







本节及后续章节将介绍机器学习中的几种经典回归算法,包括线性回归,多项式回归,以及正则项的岭回归等,所选方法都在Sklearn库中聚类模块有具体实现。本节为上篇,将介绍基础的线性回归方法,包括一元线性回归和多元线性回归等。
2.1 回归分析概述
回归(Regression)分析是机器学习领域中最古老、最基础,同时也是最广泛应用的问题之一,应用十分广泛。
简而言之,回归分析旨在建立一个模型,使用这个模型可以用一组特征(自变量)来预测一个连续的结果(因变量)。举一个容易理解的例子,我们可以使用房间的面积、楼层、位置、周边配套等特征来预测该商品房的房价高低,在这个例子中,房价是因变量,且是连续变化的,可以在一定非负区间内取任何实数值,而影响房价的各个因素,成为自变量,自变量可以是各种类型的值,但为了回归分析方便,通常将自变量也转换为数值类型。
2.1.1 回归与分类
回归问题是预测一个连续值的输出(因变量)基于一个或多个输入(自变量或特征)的机器学习任务。换句话说,回归模型尝试找到自变量和因变量之间的内在关系。
回归和分类是两类典型的监督学习问题,两者的主要区别在于输出类型和评价指标不同,如下:
- 输出类型:回归模型通常用来预测连续值(如价格、温度等),分类模型用来预测离散标签(如0/1)。
- 评估指标:回归通常使用均方误差(MSE)、R²分数等作为评估指标,而分类则使用准确率、F1分数等。
2.1.2 常见的回归方法
在此主要介绍Sklearn中实现的几类典型的回归方法,
- 线性回归:线性回归是回归问题中最简单也最常用的一种算法。它的基本思想是通过找到最佳拟合直线来模拟因变量和自变量之间的关系。
- 多项式回归:与线性回归尝试使用直线拟合数据不同,多项式回归使用多项式方程进行拟合。
- 支持向量回归:它是支持向量机(SVM)的回归版本,用于解决回归问题。它试图找到一个超平面,以便在给定容忍度内最大程度地减小预测和实际值之间的误差。
- 决策树回归:它是一种非参数的、基于树结构的回归方法。它通过将特征空间划分为一组简单的区域,并在每个区域内进行预测。
回归算法全解析!一文读懂机器学习中的回归模型-腾讯云开发者社区-腾讯云 (tencent.com)
2.2 线性回归
线性回归,顾名思义,其目标值(对应因变量)可以看作是各个特征值(对应自变量)的线性组合。
线性回归模型的有效性建立在以下关键假设之上:
- 线性关系:因变量与自变量间存在线性关系。
- 独立性:观测值之间应相互独立。
- 无多重共线性:模型中的任何一个自变量都不应该是其他自变量的精确线性组合。
- 同方差性:对于所有的观测值,误差项的方差应相等。
- 误差项的正态分布:误差项应呈正态分布。
上述假设确保了线性回归模型能够提供可靠的预测和推断。
下图列出的是与线性回归相关的思维导图。

经典的线性回归数学模型可用下式描述:
这显然是一条直线方程,其中,表示预测值,
为系数,而
为斜率。
这个模型的关键在于找到最适合数据的值,使得模型能够准确预测因变量的值。
2.2.1 一元回归
(1)数学模型
当只有一个独立的特征变量时,此时的线性回归模型简化为一元线性回归。可用下式描述:
(2)Sklearn函数
Sklearn使用LinearRegression函数完成线性模型的拟合。所使用的准则是“最小均方误差”准则,即是使观测数据与预测数据之间的均方误差取得最小值,用数学表达式表示就是:
以下是该函数的声明:
看一下LinearRegression函数的声明:
sklearn.linear_model.LinearRegression(*, fit_intercept=True, copy_X=True, n_jobs=None, positive=False)
部分参数说明:
- fit_intercept:是否计算该模型的截距,默认为True。如果使用中心化的数据,可以考虑设置为False,即不计算截距。
- copy_X:是否对X进行复制,默认为True。如果设为False,在运行过程中新数据会覆盖原数据。
- n_jobs:处理时设置任务个数,默认值为None。该参数对于目标个数大于1,且足够大规模的问题有加速作用,如果设置为-1,则代表使用所有的CPU。
- positive:默认为False,如果设为Ture,则将各个系数强制设为正数。
属性值:
- coef_:拟合得到的系数值。如果是单目标问题,返回一个以为数组;如果是多目标问题,返回一个二维数组。
- rank_:矩阵X的秩,仅X为稠密矩阵时有效。
- singular_:矩阵X的奇异值,仅X为稠密矩阵时有效。
- intercept_:截距,线性模型中的独立项,如果fit_intercept设为False,则intercept_值为0。
该函数在使用时,调用了以下函数:
- fit:用于模型训练
- get_params:获取估计器的参数值
- set_params:设置估计器的参数
- predict:模型预测
- score:模型评估
其中,fit函数用于模型的训练其,其声明如下:
fit(X, y, sample_weight=None)
部分参数说明:
- X:训练数据(特征值)。
- y:目标值。
- sample_weight:默认为None,没个样本单独的权重。
(3)实例
本节将介绍如何使用LinearRegression函数实现对线性拟合的一个实例,该实例来自Sklearn官网,详细介绍见代码的注释。
# 栽入必要的库
import matplotlib.pyplot as plt
import numpy as np
# 加载必要的函数
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# 栽入“糖尿病”数据集
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# 只使用一个特征
diabetes_X = diabetes_X[:, np.newaxis, 2]
# 将数据分为训练集和测试集
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# 讲过目标分为训练集和测试集
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# 创建线性回归对象
regr = linear_model.LinearRegression()
# 用训练集训练模型
regr.fit(diabetes_X_train, diabetes_y_train)
# 使用测试集进行预测
diabetes_y_pred = regr.predict(diabetes_X_test)
# 显示结果,包括系数,均方差,r2数等
print("Coefficients: \n", regr.coef_)
print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred))
# 绘制输出结果
plt.scatter(diabetes_X_test, diabetes_y_test, color="black")
plt.plot(diabetes_X_test, diabetes_y_pred, color="blue", linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()输出结果为:
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Coefficient of determination: 0.47
下图展示了拟合结果,其中黑色点代表测试数据点,蓝线表示拟合出的直线。
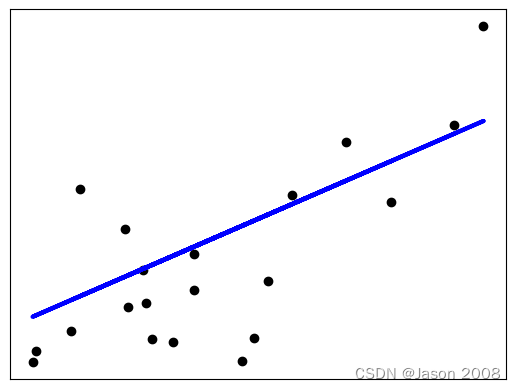
官网给出的实例,有些复杂。下面给出一个简单直观的例子。
对于下表所示一组含有10个样本点的数据。
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| x | 10.0 | 8.0 | 13.0 | 9.0 | 11.0 | 14.0 | 6.0 | 4.0 | 12.0 | 7.0 | 5.0 |
| y | 8.04 | 6.95 | 7.58 | 8.81 | 8.33 | 9.96 | 7.24 | 4.26 | 10.84 | 4.82 | 5.68 |
以下是使用Sklearn的LinearRegression函数进行模型估计的过程,主要分为三步:
- 加载必要的库函数和数据(可能需要预处理);
- 创建模型,调用fit函数,完成模型的估计;
- 显示参数,并使用新的数据进行预测。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
X = [[10.0], [8.0], [13.0], [9.0], [11.0], [14.0], [6.0], [4.0], [12.0], [7.0], [5.0]]
y = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]
model = LinearRegression()
model.fit(X, y)
print("Intercept: \n", model.intercept_) # 截距
print("Coefficient: \n", model.coef_) # 斜率
y_pred = model.predict([[0], [1]])
print(y_pred) # 对x=0, x=1的预测结果下面是输出结果:
Intercept: 3.0000909090909103 Coefficient: [0.50009091] [3.00009091 3.50018182]
2.2.2 多元线性回归
当独立特征变量的数目大于一个时,此时线性回归成为多元线性回归。下表给出了一元和二元线性回归的模型对比。

多元线性回归虽然模型与一元线性回归不同,但在Sklearn中是使用同一个函数完成模型估计的,实现步骤基本一致,在此不再赘述。
(本节初稿完成时间:2024-07-08)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









