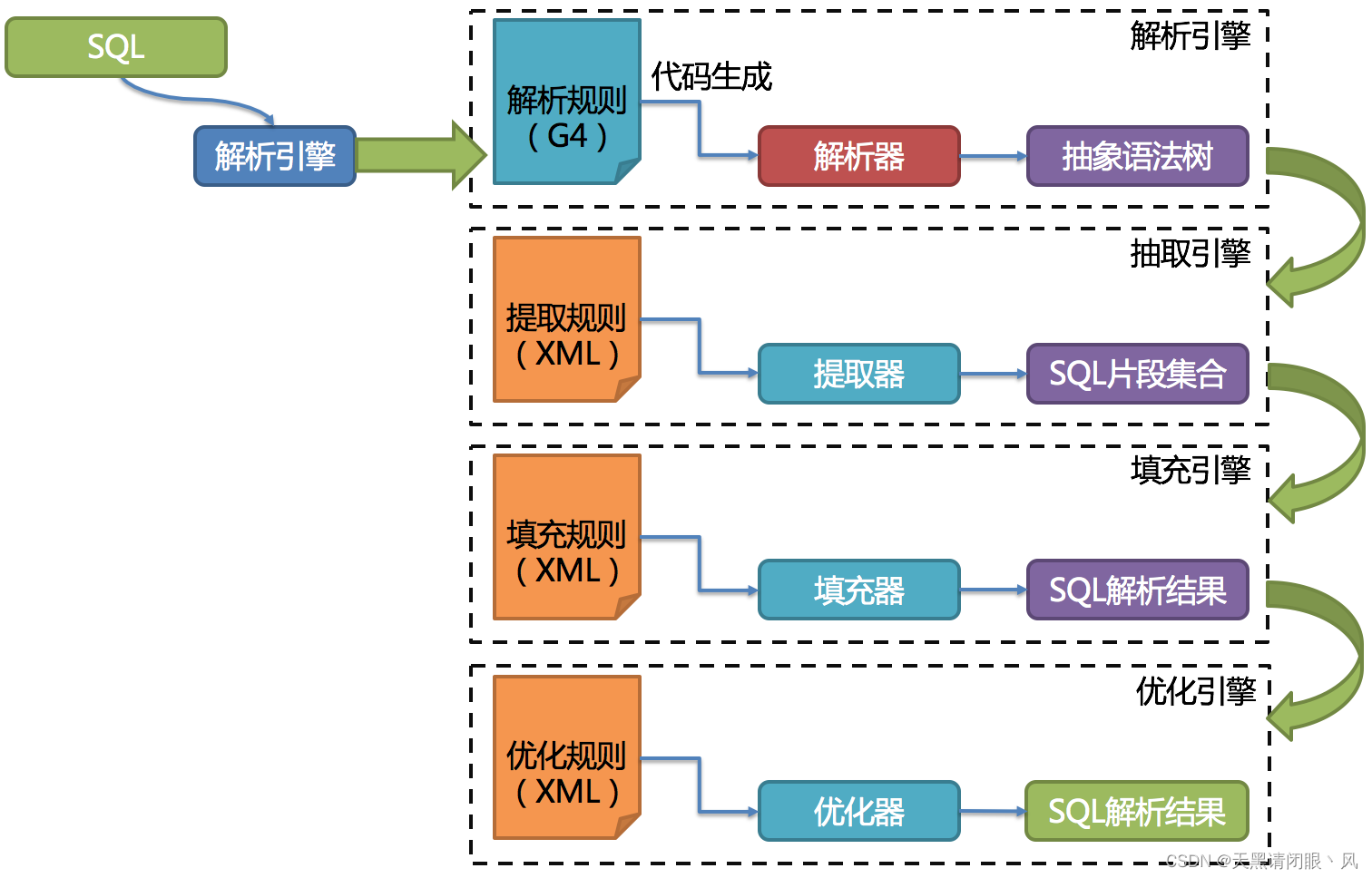
解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
例如,以下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图。

为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
最后,通过对抽象语法树的遍历去提炼分片所需的上下文,并标记有可能需要改写的位置。 供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。 SQL的一次解析过程是不可逆的,一个个Token的按SQL原本的顺序依次进行解析,性能很高。 考虑到各种数据库SQL方言的异同,在解析模块提供了各类数据库的SQL方言字典。
从3.0.x版本开始,ShardingSphere尝试使用ANTLR作为SQL解析的引擎,并计划根据DDL -> TCL -> DAL –> DCL -> DML –>DQL这个顺序,依次替换原有的解析引擎,目前仍处于替换迭代中。 使用ANTLR的原因是希望ShardingSphere的解析引擎能够更好的对SQL进行兼容。对于复杂的表达式、递归、子查询等语句,虽然ShardingSphere的分片核心并不关注,但是会影响对于SQL理解的友好度。 经过实例测试,ANTLR解析SQL的性能比自研的SQL解析引擎慢3-10倍左右。为了弥补这一差距,ShardingSphere将使用PreparedStatement的SQL解析的语法树放入缓存。 因此建议采用PreparedStatement这种SQL预编译的方式提升性能。
第三代SQL解析引擎的整体结构划分如下图所示
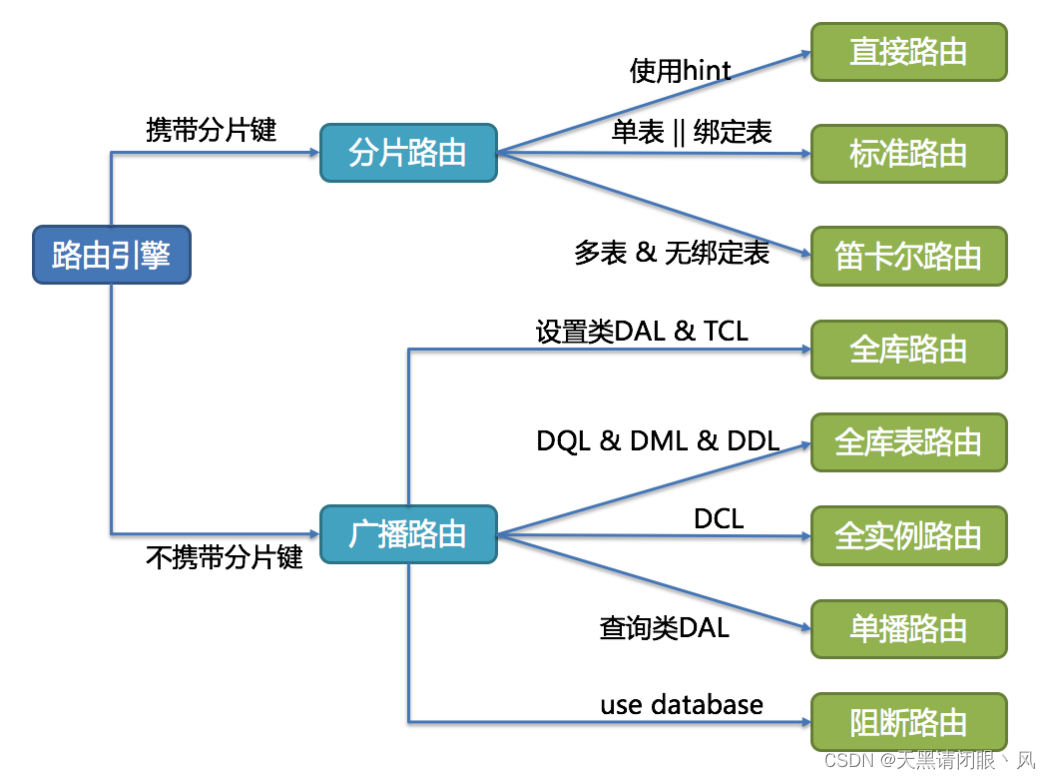
路由引擎
解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN)。 不携带分片键的SQL则采用广播路由。
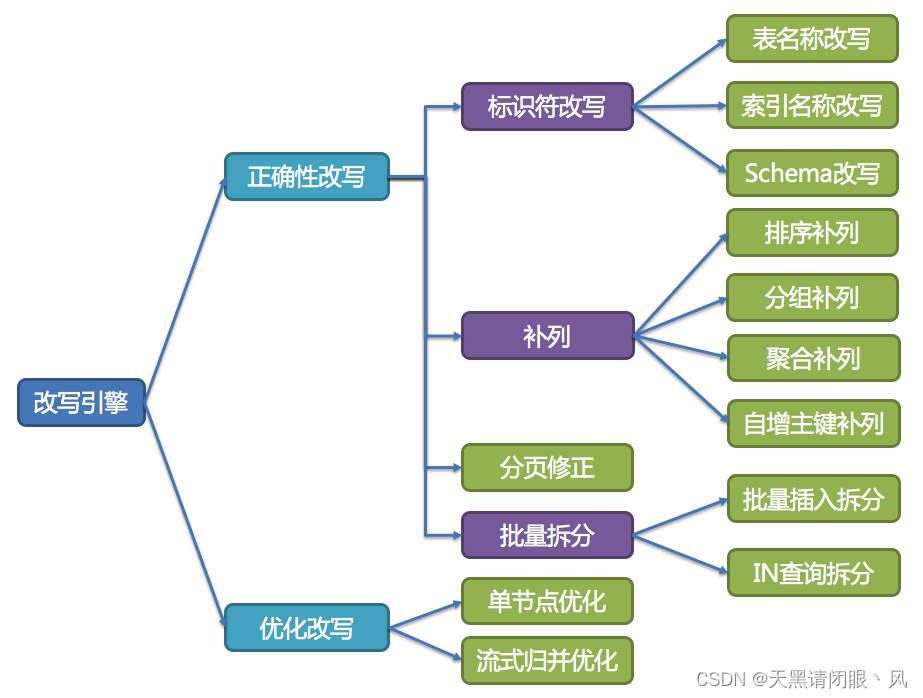
改写引擎
工程师面向逻辑库与逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据库中可以正确执行的SQL。 它包括正确性改写和优化改写两部分。
正确性改写
逻辑sql:SELECT order_id FROM t_order WHERE order_id=1; 改写为:SELECT order_id FROM t_order_1 WHERE order_id=1
对于复杂的sql:SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
改写为:SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx';
优化改写
优化改写的目的是在不影响查询正确性的情况下,对性能进行提升的有效手段。它分为单节点优化和流式归并优化。
单节点优化
路由至单节点的SQL,则无需优化改写。 当获得一次查询的路由结果后,如果是路由至唯一的数据节点,则无需涉及到结果归并。因此补列和分页信息等改写都没有必要进行。 尤其是分页信息的改写,无需将数据从第1条开始取,大量的降低了对数据库的压力,并且节省了网络带宽的无谓消耗。
流式归并优化
它仅为包含GROUP BY的SQL增加ORDER BY以及和分组项相同的排序项和排序顺序,用于将内存归并转化为流式归并。 在结果归并的部分中,将对流式归并和内存归并进行详细说明。
改写引擎的整体结构划分如下图所示
执行引擎
ShardingSphere采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率。
例如他的连接模式分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。内存限制模式只关注一个数据库连接的处理数量,通常一张真实表一个数据库连接。而连接限制模式则只关注数据库连接的数量,较大的查询会进行串行操作。
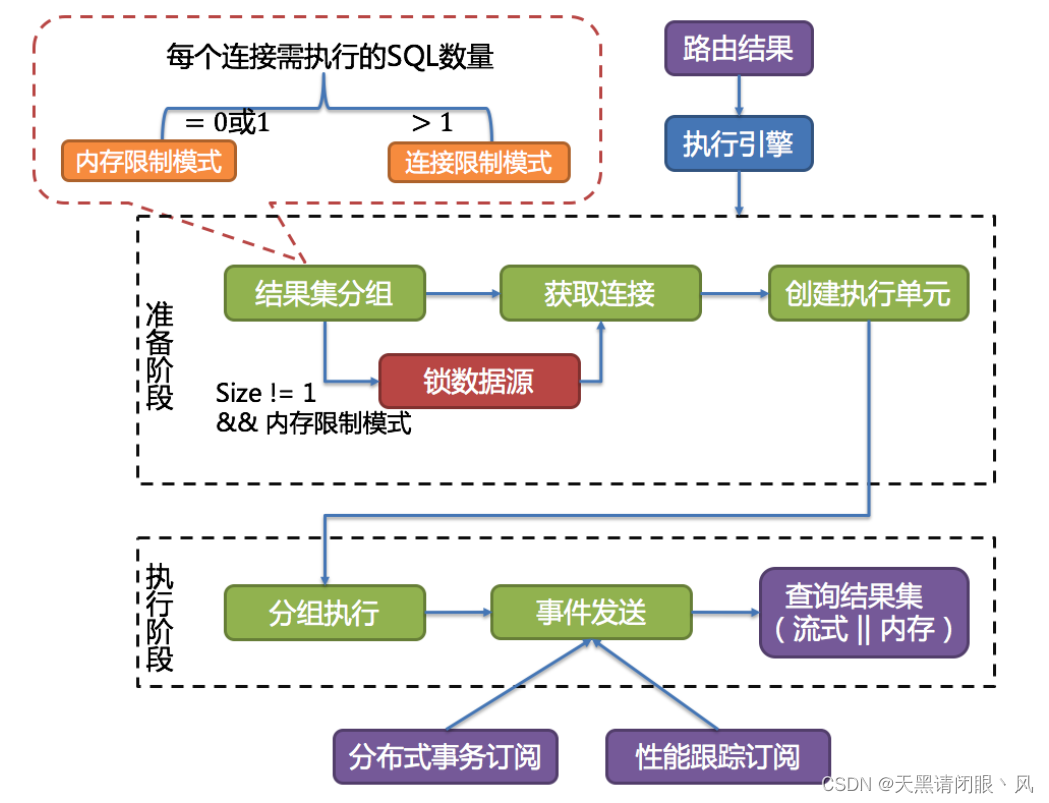
这两个模式的区分涉及到一个参数 spring.shardingsphere.props.max.connections.size.per.query=50
(默认值1,配置参见源码中ConfigurationPropertyKey类)。ShardingSphere会根据 路由到某一个数据源的路由结果计算出所有需
在数据库上执行的SQL数量,用这个数量除以 用户的配置项,得到每个数据库连接需执行的SQL数量。数量>1就会选择连接限制模式,数量<=1就会选择内存限制模式。
内存限制模式不限制连接数,也就是说会建立多个数据连接,然后并发控制每个连接只去读取一个数据分片的数据。这样可以最快速度的把所有需要的数据读出来。并且在后面的归并阶段,会选择以每一条数据为单位进行归并,就是后面提到的流式归并。这种归并方式归并完一批数据后,可以释放内存了,可以很好的提高数据归并的效率,并且防止出现内存溢出或垃圾回收频繁的情况。他的吞吐量比较大,比较适合OLAP场景。
连接限制模式会对连接数进行限制,也就是说至少有一个数据库连接会要去读取多个数据分片的数据。这样他会对这个数据库连接采用串行的方式依次读取多个数据分片的数据。而这种方式下,会将数据全部读入到内存,进行统一的数据归并,也就是后面提到的内存归并。这种方式归并效率会比较高,例如一个MAX归并,直接就能拿到最大值,而流式归并就需要一条条的比较。比较适合OLTP场景。
归并引擎
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
ShardingSphere支持的结果归并从功能上分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系。 从结构划分,可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
由于从数据库中返回的结果集是逐条返回的,并不需要将所有的数据一次性加载至内存中,因此,在进行结果归并时,沿用数据库返回结果集的方式进行归并,能够极大减少内存的消耗,是归并方式的优先选择。
流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
装饰者归并是对所有的结果集归并进行统一的功能增强,目前装饰者归并有分页归并和聚合归并这2种类型。
归并引擎的整体结构划分如下图

核心源码分析
shardingjdbc的源码有很多模块,怎么去看源码呢,首先要找到一个入口,这个入口使用官网的一个案例
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一个数据源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("");
dataSourceMap.put("ds0", dataSource1);
// 配置第二个数据源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1");
dataSource2.setUsername("root");
dataSource2.setPassword("");
dataSourceMap.put("ds1", dataSource2);
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order","ds${0..1}.t_order${0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 省略配置order_item表规则...
// ...
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
//通过数据眼获取连接 访问数据库
Connection conn = null;
try {
//ShardingConnectioin
conn = dataSource.getConnection();
//ShardingStatement
Statement statement = conn.createStatement();
String sql = "SELECT cid,cname,user_id,cstatus from course";
//ShardingResultSet 执行sql
ResultSet result = statement.executeQuery(sql);
while (result.next()) {
System.out.println("result:" + result.getInt("cid"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (null != conn) {
conn.close();
}
}
那么入口点有两个,一个创建shardingjdbc的数据源 DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());;
一个是通过数据源码获取数据库连接执行sql ResultSet result = statement.executeQuery(sql);
分析shardingjdbc的主要流程
流程一:创建数据源
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
//dataSourceMap 就是数据源的信息包括(地址,密码 用户名,连接等),
//shardingRuleConfig 分库分表的配置信息。
//props:其他属性配置
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap, final ShardingRuleConfiguration shardingRuleConfig, final Properties props) throws SQLException {
//创建ShardingRule以及ShardingDataSource实例
return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
该行代码做了什么事情,主要做了三件事:1 根据分库分表规则创建路由规则 2 初始化运行时上下文 3 获取数据源列表
重点是第一步 根据分库分表规则创建路由规则 对应的代码就是new ShardingRule(shardingRuleConfig, dataSourceMap.keySet())
public ShardingRule(final ShardingRuleConfiguration shardingRuleConfig, final Collection<String> dataSourceNames) {
Preconditions.checkArgument(null != shardingRuleConfig, "ShardingRuleConfig cannot be null.");
Preconditions.checkArgument(null != dataSourceNames && !dataSourceNames.isEmpty(), "Data sources cannot be empty.");
this.ruleConfiguration = shardingRuleConfig;
//获取所有的实际数据库
shardingDataSourceNames = new ShardingDataSourceNames(shardingRuleConfig, dataSourceNames);
//表路由规则
tableRules = createTableRules(shardingRuleConfig);
//获取广播表
broadcastTables = shardingRuleConfig.getBroadcastTables();
//绑定表
bindingTableRules = createBindingTableRules(shardingRuleConfig.getBindingTableGroups());
//创建默认的分库策略
defaultDatabaseShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultDatabaseShardingStrategyConfig());
//创建默认的分表策略
defaultTableShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultTableShardingStrategyConfig());
//分片键
defaultShardingKeyGenerator = createDefaultKeyGenerator(shardingRuleConfig.getDefaultKeyGeneratorConfig());
//主从规则
masterSlaveRules = createMasterSlaveRules(shardingRuleConfig.getMasterSlaveRuleConfigs());
//加密规则
encryptRule = createEncryptRule(shardingRuleConfig.getEncryptRuleConfig());
}
重点是表路由规则 tableRules = createTableRules(shardingRuleConfig); 这里面涉及到表的各种策略配置和主键生成策略的选择 也就是之前说SPI机制。
流程二:创建数据库连接
创建完数据源后,根据数据源创建数据库的连接 conn = dataSource.getConnection();
//runtimeContext 创建数据源时初始化的上下文对象
// TransactionTypeHolder.get()默认是 本地事务
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
private static final ThreadLocal<TransactionType> CONTEXT = ThreadLocal.withInitial(() -> TransactionType.LOCAL);
public static TransactionType get() {
return CONTEXT.get();
}
在创建数据源的时候已经根据配置的事务管理配置,加载对应事务管理器,创建连接的时候默认的事务类型就是本地事务
流程三:从数据库连接获取Statement对象
Statement statement = conn.createStatement();
@Override
public Statement createStatement() {
return new ShardingStatement(this);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {
super(Statement.class);
this.connection = connection;
statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection);
}
其中 statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection); 构造一个sql的执行器,同时该方法还会调用父类的构造方法
public AbstractStatementExecutor(final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability, final ShardingConnection shardingConnection) {
this.databaseType = shardingConnection.getRuntimeContext().getDatabaseType();
this.resultSetType = resultSetType;
this.resultSetConcurrency = resultSetConcurrency;
this.resultSetHoldability = resultSetHoldability;
this.connection = shardingConnection;
int maxConnectionsSizePerQuery = connection.getRuntimeContext().getProperties().<Integer>getValue(ConfigurationPropertyKey.MAX_CONNECTIONS_SIZE_PER_QUERY);
ExecutorEngine executorEngine = connection.getRuntimeContext().getExecutorEngine();
sqlExecutePrepareTemplate = new SQLExecutePrepareTemplate(maxConnectionsSizePerQuery);
sqlExecuteTemplate = new SQLExecuteTemplate(executorEngine, connection.isHoldTransaction());
}
基本上这一步为下一个执行流程 准备执行环境。
流程四:执行sql和结果归并
ResultSet result = statement.executeQuery(sql);
@Override
public ResultSet executeQuery(final String sql) throws SQLException {
if (Strings.isNullOrEmpty(sql)) {
throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);
}
ResultSet result;
try {
//这个上下文中包含了实际运行所需要的全部信息。包括真实数据源、真实SQL、真实参数
//执行引擎的准备阶段(包含sql解析、优化、路由、重写几个步骤)
executionContext = prepare(sql);
//执行引擎的执行阶段
List<QueryResult> queryResults = statementExecutor.executeQuery();
//结果归并阶段
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingResultSet(statementExecutor.getResultSets(), mergedResult, this, executionContext);
} finally {
currentResultSet = null;
}
currentResultSet = result;
return result;
}
一步步来分析。首先 executionContext = prepare(sql); sql的准备过程
//执行引擎的准备阶段:结果集分组-》获取连接(锁数据源)-》创建执行单元
private ExecutionContext prepare(final String sql) throws SQLException {
//清空和关闭执行需要的资源
statementExecutor.clear();
//重新获取运行时需要的环境
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
//将分片规则、属性配置、连接的数据库数据、sql解析引擎 封装成准备引擎
BasePrepareEngine prepareEngine = new SimpleQueryPrepareEngine(
runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getMetaData(), runtimeContext.getSqlParserEngine());
//通过准备引擎 解析路由,重写sql 创建执行单元
ExecutionContext result = prepareEngine.prepare(sql, Collections.emptyList());
//初始化执行引擎 存放真实sql和参数
statementExecutor.init(result);
statementExecutor.getStatements().forEach(this::replayMethodsInvocation);
return result;
}
sql执行阶段 List<QueryResult> queryResults = statementExecutor.executeQuery();
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
//定义sql执行回调方法
SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
//返回结果归并模式 有内存限制模式和连接限制模式
return getQueryResult(sql, statement, connectionMode);
}
};
return executeCallback(executeCallback);
}
//inputGroups中包含了所需执行的真实数据库以及真实SQL和参数。
@SuppressWarnings("unchecked")
protected final <T> List<T> executeCallback(final SQLExecuteCallback<T> executeCallback) throws SQLException {
//执行sql并触发回调方法
List<T> result = sqlExecuteTemplate.execute((Collection) inputGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;
}
public <T> List<T> execute(final Collection<InputGroup<? extends StatementExecuteUnit>> inputGroups,
final SQLExecuteCallback<T> firstCallback, final SQLExecuteCallback<T> callback) throws SQLException {
try {
//serial 串行还是并行,取决于连接模式
return executorEngine.execute((Collection) inputGroups, firstCallback, callback, serial);
} catch (final SQLException ex) {
ExecutorExceptionHandler.handleException(ex);
return Collections.emptyList();
}
}
重点是executorEngine.execute方法
public <I, O> List<O> execute(final Collection<InputGroup<I>> inputGroups,
final GroupedCallback<I, O> firstCallback, final GroupedCallback<I, O> callback, final boolean serial) throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
//根据serial 决定sql执行模式 连接限制模式:serialExecute(线性执行) 内存限制模式:parallelExecute(并行执行)
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}
那么serial 的值是怎么来决定的呢?在流程三的时候,会创建一个 sqlExecuteTemplate = new SQLExecuteTemplate(executorEngine, connection.isHoldTransaction());。那么connection.isHoldTransaction()的值就是serial 。
public boolean isHoldTransaction() {
//如果是本地事务,并且不是自动提交 返回true 或者 分布式事务并且正在事务中返回 true
return (TransactionType.LOCAL == transactionType && !getAutoCommit()) || (TransactionType.XA == transactionType && isInShardingTransaction());
}
不管是线性执行还是并行执行,sql执行完后触发回调函数,回调函数最终返回结果集的归并模式:内存限制模式选用流式归并,而连接限制模式选用内存归并。
结果归并
MergedResult mergedResult = mergeQuery(queryResults);
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
MergeEngine mergeEngine = new MergeEngine(runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getDatabaseType(), runtimeContext.getMetaData().getSchema());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
归并源码就不分析了,只要知道什么时候会采用流式归并,什么时候采用内存归并就好。















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









