









研究音乐领域推荐算法的性别公平性
摘要:
尽管推荐系统(RSs)在我们的社会中起着至关重要的作用,但以前的研究表明,RSs的性能在具有不同特征或来自不同人口统计学的个人群体之间可能有很大的差异。在这种情况下,如果一个RS对不同的用户群体的表现不尽相同,那么它就被认为是不公平的。考虑到RSs在全球音乐内容的传播和消费中的重要性,在音乐RSs的背景下对公平性进行仔细评估是至关重要的。为此,我们首先介绍了LFM-2b,一个新的大规模真实世界的音乐收听记录数据集,包括一个子集,以研究RSs在用户人口统计学方面的偏见。然后,我们根据具有不同人口统计学特征的用户之间的RS的性能差距定义了一个公平性的概念,并在准确性和超越准确性的指标方面评估了各种协同过滤算法,以探索RS结果对特定性别群体的公平性。我们观察到,在男性和女性用户群体中,算法的表现存在着明显的差异(不公平)。基于这些差异,我们探讨了推荐算法在多大程度上导致了最终结果中潜在的人口偏见的加剧。我们还研究了重新取样策略的效果,该策略通常被用作去偏移方法,在保持算法的准确性和超越准确性的性能的同时,对各种算法的公平性测量产生了轻微的改善。
关键词: 推荐系统、音乐、偏见、神经网络、人口统计信息
1 引言
推荐系统(RS)通过参与各种日常决策,影响我们在数字平台上接触到的内容,在我们的生活中发挥着无可争议的作用。这些决定包括选择购买一本书,观看一部电影,预订一家酒店,或听一首歌。虽然RS在访问本来几乎无法管理的数据量方面提供了巨大的支持,但一些研究显示,它们的表现可能因用户群体的特征不同而有所不同 (如性别、种族、民族、年龄、原籍国或个性Datta, Tschantz, & Datta, 2015; Lambrecht & Tucker, 2019; Melchiorre, Zangerle, & Schedl, 2020; Schedl, Hauger, Farrahi and Tkalcic, 2015)。其中一些表现差异会使某些用户群体在获得机会方面处于不利地位,因此无视公平原则,即“不因个人或群体的内在或后天特征而对其有任何偏见或偏袒”(Mehrabi, Morstatter, Saxena, Lerman, & Galstyan, 2019)。在这篇文章中,我们着手从RSs用户的角度来研究群体公平性。
RS中这种形式的不公平可以追溯到数据、模型/算法和用户之间的(相互作用)导致的偏见 (Chen, Dong, Wang, Feng, Wang, & He, 2020)。在这里,我们关注的是关于各种人口统计学的数据点数量不平衡导致的偏见。这些不平衡可以被归类为人口偏见 (Olteanu, Castillo, Diaz, & Kiciman, 2019),它是更普遍的数据偏见的一部分 (Baeza-Yates, 2018)。在存在人口偏见的情况下,机器学习模型(如由RS算法创建的模型)会更突出地捕捉到多数群体的互动模式,这可能会导致多数群体的模型性能比少数群体的更好(一个不公平的系统)(Hardt, Price, Price, & Srebro, 2016)。我们把这种不公平的原因称为模型/算法偏见。显然,数据是造成模型偏见的主要原因,但不同的模型仍然会导致不同程度的不公平,甚至会加剧数据偏见。正如之前在文本分类 (De-Arteaga et al., 2019) 和段落检索 (Rekabsaz & Schedl, 2020) 背景下的研究所示,一个机器学习模型甚至会使收集到的差异变得更加复杂,从而使模型的结果分布与基础数据中存在的差异相比更加不公平。这种现象被称为复合不平衡 (De-Arteaga et al., 2019; Hellman, 2018)。在这种情况下,该系统不仅对少数群体不公平,甚至加剧了现有的不平衡。
1.1 研究问题
在目前的工作中,我们在RS研究的一个重要领域——音乐推荐中 (Schedl, Knees, McFee, Bogdanov and Kaminskas, 2015),全面研究了在性别不公平背景下的人口和模型偏见。具体来说,我们探索了以下研究问题:RQ1:不同类别的推荐算法在不同性别的用户群体中是否产生了不同的性能分数(在准确性和超准确性指标方面)?如果是这样,如何描述这些差异? RQ2:重采样策略,通常用作去偏方法,对算法的性能和公平性有什么影响? RQ3:RS算法混合了人口偏见吗?如果是这样,应该如何描述这种特点?
这些问题只能通过包含用户性别信息的音乐推荐数据集来解决。现有的这类(公开的)数据集完全由音乐流媒体平台Last.fm的数据组成,包括Last.fm 1K (Celma, 2010)、LFM-1b (Schedl, 2016) 和Music Listening Histories Dataset(MLHD)(Vigliensoni & Fujinaga, 2017)。它们中的大多数要么很小 (Celma, 2010),要么不包含最新的收听信息 (Schedl, 2016; Vigliensoni & Fujinaga, 2017)。因此,作为额外的贡献,我们引入了LFM-2b数据集,这是一个最新的大规模现实世界的音乐收听记录集合,从Last.fm收集,它大大扩展了LFM-1b。与现有的数据集不同,LFM-2b提供了超过12万用户的20亿条收听记录,这些用户总共收听了超过5000万首独特的曲目。与LFM-1b的另一个显著区别是收听记录的大时间覆盖(2005-2020年),这使得我们可以在相当长的时间内跟踪用户的收听行为。LFM-2b包含一个专门的子集,LFM-2b-DemoBias,我们特别开发了这个子集来研究和评估音乐RS在用户的性别、年龄和原籍国方面的公平性和偏见。由于这些特点,以及与LFM-1b相比,每个用户收听记录的平均数量更多(表1,LFM-1b、LFM-2b和LFM-2b/1b𝑑𝑖𝑓𝑓),LFM-2b-DemoBias很适合于处理所调查的研究问题。所有的数据都是公开的。
为了解决RQ1,我们研究了各种RS算法上与性别有关的不公平性。使用LFM-2b-DemoBias,我们对算法进行训练,并对测试集中的男性和女性用户子集分别计算评价指标,使用基于准确性(召回率和NDCG)以及超越准确性的指标(多样性和覆盖率)。我们将RS算法在评价指标方面的不公平性定义为敏感属性对(在我们的实验中为性别)之间的平均评价分数的平均绝对差异,这一公平性概念与Hardt等人(2016)的机会平等指标密切相关。
为了解决RQ2,我们通过考虑一种去偏方法重复上述实验,其中——继 Geyik、Ambler 和 Kenthapadi(2019)之后——训练数据中少数群体(女性)的数据点被重新采样,直到多数群体(男性)的数据点数量。
为了回答RQ3,我们将De-Arteaga等人(2019)在真-正(TP)指标上引入的复合失衡的概念扩展到任何任意指标,并将其称为复合因子。关于模型和评价指标的复合因子被定义为指标结果在用户组中的分布与数据集中人口分布的差异。较高的复合因子表明,该模型加剧了数据中对多数群体的现有偏见。
1.2 主要贡献
目前工作的主要贡献可以概括为以下几点。
- 我们引入了一个大规模的真实世界音乐收听记录数据集,可以用来研究音乐RS的公平性和偏见。
- 我们通过使用具体的公平性度量,指出哪些是能更稳健地处理真实世界数据中存在的性别偏见的推荐算法。
- 我们确定了推荐算法在多大程度上复合了人口偏见,以及数据去偏方法如何缓解这一问题。
1.3 文章结构
在本文的其余部分,我们介绍了相关文献和数据集(第2节),描述了我们创建的LFM-2b和LFM-2b-DemoBias数据集,并与本文一起发布(第3节)。然后,我们介绍并制定了我们的公平性和复合因子的概念(第4节)。随后,我们通过描述数据处理、介绍所考虑的算法和讨论实验程序,概述了实验设置(第5节)。最后,我们讨论了调查的结果(第6节),并提出了所提交工作的结论和局限性,以及在研究音乐RSs的人口统计学偏见方面的未来研究方向(第7节)。
2 相关工作
相关文献可分为RSs算法(第2.1节),RSs背景下的偏见、公平和去偏的研究(第2.2节),以及现有的音乐推荐数据集(第2.3节)。
2.1 推荐系统算法
RSs是将用户与物品相匹配的系统,以最大化某些指标(或指标组合)。在音乐推荐的案例中 (Schedl, Knees et al., 2015),用户通常是使用某种推荐服务的人,推荐的项目通常是曲目/唱片或艺术家。这类RS的目标是向用户提供满意的曲目或艺术家推荐。RS算法所利用的基础数据通常包括一个用户与项目的交互矩阵,其中一个单元格的值表示用户的评分或播放次数(即用户听该曲目的频率),有时还辅以用户的侧面信息(如年龄或性别)或项目(如音频特征、编辑和用户生成的元数据,如流派、艺术家传记或平台用户贡献的标签等),以及背景信息(如时间戳或位置)。
RS中最广泛采用的策略是协同过滤(CF) (Aggarwal, 2016b; Koren & Bell, 2015) 和基于内容的过滤(CBF)(Deldjoo, Schedl, Cremonesi, & Pasi, 2020; Lops, de Gemmis, & Semeraro, 2011),以及它们的组合(混合推荐系统)(Aggarwal, 2016a; Beliakov, Calvo, & James, 2011),有时将上下文信息整合到上下文感知推荐系统(CARS)中 (Adomavicius, Mobasher, Ricci, & Tuzhilin, 2011)。
纯粹的CF方法只利用用户与物品互动的历史数据来预测活跃用户对未知物品的偏好程度,并向他们推荐预测分数最高的物品 (Aggarwal, 2016b; Koren & Bell, 2015)。CF系统可以进一步分为基于记忆和基于模型。前者直接在用户-项目互动矩阵的高维向量上计算用户(或项目)之间的相似性,以识别最近的邻居(例如,音乐品味与活跃用户最相似的用户);后者从用户-项目互动中学习一个模型,用来实现预测或推荐。通常使用的是潜在因素模型,它可以被视为用户-项目互动空间的低维嵌入。这可以通过例如矩阵分解来实现。 然后在这个潜在因素空间而不是在原始空间中计算用户和项目之间的相似性。
相比之下,CBF 系统利用活动用户已经与之交互的项目的内容描述符来识别与用户喜欢的项目相似的项目 (Deldjoo et al., 2020; Lops et al., 2011)。在音乐领域,这种内容描述符可能包括节奏、韵律模式或流派信息。因此,除了内容信息外,CBF系统只需要活动用户的交互数据(而非其他用户的数据)来进行推荐。
CARS 利用上下文信息(例如用户的时间、位置或活动)来构建推荐模型,该模型在进行推荐时会考虑活跃用户的当前情况 (Adomavicius et al., 2011)。CARS最常扩展CF或CBF方法。
混合RSs使用融合或聚合方法将至少两种单独的方法结合起来 (Burke, 2002; Çano & Morisio, 2017)。最近大多数基于深度学习的音乐推荐方法都属于这一类,并利用共听信息(CF)以及内容特征(CBF),如Huang等人(2020)、Oramas等人(2017)以及van den Oord等人(2013)。
在手头的研究中,出于几个原因,我们将研究重点放在CF算法上。首先,它们比CBF被更广泛地采用。其次,它们通常比CBF系统产生更好的性能,因此被用于(或作为其一部分)几乎所有最先进的系统。第三,研究混合系统反而会导致难以将源自协作信息的不公平方面与源自内容信息的不公平方面分开。第四,CF系统的输出对数据偏见特别敏感,例如,Melchiorre等人(2020)针对用户不同性格特征导致的交互数据差异的研究,Lambrecht和Tucker(2019)研究招聘广告中的性别差异,Bauer和Schedl(2019)显示了用户听主流音乐的倾向差异,以及 Abdollahpouri、Mansoury、Burke和Mobasher (2019) 以及Kowald、Schedl 和 Lex (2020) 研究音乐和电影领域中不同项目受欢迎程度导致的差异。
2.2 调查和减轻推荐系统的偏见
RSs中公平性和偏见是最近许多研究的重点 (Lin, Sonboli, Mobasher, & Burke, 2019a; Mansoury, Abdollahpouri, Pechenizkiy, Mobasher, & Burke, 2020a; Mansoury, Mobasher, Burke, & Pechenizkiy, 2019)。公平的概念要求系统在推荐质量方面不歧视群体或个人。
- 评估偏见和公平
各种研究从不同利益相关者(即RS用户、物品/项目提供者或全部)的角度探讨RS中的公平性,称为多边公平。目前的工作主要是从用户群体的角度来研究公平和偏见,这些用户群体是由共同的性别定义的。
公平性在各个领域都得到了调查。例如,在工作推荐方面,研究发现,无论是Lambrecht和Tucker(2019)在Facebook上还是Datta等人(2015)在Google上都向男性推荐高薪工作。Lambrecht和Tucker认为广告算法的成本最小化策略是其原因。更准确地说,平台所有者向用户展示招聘广告是要收费,而不同的人口目标群体成本是不同的。由于年轻女性属于一个特别昂贵的群体,因此本应与性别无关的高薪广告实际上更频繁地通过采用成本最小化策略的算法呈现给男性用户,因为后者是“成本较低”的群体。在图书领域,Ekstrand、Tian、Imran、Mehrpouyan和Kluver (2018)调查了图书作者在用户资料和推荐列表中的性别分布差异。他们发现,特别是CF算法通常会产生偏向男性作者的推荐结果。在电影领域,Lin、Sonboli、Mobasher和Burke (2019b)研究了不同的推荐系统算法如何放大或抑制男性和女性用户对特定项目类别(例如,动作与浪漫)的偏好。例如,他们表明,基于邻域的模型增强了所有用户对主导群体(男性)的首选项目类别的偏好,而其他一些算法,如SVD++和BiasedMF,则抑制了这些偏好。同样,Mansoury、Abdollahpouri、Pechenizkiy、Mobasher和Burke (2020b) 评估了推荐系统中由于反馈循环而导致的流行偏见的放大,例如,推荐热门商品使热门商品更受欢迎,表明少数群体(即女性)的偏见放大更强。Mansoury等人(2019)也研究了不同的推荐系统算法在多大程度上反映了用户群体对输入物品类别的偏好,他们采用的方法与Lin等人(2019b)类似。在音乐领域,这也是我们研究的目标领域,推荐系统中的偏见 (Ekstrand, Tian, Azpiazu et al., 2018; Melchiorre et al., 2020; Schedl, Hauger et al., 2015; Shakespeare, Porcaro, Gómez, & Castillo, 2020) 和音乐流媒体以及广播服务中的性别表征 (Epps-Darling, Bouyer, & Cramer, 2020; Watson, 2020) 最近被调查。特别是Schedl、Hauger等人(2015)表明,通过简单的CF和CARS算法获得的准确率和召回率对于不同性别、年龄和国家的用户存在显着差异。Melchiorre等人(2020)表明,最先进的CF算法针对不同用户群体的人格特征产生不同的性能得分(召回率和NDCG),特别是对于具有高与低开放性和神经质的用户。Ekstrand、Tian、Azpiazu等人(2018)揭示了简单CF算法在音乐和电影领域的性能差异(相对NDCG指标),导致了年龄和性别方面的不公平。他们还发现,偏见不一定与用户群体大小相关。
在与推荐相关的各种任务中,算法造成的不公平和偏见被研究,事实上,文献中已经提出了公平意识的推荐算法 (Steck, 2018; Yao & Huang, 2017)。Rekabsaz和Schedl(2020)表明,与经典的精确匹配模型相比,基于神经网络的排名模型增加了检索结果中对男性的性别偏见。在分析算法偏见的方向上,De-Arteaga等人(2019)讨论了复合不平衡,这是一个与政治哲学中复合不公正有关的概念 (Hellman, 2018),并表明如果分类器对少数群体的敏感度(即真阳性率(TPR))低于大多数群体,那么最终TPR中群体之间的不平衡就会变得比基础数据集的初始不平衡更大。在这种情况下,模型(分类器)加剧了数据集中现有的不平衡现象。
除了公平之外,最近的工作还揭示了RS中涉及的各种类型的偏见。例如,最近的研究揭示了当前推荐算法中的流行偏见。特别是,研究表明,用户被推荐的项目不符合他们对某种流行程度的偏好(小众歌曲/艺术家的价值被低估)(Abdollahpouri et al., 2019; Kowald et al., 2020)。
- 消除偏见并提高公平
适用于RS的最先进的去偏方法通常分为四种方法(Chen et al., 2020):(1)重新平衡,(2)正则化,(3)反事实干预,以及(4)对抗性训练。在第一类中,数据或推荐结果被重新平衡,以满足某种公平性措施(例如,人口均等)。在这样的方法中,去偏作为预处理或后处理步骤进行。常见的预处理方法是:重新标记训练数据,以实现各组之间相关标签数量相等 (Pedreshi et al., 2008),或重新取样数据,以获得相等数量的训练数据 (Geyik et al., 2019)。后处理方法通常旨在改变RS的输出列表,使每个建议的结果或结果的期望值满足目标公平性措施 (Biega et al., 2018; Zehlike et al., 2017)。
在第二类中,去偏是通过在训练期间引导推荐模型的优化过程来完成的,其中包括一个公平性的正则化项。Zemel、Wu、Swersky、Pitassi和Dwork(2013)提出了一个通用框架,旨在学习包含足够信息用于手头任务但在敏感属性方面保持不变的表示。Kamishima等人在RS的背景下采用了这个框架,后来将其推广到基于隐性反馈的推荐系统 (Kamishima & Akaho, 2017; Kamishima, Akaho, Asoh, & Sakuma, 2012)。基于正则化的方法也在RS中的偏见背景下进行了研究,例如 Abdollahpouri、Burke和Mobasher (2017)以解决流行度偏见。
关于第三类,Kusner、Loftus、Russell和Silva(2017)将反事实的公平性引入RSs。在这种方法中,当个人在反事实世界中的评价——个人的敏感属性因干预而改变——和在现实世界中的评价相同时,就满足了公平性标准。
最后,通过对抗性学习去偏的类别通过最小-最大博弈创建无偏表示来接近该主题,这与敏感属性无关(Bose & Hamilton, 2019)。在这个方向上,最近,Beigi等人(2020)提出了一种对抗性训练方法,该方法旨在保护用户的敏感属性不被能够访问用户的项目列表和建议的攻击者发现。
在当前的研究中,我们研究了第一类方法中的一种方法,即再平衡。特别是,我们研究了在RS算法的训练数据上使用再平衡技术来实现统计上的均等。为此,我们对训练数据中少数群体(女性)用户的数据点进行重新取样,以实现与多数群体(男性)用户的数量相等。
2.3 音乐推荐实验数据集
研究(音乐)推荐算法,使所获得的见解能够推广到现实世界的应用中,需要获得包含在野外获得的数据的合适数据集。尽管在过去的十年中,已经公开发布了许多用于研究音乐RS的语料库,但其中大多数——与提议的LFM-2b数据集不同——并不包括用户的人口统计信息。对于包含Spotify、Yahoo!、Echo Nest或Art of the Mix数据的语料库来说,这种忽略用户人口统计信息的情况尤为明显。
然而,为了研究一般的音乐RS中的偏见,特别是所谓的人口偏见,用户的人口统计信息变得至关重要。我们在此研究的人口偏见,是一种包含在数据本身的偏见,它是由特定人口对目标人口的扭曲而产生的。这是典型的,例如社交媒体,因为一些平台更经常被一个特定的群体使用,例如Pinterest上的女性,而另一些则是另一个群体,例如Twitter上的男性。从文献中已经介绍的公开可用的数据集来看,包含此类信息的数据集有 (1) 从音乐平台Last.fm收集的数据集,即Last.fm 360K和Last.fm 1K,LFM-1b,以及Music Listening Histories Dataset(MLHD),其中包括用户在注册时收集的性别、国家和年龄;(2) 从其他社交媒体网站(如Twitter)上分享的数据创建的数据集,其中包含通过MusicBrainz等开放音乐百科全书映射到音乐元数据的音乐相关标签,即MusicMicro, Million Musical Tweets Dataset (MMTD) , 和#nowplaying-RS。然而,没有一个包含人口统计信息的数据集是事先考虑到人口偏见的评估而开发的,这影响了其进行偏见相关研究的真正清晰理解:考虑到缺乏人口统计信息的用户在这样的研究中会被抛弃,这些数据集对于评估音乐RS的偏见的实际价值是未知的。此外,尽管在线音乐平台和社交媒体的使用——即在这种情况下检索用户人口信息的主要来源——在过去几年里特别多,但这种类型的最新数据集最近没有出现。因此,我们引入了LFM-2b数据集,这是一个最新的大规模语料库,包含了过去15年(从2005到2020)收集的Last.fm用户的收听历史。除此之外,还介绍了LFM-2b-DemoBias,即前者人口统计学的一个子集,专门用于评估音乐RS的人口偏见。
3 LFM-2b 数据集
在本节中,将介绍LFM-2b和LFM-2b-DemoBias数据集。下文将讨论诸如数据采集程序、可及性以及每个数据集的主要特征等方面。
3.1 数据采集和可访问性
LFM-2b(illion)数据集是一个大型的音乐收听事件(LEs)集合,即用户与音乐在线平台Last.fm的互动,丰富了用户的人口统计信息(即用户的年龄、国家和性别)、音乐相关的元数据(如艺术家和曲目名称)和时间戳(特定用户收听特定曲目的具体时间)。按照获取LFM-1b数据集的方法 (Schedl, 2016),LFM-2b是使用Last.fm API从网络流媒体服务Last.fm收集的。LFM-2b(包括超过20亿个LEs)是前者的延伸,包含同样的120,322个用户,但收听历史延长了15年:从2005年2月14日到2020年3月20日;总共产生了2014,164,872个LEs。
为了使我们的结果具有可重复性,并促进对音乐推荐领域的偏见和公平性的进一步实验,LFM-2b数据集是以UTF-8编码的表格数据的形式存储的。LEs被编码在一个独特的文件中,每一行包含一个LE,每一列包含用户的人口统计信息、音乐元数据和时间戳。用户的人口统计是:用户ID(每个用户都是唯一的)、性别信息(女性或男性)、国家和年龄。音乐属性是:曲目ID(每个曲目都是唯一的)和曲目标识符(曲目和艺术家名字的组合)。请注意,我们用曲目指的是由特定艺术家制作的每个独特的音乐项目。此外,用户-曲目-播放次数矩阵(UTM)和用户-艺术家-播放次数矩阵(UAM),即分别包含独特的用户-曲目和用户-艺术家之间互动的两个二维矩阵,也以Python NumPy格式提供稀疏矩阵。
3.2 从LFM-1b到LFM-2b
表1显示了LFM-1b、LFM-2b、LFM-2b\1b𝑑𝑖𝑓𝑓(LFM-1b和LFM-2b之间的集合差异)和LFM-2b-DemoBias(人口学偏见子集)的描述性统计数据。对于每个数据集,报告了用户、曲目、艺术家和收听事件(LEs)的数量,以及在每个用户的曲目(唯一)、每个用户的艺术家(唯一)和每个用户的总LEs(分别见曲目/用户、艺术家/用户和LEs/用户)方面用户互动的平均值和标准偏见。
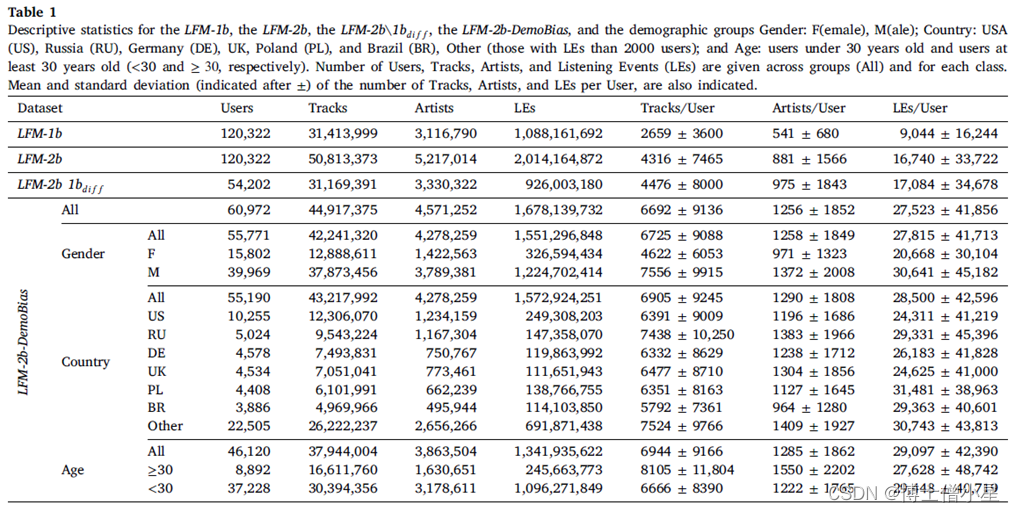
虽然LFM-1b与LFM-2b数据集收集的收听历史长度只有6年的差别,但后者所代表的收听曲目和艺术家的范围要大得多。LFM-1b与LFM-2b相比,后者的曲目和艺术家范围要大得多:31,413,999对50,813,373,3,116,790对5,217,014(分别见表1的曲目和艺术家)。同样,LFM-2b包含的LEs数量大约是LFM-1b的两倍:1,088,161,692对2,014,164,872(见表1中LEs)。当评估LFM-1b和LFM-2b之间的集合差异时,即。在评估LFM-1b和LFM-2b之间的差异时,即LFM-2b仅在过去6年中收集的LEs(见LFM-2b\1b𝑑𝑖𝑓𝑓),我们发现LFM-2b\1b𝑑𝑖𝑓𝑓的LEs数量与LFM-1b(收集于9年)相当,这表明用户在过去6年中在平台上的音乐消费有所增加:1,088,161,692对926,003,180,分别为LFM-1b对LFM-2b\1b𝑑𝑖𝑓𝑓(见表1的LEs)。这与近年来社交媒体使用量的普遍提高相吻合,这强调了在评估用户的音乐消费时使用最新数据集的重要性。
通过计算每种类型的互动变异系数(CV𝑑𝑖𝑓𝑓)的差异,即标准差与平均值之比的差异(LFM-1b对LFM-2b\1b𝑑𝑖𝑓𝑓),显示出用户消费习惯的变异性普遍增加。最小的增量出现在LEs方面的互动(见表1中LFM-1b与LFM-2b\1b𝑑𝑖𝑓𝑓的LEs/User),产生CV𝑑𝑖𝑓𝑓=20%。艺术家方面的交互作用增量最大(见表1中LFM-1b与LFM-2b\1b𝑑𝑖𝑓𝑓的Artists/User),得出CV𝑑𝑖𝑓𝑓=70%。曲目方面的相互作用(见表1中LFM-1b与LFM-2b\1b𝑑𝑖𝑓𝑓的Tracks/User),产生CV𝑑𝑖𝑓𝑓=50%。总的来说,这表明在过去6年中,用户的收听行为发生了变化,特别是关于艺术家的可变性,这意味着许多用户大幅增加了他们收听的艺术家的数量。通过比较每个系列的Artists/User互动的变异系数(CV)也可以证明这一点。在LFM-2b\1b𝑑𝑖𝑓𝑓对LFM-1b,Artists/User的CV=190%,而CV=120%。不同的是,平台内的互动量在不同的用户之间保持了更大的稳定性。在LFM-2b\1b𝑑𝑖𝑓𝑓与LFM-1b相比,LEs/User的CV=200%,而CV=180%。正如在野外收集的数据所预期的那样,LFM-1b和LFM-2b\1b𝑑𝑖𝑓𝑓在用户的消费行为中显示出巨大的差异,也就是说,一些用户的互动次数比其他用户少得多。然而,LFM-2b\1b𝑑𝑖𝑓𝑓表明,这种用户间的差异在艺术家方面变得更加突出,这表明用户对音乐多样性的兴趣增加。总而言之,LFM-2b是LFM-1b和LFM-2b/1b 𝑑𝑖𝑓𝑓的结合,与LFM-1b相比,每个用户呈现的LEs数量要高得多。此外,它是最新的,也显示了更多的艺术家种类;因此,特别适合于评估一般的音乐推荐系统的性能,特别是研究它们的偏见。
3.3 LFM-2b-DemoBias: 一个研究公平性的集合
为了研究音乐RS中的数据和算法/模型偏见,在LFM-2b数据集的基础上,我们引入了LFM-2b-DemoBias(人口统计学偏见)子集,它包含了在年龄、性别和国家方面具有有效人口统计学信息的用户的音乐LEs。由于可能会针对性别、年龄和国家/地区独立调查偏见,因此我们有意在LFM-2b-DemoBias中考虑至少具有一种人口统计属性的用户,而不是全部三种。请注意,所有的过滤集合,即几个人口统计学属性之间交集的子集(例如,具有有效性别和年龄信息的用户的LE)以及播放量矩阵,都可以直接从LFM-2b中推断出来。
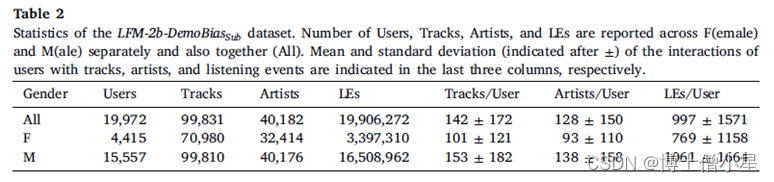
LFM-2b-DemoBias共包括60,972个用户(见表1中LFM-2b-DemoBias的全部),其中55,771个用户提供了性别信息(见表1中性别的全部),55,190个国家信息(见表1中国家的全部),以及46,120个年龄信息(见表1中年龄的全部)。在每个人口统计学组内,即性别、国家和年龄,样本之间的用户分布是不平衡的:例如,15802名女性对39969名男性(见表1中用户的F和M);10255名用户来自美国,即排名第一的国家与其他国家相比,其用户数量超过两倍。(表1中的用户见美国);37228个30岁以下的用户与8892个30岁以上的用户(表1中的用户见<30和≥30)。正如预期的那样,在评估曲目和艺术家层面的收藏时,也显示了类似的情况(见表1中曲目和艺术家的性别、国家和年龄组内的样本差异)。事实上,我们观察到各国在收听的独特艺术家方面有很大的差异:尽管在用户数量上有差异,但美国和俄罗斯都显示出很高的独特艺术家数量(见表1中美国和俄罗斯的艺术家数量为1,234,159和1,167,304);德国、英国和波兰——尽管在用户数量上相似——显示出相当低的多样性(表1中艺术家为750,767、773,461和662,239)。这种不平衡的分布,是在野外收集的数据集的特点,表明LFM-2b的人口偏向,其中男性、美国和年轻听众代表了用户的主要群体。换句话说,LFM-2b-DemoBias的人群与现实世界的人群相比是扭曲的,而现实世界的人群并不包含这种偏见。LFM-2b-DemoBias中显示的人口偏见使这个集合特别适合于研究模型/算法的偏见,因为它能够评估一个给定的推荐算法在多大程度上可能创建一个反映、放大或减轻这种数据偏见的模型。
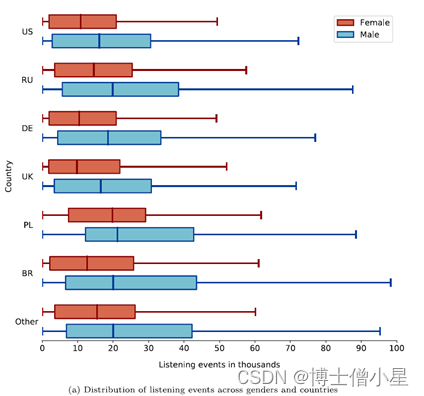
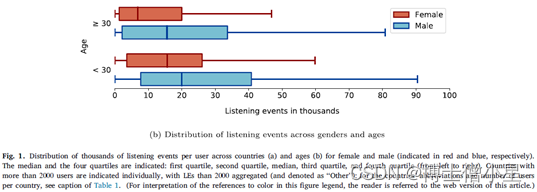
由于目前研究的目的是调查性别公平性,我们进一步检查LFM-2b-DemoBias中的性别属性与其他两个人口统计学属性,即国家和年龄的互动。因此,在图1中,显示了含有至少两个人口统计学属性,即性别和国家(见图1a),或性别和年龄(见图1b),信息的用户之间收听事件的分布。尽管美国是拥有更多用户的国家,但他们在平台内的互动普遍低于其他拥有大量用户的国家,如波兰。这一点在男性用户中尤为明显:美国用户的中位数最低(16,108),波兰用户的中位数最高(21,223)。这种来自波兰用户的较高消费在女性中也有明显体现,其中位数(19813)不仅几乎和男性用户一样高,而且和所有其他用户少于2000人的国家(即其他国家)的中位数一样高,并超过了包括美国在内的许多国家的男性用户的中位数;关于年龄,在两个显示的年龄组,即30岁以上和30岁以下,可以观察到女性和男性之间类似的趋势:对于女性和男性,每个组中只有四分之一的用户(30岁以下和30岁以上)产生了超过一半的LE:见图1中每个性别和组的第四四分位数。这种倾斜的分布在LFM-1b数据集中已经显示出来了,它也清楚地显示在国家的人口信息中。
4 衡量推荐中的用户群体公平性
在本节中,我们定义并阐明了量化RS的公平性/偏见以及复合因子的方法。我们首先解释 RecGap,这是一种从用户群体角度来衡量RS的不公平性的指标(第4.1节)。提出的RecGap度量与De-Arteaga等人(2019)介绍的Gap度量密切相关,同时将Gap扩展到任何任意的评价度量,使其适用于RS。然后,我们描述了RSs中复合不平衡的概念,并提出了一个捕捉这一概念的度量(第4.2节)。这项工作中讨论的度量是针对敏感属性的任意数量的用户组(非二元设置)制定的。度量是为用户组集合𝐺定义的,在敏感属性性别的二进制设置的情况下,它等于𝐺={𝑓𝑒𝑚𝑎𝑙,𝑚𝑎𝑙𝑒}。
4.1 RecGap: 推荐的不公平度量
我们关于RS公平性的概念与Hardt等人(2016)的机会均等度量密切相关。我们认为,如果根据任何任意的评价指标,一个RS在各组用户中的表现同样好,那么它就是公平的。为了衡量一个推荐算法的公平性,首先训练一个RS模型——在算法需要训练的情况下——然后对测试集中的每一组用户分别评估其推荐预测。RS模型关于给定评价指标的公平性被定义为每对组中平均评价分数(在所有用户中)的平均绝对差异。我们把这个指标称为RecGap,公式如下:
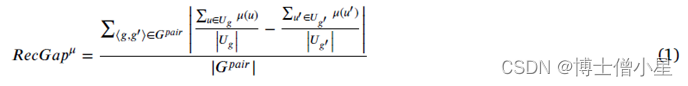
其中𝐺𝑝𝑎𝑖𝑟是组对的集合,𝑈𝑔表示组𝑔中的用户集,𝜇(𝑢)返回用户𝑢的度量𝜇的评估结果(假设有相应的真实数据可用)。RecGap的指标直观地量化了不同用户组的平均结果之间的差距,即𝜇(𝑢)。
指标𝜇可以是任何可以在用户层面上计算的评价指标(并在用户组层面上进行汇总),如NDCG、多样性、召回率等。根据这种提法,RecGap使用不同用户的平均值(在评价指标中很常见),而不强求各组有相同数量的用户。RecGap的这一特点在现实世界的场景中尤为重要,因为各敏感属性的用户数量通常是不同的。𝑅𝑒𝑐𝐺𝑎𝑝𝜇可以有零或正值,其中零表示推荐算法是公平的,而较高的正值表明存在较高程度的不公平。解读𝑅𝑒𝑐𝐺𝑎𝑝𝜇的大小取决于考虑的𝜇函数和组的数量。作为召回指标的一个简单例子,让我们考虑一个二元性别设置,男性和女性的平均召回分数分别为0.5和0.3。在这个例子中,𝑅𝑒𝑐𝐺𝑎𝑝Recall等于0.2,这意味着与提供给普通女性用户的结果相比,平均男性用户在前10个结果中获得的相关条目增加了20%。
在𝐺为二元集的特殊情况下,𝑅𝑒𝑐𝐺𝑎𝑝𝜇被简化为各组评价分数平均值的绝对差异。在这种情况下,𝑅𝑒𝑐𝐺ap 的大小可以通过应用假设检验来评估,检验组间差异是否有统计学意义,表明𝑅𝑒𝑐Gap在多大程度上是有意义的。最后,𝑅𝑒𝑐Gap中的偏见/不公平的方向可以简单地通过比较各组均值的程度来确定:模型对均值较高的组有偏见(考虑到较高的𝜇值意味着较高的收益)。
4.2 推荐系统中的复合不平衡现象
我们对复合不平衡的定义遵循De-Arteaga等人(2019)的工作,将复合的概念扩展到任何任意评价指标的RS。考虑到一种推荐算法在用户组之间存在一定程度的不公平(𝑅𝑒𝑐𝐺𝑎𝑝≠0),我们旨在量化算法在给定任意评估指标的情况下,在多大程度上复合了数据中的初始不平衡。更具体地说,与De-Arteaga等人(2019)类似,我们希望每个组根据评价指标获得的收益与它的人口成正比,否则算法会加剧总体偏见。(例如:男女比例2:1,收益比例至少也应该是2:1,若收益比例变成4:1则说明算法加剧了总体偏见)
为了定义这样一个指标,我们首先引入人口分布𝐵,作为用户在群体中的比例分布。例如在二元性别设置的情况下,𝐵可以是𝐵=[0.8, 0.2],意味着80%的用户是男性,其余是女性。给定一个推荐算法和评价指标𝜇,我们定义用户组的指标分数分布,用𝐶𝜇={𝑐𝜇𝑔|𝑔∈𝐺}表示。𝐶𝜇的每个元素𝑐𝜇𝑔是一个概率,定义为组内所有用户的评价分数之和除以所有组内所有用户的分数之和:

𝐶𝜇分布包含了指标𝜇中关于每组的评价分数部分。按照上面的例子,根据NDCG,RS偏向男性的二元性别(𝑅𝑒𝑐𝐺𝑎𝑝NDCG≠0),NDCG分数的分布可能导致𝐶NDCG=[0.85, 0.15],即男性为0.85,女性为0.15的值。现在,将𝐶NDCG与人口分布𝐵=[0.8, 0.2]相比较,我们观察到人口对男性的偏见(80%到20%)在推荐结果中被加强(85%到15%)。换句话说,推荐者算法加重了人口的偏见。
为了将这些分布之间的差异描述为一个单一的数字,我们引入了复合因子度量,定义为分布之间的 Kullback-Leibler (KL) 散度。因此,关于推荐算法关于指标 𝜇 (𝐶𝑜𝑚𝑝𝐹𝑐𝑡𝜇) 的复合因子公式为:

𝐶𝑜𝑚𝑝𝐹𝑐𝑡𝜇指标的值显示𝐶𝜇与𝐵的分歧程度,其中值越大表示算法合成的偏见程度越高。在上面的示例中,鉴于𝐵=[0.8,0.2]和𝐶NDCG =[0.85, 0.15],所以𝐶𝑜𝑚𝑝𝐹𝑐𝑡NDCG = 0.0101。(即B和C之间的KL距离)
5 实验设置
在本节中,解释实验设置。总的来说,我们在LFM-2b-DemoBias的性别分组的数据上进行了所有的实验,考虑了两种实验方案。在第一种情况下,即标准情况下,在没有任何干预的情况下对数据集进行了实验。这种情况反映了被调查的推荐系统算法在野外的表现,以及它们对用户的性别不公平的处理。第二种情况,即重新取样,考虑的是在原始数据集上应用去偏程序。去除过程试图减少男性和女性的待遇差异,并对应于解决公认的基于性别的差异的情况。在每个场景中,我们研究了各种不同性质的核心协同过滤(CF)算法(例如,矩阵分解Billsus, Pazzani, et al., 1998和自动编码器Zhang, Yao, Sun, & Tay, 2019),以及几个评价指标(包括与Accuracy相关的和超越准确性的)。在随后的小节中,详细介绍了为获得实验中使用的数据集而进行的处理步骤(第5.1节),所有调查的算法(第5.2节),算法的训练和评估程序(第5.3节),实验场景(第5.4节),使用的指标(第5.5节),使用的显著性检验(第5.6节),以及我们对超参数的调整方法(第5.7节)。复制实验的代码可在https://github.com/CPJKU/recommendation_systems_fairness。
5.1 数据处理与准备
在我们的实验中,我们重点关注LFM-2b-DemoBias的性别子组(见表1中与性别有关的部分)。根据以下过滤标准来处理这个子组的数据。首先,只考虑播放次数(PC)>1的用户-曲目互动。这就去掉了可能由单一互动引入的可能有噪音的用户-曲目互动。第二,只考虑至少有5个不同用户听过的曲目和至少听过5个不同曲目的用户。这些阈值在以前的工作中常用 (Bauer & Schedl, 2019; Liang, Krishnan, Hoffman, & Jebara, 2018; Ning & Karypis, 2011; Schedl, 2017),对于协作过滤算法的有意义使用是必要的。第三,我们只考虑过去5年内收集的Les(收听事件)。这使得研究集中在用户最近的收听行为上,如第3节所示,这些行为在过去几年里有很大的增长。最后,将用户与曲目的互动转换为二进制值,即如果用户至少听过一次该曲目,则将用户与曲目的互动设置为1,否则为0。
由此产生的数据集包括23,272个用户——这是一个从用户角度研究公平性的良好设置——但也是一个非常高的项目/曲目数量(共1,606,686个),这使得它对于大规模的推荐实验不切实际。通过随机抽取100,000条曲目来解决这个问题。请注意,应用随机抽样保证了涵盖不同流行程度的曲目都包含在最终的数据集中。把这个最终的子集称为LFM-2b-DemoBiasSub。该数据集的统计数据在表2中报告。应该注意到,即使是这样的减少,LFM-2b-DemoBiasSub数据集仍然大于Million Song数据集(包含41,000个项目),后者通常用于音乐RS的研究。(Artists/User:表示用户收听艺术家的平均值和标准差)
5.2 推荐系统算法
研究了不同的隐性数据推荐算法在多大程度上产生了不同的结果,这取决于用户的人口统计特征。所选算法涵盖了不同类型的协同过滤方法。特别是,研究了基于非个性化推荐、矩阵分解、𝑘最近邻和自动编码器的算法,这些都是RS研究中的核心。所有的算法都适用于用户-物品交互矩阵,其中用户在行中表示,物品在列中表示。如果一个用户与一个项目进行了互动,那么矩阵中的相应值就是1,否则就是0。 在下文中,将对本工作中研究的每一种RS算法进行简要解释。
- Popular Items (POP):提供了一个简单的非个性化的基准。它向各用户推荐同样的一组Top-𝑛曲目,其中的曲目是按照总体流行度(有多少用户听过该曲目)排序的。
- Item k-Nearest Neighbors (ItemKNN):是一种基于计算项目-项目相似性的基本的基于内存的推荐方法。在这种方法中,如果一个项目与用户之前选择的项目相似,就会向用户推荐该项目。在CF系统中,由同一组用户选择的项目被认为比不重叠的用户组的项目更相似。
- Alternating Least Squares (ALS) (Hu, Koren, & Volinsky, 2008):属于矩阵分解法的范畴,是自Netflix挑战以来广泛使用的算法系列(Billsus et al., 1998)。ALS采用一个交替的训练程序来获得一组用户和项目的嵌入,其方式是使嵌入的点积接近于原始的用户-项目矩阵。
- Bayesian Personalized Ranking (BPR) (Rendle, Freudenthaler, Gantner, & Schmidt-Thieme, 2012)提供了一个优化函数,它不是预测特定的用户和项目对的评级,而是根据用户的偏好对用户消费的项目进行排名(因此,这个是个性化排名)。为此,BPR定义了一对物品之间的隐含顺序。BPR最大化了与用户有互动的项目和没有互动的项目的评级预测之间的差异。我们将BPR目标函数应用于矩阵分解嵌入。
- Sparse Linear Methods (SLIM) 是一个线性模型,旨在计算Top-𝑛推荐,通过在非负性、𝐿1和𝐿2约束下因子分解项目-项目共现矩阵。学习到的项目系数被用来稀疏地聚合过去的用户交互,并预测用户推荐的项目。
- Variational Autoencoders (MultiVAE) (Liang et al., 2018)是一个变分自动编码器架构,它首先将稀疏用户的交互向量投射到一个潜在的分布空间,之后用于生成所有项目的概率分布。MultiVAE采用了多项式似然和涉及线性退火的不同正则化程序。
5.3 实验流程
在本节中,详细描述了算法的训练和评估过程,并附有应用的交叉验证方法。
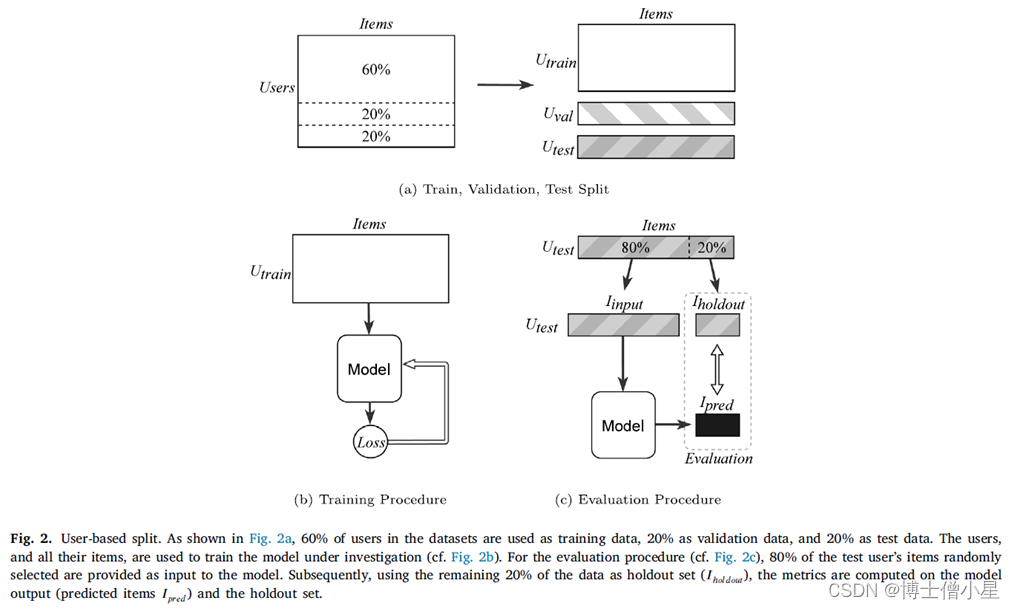
对于手头的推荐任务,RS文献中提出了不同的评价目标和数据拆分。在我们的实验中,采用了数据集的用户拆分策略,通常用于自动编码器等算法。该拆分策略如图2a所示。LFM-2b-DemoBiasSub数据集的19,972个用户被划分为训练集、验证集和测试集,采用常见的60-20-20比例划分。训练集中的用户,连同他们所有的互动,被用来训练分析中的算法(图2b)。评估程序(验证或测试)是通过将80%的用户项目均匀地随机抽样给模型,并将剩余的20%作为计算指标的基础事实来进行的(图2c)。直观地说,评估程序迫使模型学习用户广泛的音乐品味,而不是只预测用户接下来要听什么。该实验设置也被称为强泛化,因为我评估的是没有遇到的新用户的推荐系统。
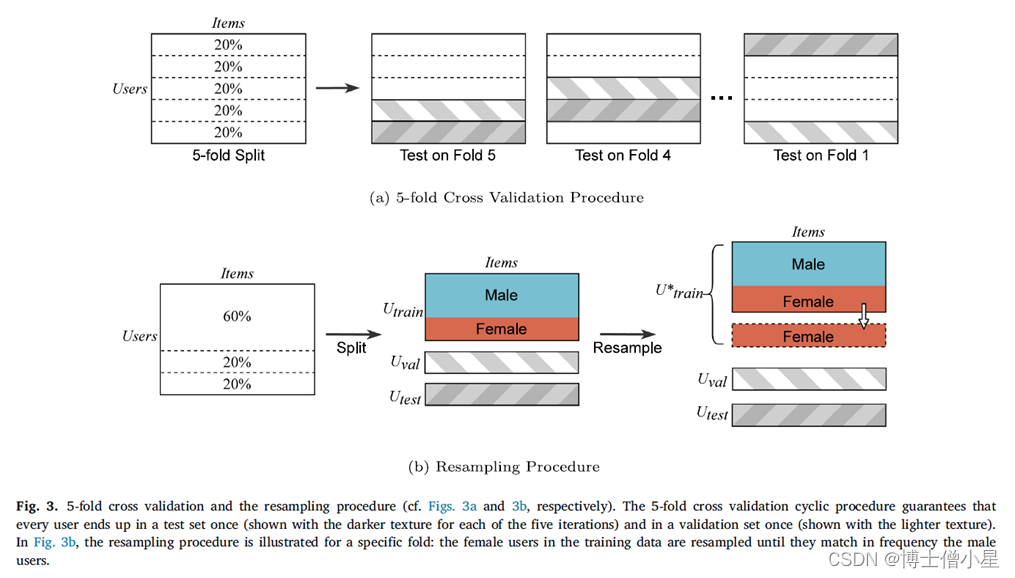
为了对数据集中的所有用户进行评估,同时避免上述用户抽样策略可能带来的偏见,遵循机器学习的标准做法,进行5倍交叉验证,如图3a所示。具体而言,把用户分成5个大小相等的组,用3个组进行训练(60%的用户),1个组进行验证(20%的用户),1个组进行测试(20%的用户)。对于每个一折,都遵循上述的训练和评估程序。我们以轮流的方式切换组别,直到每个用户组都被用作测试组。应用交叉验证为指标提供了更好的估计,也允许我们测试数据集中的所有用户,得到基于性别属性的更好比较。
5.4 实验场景
进行所有实验时,牢记两种情况:标准和重采样。在标准场景中,在不对数据进行任何干预的情况下训练系统,这与第5.3节中描述的程序完全对应。对于重采样方案,试图通过对基础数据集的重采样干预,消除推荐算法偏见,如图3b所示。首先,按照5.3节所述程序,把用户分成训练、验证和测试三部分,就像在标准场景中一样。其次,对训练集中的少数群体(女性)用户进行重采样,直到他们与多数群体(男性)训练数据点数量相匹配。请注意,当一个用户被重采样时,她的收听历史会被复制并完全用于训练过程中。继Geyik等人(2019)之后,通过在训练过程中提供男性和女性用户的平衡表示,我们的目标是在推理时促进同样好的推荐。此外,由于验证集和测试集保持不变,标准和重采样方案的评估结果具有可比性。
5.5 评价指标
使用两个基于准确性的指标来评估算法的性能:Recall和NDCG(Normalized Discounted Cumulative Gain,归一化打折累积增益)。还使用两个超越准确率的指标来评估结果:多样性和覆盖率。所有指标都是根据排名结果计算的,直到位置𝐾。下文对指标进行了简要解释。
Recall@K for user 𝑢 is defined as:

其中,𝑁𝑢是测试集中与𝑢相关的项目数量,𝑟𝑒𝑙(𝑖)是一个指标函数,表示等级为𝑖的推荐轨道是否与𝑢相关(即。𝑟𝑒𝑙(𝑢)=1)或与𝑢不相关(即𝑟𝑒(𝑢)=0)。Recall@K量化了分析中为用户检索相关项目的能力。它的范围从0,即没有检索到用户的相关项目,到1,即所有的相关项目都出现在第一个k位置。
NDCG@K is defined as:

其中𝐼𝐷𝐶𝐺@𝐾(𝐾)是用户u的理想𝐷𝐶𝐺@𝐾(𝑢),当u的测试集的所有项目都排在顶部时得到,𝐷𝐶𝐺@𝐾(𝑢)是用户𝑢在位置𝐾处的打折累积增益,由DGG给出:

其中𝑟𝑒𝑙(𝑖)是上述相同的指标函数。与Recall@K相比,NDCG@K是一个准确度指标,它不仅可以量化检索相关项目的能力,还可以量化对其进行排名的能力。在列表顶部提供相关项目的推荐系统算法在 NDCG@K 中的得分将高于相关项目位于底部的算法。这种行为是通过根据项目的位置进行“打折”来实现的,也就是说,计算打折累计收益(DCG)。为了在0和1之间标准化分数,然后将DCG与通过将所有相关项目放在列表顶部获得的所谓“理想排名”进行比较。
Diversity is calculated for each user as normalized Shannon entropy (香农熵) on the artist level:
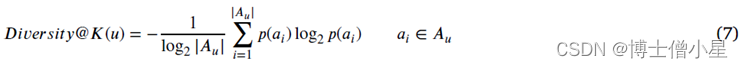
其中,𝐴𝑢是向用户𝑢推荐曲目(在前𝐾)的唯一艺术家集合,𝑝(𝑎𝑖)是艺术家𝑎在推荐列表前𝐾中的曲目比例。𝐷𝑖𝑣𝑒𝑟𝑠𝑖𝑡𝑦@𝐾(𝑢)因此,如果推荐给用户的前𝐾曲目中的每一首曲目都有不同的艺术家,则等于1。如果所有顶级𝑢推荐的曲目都来自同一个艺术家,那么𝐷𝑖𝑣𝑒𝑟𝑠𝑖𝑡𝑦@𝐾(𝑢)变成0。
最后,𝐶𝑜𝑣𝑒𝑟𝑎𝑔𝑒@𝐾被定义为测试集中曲目的比例,这些曲目至少在一个用户的顶级𝐾推荐列表中出现。
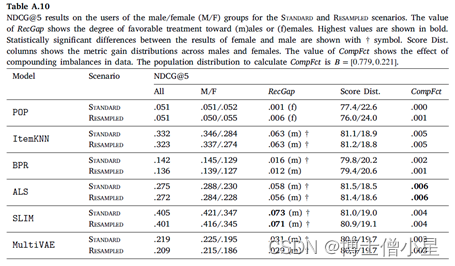
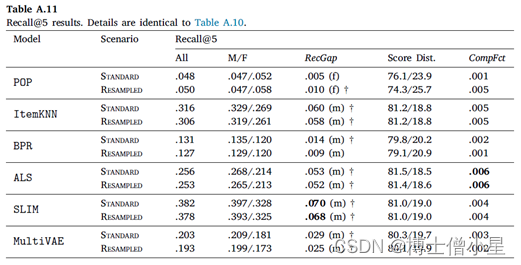
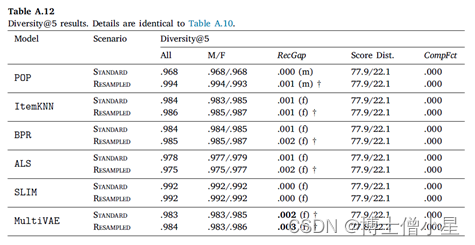
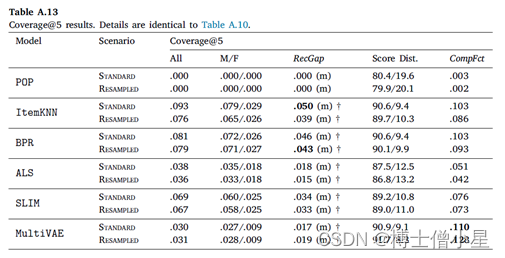
在我们的实验中,计算 𝐾 = {5, 10, 50} 的指标。这样做的目的是为了模拟不同的用户需求,从只对少数顶级推荐感兴趣的用户到对较长推荐项目列表感兴趣的用户。在详细讨论结果时(第6节),我们关注设置𝐾 = 10,因为这是Last.fm的推荐器默认显示给用户的曲目数量。𝐾 = {5, 50}的结果在附录A中提供。
5.6 显著性检验
检验了两种设置中结果差异的显着性。 第一个设置(考虑检查RecGap的结果)是关于一种推荐算法在两个不同规模的群体之间的差异,即女性与男性。第二种设置涉及一种推荐算法在两种应用场景中的差异,即标准和重采样(见5.4节)。在这两种情况下,都执行Mann-Whitney U-test,也称为 Wilcoxon 秩和检验。此外,还对每个场景的不同模型进行了成对比较。对于这些,采用Dunn test(邓恩检验)和Bonferroni校正的𝑝值调整。
考虑到每个实验中我们通过5折交叉验证来进行实验,要进行5个独立的统计测试(每折都有一个)。随后,通过应用加权Stouffer's Z方法,将所得的𝑝值合并。我们选择加权Stouffer’s Z法是因为它对不对称问题比较稳健,对单一的低𝑝值不太敏感,也就是说,为了达到低的综合𝑝值,需要几个持续的低𝑝值(Darlington & Hayes, 2000)。此外,当合并的𝑝值来自于对同一假设的多次检验时,加权Z方法也是合适的,就像我们的研究一样。在我们所有的实验中,我们认为𝑝<0.01的结果是显著的。
5.7 超参数和训练
通过对不同的参数进行网格搜索来选择所研究的算法的超参数,并根据验证集上NDCG@50的结果找到最佳参数集。经过验证后,选择性能最佳的模型,最后在测试集上进行评估。我们为每折重新选择超参数。
下文中,报告了与每个模型相关的超参数范围。
对于ItemKNN,从{3, 5, 10}中选择邻居数,并在余弦度量、Pearson相关系数和Jaccard系数中选择相似性函数。还检查了上述相似函数中去除归一化的效果(通过消除分母)。选择{0, 10, 100}之间的收缩值(the value for shrinkage)。
对于ALS和BPR,在{10, 100, 1000}之间选择嵌入大小,在{500, 1000}之间选择训练的迭代次数,在 {1e-3, 1e-4}之间选择正则化因子。对于BPR,使用{1e-3, 1e-4}之间的值进一步调整学习率。
对于SLIM,探索了不同的𝛼值 (𝐿1和𝐿2系数之和)和𝐿1 𝑟𝑎𝑡𝑖𝑜𝑠 (𝐿1系数在𝛼中的比率)。在{0.5, 0.1, 0.01, 0.001}和𝐿1 𝑟𝑎𝑡𝑖𝑜从{0.1, 0.01}中搜索𝛼值。将迭代次数设置为500。
对于MultiVAE,探索了不同的(对称)架构和退火程序。将epoch的总数设置为100,将学习率设置为 1e-3。我们研究了各种架构,即 I-500-I、I-1000-I 和 I-1000-500-1000-I。在架构中,I 是轨道的总数,中间的数字表示潜在嵌入的维度,中间的数字(如果存在)是具有双曲正切非线性的前馈网络的中间维度。关于原始论文(Liang et al., 2018)中描述的退火过程,通过从值{5000, 100 000}中选择beta steps对正则化参数进行线性退火。我们将退火上限设置为1,即执行正则化直到其最大值。
6 结果与讨论
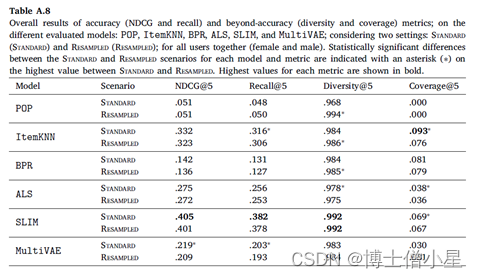
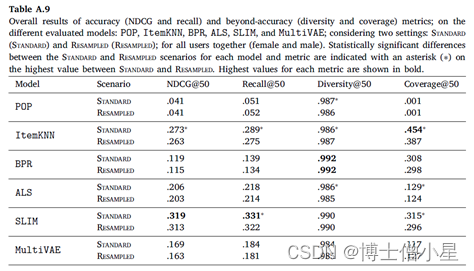
在本节中,报告实验结果并讨论。首先介绍推荐算法/模型的整体性能(6.1节),然后报告衡量推荐公平性的结果(6.2节)。在本节中,只报告排名到位置𝐾 = 10的结果。关于其他位置(5和50)的结果在Appendix A中报告。此外,还在LFM-1b数据集上进行了精确的实验,其结果在Appendix B中报告。
6.1 性能评价结果(各算法模型的整体性能)
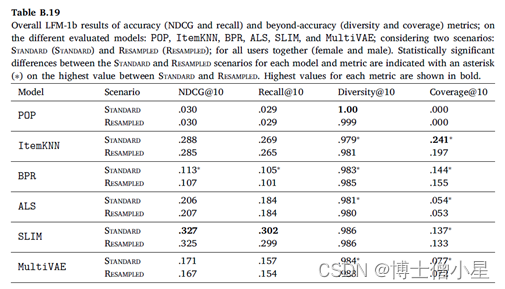
表3显示了所有用户的两个实验场景(标准和重采样)中的平均实验评价结果。我们对每个算法和指标的结果进行了标准和重采样之间的显著性测试(5.6节)。
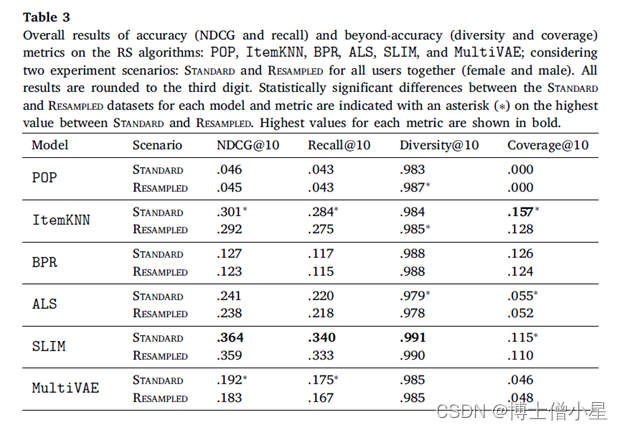
每个模型和指标的标准数据集和重采样数据集之间的统计显着差异在标准和重采样之间的最大值上用星号 (*) 表示。
总体而言,两个实验场景中SLIM在基于准确性的指标(NDCG和召回)以及超准确性指标(Diversity)方面表现出最佳性能。在所有的配对比较中,SLIM与其他模型所取得的分数之间的差异具有统计学意义(|users|×2种算法 à 5个独立的统计测试 à 加权p值)。在重新采样的多样性场景中,SLIM和ItemKNN之间的差异最小(𝑝 = .0002)。另一方面,ItemKNN 在覆盖率方面得分最高。除了与SLIM和BPR的比较(在重采样和标准场景中),ItemKNN和其他模型之间的所有其他配对比较都显示出统计学上的显著差异。正如预期的那样,非个性化方法(POP)在基于准确性的指标上表现最低,在覆盖率上的值为0.0,因为POP向所有用户推荐相同的项目集。矩阵分解方法(ALS和BPR)在基于准确性的指标方面,BPR的性能通常低于基于内存的ItemKNN,而BPR与ItemKNN相比具有更高的多样性。最后,MultiVAE通常表现较弱,尤其是在基于准确性的指标上。这一观察结果与先前关于较小数据集的研究报告的结果形成对比。我们怀疑MultiVAE的性能较低是由于我们的数据集中有大量项目,这使得算法更难提供输出预测的有效分布。我们认为对MultiVAE的这种行为的进一步分析是未来的工作。
将“标准场景”的结果与“重采样场景”的相应结果相比较(|users|×2种场景 à 5个独立统计测试的加权 à 加权p值),观察到性能的整体下降,而在大多数情况下没有观察到明显的差异。在所有指标中,去偏见操作明显损害了ItemKNN的性能;在NDCG和Recall中,MultiVAE的性能明显下降;在Diversity和Coverage中,ALS的性能明显下降。
在本节的其余部分,研究了这些算法的公平性和复合因子的结果。
6.2 推荐系统中的公平偏见
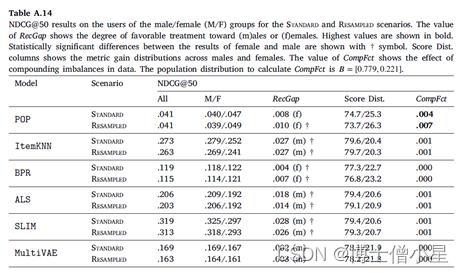
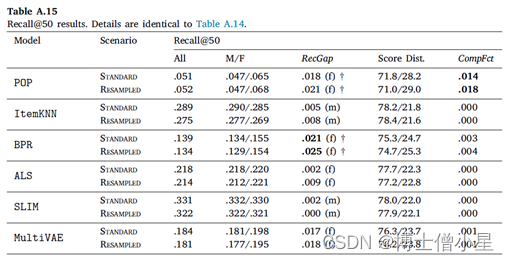
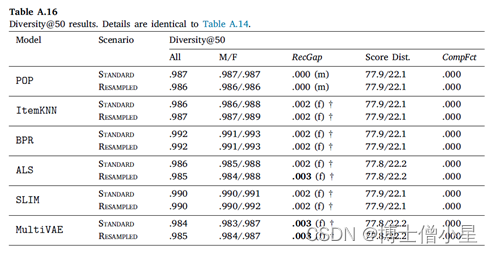
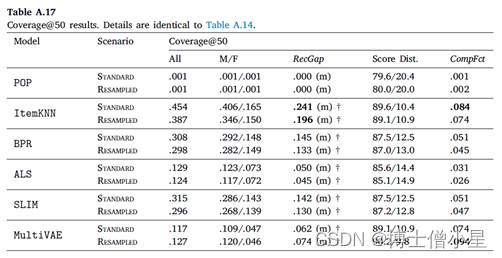
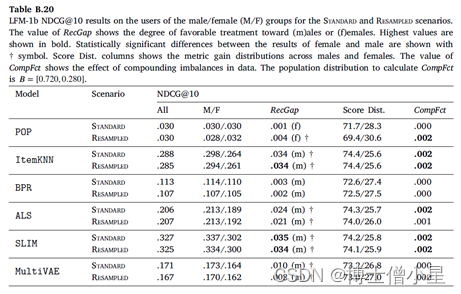
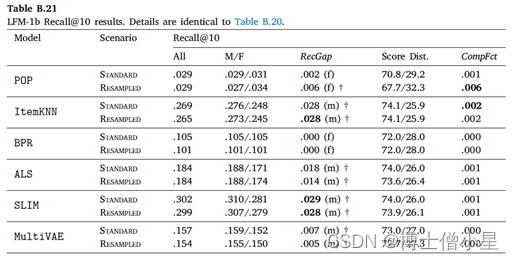
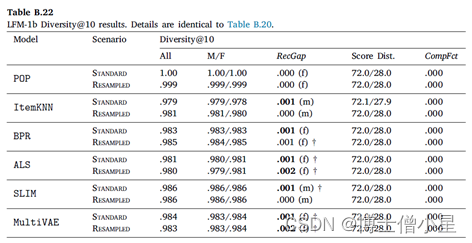
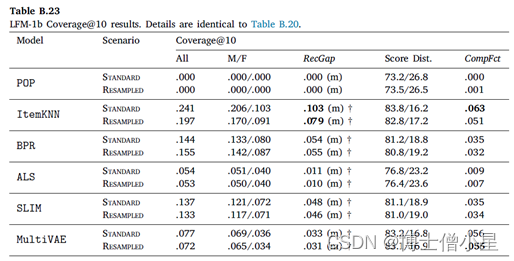
在本节中,首先讨论RecGap的评价结果,然后分析复合因子的结果。如第4节所述,通过分别评估男性和女性用户组的测试集结果来计算标准和重采样的RecGap指标。表4-7重复了总体评价结果,但也报告了每个用户组的结果,以及计算出的RecGap指标。RecGap的绝对值越高,表示不公平程度越高,而(m)或(f) 分别表示偏爱的方向,无论它是朝向 (m)ales 还是 (f)emales。还报告了与男性和女性组相关的评估结果之间差异的显着性,以匕首符号显示 (|males + females|=|users| à 5个独立的统计测试 à 加权p值)。每个场景和指标的最高绝对值以粗体显示。
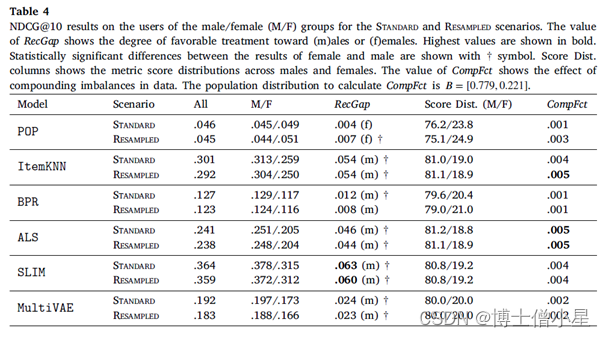
CompFct的值显示了数据中复合不平衡的影响。计算CompFct的人口分布是𝐵=[0.779, 0.221]。
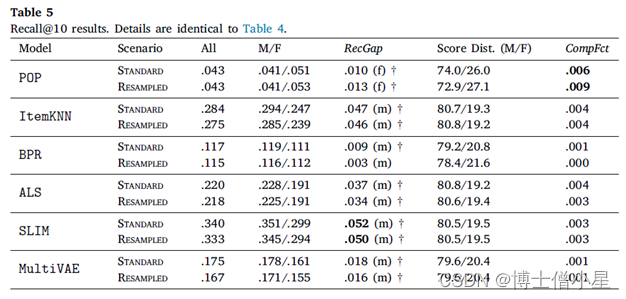
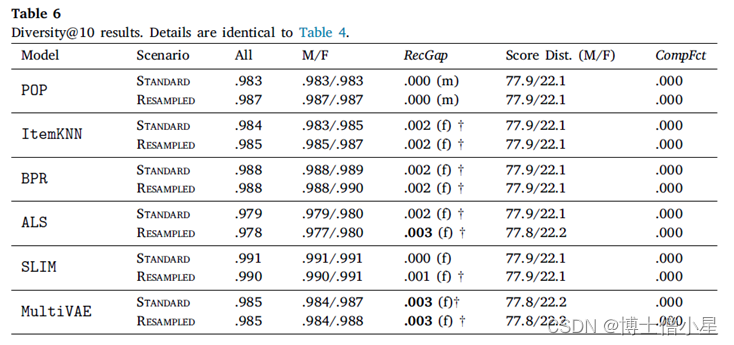
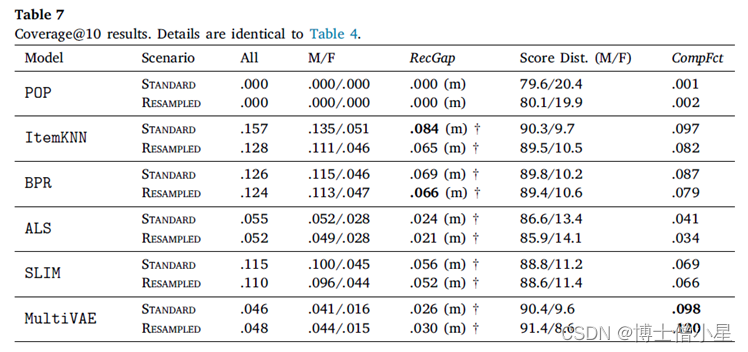
如上所示,大多数算法在性能上存在明显的偏见(RecGap),特别是在NDCG、Recall和Coverage上,对男性用户群有利。总体而言,Diversity指标显示与男性用户群体的差距非常小。稍微偏向女性群体。
在所有算法中,SLIM在基于准确性的指标上具有最高程度的不公平性。这尤其令人担忧,因为SLIM 在所有算法中表现最好,在不考虑公平性措施的情况下,它成为潜在RS的有力候选者。事实上,甚至可以观察到基于准确性和公平性度量之间的反比关系,即ItemKNN和SLIM等性能更好的算法,RecGap变得更大,而在准确度方面表现更差的算法,RecGap减小,达到BPR和POP 的最小值。
从去偏移方法的效果来看,我们观察到,与标准场景的NDCG、Recall和Coverage相比,RecGap在重采样上只是略有下降。这种下降虽然微不足道,但考虑到去偏方法并没有降低大多数算法的性能,如SLIM、ALS和BPR,其仍然是有价值的。这些结果表明,有必要在这个数据集上进一步研究其他的算法去偏方法,我们认为这是一个未来的方向。
我们现在检查一下性能指标NDCG的结果与它相应的RecGap之间的关系。图4a描述了在LFM-2b-DemoBiasSub数据集上评估的不同推荐算法的NDCG@10和其RecGap。每种推荐算法的深色标记表示标准场景下的结果,浅色标记表示重采样场景下的结果。虚线表示对标准结果的线性拟合,表明NDCG@10和RecGap之间的关联性。如图所示,性能指标和RecGap高度相关,这样,具有较高NDCG的算法也显示出较高的不公平性。换句话说,推荐算法通过更强烈地改善多数组,从而增加差距,达到更好的性能。我们的结果强调了平行研究推荐算法的公平性,并与它们的性能并列的重要性。
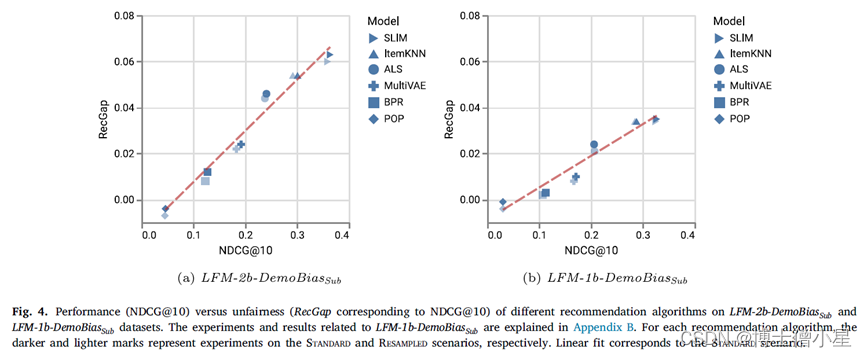
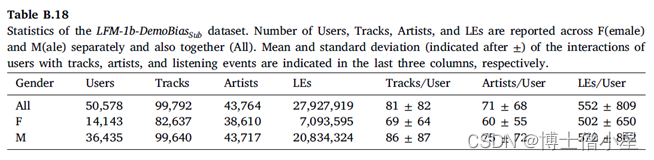
为了完整起见,还报告了在LFM-1b-DemoBiasSub上进行的同样的实验结果(Appendix B)。如图所示,在这个数据集上可以观察到相同的相关模式。然而,由于LFM-1b-DemoBiasSub上算法的NDCG@10结果一直低于LFM-2b-DemoBiasSub中的相应结果,相应的相关系数相对较小。
至于复合因子的结果,即指标分数分布和相应的CompFct,分别在表4-7最后两列中提供。这些结果通过量化模型偏见在多大程度上加剧了数据/总体偏见,为RS中的不公平性提供了补充观点。
男性和女性用户在人口中的分布是𝐵=[0.779, 0.221]。基于这个人口分布,如果一个指标增益分布中男性的数值高于77.9%,那么相应的模型就加重了人口对男性群体的偏见,这相应地反映在CompFct中。每个算法、指标和数据集的CompFct的最高绝对值以粗体显示。正如预期的那样,大多数算法(除POP外)在最终结果中加重了现有的数据偏见。与RecGap类似,去偏方法一般会减少CompFct的绝对值(除了POP和ItemKNN),而这种减少是边际的。这些结果强调了RS模型中存在的不公平是如何放大数据中的潜在偏见的,并激发未来解决该问题的工作。
扩展之前对结果的描述,我们从RecGap度量的角度分析了推荐算法之间的差异,并为这些差异提供了可能的解释。POP表现不尽如人意(POP expectedly does not perform well),因为它只考虑流行项目,而忽略了个性化推荐算法的细微之处。结果表明,女性用户平均消费的流行歌曲比男性用户略多,这与之前的发现一致。关于POP的一个特别的观察结果是,RecGap在重采样场景中的结果略有增加,而在其他算法中则有所减少。我们认为,其原因是由于女性用户重新取样后,女性用户所听曲目的受欢迎程度增加。这种增加最终导致了POP在女性群体的准确性指标(NDCG@10和Recall@10)方面的轻微改善,并因此导致了RecGap向女性的边际增加。
对于创建个性化模型的算法,观察结果显示出截然不同的特征。 在准确性方面最不公平的算法是 SLIM 和 ItemKNN(最高 RecGap)。 这两种算法都依赖于从用户-项目交互矩阵计算的项目-项目相似性度量。 这表明项目-项目相似性度量可能对反映多数群体的偏好产生影响。我们认为对这种影响的进一步深入分析是未来的方向。
最后,比较了两种被调查的矩阵分解方法的结果,即ALS和BPR。这两种算法产生的RecGap大不相同,其中BPR在个性化模型中提供了最公平的结果(尽管在NDCG和Recall方面也是第二差的),而ALS的结果则高度不公平。基于这些实验,我们没有观察到矩阵分解方法对推荐算法公平性的任何直接影响。
7 结论,局限和未来工作
在这项工作中,研究了人口和模型/算法在音乐推荐方面的性别偏见的影响。为此,首先介绍了LFM-2b,一个新的大规模真实世界的音乐收听记录数据集,其中包括LFM-2b-DemoBias,一个包含用户收听记录的子集,这些用户的性别、年龄和原籍国等人口统计信息是可用的。利用LFM-2b-DemoBias,根据算法评价指标的差异,探索RS算法在用户性别方面的群体公平性。研究了文献中常见的不同协作过滤算法,并考虑了准确性和超越准确性的指标。此外,制定了RSs的复合因子,并研究RS算法在多大程度上加剧了数据的潜在偏见。此外,还利用一种应用于数据的去偏方法,其目的是减轻模型的偏见。在下文中,将总结我们对所考虑的研究问题的发现。
RQ1:不同类别的推荐算法是否会针对不同的用户群体在性别方面产生不同的性能分数(在准确性和超越准确性的指标方面)?如果是的话,如何描述这种差异?研究结果表明,在NDCG、Recall和Coverage指标方面,研究中考虑的大多数协同过滤算法往往对女性群体(少数群体)不公平,特别是在较短的推荐列表上,即排名列表到第5和第10位。此外,注意到基于准确性和公平性指标之间的(反向)关系:性能更好的算法(如SLIM和ItemKNN),与不太准确的算法相比(如BPR和POP),表现出更大程度的不公平性。
RQ2:通常作为去偏方法的重采样策略对算法的性能和公平性有什么影响?总的来说,所研究的去偏方法稍微改善了各种RS算法中推荐结果的公平性(通过减少RecGap)。在准确性和超越准确性的指标方面,应用去偏移只稍微降低了RS算法的性能(在大多数情况下没有观察到明显的变化),这表明使用去偏方法的好处。
RQ3:RS算法会加剧数据偏差吗?如果是,如何描述?导致RS不公平结果的算法也加剧了数据的偏见。在这种情况下,算法的最终收益分布甚至比数据中的性别分布更加有偏见。观察到,在基于准确性的指标上(ALS和ItemKNN),以及在覆盖率上(MultiVAE),这种不平衡的复合程度特别高。
发现为音乐信息检索(MIR)和音乐推荐系统(MRS)界提供了可重复使用的见解。首先,根据实验结果,我们认为,对于涉及个性化的MIR和MRS任务,迫切需要开发、改进和采用去偏策略,不仅要考虑与性别相关的性能偏见——这在本文中有所展示——还要考虑其他用户和数据的特定偏见(例如,根据年龄、经验或受欢迎程度)。虽然已经存在几种去偏方法,但据我们所知,其中绝大多数仍然缺乏MIR和MRS社区的验证和采用。其次,在进行评估实验以评估(新提出的)算法的性能时,这仍然是(面向技术的)MIR 和 MRS 社区的重点,应针对不同的用户组报告结果。虽然在明确以比较不同群体的具体特征为目标的MIR和MRS研究中通常会这样做,但在技术性更强的工作中却常常被忽略。这通常需要调整实验设置,这使得MIR和MRS的研究人员在实验设计过程中对性别(和其他)偏见的相应认识内化至关重要。同样,在MIR和MRS中进行的用户研究应该批判性地反映出参与者中不平等的性别分布的潜在影响。即使MIR和MRS文献中提出的研究提到了受试者的性别分布,但往往没有从这个角度讨论结果,特别是结果的差异在多大程度上可能是由性别相关方面造成的。最后,从用户的角度来看,应该更广泛地采用提高推荐算法的透明度和推荐的可解释性的方法,这不仅是为了提高对MRS的信任(这是系统提供者经常提到的动机),也是为了提高对潜在公平问题的认识,例如,通过解释 "你被推荐歌曲𝑋是因为其他女性听众喜欢它 "这样的形式。
至于目前研究的局限性,我们承认,将性别作为二元结构的假设是一种过度简化,并没有反映出关于性别的公平和偏见的复杂性。然而,这一决定使我们能够采取实际措施。此外,我们的研究集中在对与性别有关的偏见的评估上,而其他人口统计学方面的问题,如年龄和原籍国,则没有考虑。此外,所使用的数据集包含用户与在线平台Last.fm的互动日志。因此,它们只能捕获使用该平台的人的收听事件。所有包含的信息(人口统计学和收听记录)都是由用户自我报告的,这可能容易出错,不一定能反映事实。
这些限制将在未来的工作中通过将我们的框架扩展到非二进制设置来解决,这使得研究上述案例成为可能。此外,将考虑来自音乐领域内外其他平台的数据集。最后,本工作的一个自然的未来方向是研究额外的算法去偏方法。特别是,将探讨如何/是否可以实现RS算法的公平性,而不会对其平均性能产生负面影响。(已经有人开始研究了- arXiv上有文章)
Appendix A
Appendix B



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











