







>>号外:关注“Java精选”公众号,回复“面试资料”,免费领取资料!“Java精选面试题”小程序,3000+ 道面试题在线刷,最新、最全 Java 面试题!
kafka的IO效率这么高的原因:
1)第一个是在写入数据的时候第一个就是因为kafka是顺序写入数据的,把普通的那种随机IO变成了顺序IO,这样的话写入数据的速度就比较快。
2)第二个就是kafka读取数据的时候是基于sendfile实现Zero Copy。
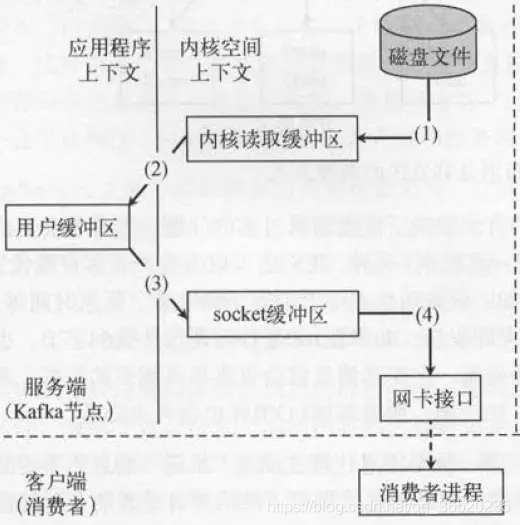
传统的数据读取的流程是:
基于sendfile实现Zero Copy调用read函数,文件数据被copy到内核缓冲区
read函数返回,文件数据从内核缓冲区copy到用户缓冲区
write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
数据从socket缓冲区copy到相关协议引擎。
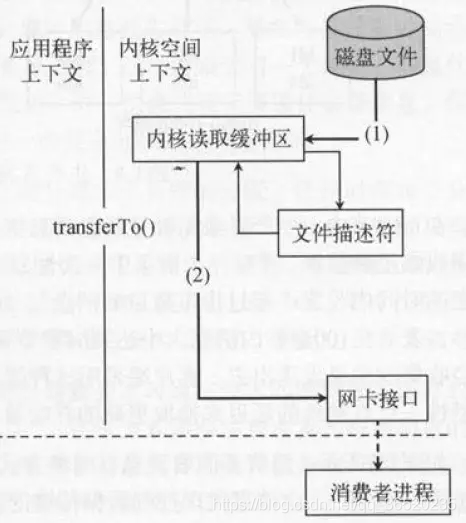
但是kafka的读取时这样的:
sendfile系统调用,文件数据被copy至内核缓冲区
再从内核缓冲区copy至内核中socket相关的缓冲区
最后再socket相关的缓冲区copy到协议引擎
3)第三个就是kafka的数据压缩,Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
下面这个图就是传统的数据读取:
这个是kafka使用的零拷贝的数据读取:
4)第二个就是kafka的生产者在进行生产消息的时候,采用的是批量发送和双线程,其实就是使用了双线程,主线程和Sender线程。主线程负责将消息置入客户端缓存,Sender线程负责从缓存中发送消息,而这个缓存会聚合多个消息为一个批次。有些消息中间件会把消息直接扔到broker。
作者:依本多情
blog.csdn.net/qq_36520235/article/details/89841798
往期精选 点击标题可
【044期】面试官:批处理框架 Spring Batch 的源码解读和批处理原则?
【045期】阿里面试题:说说关于 BeanFactory 理解和 FactoryBean 有什么区别?
【046期】面试官:MySQL InnoDB 中意向锁有什么作用?与其他锁的区别?
【047期】SpringMVC 中身份验证如何使用拦截器获取 Controller 方法名和注解信息?
【048期】面试官问:Java 中如何理解算法的时间复杂度?
【050期】面试官问:线上 5W+QPS 峰值,如何控制高并发流量?
【051期】阿里面试:为什么 B+ 树更适合作为索引的结构?分析索引原理?
【052期】面试官问:MySQL 中为什么 SQL 查询要使用小表驱动大表?
【053期】面试官问:说说 List 复制深拷贝和浅拷贝的用法与区别?
点个赞,就知道你“在看”!















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









