







目录
概述:
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。本身也是一个数据库;
文档通过Http利用XML加到一个搜索集合中。
查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
优点:
- Solr有一个更大、更成熟的用户、开发和贡献者社区。
- 支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式。
- Solr比较成熟、稳定。
- 不考虑建索引的同时进行搜索,速度更快。
- 跨平台跨语言,可以通过REST 的 HTTP API确保任何编程语言可以使用
缺点:
- 建立索引时,搜索效率下降,实时索引搜索效率不高。
扩展:
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构,另外它不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装。
安装配置
下载地址
http://mirror.bit.edu.cn/apache/lucene/solr/
网盘资料下载
链接:https://pan.baidu.com/s/1Gk3itgTIz_ExhcKDlPLbRw
提取码:rz00
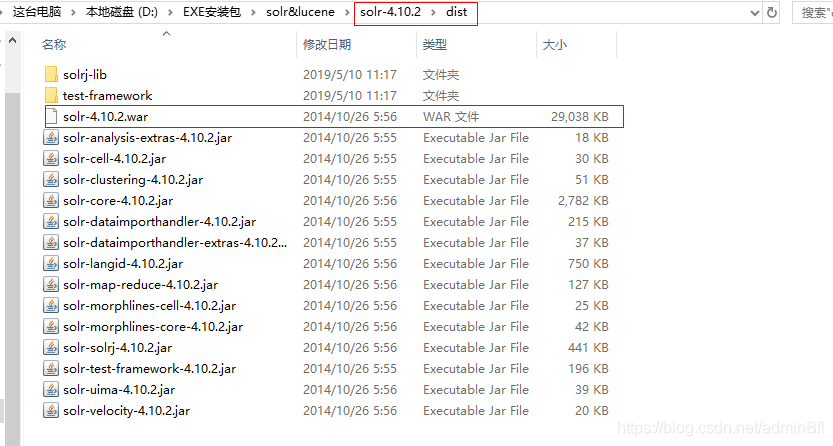
下载.zip解压后找到dist下的war包放在tomcat下的webapp目录下,更改.war名称方便访问

启动tomcat
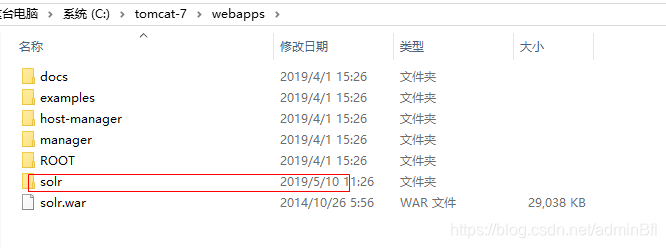
添加扩展包 将ext文件夹下的jar包放到WEB-INF下的lib文件夹下

配置solr的数据存放位置
将example目录下的solr目录拷贝到一个靠近根目录下并且更改目录名solrhome
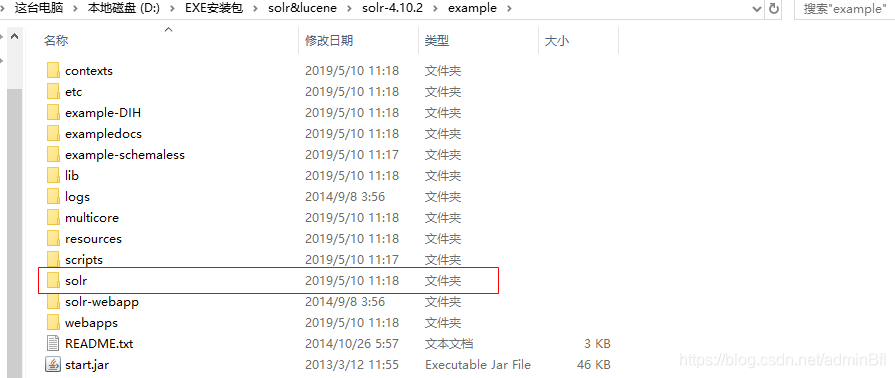
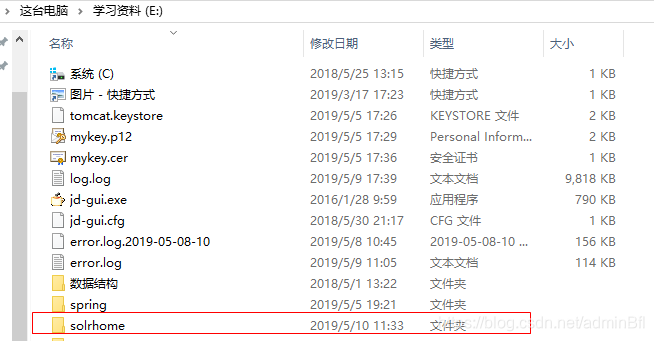
配置solrhome位置
打开WEB-INF 下web.xml

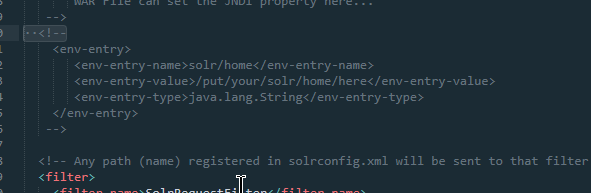
打开<env-entry> 注释改为刚刚复制后的地址
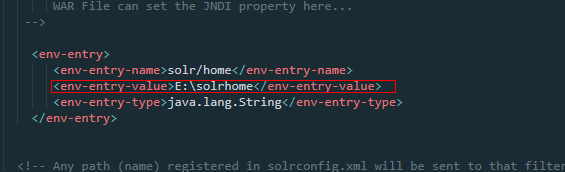
保存之后启动tomcat访问

选择数据库
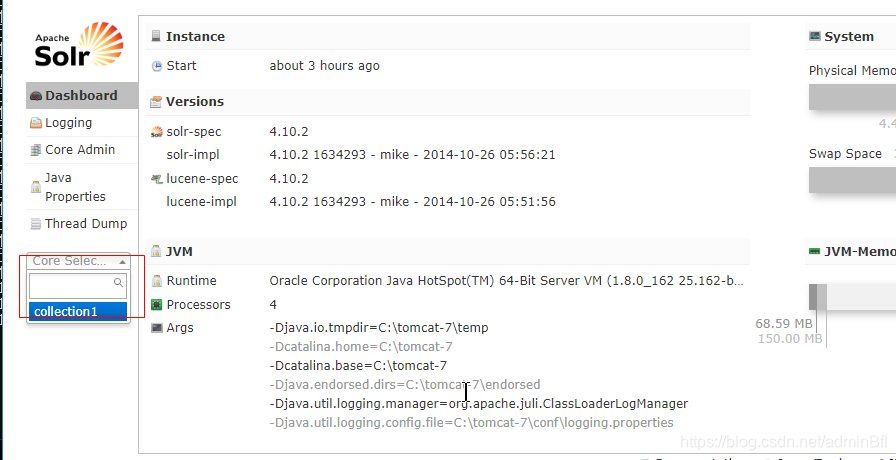
查询界面
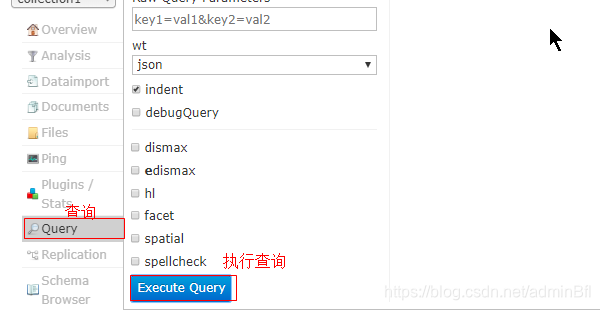
查询表达式 *:* 查询全部 第一个* 代表字段名称 第二个*代表要查询的条件值
IK Analyzer配置
solr中默认的配置不会对中文进行分词
默认配置每一个字一个分词

导入jar包复制拷贝

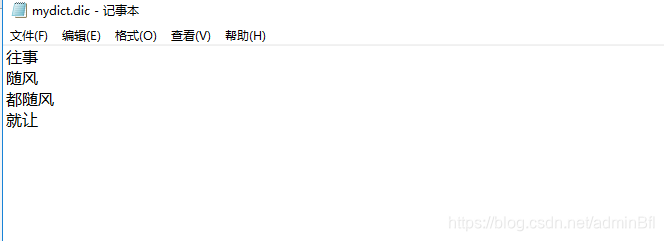
扩展词典拷贝文件如果没有,mydict.dic手动创建一个
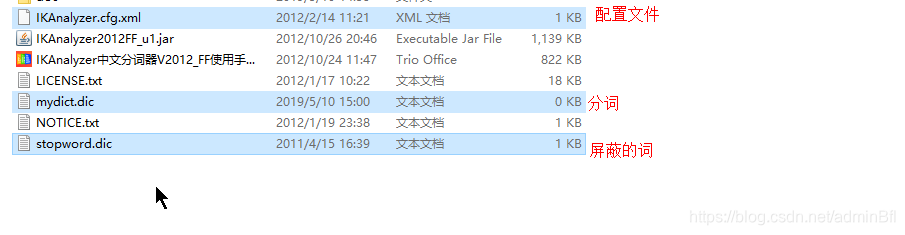
新建一个classes目录粘贴进去
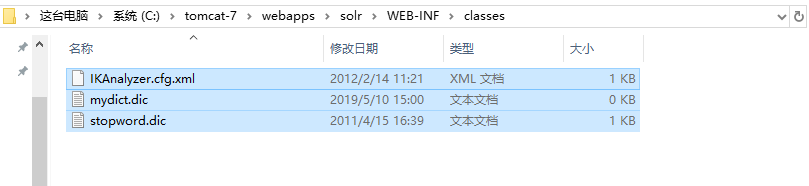
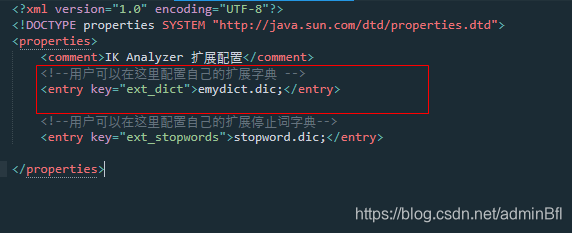
配置词典打开.xm配置文件打开注释将扩展的词典放进去
修改solrhome的schema.xml (这个文件很重要)
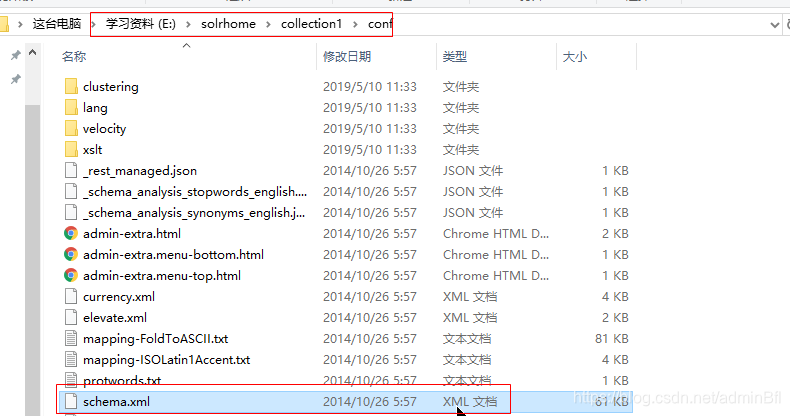
将这一段配置加进去
<!-- 自定义字段类型 name 自定义名称 class 基本类型 analyzer采用哪个分词器-->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>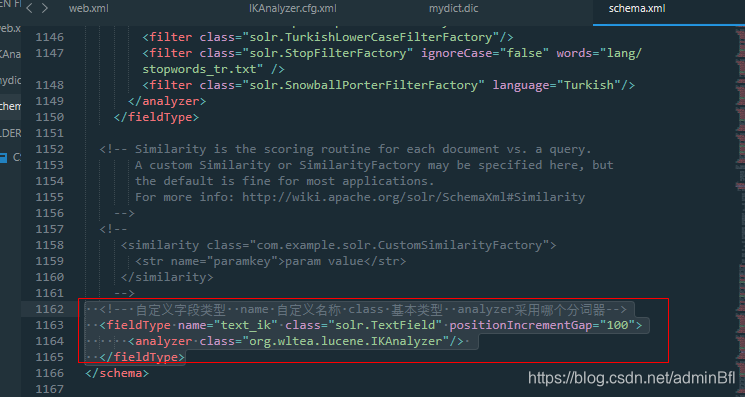
扩展分词mydict.dic自定义内容
重新启动
查看效果选择自定义的type类型,现在他走的就是自定义的词典

配置域:
域相当于数据库的表字段,用户存放数据,因此需要根据业务需要去定义相关的Field(域)
solrhome的schema.xml 文件
name:指定域的名称 type:指定域的类型 indexed: 是否索引 stored: 是否存储 required: 是否必须 multiValied: 是否多值
![]()
复制域
将某一个Filed中的数据复制到另一个域中
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true" />
<copyField source="item_category" dest="item_keywords"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_seller" dest="item_keywords"/>
<copyField source="item_brand" dest="item_keywords"/>
动态域
当需要动态扩充字段时,需要使用动态域
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true"/>
注意type属性类型首字母一般小写















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









