






一.为什么要设计cookie池
1.很多网站要登陆才能访问(能不用cookie的网站就不用带cookie)
2.cookie会对应到账号,单个账号会受到访问频率的限制
3.设计cookie池:将模拟登陆单独做成一个服务,检测cookie有效性做成一个服务,爬虫做成一个服务,做到服务分离
4.使用redis组件可以使各个服务用不同的语言实现
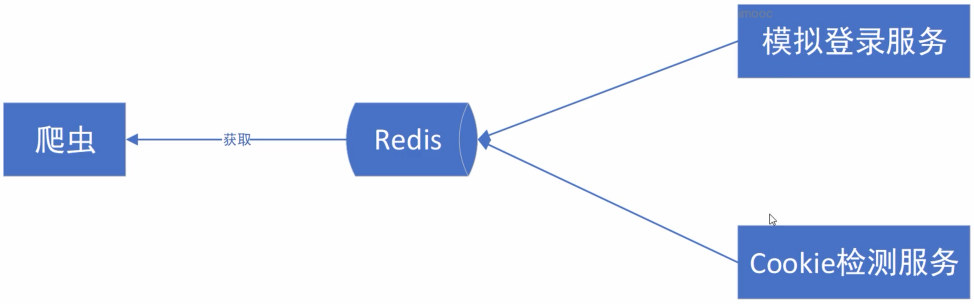
二.设计cookie池会面临的问题:
1.cookie池的合理大小
2.各个网站的cookie如何分开管理
3.如何及时发现cookie失效了
4.新加入的网站如何快速接入系统
三.以知乎为例,实现cookie池服务的建立
#抽象基类,强制子类重写登陆函数与检查cookie有效性函数
from services.base_service import BaseService
class ZhihuLoginService(BaseService):
name = "zhihu"
#数据统一放在构造函数中赋值,及放在对象自己的__dict__字典中
def __init__(self, settings):
self.user_name = settings.Accounts[self.name]["username"]
self.pass_word = settings.Accounts[self.name]["password"]
chrome_options = Options()
chrome_options.add_argument("--disable-extensions")
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
self.browser = webdriver.Chrome(executable_path="D:/c盘下载/chromedriver.exe",
options=chrome_options)
#检测是否登陆成功,找一个登陆后才有的原始,如果找不到证明没有登陆成功
def check_login(self):
try:
self.browser.find_element_by_css_selector(".Popover.PushNotifications.AppHeader-notifications")
return True
except Exception as e:
return False
#检测cookie的有效性,直接requests带上cookies去访问网站,能访问则代表cookie有效
def check_cookie(self, cookie_dict):
res = requests.get("https://www.zhihu.com/", headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"
}, cookies=cookie_dict, allow_redirects=False) #allow_redirects=False禁止重定向
if res.status_code != 200:
return False
else:
return True
#主方法:登陆以便获得cookie,以下为伪代码
def login(self):
import time
#判断是否登陆成功,如果成功就直接跳出循环,取cookies
while not self.check_login():
self.browser.get("https://www.zhihu.com/signin")
#选择用户密码登陆元素并点击
time.sleep(5)
login_element = self.browser.find_element_by_css_selector(".SignFlow-tabs div.SignFlow-tab")
login_element.click()
browser_navigation_panel_height = self.browser.execute_script('return window.outerHeight - window.innerHeight;')
time.sleep(5)
self.browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys(Keys.CONTROL + "a")
self.browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys(
self.user_name)
self.browser.find_element_by_css_selector(".SignFlow-password input").send_keys(Keys.CONTROL + "a")
self.browser.find_element_by_css_selector(".SignFlow-password input").send_keys(
self.pass_word)
self.browser.find_element_by_css_selector(
".Button.SignFlow-submitButton").click()
time.sleep(15)
print("判断登录是否成功")
if self.check_login():
break
"""
此处为处理中文/英文验证码等的逻辑
"""
# 等待登录成功后加载个人中心信息
time.sleep(10)
#跳出循环后取cookies
Cookies = self.browser.get_cookies()
print(Cookies)
cookie_dict = {}
for cookie in Cookies:
cookie_dict[cookie['name']] = cookie['value']
self.browser.close()
return cookie_dict
if __name__ == "__main__":
import settings
zhihu = ZhihuLoginService(settings) #类似scrapy,配置作为参数,从参数中取配置
cookie_dict = zhihu.login()
print(cookie_dict)
四.登陆服务之上的管理器
此处只写了一个知乎的登陆服务,如果有多个网站的服务,如何统一管理,确保每一个网站都会被单独运行
#1. cookie保存在redis中应该使用什么数据结构
#2. 数据结构应该满足: 1. 可以随机获取 2. 可以防止重复 - set
import json
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from functools import partial
import redis
#1. 如何确保每一个网站都会被单独的运行
class CookieServer():
def __init__(self, settings):
self.redis_cli = redis.Redis(host=settings.REDIS_HOST, port=settings.REDIS_PORT, decode_responses=True)
self.service_list = []
self.settings = settings
def register(self, cls):
self.service_list.append(cls)
def login_service(self, srv): # srv参数是一个服务类
while 1:
srv_cli = srv(self.settings)
srv_name = srv_cli.name
cookie_nums = self.redis_cli.scard(self.settings.Accounts[srv_name]["cookie_key"])
if cookie_nums < self.settings.Accounts[srv_name]["max_cookie_nums"]:
cookie_dict = srv_cli.login()
self.redis_cli.sadd(self.settings.Accounts[srv_name]["cookie_key"], json.dumps(cookie_dict))
else:
print("{srv_name} 的cookie池已满,等待10s".format(srv_name=srv_name))
time.sleep(10)
#celery
def check_cookie_service(self, srv): # srv参数是一个服务类
while 1:
print("开始检测cookie是否可用")
srv_cli = srv(self.settings)
srv_name = srv_cli.name
all_cookies = self.redis_cli.smembers(self.settings.Accounts[srv_name]["cookie_key"])
print("目前可用cookie数量: {}".format(len(all_cookies)))
for cookie_str in all_cookies:
print("获取到cookie: {}".format(cookie_str))
cookie_dict = json.loads(cookie_str)
valid = srv_cli.check_cookie(cookie_dict)
if valid:
print("cookie 有效")
else:
print("cookie已经失效, 删除cookie")
self.redis_cli.srem(self.settings.Accounts[srv_name]["cookie_key"], cookie_str)
# 设置间隔,防止出现请求过于频繁,导致本来没失效的cookie失效了
interval = self.settings.Accounts[srv_name]["check_interval"]
print("{}s 后重新开始检测cookie".format(interval))
time.sleep(interval)
def start(self):
task_list = []
print("启动登录服务")
login_executor = ThreadPoolExecutor(max_workers=5)
for srv in self.service_list:
task = login_executor.submit(partial(self.login_service, srv))
task_list.append(task)
print("启动cookie检测服务")
check_executor = ThreadPoolExecutor(max_workers=5)
for srv in self.service_list:
task = check_executor.submit(partial(self.check_cookie_service, srv))
task_list.append(task)
for future in as_completed(task_list):
data = future.result()
print(data)
#run.py
import settings
srv = CookieServer(settings)
#注册需要登录的服务
srv.register(ZhihuLoginService)
#启动cookie服务
print("启动cookie池服务")
srv.start()
五.爬虫服务直接从redis中取cookie
scrapy spider中从redis中随机获取一个cookie,并设置给request
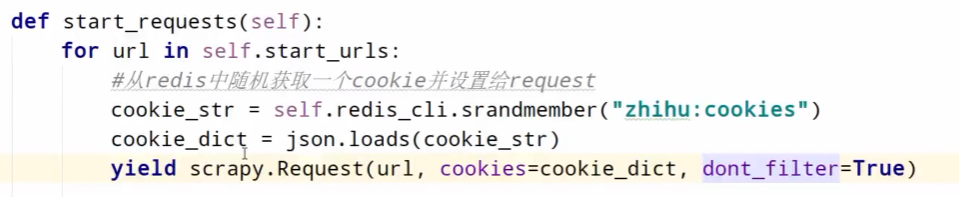
也可以参照user-agent,在middleware中设置cookie;
需要在custom_settings中对每一个爬虫单独设置middleware,因为每个网站的cookie不同,并且有些网站可以不带cookie进行访问.
六.改进
1.将获取cookie数据通过web框架的url来获取
2.通过celery,将模拟登陆和cookie检测做成定时任务
视频教程
相应的视频教程在这里 https://mp.weixin.qq.com/s/DG-T965Y9yKLwNYPus2cXA
本文由 mdnice 多平台发布















 2057
2057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









