






本文转自浅析敏感词过滤算法(C++),自己也在其基础上根据自己的情况做了一点修改。
https://blog.csdn.net/u012755940/article/details/51689401?utm_source=app
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个WordNode。
比如敏感词库里面有枪手、手枪这几个词,读入后就变成了如下图所示的树状结构。
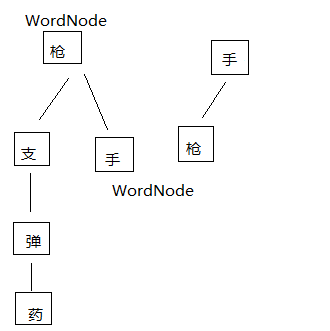
STL::map是按照operator<比较判断元素是否相同,以及比较元素的大小,然后选择合适的位置插入到树中。
下面主要实现了WordNode类,进行节点的插入以及查询。
WordNode.h
#ifndef __WORDNODE_H__ #define __WORDNODE_H__ #define PACE 1 #include <string> #include <map> #include <stdio.h> class CWordNode { public: CWordNode(std::string character); CWordNode(){ m_character = ""; }; ~CWordNode(); std::string getCharacter() const{ return m_character; }; CWordNode* findChild(std::string& nextCharacter); CWordNode* insertChild(std::string& nextCharacter); private: friend class CWordTree; typedef std::map<std::string, CWordNode> _TreeMap; typedef std::map<std::string, CWordNode>::iterator _TreeMapIterator; std::string m_character; _TreeMap m_map; CWordNode* m_parent; }; #endif
WordNode.cpp
#include "WordNode.h" using namespace std; CWordNode::~CWordNode() { } CWordNode::CWordNode(std::string character) { if (character.size() == PACE) { m_character.assign(character); } } CWordNode* CWordNode::findChild(std::string& nextCharacter) { _TreeMapIterator TreeMapIt = m_map.find(nextCharacter); if (TreeMapIt == m_map.end()) { return NULL; } else { return &TreeMapIt->second; } } CWordNode* CWordNode::insertChild(std::string& nextCharacter) { if (!findChild(nextCharacter)) { m_map.insert(pair<std::string, CWordNode>(nextCharacter, CWordNode(nextCharacter))); return &(m_map.find(nextCharacter)->second); } return NULL; }
另外,
#define PACE 1这里的PACE原本是2,因为一个GBK汉字占两个字符,而且原文中也说了如果需要考虑英文或中英文结合的情况,将PACE改为1。
不过我试过之后,觉得不管是中文、英文还是中英文,PACE为 1 都适用,结果都没错,只不过中文的情况下每个节点的string都不再是一个完整的汉字,而是汉字的一个字符。
接下来实现这个tree,在建立WordNode树时,以parent为根节点建立,一开始parent为m_emptyRoot,然后keyword按照规则添加到树中,假设一开始m_emptyRoot为空,keyword为”敏感词”,则会以”敏感词”为一条分支建立成为一颗树枝’敏’->’感’->’词’,此后,若想再添加”敏感度”,由于”敏感词”与”敏感度”的前两个字相同,则会在’敏’->’感’->’词’的基础上,从字’感’开始新生长出一颗分支,即’敏’->’感’->’度’,这两颗分支共用’敏’->’感’。
下面代码实现了WordTree类,进行树的构成及查询。
WordTree.h
#ifndef __WORDTREE_H__ #define __WORDTREE_H__ #include "WordNode.h" class CWordTree { public: CWordTree(); ~CWordTree(); int nCount; CWordNode* insert(std::string &keyWord); CWordNode* insert(const char* keyword); CWordNode* find(std::string& keyword); private: CWordNode m_emptyRoot; int m_pace; CWordNode* insert(CWordNode* parent, std::string& keyword); CWordNode* insertBranch(CWordNode* parent, std::string& keyword); CWordNode* find(CWordNode* parent, std::string& keyword); }; #endif // __WORDTREE_H__
WordTree.cpp
#include "WordTree.h" CWordTree::CWordTree() :nCount(0) { } CWordTree::~CWordTree() { } CWordNode* CWordTree::insert(std::string &keyWord) { return insert(&m_emptyRoot, keyWord); } CWordNode* CWordTree::insert(const char* keyWord) { std::string wordstr(keyWord); return insert(wordstr); } CWordNode* CWordTree::insert(CWordNode* parent, std::string& keyWord) { if (keyWord.size() == 0) { return NULL; } std::string firstChar = keyWord.substr(0, PACE); CWordNode* firstNode = parent->findChild(firstChar); if (firstNode == NULL) { return insertBranch(parent, keyWord); } std::string restChar = keyWord.substr(PACE, keyWord.size()); return insert(firstNode, restChar); } CWordNode* CWordTree::find(std::string& keyWord) { return find(&m_emptyRoot, keyWord); } CWordNode* CWordTree::find(CWordNode* parent, std::string& keyWord) { std::string firstChar = keyWord.substr(0, PACE); CWordNode* firstNode = parent->findChild(firstChar); if (firstNode == NULL) { nCount = 0; return NULL; } std::string restChar = keyWord.substr(PACE, keyWord.size()); if (firstNode->m_map.empty()) { return firstNode; } if (keyWord.size() == PACE) { return NULL; } nCount++; return find(firstNode, restChar); } CWordNode* CWordTree::insertBranch(CWordNode* parent, std::string& keyWord) { std::string firstChar = keyWord.substr(0, PACE); CWordNode* firstNode = parent->insertChild(firstChar); if (firstNode != NULL) { std::string restChar = keyWord.substr(PACE, keyWord.size()); if (!restChar.empty()) { return insertBranch(firstNode, restChar); } } return NULL; }
最后就是利用上述的Tree来实现敏感词过滤,WordFilter::censor(string &source) 函数用来进行敏感词过滤,source即输入的字符串,如果source包含敏感词,则用“**”替代掉。
WordFilter::load(const char* filepath) 函数通过文件载入敏感词,并构建WordTree,这里我用的是txt文件。
下面实现了WordFilter类。
WordFilter.h
#ifndef __WORDFILTER_H__ #define __WORDFILTER_H__ #include "WordTree.h" #include "base/CCRef.h" USING_NS_CC; class CWordFilter : public Ref { public: ~CWordFilter(); bool loadFile(const char* filepath); bool censorStr(std::string &source); bool censorStrWithOutSymbol(const std::string &source); static CWordFilter* getInstance(); static void release(); private: std::string string_To_UTF8(const std::string & str); std::string UTF8_To_string(const std::string & str); CWordFilter(); static CWordFilter* m_pInstance; CWordTree m_WordTree; }; #endif // __WORDFILTER_H__
WordFilter.cpp
#include "WordFilter.h" #include <ctype.h> #include <algorithm> #include <iostream> #include <fstream> #include <istream> using namespace std; USING_NS_CC; CWordFilter* CWordFilter::m_pInstance = nullptr; CWordFilter::CWordFilter() { } CWordFilter::~CWordFilter() { } CWordFilter* CWordFilter::getInstance() { if (m_pInstance == NULL) { m_pInstance = new CWordFilter(); } return m_pInstance; } void CWordFilter::release() { if (m_pInstance) { delete m_pInstance; } m_pInstance = NULL; } bool CWordFilter::loadFile(const char* filepath) { ifstream infile(filepath, ios::in); if (!infile) { return false; } else { string read; while (getline(infile, read)) { #if (CC_TARGET_PLATFORM == CC_PLATFORM_ANDROID || CC_TARGET_PLATFORM == CC_PLATFORM_IOS) string s; s = read.substr(0, read.length() - 1); m_WordTree.insert(s); #else m_WordTree.insert(read); #endif } } infile.close(); return true; } bool CWordFilter::censorStr(string &source) { int lenght = source.size(); for (int i = 0; i < lenght; i += 1) { string substring = source.substr(i, lenght - i); if (m_WordTree.find(substring) != NULL) { source.replace(i, (m_WordTree.nCount + 1), "**"); lenght = source.size(); return true; } } return false; } bool CWordFilter::censorStrWithOutSymbol(const std::string &source) { string sourceWithOutSymbol; int i = 0; while (source[i] != 0) { if (source[i] & 0x80 && source[i] & 0x40 && source[i] & 0x20) { int byteCount = 0; if (source[i] & 0x10) { byteCount = 4; } else { byteCount = 3; } for (int a = 0; a < byteCount; a++) { sourceWithOutSymbol += source[i]; i++; } } else if (source[i] & 0x80 && source[i] & 0x40) { i += 2; } else { i += 1; } } return censorStr(sourceWithOutSymbol); }
这里说明一点,本人是做Cocos2d-x手游客户端开发的,程序是要移植到安卓或者iOS平台上。当逐行读取txt文件中的敏感词并构成树的时候,getline(infile, read)函数得到的read字符串后面带有结束符,比如“枪手\0”,这时跟我们需要检测的字符串“…枪手…”就明显不符合,这是检测不出来的。这种情况我现在只知道在安卓或者iOS平台存在,而在windows环境下VS中是不会出现这种问题的。所以我对读取到的字符串做了处理,把最后一个字符也就是结束符去掉,再进行下一步操作。
而我使用的是lua,lua发送给C++的字符串都是用utf-8编码的,所以再去除字符串的时候并不能简答的使用(a & 0x80)来判断














 2403
2403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









