







MapReduce之Join多表查询实现
0.思路:
1、在map阶段注意区分读取进来的数据所属哪张表,需做判断进行区分
2、在reduce阶段注意对相同key的value进行处理,分别取出哪些是部门表和员工表的信息
3、编写Job类,设置mapper及输入输出
4、注意将emp.cvs和dept.csv放在同一个目录下
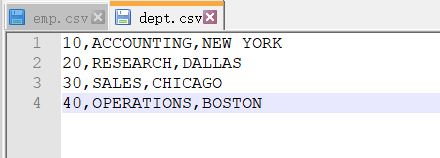
内容如下:

1.依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
2.添加log4j.properties文件在资源目录下即resources,文件内容如下
log4j.rootLogger=FATAL, dest1
log4j.logger.dsaLogging=DEBUG, dsa
log4j.additivity.dsaLogging=false
log4j.appender.dest1=org.apache.log4j.ConsoleAppender
log4j.appender.dest1.layout=org.apache.log4j.PatternLayout
log4j.appender.dest1.layout.ConversionPattern=%-5p:%l: %m%n
log4j.appender.dest1.ImmediateFlush=true
log4j.appender.dsa=org.apache.log4j.RollingFileAppender
log4j.appender.dsa.File=./logs/dsa.log
log4j.appender.dsa.MaxFileSize=2000KB
# Previously MaxBackupIndex=2
log4j.appender.dsa.MaxBackupIndex=5
log4j.appender.dsa.layout=org.apache.log4j.PatternLayout
log4j.appender.dsa.layout.ConversionPattern=%l:%d: %m%n
3.编写mapper类 EqualJoinMapper.java
package com.mr.jointable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class EqualJoinMapper extends Mapper<LongWritable, Text, IntWritable,Text> {
IntWritable key2 = new IntWritable();
Text value2 = new Text();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**数据结构:
* emp:7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
* dept:20,RESEARCH,DALLAS
*/
System.out.println("偏移量:" + key + ",value : " + value.toString());
//1、分词
String[] splits = value.toString().split(",");
//2、区别emp和dept
if (splits.length >= 8){ //读取的是emp表数据
String empName = splits[1];
String empDept = splits[7];
key2.set(Integer.parseInt(empDept));
value2.set(empName);
}else{ //读取是dept表的数据
String detpNo = splits[0];
String deptName = "*" + splits[1];//加*的目的是标识当前的数据是属于部门表里面的
key2.set(Integer.parseInt(detpNo));
value2.set(deptName);
}
//3、通过context写出去
context.write(key2,value2);
}
}
4.编写reducer类
package com.mr.jointable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class EqualJoinReducer extends Reducer<IntWritable,Text,Text,Text> {
Text key4 = new Text();
Text value4 = new Text();
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//从values中取出部门名称和员工的名称
String empNameList = "";
String deptName = "";
for (Text v: values) {
String data = v.toString();
int deptFlag = data.indexOf("*");
if (deptFlag != -1 ){//找到包含有*号的数据:部门名称 如*RESEARCH
deptName = data.substring(1);
}else{
empNameList = data + ";" + empNameList;
}
}
key4.set(deptName);
value4.set(empNameList);
context.write(key4,value4);
}
}
5.编写Job类
package com.mr.jointable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Random;
public class EqualJoinJob {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(EqualJoinJob.class);
//设置Mapper
job.setMapperClass(EqualJoinMapper.class);
job.setMapOutputKeyClass(IntWritable.class);//key2
job.setMapOutputValueClass(Text.class);//value2
//设置Reducer
job.setReducerClass(EqualJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//先使用本地文件做测试
FileInputFormat.setInputPaths(job,new Path("D:\\equaljoin\\"));
FileOutputFormat.setOutputPath(job,new Path(getOutputDir()));
boolean result = job.waitForCompletion(true);
System.out.println("result:" + result);
}
//用于产生随机输出目录
public static String getOutputDir(){
String prefix = "D:\\output_equaljoin\\";
long time = System.currentTimeMillis();
int random = new Random().nextInt();
return prefix + "result_" + time + "_" + random;
}
}
6.运行结果


















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











