






在爬取过程中遇到的反爬机制以及解决
1.页面频繁获取会失败。
出现在景点详细爬取的过程中,因为获取页面太过频繁,所以偶尔会出现返回状态码异常的情况,此时需要将爬虫的速度调慢,比如:
time.sleep(3)
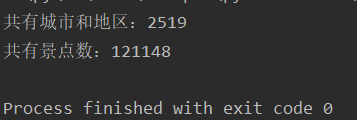
景点爬取时一共170页的城市,共爬取2500多个城市和地区,12万多条景点信息:
list = json.load(file)
print("共有城市和地区:"+str(len(list.keys())))
i = 0
for key in list.keys():
i = i + len(list[key].keys())
print("共有景点数:"+str(i))
2.随机的useragent
在伪装头部信息的时候,往往需要加上useragent,这里我采用了随机生成一个useragent,以提高爬取网站的成功率。
import my_fake_useragent as mfu
user_agent = mfu.UserAgent()
self.headers = {
"User-Agent": user_agent.random(),
}
3.需要登录的网站
在爬取某些网站的时候,它要求我们登录该网站,才能获取信息,比如大众点评,这个时候有几种办法:
1)手动登录,获取登陆之后的cookie,然后把这个cookie加到程序中。
2)利用selenium模拟用户操作,填入账号密码即可登录。
3)post请求传入参数登录。
以大众点评为例,我在登录之后发现,post请求传入的参数有一个userid之类的东西。

4.JS混淆
在爬取马蜂窝的时候,他不会返回给网页源代码,而是一段混淆的JS代码,状态码为521,通过其需要得出新的cookie,才能访问成功.
<script>
document.cookie=('_')+('_')+('j')+('s')+('l')+('_')+('c')+('l')+('e')+('a')+('r')+('a')+('n')+('c')+('e')+('=')+(-~0+'')+([2]*(3)+'')+((1<<1)+'')+(2+'')+(2+6+'')+((2<<2)+'')+(+!+[]*2+'')+(-~[2]+'')+(1+3+'')+((1<<1)+'')+('.')+(-~[2]+'')+((2^1)+'')+(-~(8)+'')+('|')+('-')+(-~0+'')+('|')+((1+[0])/[2]+'')+('J')+('T')+('c')+('e')+('q')+('b')+(1+5+'')+('U')+('x')+('q')+('X')+('h')+('b')+(3+6+'')+('J')+('V')+('D')+('F')+('H')+('R')+('%')+(0+1+0+1+'')+('F')+('N')+('r')+('%')+(-~1+'')+('F')+('Q')+('c')+('%')+((1+[2]>>2)+'')+('D')+(';')+('m')+('a')+('x')+('-')+('a')+('g')+('e')+('=')+((2^1)+'')+(3+3+'')+(~~''+'')+(~~''+'')+(';')+('p')+('a')+('t')+('h')+('=')+('/');
location.href=location.pathname+location.search
</script>
5.动态参数问题
爬取携程的时候,在向网站发出POST请求的时候我发现,这里面有一段参数是动态的,而且只能用一次,过期就无效,
但我们很难获取到这种动态改变的参数。
headers = {
'authority': 'm.ctrip.com',
'accept': 'application/json',
'origin': 'https://huodong.ctrip.com',
'user-agent': mfu.UserAgent().random(),
'content-type': 'application/json;charset=UTF-8',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'cors',
'referer': 'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=%E6%B8%B8%E4%B9%90%E5%9B%AD&id=104&name=%E6%88%90%E9%83%BD&pshowcode=Ticket2&kwdfrom=srch',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '_abtest_userid=128990d6-ec49-40cb-b25d-fc8452c3d8a1; _ga=GA1.2.179469688.1614864484; MKT_CKID=1614864484805.yk39i.z4vz; _RSG=r2q6zDxpRN1sq9uB0iKSXA; _RGUID=15dbcfb3-7d1b-40b5-a85c-52c00be09d36; _RDG=287a9b7a6689de2a903820b27712075311; ibulanguage=CN; ibulocale=zh_cn; cookiePricesDisplayed=CNY; MKT_Pagesource=PC; GUID=09031023413294183609; __utmz=1.1618917016.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=1.179469688.1614864484.1618917016.1618922802.2; nfes_isSupportWebP=1; MKT_OrderClick=ASID=5376153507&AID=5376&CSID=153507&OUID=title&CT=1618998832318&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fsid%3D153507%26allianceid%3D5376%26ouid%3Dtitle%26sepopup%3D104&VAL={"pc_vid":"1614864482896.3146qi"}; Union=AllianceID=5376&SID=130860&OUID=&createtime=1619271201&Expires=1619876000503; Session=smartlinkcode=U130860&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; MKT_CKID_LMT=1619271200658; _gid=GA1.2.378288138.1619271201; appFloatCnt=24; _bfs=1.9; _bfi=p1%3D290510%26p2%3D290510%26v1%3D76%26v2%3D75; _jzqco=%7C%7C%7C%7C1619271200974%7C1.94961373.1614864484796.1619271362144.1619272539048.1619271362144.1619272539048.undefined.0.0.35.35; __zpspc=9.7.1619271200.1619272539.4%233%7Cwww.so.com%7C%7C%7C%7C%23; _RF1=58.194.169.152; __guid=34241149.1925595889163686100.1619272712140.797; monitor_count=1; U_TICKET_SELECTED_DISTRICT_CITY=%7B%22value%22%3A%7B%22districtid%22%3A%22104%22%2C%22districtname%22%3A%22%E6%88%90%E9%83%BD%22%2C%22isOversea%22%3Anull%7D%2C%22createTime%22%3A1619272815746%2C%22updateDate%22%3A1619272815746%7D; _bfa=1.1614864482896.3146qi.1.1618999040479.1619272816278.7.80.10650038368',
}
data = '{"head":{"cid":"09031023413294183609","syscode":"999"},"imageOption":{"width":568,"height":320},"requestSource":"activity","destination":{"keyword":"' + self.to_unicode(Ncity + keyword) + '"},"filtered":{"pageIndex":'+str(p)+',"sort":"1","pageSize":20,"tab":"Ticket2","items":[]},"productOption":{"needBasicInfo":true,"needComment":true,"needPrice":true,"needRanking":true,"needVendor":true,"tagOption":["PRODUCT_TAG","IS_AD_TAG","PROMOTION_TAG","FAVORITE_TAG","GIFT_TAG","COMMENT_TAG","IS_GLOBALHOT_TAG"]},"searchOption":{"filters":[],"needAdProduct":true,"returnMode":"all","needUpStream":false},"extras":{},"debug":false,"contentType":"json","client":{"pageId":"10650038368","platformId":null,"crnVersion":"2021-04-22 16:45:08","location":{"cityId":null,"cityType":null,"locatedCityId":null,"lat":"","lon":""},"locale":"zh-CN","currency":"CNY","channel":114,"cid":"09031023413294183609","trace":"943fec20-13b5-7e20-a1a1-12f162815722","extras":{"client_districtId":"'+str(id)+'","client_locatedDistrictId":"0"}}}'
response = requests.post('https://m.ctrip.com/restapi/soa2/20684/json/productSearch', headers=headers,
data=data)
因此我在这一部分选择了selenium模拟用户:
options = Options()
options.add_argument('--headless')
self.chrome = Chrome(executable_path='D:\\py\\aaaaaaaaa\\selenuim\\chromedriver.exe', options=options)
url = 'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=' + Ncity+keyword + '&id=' + str(self.getCityID(city)) + '&pshowcode=Ticket2'
self.chrome.get(url)
content = self.chrome.find_element_by_class_name('right-content-list').get_attribute('innerHTML')
cons = re.findall(r'href="(.*?)" title="(.*?)"', content)
如此就成功获取到网页内容。
6.爬取频繁导致封禁IP问题,采用IP代理:
def getHtml(self, url, host):
try:
appKey = "这里写key"
# 蘑菇隧道代理服务器地址
ip_port = '这是地址'
proxy = {"http": "http://" + ip_port, "https": "https://" + ip_port}
self.headers['User-Agent'] = mfu.UserAgent().random()
self.headers['Cookie'] = self.choseCookie()
self.headers['Proxy-Authorization'] = 'Basic ' + appKey
self.headers['Accept-Language'] = 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4'
#self.headers['Host'] = host
#self.headers['Referer'] = url
resp = requests.get(url, headers=self.headers, proxies=proxy, verify=False,
allow_redirects=False)
resp.raise_for_status()
resp.encoding = 'utf-8'
return resp.text
except:
return ""


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









