




光速角逐——
纳秒级优化训练营

Training Camp


形象地说,现代CPU是以光速运转的。在光从屏幕一端行进到另一端的时间里,主流现代处理器的执行引擎可以发射数条指令。为了能“喂饱”这个高速流水线,最好有大量的cache、高速的DRAM、高速的SSD,以及使用匠心设计的软件。
本训练营紧紧围绕纳秒级优化这个目标,分上下两部分(五篇18章)从不同角度围攻这个目标。
上半部分(前三篇,每篇三章)先深挖Intel微架构所代表的现代处理器核心,理解“光速工厂”的核心结构,然后探讨考量“光速工厂”能力和效率的方法,再过渡到为工厂提供数据和指令的记忆系统。
下半部分(后两篇,共七章)先讨论影响性能的种种干扰因素(中断、CPU管理、内核调度器),再讨论如何巧妙使用软硬件资源设计出适合现代处理器的好代码。
除以上内容外,本训练营还会覆盖Intel VTUNE调优工具、perf、Intel最新推出的APX(Advanced Performance eXtensions)技术等内容。本训练营由《软件调试》和《格蠹汇编》的作者张银奎亲自讲授和带领实验。
课程形式
封闭训练:
讲解
演示
讲师带领的现场实际操作
课程时间
2025年6月6 - 8日(三天)
课程地点
北京亚运村
主办单位
格蠹信息科技(上海)有限公司
高端调试网站

第一篇:中枢

AMD和Intel微架构探秘

1
IA大局观
要点:架构和微架构、Core与Uncore、Uncore中的主要部件、最近几年的微架构、终端版本(酷睿)和服务器版本(XEON)。
2
Core——核心的核心
要点:前端、神秘的微码、MSROM (microcode sequencer ROM)、解码单元、分支预测单元(BPU)、微指令缓存、微指令队列、重命名、调度和发射、执行引擎、Golden Cove的执行端口。

3
Uncore——股肱之臣
要点:取名难、北桥分家、L3缓存、PMU、snoop agent、内存控制器、UPI、PCIe Root Complex、Thunderbolt。
4
AMD EPYC——霄龙传奇
要点:Zen微架构简史、两大市场(Ryzen和EPYC)、Zen 5惊世、EPYC 9005系列、海光变体、多DIE结构、MCM解析、IOD、CCD、CCX、CXL(Compute eXpress Links)、through-silicon-vias和多层组合、超大缓存、3D V-CACHE技术、开发和调优资源。

5
优化工具
要点:Intel VTune精要、采样和热点分析、微架构分析、AMDuProf、性能计数器、采样模式和计数模式、基于指令采样(IBS)、L3 Cache Performance Monitor Counters (L3PMC)、Data Fabric Performance Monitor Counters (DFPMC)。

第二篇:发微

时间和频率
1
逐光——纳秒级测量
要点:纳秒与光尺、RDTSC、LINUX和Windows上的实现、测量误差、降低测量误差的方法。
2
切脉——深究CPU的工作频率
要点:额定频率、跳频(boost)、Intel Turbo Boost、降频(throttling)、为何降频、TDP(Thermal Design Power)、电流和热量、pause指令、频率切换、锁频。
3
CPI——CPU工厂的硬指标
要点:CPI或者IPC、理论值、使用perf stat测量、perf原理、perf top、Golden Cove微架构的执行流水线、乱序执行、指令的吞吐量(Throughput)和延迟(Latency)。

第三篇:法门

记忆系统

1
寄存器
要点:源自图灵、通用寄存器、APX新增的寄存器(R16-R31)、寄存器上下文保存XSAVE、寄存器变量。
2
高速缓存
要点:内存层次体系、Richard Sites的预言、cache、cache结构、L1、L2、L3、cache hit和cache miss、提高cache hit的关键思想、局部性、空间局部性和时间局部性、如何编写cache友好的代码、常用技巧、循环交换、C++的虚方法、使用高级指令显式控制cache。
3
DRAM
要点:DRAM组织、通道、Rank、Bank、行、列、DIMM、工作频率、传输率、页表结构、页表项、页错误、Major Fault和Minor Fault、页错误导致的延迟、大内存页原理、Linux系统的大内存页支持、分配大内存页、评估大页的性能、案例分析之DPDK、配置大内存页。

第四篇:噪声

外设和多CPU管理
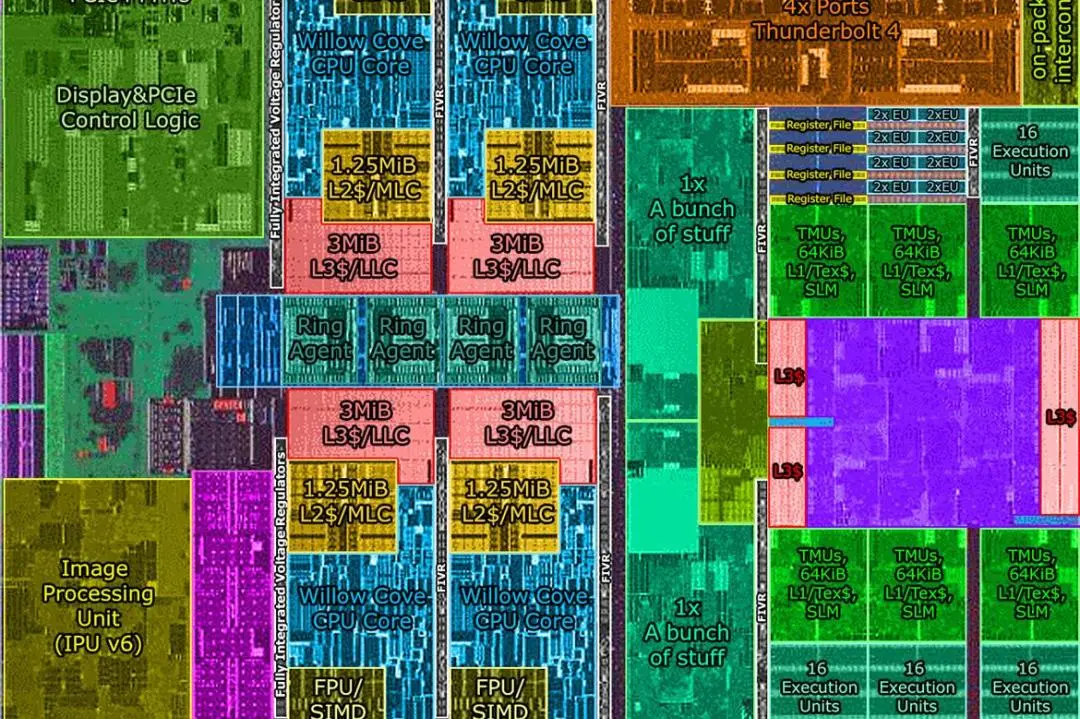
1
中断
要点:离不开的中断、APIC、IDT、中断处理过程、硬件中断、时钟中断、中断亲缘性、在Linux系统中设置中断亲缘性。
2
多CPU管理
要点:多处理器简史、IPI、Linux的SMP实现、Function Call、线程迁移、内存迁移、TLB同步。
3
内核调度器
要点:最难写的代码、调度器框架、线程状态机、ready队列、优先级、nice机制、使用kernelshark精确观察线程调度事件。

第五篇:匠心

现代CPU眼里的好代码

1
使用共享内存通信
要点:进程间通信、线程间通信、共享内存原理、使用共享内存通信、polling机制、同步、自旋锁、队列、无锁设计、使用CPU的互锁指令、案例分析。
2
数据处理
要点:两种模式、Run-to-completion和Pipeline(流水线)、流水线模式的经典实例、两种模式的多角度比较、包转发、负载均衡、流水线结构的可视化、DPDK的测试程序、解析DPDK的包处理过程。
3
内存池
要点:内核池和用户态堆、堆简介、分配和释放内存的过程和开销、内存池设计的方法、可利用的资源。
4
集腋成裘
要点:消减分支、使用谓词指令、优化内存布局、选择高性能的数据结构、结构体定义的最佳实践、避免低效率指令、数据对齐、使用VTUNE和AMDuProf精细调优。

讲师介绍


张银奎
系统内核专家
著名系统内核专家,《软件调试》作者,在软件产业工作20余年,一多半时间任职于Intel公司的上海研发中心,先后在PASD、DEG、CPG、PCCG、VPG等部门工作。业余时间喜欢写作和参与各类技术会议,发文数百万字,探讨各类软件问题,其中《在调试器里看阿里的软件兵团》等文章广为流传。多次获微软全球最有价值技术专家(MVP)奖励。在多家跨国公司历任开发工程师、软件架构师、开发经理、项目经理等职务,对 IA-32 架构、操作系统内核、驱动程序、虚拟化技术、云计算、软件调优、尤其是软件调试有较深入研究。著有《软件调试》和《格蠹汇编》二书,曾经主笔《程序员》杂志调试之剑专栏。
附录:报名与收费
标准收费:6980元 / 人
包括:
研习班期间的午餐和茶点
纸质版讲义
课程顾问(报名或垂询)
Lisa
邮箱:lisa.long@nanocode.cn
微信:13801874134
Gary
邮箱:jiali.liu@nanocode.cn
微信:17621086819
公司付款信息
账户名称:格蠹信息科技(上海)有限公司
开户行:招商银行股份有限公司上海浦江镇支行
账号:1219 3085 8010 501
【盛格塾】
正心诚意,格物致知
以人文情怀审视软件,以软件技术改变人生

格友公众号

盛格塾小程序
扫描上方二维码或在微信中搜索“盛格塾”小程序
可以阅读更多文章和有声读物
往期推荐


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









