







此脚本用于下载apache文件服务器中制定某个文件夹下所有文件与文件夹。
包含下载单个文件的方法、拼接url递归下载的方法、参数解析。
1 下载文件
功能点:
- 文件下载
以追加写的方式打开一个新文件,按照块大小写入文件
with open(filepath, 'wb') as file: # 显示进度条
for data in response.iter_content(chunk_size=1024):
file.write(data)
- 文件大小
content_size = int(response.headers['content-length'])
- 下载计时
这个简单,不做概述。 - 下载进度
转义符\r代表回车,也就是打印头归位,(光标)回到当前行的开头。
那么打印进度时,在前面加上该转义符,进度条则会覆盖住当前打印行,即可实现进度条刷新
print('\r'+"进度条:>>>")
print('\r'+"进度条:>>>>>")
print('\r'+"进度条:>>>")

2 下载链接
功能点:正则获取html中文件链接、拼接各级路径
由于apache文件服务器页面以html输出,且各文件、文件夹链接地址为相对地址,所以在解析html文件后,仍需对链接进行拼接。
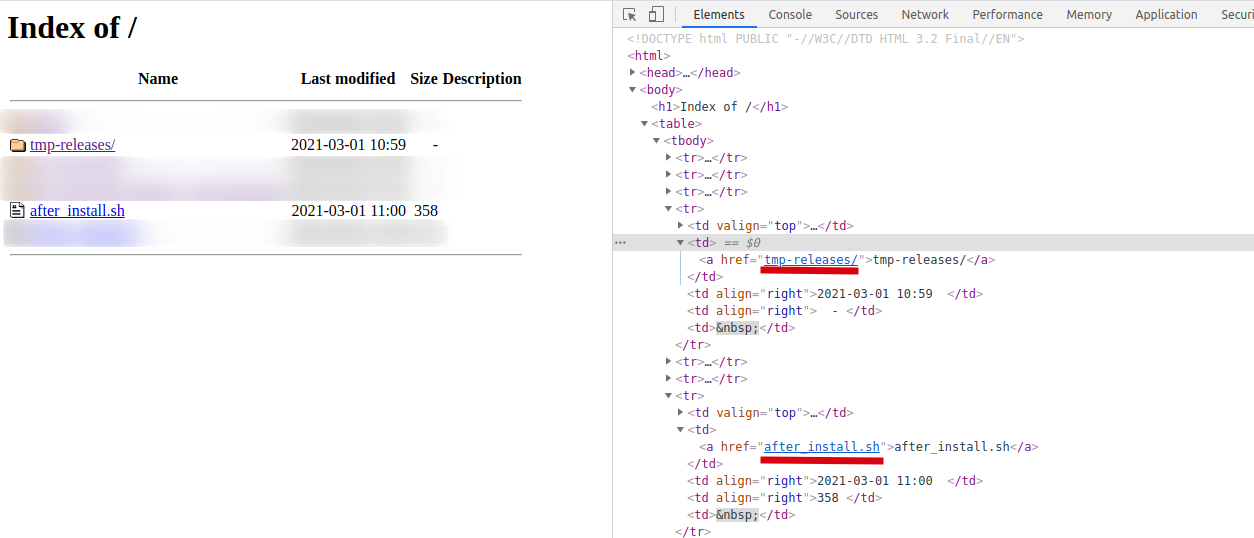
根据网页结构,目录的链接以/结束,则可以此为判断依据。
- 获取链接
response = requests.get(root_url).text
urls = re.findall(r'<td><a href="(.*?)">', response, re.S | re.M)
- 拼接
# 判断链接不是目录,是文件则调用下载方法,root_url是当前请求路径,url是文件名
if not url.endswith('/'):
tm += download_file(root_url+url, download_dir+url)
continue # 跳过当前循环
# 至此,url只能是目录
# root_url拼接下一级目录url,递归调用当前获取url的方法
3 参数读取
模仿终端中大部分命令的执行方式,以--参数名=参数值的方法进行参数的传递。
思路: 构建参数字典,将参数以等号分割,去除左边的短横&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









