






neo4j-admin[1] 是neo4j官方出的海量数据入库的方法,看了现网的案例,都写的迷迷糊糊的,果断看英文官方文档,慢慢啃完之后,突然感觉受益匪浅。海量csv文件入库,为了降低存储,可以压缩,既可以pandas直接压缩,也可以zipfile压缩。压缩前242M,压缩后53M,存储效果明显变好。另外,海量csv文件入库,可以使用正则表达式,简化脚本。针对千万级数据测试发现,速度比load csv快将近10倍。
有head的csv文件
movies.csv 注意:
- :LABEL 节点才有标签,多标签使用“;”分号连接
- 节点必须有ID,因为边的csv需要节点ID
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequelactors.csv
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actorroles.csv 注意:
- :TYPE 边才有类型
- :START_ID和:END_ID是节点中的ID,因为边是由2个节点构成
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN第一步:导入csv文件
bin/neo4j-admin import --nodes=import/movies.csv --nodes=import/actors.csv --relationships=import/roles.csv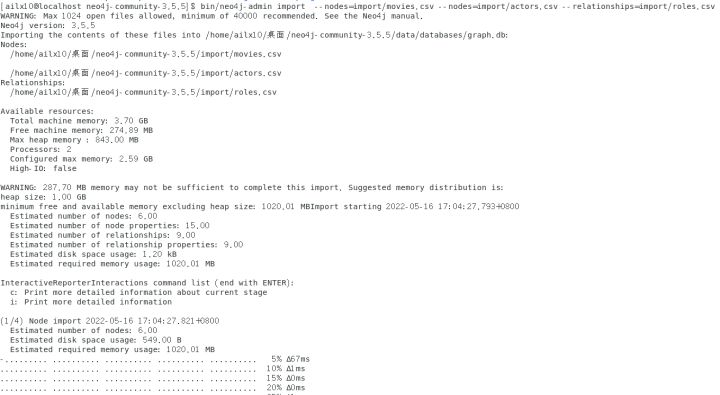
第二步:启动neo4j
bin/neo4j start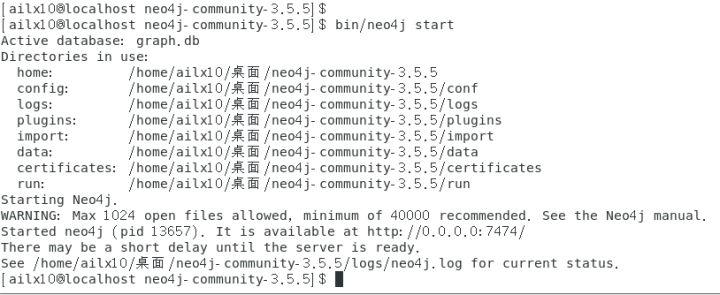
第三步:在浏览器中查看
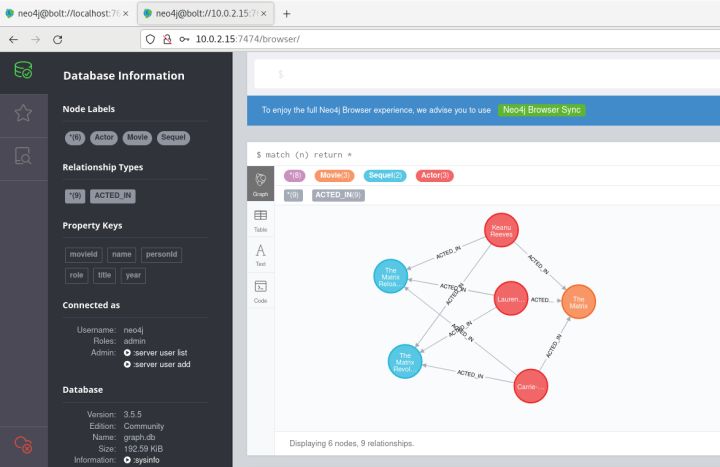
没有head的csv文件
- movies3-header.csv
movieId:ID,title,year:int,:LABEL- movies3.csv
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequelactors3-header.csv
personId:ID,name,:LABELactors3.csv
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actorroles3-header.csv
:START_ID,role,:END_ID,:TYPEroles3.csv
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN将文件头和内容分离之后,遍可以导入了。注意,这里同一标签的节点使用“,”逗号来连接,同一类型的边也是使用“,”逗号来连接。
bin/neo4j-admin import --nodes=import/movies3-header.csv,import/movies3.csv --nodes=import/actors3-header.csv,import/actors3.csv --relationships=import/roles3-header.csv,import/roles3.csv大量文件输入
如果有大量的文件输入,可以使用","逗号继续连接。
- --nodes=import/movies4-header.csv,import/movies4-part1.csv,import/movies4-part2.csv
- --nodes=import/actors4-header.csv,import/actors4-part1.csv,import/actors4-part2.csv
- --relationships=import/roles4-header.csv,import/roles4-part1.csv,import/roles4-part2.csv
bin/neo4j-admin import --nodes=import/movies4-header.csv,import/movies4-part1.csv,import/movies4-part2.csv --nodes=import/actors4-header.csv,import/actors4-part1.csv,import/actors4-part2.csv --relationships=import/roles4-header.csv,import/roles4-part1.csv,import/roles4-part2.csv输入正则简化
当有大量文件输入时,内容会很长,为了简化脚本,可以使用正则表达式,注意这里需要使用双引号包住全部内容,非常适合海量数据入库。需要特别特别注意(.*),之前光写一个*,就会出现正则错误。谨记!!!顺便在多一句嘴,neo4j 3.5 - neo4j 4.x 都支持正则呦 ,亲测有效,在语法层面上,后面的 -- skip --ignore 参数有点不一样 ~
- --nodes="import/movies4-header.csv,import/movies4-part.*"
- --nodes="import/actors4-header.csv,import/actors4-part.*"
- --relationships="import/roles4-header.csv,import/roles4-part.*"
bin/neo4j-admin import --nodes="import/movies4-header.csv,import/movies4-part.*" --nodes="import/actors4-header.csv,import/actors4-part.*" --relationships="import/roles4-header.csv,import/roles4-part.*"输入标签和类型简化
由于节点存在大量冗余的label,边存在大量冗余的type,为了简化csv,可以指定统一的标签和类型。
- --nodes=Movie=import/movies5a.csv (全是Movie标签)
- --nodes=Movie:Sequel=import/sequels5a.csv (全是Movie:Sequel标签)
- --nodes=Actor=import/actors5a.csv(全是Actor标签)
- --relationships=ACTED_IN=import/roles5a.csv(全是ACTED_IN类型)
bin/neo4j-admin import --nodes=Movie=import/movies5a.csv --nodes=Movie:Sequel=import/sequels5a.csv --nodes=Actor=import/actors5a.csv --relationships=ACTED_IN=import/roles5a.csvID空间
为了让不同的节点的ID字段不打架,可以使用ID空间有优化。
- movies7.csv(括号里面就是 Movie-ID,可以自由增长)
movieId:ID(Movie-ID),title,year:int,:LABEL
1,"The Matrix",1999,Movie
2,"The Matrix Reloaded",2003,Movie;Sequel
3,"The Matrix Revolutions",2003,Movie;Sequel- actors7.csv(括号里面就是 Actor-ID,可以自由增长)
personId:ID(Actor-ID),name,:LABEL
1,"Keanu Reeves",Actor
2,"Laurence Fishburne",Actor
3,"Carrie-Anne Moss",Actor- roles7.csv(直接依赖节点的ID空间)
:START_ID(Actor-ID),role,:END_ID(Movie-ID)
1,"Neo",1
1,"Neo",2
1,"Neo",3
2,"Morpheus",1
2,"Morpheus",2
2,"Morpheus",3
3,"Trinity",1
3,"Trinity",2
3,"Trinity",3跳过异常关系
使用 --skip-bad-relationships 跳过异常关系(备注:neo4j v4.0+)
bin/neo4j-admin import --skip-bad-relationships --nodes=import/movies8a.csv --nodes=import/actors8a.csv --relationships=import/roles8a.csv跳过相同ID的节点
使用 --skip-duplicate-nodes 跳过相同ID的节点(备注:neo4j v4.0+)
bin/neo4j-admin import --skip-duplicate-nodes --nodes=import/actors8b.csv

















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











