






Items
Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},items_loders就是从网页中提取title和author字段填充到items里,比如{"title":"初学scrapy","author":"Alex"},然后items把结构化的数据传给pipeline,pipeline可以把数据插入进MySQL里.
实例
items.py
import scrapy
class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()jobbole.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.loader import ItemLoader
from urllib import parse
import re
import datetime
from ArticleSpider.items import JobBoleArticleItem
from utils.common import get_md5
class JpbboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] #先下载http://blog.jobbole.com/all-posts/这个页面,然后传给parse解析
def parse(self, response):
#1.start_urls下载页面http://blog.jobbole.com/all-posts/,然后交给parse解析,parse里的post_urls获取这个页面的每个文章的url,Request下载每个文章的页面,然后callback=parse_detail,交给parse_detao解析
#2.等post_urls这个循环执行完,说明这一个的每个文章都已经解析完了, 就执行next_url,next_url获取下一页的url,然后Request下载,callback=self.parse解析,parse从头开始,先post_urls获取第二页的每个文章的url,然后循环每个文章的url,交给parse_detail解析
#获取http://blog.jobbole.com/all-posts/中所有的文章url,并交给Request去下载,然后callback=parse_detail,交给parse_detail解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail)
#获取下一页的url地址,交给Request下载,然后交给parse解析
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=next_url,callback=self.parse)
def parse_detail(self,response):
article_item = JobBoleArticleItem() #实例化定义的items
item_loader = ItemLoader(item=JobBoleArticleItem(),response=response) #实例化item_loader,把我们定义的item传进去,再把下载器下载的网页穿进去
#针对直接取值的情况
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_value("front_image_url",[front_image_url])
#针对css选择器
item_loader.add_css("title",".entry-header h1::text")
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_css("praise_nums",".vote-post-up h10::text")
item_loader.add_css("comment_nums","a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
#把结果返回给items
article_item = item_loader.load_item()
- .add_value:把直接获取到的值,复制给字段
- .add_css:需要通过css选择器获取到的值
- .add_xpath:需要通过xpath选择器获取到的值
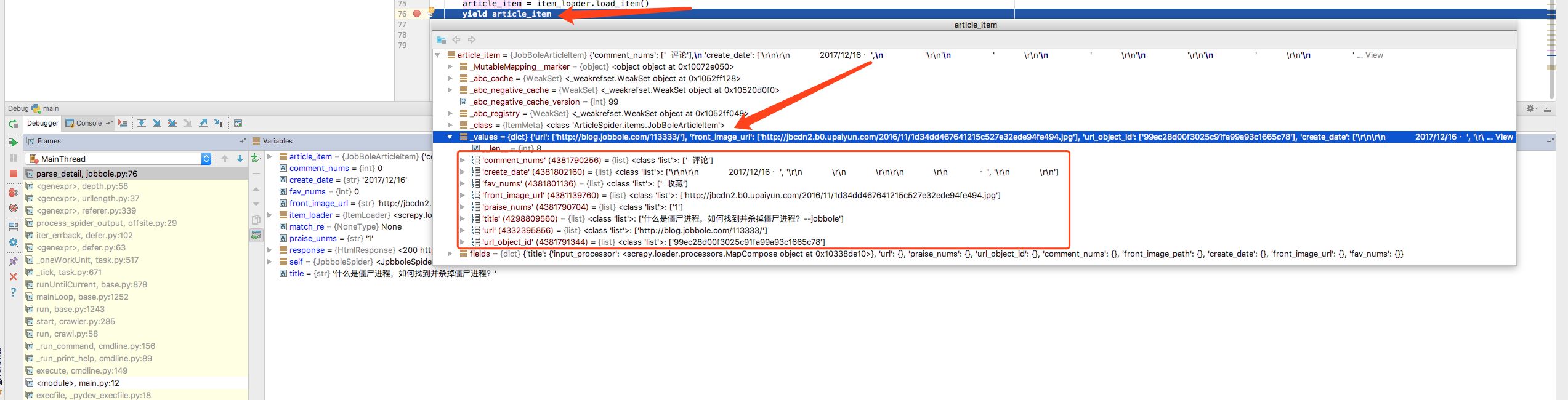
debug调试,可以看到拿到的信息















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









