







线性回归——基于燃油汽车效率数据集
1.线性回归模型与参数估计原理
线性回归模型可表示为
y
^
=
X
w
+
b
\hat{y}=Xw+b\
y^=Xw+b
y
^
\hat{y}
y^为相比于真实标签
y
y
y的预测值,
X
X
X为用于预测的数据样本的特征矩阵,其中,
X
X
X的每一行是一个样本,每一列是一种特征。
w
w
w和
b
b
b为待估计的模型参数。
对模型参数的估计一般采用损失函数作为衡量指标,损失函数的目的是使得预测值尽可能的接近真实值,从而也间接反映了所建立模型的合理性。线性回归一般采用的损失函数表示如下:
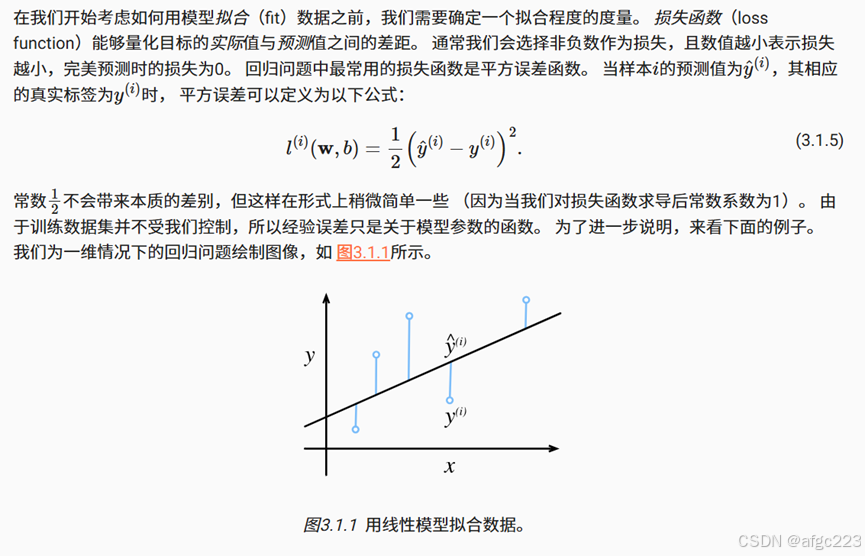

上述损失函数为最小平方误差损失函数。同时,由于线性回归模型较为简单,其在该准则下存在最优的解析解(可行域只存在一个全局最小点,不存在局部极小点),最优解的计算公式为

其中参数
b
b
b被合并到参数
w
w
w中。详细推到过程如下:

受数值计算误差的影响,有时在利用解析解求解参数时会存在较大的误差(即该问题是病态的,
X
T
X
{{X}^{T}}X
XTX可能不是满秩的或者存在很大的条件数),这种情况下更适合采取梯度下降的方法进行求解,同时随机梯度下降(随机选取小批量样本进行梯度下降)也是深度学习反向传播的一个较为核心的理论基础。线性回归的随机梯度下降可表示为

2.基于燃油汽车效率数据集的仿真验证
仿真代码中所用到的python包:
import pandas as pd
import numpy as np
import torch
from torch import nn
from torch.utils.data import TensorDataset,DataLoader,random_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
燃油汽车效率数据集是用于研究汽车的一些特征参数与汽车燃油效率关系的一个数据集,其部分数据展示如下:
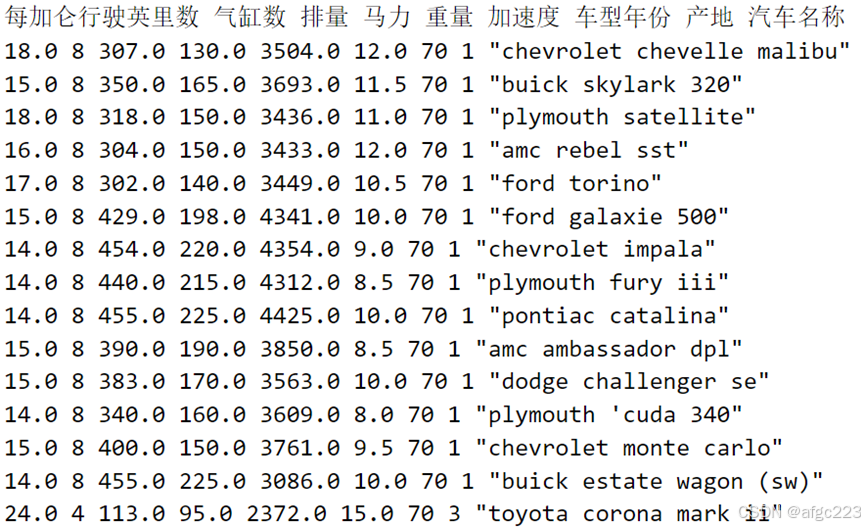
其中第一列‘每加仑行驶的英里数’即为标签值,其余列可认为是特征参数。在python中对该数据集的加载可用如下代码实现:
#加载数据集
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
column_names = ['每加仑行驶英里数', '气缸数', '排量', '马力', '重量', '加速度', '车型年份', '产地', '汽车名称']
# 读取数据,处理丢失值,‘马力’列中有 '?' 需要转换成 NaN
data = pd.read_csv(url, names=column_names, delim_whitespace=True, na_values='?')
data.to_csv('汽车燃油数据集.txt', sep=' ', index=False, header=True) #存储
在进行线性回归前,进行如下的数据预处理操作:删除与汽车燃油效率关系较小的‘汽车名称’列;‘马力’列中存在缺失值‘?’,将其替换为‘NaN’,并删除相关的行;将其余的特征参数列进行标准化。代码如下
#数据预处理
data = pd.read_csv('汽车燃油数据集.txt', delim_whitespace=True)
data = data.dropna()# 处理缺失值,删除含有 NaN 的行
data = data.drop(columns=['汽车名称']) #删除对回归无用的‘汽车名称列’
X = data.drop(columns=['每加仑行驶英里数']).values # 特征为除了目标值(第一列)以外的列
y = data['每加仑行驶英里数'].values # 提取目标值
scaler = StandardScaler()
X = scaler.fit_transform(X) #数据标准化 每一列的(x-均值)/方差
利用pytorch进行线性回归模型的训练,将数据转化为张量,并划分训练集与测试集:
# 转化为张量
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).view(-1,1)
dataset = TensorDataset(X, y) #构建数据集
# 划分训练集和测试集
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
batch_size = 10
train_loader =DataLoader(train_dataset, batch_size, shuffle=True)
建立线性回归模型,并进行相应设置:
# 线性回归模型
model = nn.Sequential(nn.Linear(7, 1))
# 初始化参数
model[0].weight.data.normal_(0, 0.01) #初始化参数均值为零,方差为1的正态分布
model[0].bias.data.fill_(0) #参数设置为零
#设置损失函数和优化器
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005) # 随机梯度下降优化器
模型的训练与测试:
# 模型训练
num_epochs = 50
L_all=np.zeros(num_epochs)
for epoch in range(num_epochs):
for xtrain, ytrain in train_loader:
L = loss(model(xtrain) ,ytrain)
optimizer.zero_grad()
L.backward()
optimizer.step()
L_all[epoch] = loss(model(X), y).item()
print(f'epoch {epoch + 1}, loss {L_all[epoch]:f}')
# 测试
torch.ones(1,7)
X_test = X[test_dataset.indices,:]
y_test = y[test_dataset.indices,0]
with torch.no_grad():
y_test_pred = model(X_test)
test_loss = loss(y_test_pred, y_test)
迭代次数为50时,得到的Loss函数下降过程以及测试集的预测值与真实值的对比结果如下:


计算在该数据集划分方式下的参数估计的解析解,并将其与梯度下降解进行对比,结果为
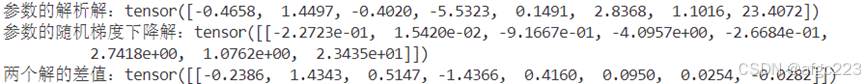
可以看到两个解的差值相差还是非常多的,对于至于全局最小点的线性回归模型,利用梯度下降可以无限逼近全局最小点,这里差值较大的原因是由于迭代次数不够,因此,增加迭代次数到一千,相应的结果为

可以看到相比于迭代次数50次时两者的误差已经小了很多,即梯度下降得到的解与最优解非常接近,此时Loss下降过程为

有趣的是,在迭代50次的Loss损失值与1000次的Loss损失值(整个训练集和测试集Loss函数的平均值)几乎相差无几,而在50次时的解与最优解却相差较大。这说明即使利用深度学习随机梯度下降方法无法获得模型的全局最优解(绝大多数网络都无法得到全局最优解),但所得到解的预测效果很有可能与全局最优解的预测效果差别很小。这也是深度学习能够获得如此广泛应用的原因之一,我们无需获得模型的最优解,只需关注模型所得到的预测效果。不同网络模型估计得到的参数可能千差万别,但计算结果可能会相差很小,这说明一个网络具有很强的表达能力(特别是参数较大的情况下,例如大模型)。当然,一个可解释性良好的网络更可能得到一个很好的效果,这需要我们去参透问题的本质,特别是当今对语言文字的理解以及视觉方面的目标检测。即使如此,冥冥之中我们又期待有一个万能的模型和一套固定的机制来解决这世间的所有问题,大模型或许就是我们在这一方面的实践,大模型就相当于这一个万能的模型,但问题的核心是如何确定这一套固定的机制,目前对这种机制的研究主要集中在模仿人脑这一块。个人认为,模仿人脑的机制是必须的,毕竟人工智能就是起源与此,即使机器本身这种特有的0-1架构有其更适合的机制来达到智能,但我们也很难想象得到,就像生活在三维空间的我们很难想象的到四维空间是怎样的(并不是没有可能性,只能说很难)。智能的概念来源于人脑,因此目前对智能的深入理解也只能从人脑分析,相信不久的将来随着对脑科学的深入研究,人工智能的势必会更进一步。
结果显示的代码如下:
# 线性回归模型
# 计算多元线性回归解析解
X_train =X[train_dataset.indices,:]
y_train = y[train_dataset.indices,0]
X_=torch.cat((X_train,torch.ones(train_size,1)),dim=1)
w=torch.matmul(torch.matmul(torch.inverse(torch.matmul(X_.T,X_)),X_.T),y_train)
print(f'参数的解析解:{w.T}')
w_sgd=torch.cat((model[0].weight.data, model[0].bias.data.reshape(1,1)),dim=1)
print(f'参数的随机梯度下降解:{w_sgd}')
print(f'两个解的差值:{(w.T-w_sgd)}')
# 可视化训练Loss函数
plt.plot(np.arange(num_epochs)+1,L_all)
plt.title('The loss function during the training process')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
# 可视化预测结果
plt.scatter(np.arange(test_size)+train_size,y_test.numpy(),color='blue',label='True')
plt.scatter(np.arange(test_size)+train_size, y_test_pred.numpy(),color='red',label='pred_sgd')
plt.xlabel('index')
plt.ylabel('MPG')
plt.title('True vs Predicted MPG')
plt.legend()
plt.ylim(y.min()-8,y.max()+10)
plt.show()
3.参考
《动手学深度学——Pytorch版》,阿斯顿 张,李沐等著,p55-p57
《机器学习——公式推导与代码实现》,鲁伟著,p21


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









