






Rabbitmq--topic
一、前言
前面讲到direct类型的Exchange路由规则是完全匹配binding key与routing key,但这种严格的匹配方式在很多情况下不能满足实际业务需求。topic类型的Exchange在匹配规则上进行了扩展,它与direct类型的Exchage相似,也是将消息路由到binding key与routing key相匹配的Queue中,但这里的匹配规则有些不同,它约定:
- routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
- binding key与routing key一样也是句点号“. ”分隔的字符串
- binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
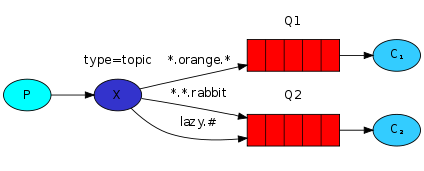
以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,routingKey=”lazy.orange.fox”的消息会路由到Q1与Q2,routingKey=”lazy.brown.fox”的消息会路由到Q2,routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。
二、Exchange topic
topic 和 direct 改动不多,就是routing key 和bind key 需要改一下
生产端:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# -*- coding: UTF-8 -*-
import
pika
# 创建一个连接
connection
=
pika.BlockingConnection(pika.ConnectionParameters(
host
=
'localhost'
))
# 创建一个管道
channel
=
connection.channel()
# 声明exchange 及类型
channel.exchange_declare(exchange
=
'topic_log'
,
exchange_type
=
'topic'
)
# 输入信息,格式为 *.info from *.info test 类似
input_data
=
input
(
'>>:'
).strip()
# 将输入的信息以空格为分割,转换为列表
data_list
=
input_data.split(
' '
)
# 三元运算,如果输入信息存在,就使用输入的信息data_list[0],否则用 'anonymous.info'
severity
=
data_list[
0
]
if
len
(data_list) >
1
else
'anonymous.info'
message
=
' '
.join(data_list[
2
:])
or
'hello,world!'
# 这里的routing_key就是 data_list[0] 或 'info'
channel.basic_publish(exchange
=
'topic_log'
,
routing_key
=
severity,
body
=
message)
print
(
'[x] Sent %r:%r'
%
(severity, message))
connection.close()
|
消费端:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# -*- coding: UTF-8 -*-
import
pika
connection
=
pika.BlockingConnection(pika.ConnectionParameters(
host
=
'localhost'
))
channel
=
connection.channel()
# 声明exchange 及类型
channel.exchange_declare(exchange
=
'topic_log'
,
exchange_type
=
'topic'
)
result
=
channel.queue_declare(exclusive
=
True
)
queue_name
=
result.method.queue
# 在此我们定义一些列表,列表内容如下
# 这2个列表分别用来测试和routing_key匹配情况
# 第一种只允许接收info的信息
# 第二种允许接收error 和 mysql的信息
# severities = ['*.info']
severities
=
[
'*.error'
,
'mysql.*'
]
for
severity
in
severities:
channel.queue_bind(exchange
=
'topic_log'
,
queue
=
queue_name,
routing_key
=
severity)
print
(
' [*] Waiting for logs. To exit press CTRL+C'
)
def
callback(ch, method, properties, body):
print
(
" [x] %r:%r"
%
(method.routing_key, body))
channel.basic_consume(callback,
queue
=
queue_name,
no_ack
=
True
)
channel.start_consuming()
|
我们测试时,分别启动两个consumer。
第一个consumer1 中使用 severities = ['*.info']
第二个consumer2中使用 severities = ['*.error', 'mysql.*']
生产者分别输入:
|
1
2
3
4
5
|
appache.info
from
appache info test
nginx.error
from
nginx error test
mysql.info
from
mysql info test
|
可以看到日志信息分别会汇总到两个consumer中, 其中 consumer1 会收到 appache.info 和 mysql.info的信息, 而 consumer2 会收到 nginx.error 和 mysql.info 的信息。

















 1130
1130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










【前端】SpreadJS表格控件,可嵌入系统开发的在线Excel
【培训】阿里P8面试官:什么样的人能进阿里
【推荐】程序员问答平台,解决您开发中遇到的技术难题
· rabbit channel参数
· RabbitMQ探索之路(一):RabbitMQ简介
· Rabbitmq-topic演示
· RabbitMQ消息队列(二)-RabbitMQ消息队列架构与基本概念
· 消息队列RabbitMQ
· 265年,571种植物灭绝
· 为我国光子集成注入强“芯”剂
· 投资人对锂矿没了兴趣,电动汽车行业受影响?
· 量子计算机的性能何时能超越传统计算机?
· 一初创公司开发廉价自动驾驶传感器:最低不到500美元
» 更多新闻...