







1. 单选题
1. 假设把整数关键码K散列到N个槽列表,以下哪些散列函数是好的散列函数
A: h(K)=K/N;
B: h(K)=1;
C: h(K)=K mod N;
D: h(K)=(K+rand(N)) mod N, rand(N)返回0到N-1的整数
参考答案:D
2. 下面排序算法中,初始数据集的排列顺序对算法的性能无影响的是:
A: 堆排序 B:插入排序
C: 冒泡排序 D:快速排序
参考答案:A
3. 下面说法错误的是:
A: CISC计算机比RISC计算机指令多
B: 在指令格式中,采用扩展操作码设计方案的目的是为了保持指令字长不变而增加寻址空间
C:增加流水线段数理论上可以提高CPU频率
D:冯诺依曼体系结构的主要特征是存储程序的工作方式
参考答案:B
解释:指令操作码分为三种:定长操作码,霍夫曼操作码和扩展操作码,采用扩展操作码可以使得指令字长不变的情况下,尽可能多的表示更多的指令。
原因 扩展操作码的设计方案目的是保持指令字长度不变而增加指令操作的数量
4. 不属于冯诺依曼体系结构必要组成部分是:
A:CPU B: Cache C:RAM D:ROM
参考答案:应该是选cache
5. 一个栈的入栈序列式ABCDE则不可能的出栈序列是:
A:DECBA B:DCEBA C:ECDBA D:ABCDE
参考答案:C
6.你认为可以完成编写一个C语言编译器的语言是:
A:汇编 B:C语言 C:VB D:以上全可以
参考答案:我认为选D,编译器的目的就是把编程语言编译成为汇编语言或者机器语言,主要是词法分析,语法分析,语义分析,编译原理这门课程的时候曾经用c语言实现过编译器的部分功能,而设想没有c语言,那么第一c程序跑起来的编译器肯定用汇编语言写的,所以应该是全部
7. 关于C++/JAVA类中的static成员和对象成员的说法正确的是:
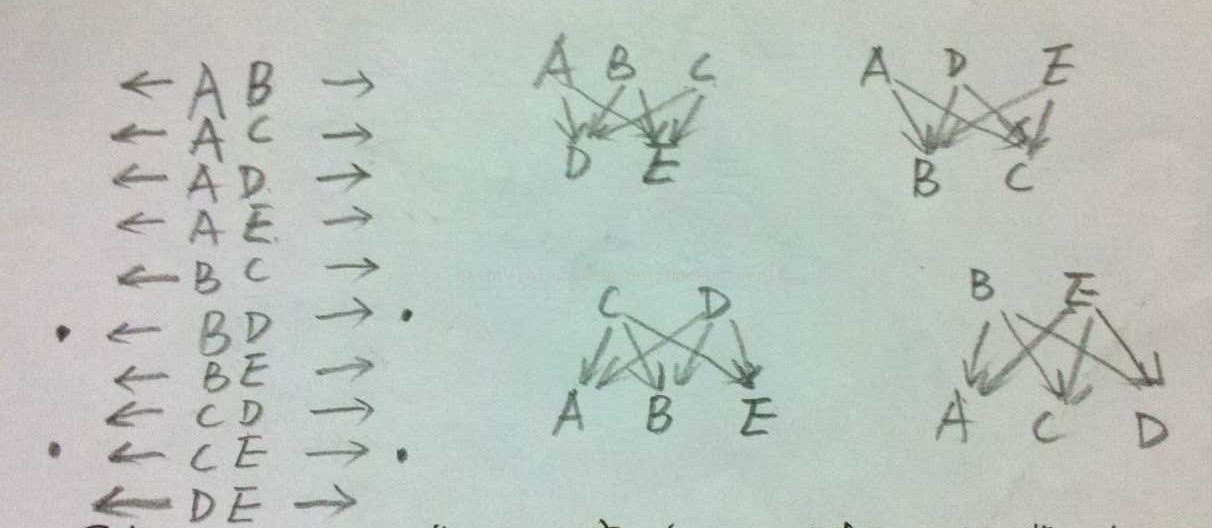
A:static成员变量在对象构造时候生成
B: static成员函数在对象成员函数中无法调用
C: 虚成员函数不可能是static成员函数
D: static成员函数不能访问static成员变量
参考答案:C
转载请注明出处:csdn-zhlfox2006
8:


参考答案:C,13个
9:某进程在运行过程中需要等待从磁盘上读入数据,此时进程的状态将:
A: 从就绪变为运行 B:从运行变为就绪
C: 从运行变为阻塞 D:从阻塞变为就绪
参考答案:c
10:下面算法的时间复杂度为:
Int f(unsigned int n)
{
If(n==0||n==1)
Return 1;
Else
Return n*f(n-1);
}
A: O(1) B:O(n) C:O(N*N) D:O(n!)
参考答案:B,题目算得是n!,但是复杂度确实O(n)
转载请注明出处:csdn-zhlfox2006
11: n从1开始,每个操作可以选择对n加1或者对n加倍。若想获得整数2013,最少需要多少个操作。
A:18 B:24 C:21 D;不可能
参考答案: A,18个完美解决,方法也很简单,尽量对2013用除法,显示2013->2012->1006->503->502->251->250->125->124->62->31->30->15->14->7->6->3->2->1
正向只能是+1和×2,所以逆向只能-1和/2,由上过程可得18次
12:对于一个具有n个顶点的无向图,若采用邻接表数据结构表示,则存放表头节点的数组大小为:
A: n B: n+1 C: n-1 D:n+边数
参考答案:A
13:

参考答案:对于几何中的每个字符串取hash可以看作是同分布的独立重复事件,所以每一个事件出现10的概率都是p=1/1024,那么当出现的时候,期望的次数就是1/p,1024.
14:如下函数,在32bit系统foo(2^31-3)的值是:
Int foo(int x)
{
Return x&-x;
}
A: 0 B: 1 C:2 D:4
参考答案:C,首先-号比^的优先级高,所以实参应该是2^28,而C++中并没有幂指数的运算符,这个^只表示异或运算,所以实参的二进制值,
x 的值为 11111111111111111111111111111110-011 = 01111111111111111111111111111101
-x 的值为 0-x = 0- 01111111111111111111111111111101 = 10000000000000000000000000000010
即为2。
所以答案为C
15:对于顺序存储的线性数组,访问节点和增加节点删除节点的时间复杂度为:
A: O(n),O(n) B:O(n),O(1) C:O(1),O(n) D:O(n),O(n)
参考答案:C
16:在32为系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是:
Struct A
{
Int a;short b;int c;char d;
};
Struct B
{int a;short b;char c;int c;};
A: 16,16 B:13,12 C:16,12 D:11,16
参考答案:C
17:袋中有红球,黄球,白球各一个,每次任意取一个放回,如此连续3次,则下列事件中概率是8/9的是:
A: 颜色不全相同 B:颜色全不相同C:颜色全相同D:颜色无红色
参考答案:A
解释:由于颜色任一颜色相同的概率为1/27
颜色无红色的概率为2/3×2/3×2/3=8/27
颜色全部相同的概率为1/9
颜色都不同,概率为3×1/3×2×1/3×1/3=2/9
颜色不全相同为8/9
18:一个洗牌程序的功能是将n张牌的顺序打乱,以下关于洗牌程序的功能定义说法最恰当的是:
A: 每张牌出现在n个位置上的概率相等
B: 每张牌出现在n个位置上的概率独立
C: 任何连续位置上的两张牌的内容独立
D: n张牌的任何两个不同排列出现的概率相等
参考答案:A
解释,创新工场笔试题让设计一个shuffle算法的时候就是特意提到,每张牌出现在任意位置的概率相等。
19:用两种颜色去染排成一个圈的6个棋子,如果通过旋转得到则只算一种,一共有多少种染色:
A: 10 B:11 C:14: D:15
参考答案:C
解释:应该有14种方案,设只有黑白两色,默认白色,那么,用p(n)表示有n个黑棋的种类
p(0)=p(6)=1
p(1)=p(5)=1
p(2)=p(4)=3 //相邻的一种,隔一个的一种,两个的一种
p(3)=4 //都相邻的一种,BB0B的一种,BB00B的一种,B0B0B的一种,一共4种
综上是14种
20:递归式的先序遍历一个n节点,深度为d的二叉树,则需要栈空间的大小为:
A: O(n) B:O(d) C:O(logn) D:(nlogn)
参考答案:B
解释:因为二叉树并不一定是平衡的,也就是深度d!=logn,有可能d》》logn。。所以栈大小应该是O(d)
第二部分:多选
21:两个线程运行在双核机器上,每个线程主线程如下,线程1:x=1;r1=y;线程2:y=1;r2=x;
X和y是全局变量,初始为0。以下哪一个是r1和r2的可能值:
A: r1=1,r2=1
B: r1=1,r2=0
C:r1=0,r2=0
D:r1=0,r2=1
参考答案:ABD
22.关于Linux系统的负载,以下表述正确的是:
A: 通过就绪和运行的进程数来反映
B: 通过TOP命令查看
C: 通过uptime查看
D: Load:2.5,1.3,1.1表示系统的负载压力在逐渐变小
参考答案:BC
23:关于排序算法的以下说法,错误的是:
A: 快速排序的平均时间复杂度O(nlogn),最坏O(N^2)
B:堆排序平均时间复杂度O(nlogn),最坏O(nlogn)
C:冒泡排序平均时间复杂度O(n^2),最坏O(n^2)
D:归并排序的平均时间复杂度O(nlogn),最坏O(n^2)
答案: D
24:假设函数rand_k会随机返回一个【1,k】之间的随机数(k>=2),并且每个证书出现的概率相等。目前有rand_7,通过调用rand_7()和四则运算符,并适当增加逻辑判断和循环控制逻辑,下列函数可以实现的有:
A:rand_3 B:rand_21 C:rand_23 D:rand_47
参考答案:ABCD
解释,对于rand_x(x<7)的直接截断,只要rand数大于x直接忽略,保证rand_x能够做到概率相等。而对于其他的则采用7×rand_7+rand_7,可以-7得到rand_49,然后截断成rand_42,统一除以2,则是rand_21,其他类似。多谢@plylw456 提醒。
鉴于大家对这道题的解释看得不太清,我就在此展开解释一下:
首先分析:7×rand_7+rand_7
1. 首先它是由两个随机变量组成,亦即7X+Y,只不过X与Y是独立同分布的而已,所以上式子表示为Z=7X+Y
那么对于随机变量X,你可以理解为它是一个“量级”的概念,X取值为1~7
当X=1时,随机变量Z取值范围是1*7+(1~7),也就是8~14
当X=2时,随机变量Z取值范围是2*7+(1~7),也就是15~21
当X=3时,随机变量Z取值范围是3*7+(1~7),也就是22~28
以此类推。。。
可以产生8~56的随机数。
那么产生的8~56的随机数,概率都相等吗?
答案是必然的,因为X是量级的概念,达到每个量级的概率是1/7,在量级内,Y达到1~7每个数的概率依然是1/7,所以8~56的每个数的概率都是1/49
好了我们可以得到1/49等概率的8~56,直接在生产的时候-7,得到等概率1/49的1~49.。。。。
好,现在只需要记住,得到rand_49,1~49的每个数都是等概率的就可以了,因为我们要截断,也就是说,为了得到rand_23直接截断,判断输出如果>23,直接忽略,否则输出,大家可能有点别扭,因为有的随机数生成的时候可能时间上要比其他的长点。但是要记住,1~23每个数输出的概率都是相等的,只不过不能保证每次输出时间都分秒不差而已。时间长短是跟概率无关的概念。
第三部分 填空与问答
25、某二叉树的前序遍历序列为-+a*b-cd/ef,后序遍历序列为abcd-*+ef/-,问其中序遍历序列是:
26、某缓存系统采用LRU淘汰算法,假定缓存容量为4,并且初始为空,那么在顺序访问以下数据项的时候,1、5、1、3、5、2、4、1、2,出现缓存直接命中的次数是(),最后缓存中即将准备淘汰的数据项是()
1
1,5
5,1 命中
5,1,3
1,3,5 命中
1,3,5,2
3,5,2,4 超过缓存容量上限,删除1
5,2,4,1
5,4,1,2 命中
所以答案就出来了,直接命中次数是3,最后缓存中准备淘汰的数据项是5
有例子 LRU(least recently used)最近最久未使用。 假设 序列为 4 3 4 2 3 1 4 2 物理块有3个 则 首轮 4调入内存 4 次轮 3调入内存 3 4 之后 4调入内存 4 3 之后 2调入内存 2 4 3 之后 3调入内存 3 2 4 之后 1调入内存 1 3 2(因为最近最久未使用的是4,从这里向前找最近最久未使用的) 之后 4调入内存 4 1 3(原理同上) 最后 2调入内存 2 4 1
27、有两个较长的单向链表a和b,为了找出节点node满足node in a 并且 node in b,请设计空间使用尽量小的算法。(用C/C++/JAVA或伪码表示都可以)
28、当存储数据量超出单节点数据管理能力的时候,可以采取的办法有数据库sharding的解决方案,也就是按照一定的规律把数据分散存储在多个数据管理节点N中(节点编号0.1.2...N-1)。假设存储的数据是a,请完成为数据a计算存储节点的程序。(没学过C语言的同学也可以用伪码完成)
- #define N 5
- int hash(int element)
- {
- return element*2654435761;
- }
- int shardingIndex(int a)
- {
- int p = hash(a);
- //1
- return p;
- }
29、宿舍内5个同学一起玩对战游戏,每场比赛有一些人作为红方,另一些人作为蓝方,请问至少需要多少场比赛,才能使任意两个人之间有一场红方对蓝方和一场蓝方对红方的比赛?
需要四场比赛即可 .
第一场 : 红方为 ABE, 蓝方为 CD
第二场 : 红方为 CDE, 蓝方为 AB
第三场 : 红方为 AC, 蓝方为 BDE
第四场 : 红方为 BD, 蓝方为 ACE
答案为4场。
第四部分 JAVA选做题
1、以下每个线程输出的结果是什么?(不用关注输出的顺序,只需写出输出的结果集即可)
2、一个有10亿条记录的文本文件,已按照关键字排好序存储,请设计算法,可以快速的从文件中查找关键字的记录。
有 10 亿条记录的文本文件存储在磁盘中 , 不能一次存入内存 , 所以讲10 亿条分为 N 份 , 然后顺序将第 N 份存入内存 , 对关键字进行哈希得到ID 号 , 然后进行二分法比较 , 如果不在这一份之中 , 那么需要将磁盘中的第二份导入内存 , 就这样进行计算 ~~
10亿在 G量级, 分成100份, 为10M量级, 基本上放入内存无压力了.
在这10亿记录中, 均分为100份, 把每份的第一条记录关键字和此记录对应的文件偏移量先扫入内存(类似索引), 这里需要磁盘随机io 100次.
这样可以马上定位出指定关键字所在的记录块, 把相应的记录块拿到内存, 二分查找即可.
C++选做题
Part I
假设你有一台计算机,配置如下:
48GB内存
16核CPU,3.0GHz
12块2TB SATA硬盘
有两个数据文件A和B,A的大小是40GB,B的大小是2TB,A和B的文件格式一样,都包含等长的100字节的记录,记录的前20个字节表示key,后80个字节表示value,所有的key和value都由数字和大小写字母组成(0-9 A-Z a-z),同一个文件中的key没有排序,也没有重复。
文件A和B都切成了1GB(1*10^9字节)的数据块(名为A000001、A000002......A000010、B000001、B000002......B002000),均匀分布在6块硬盘上。
请问如何用最快的方法找到A和B之间共同的key,以及他们对应的value值(建议输出格式如下所示:<key><空格><A中对应value><空格><B中对应value>)
相关题目:给定a,b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,
让你找出a、b文件共同的url.
每个文件:5Gx64 = 320G,所以不可能将其完全加载到内存中储粮,考虑采取分治法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取的值将url分别存储到1000个小文件
(记为a0, a1, ...., a999)中,这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式 将url分别存储到1000小文件(记为b0,..b999).这样处理后,所有可能相同的
url都在对应的小文件(a0vsb0, a1vsb1, ,,,,a999vs9999)中
不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了
请描述你的方法里面用到的关键的数据结构和算法,估算这个方法需要的内存空间和运算时间,并说明你的推导过程。
Part II
如果你有100台服务器,每台配置如上描述,它们通过千兆网络组成一个集群,任意两台之间的带宽可以达到1000Mbps,同时假设文件A和B的大小也放大100倍(各位4TB和200TB),并且被切分成1GB的碎片,均匀分布在100台服务器上。
请问如何用最快的方法找到A和B之间共同的key,以及他们对应的value值(建议输出格式如下所示:<key><空格><A中对应value><空格><B中对应value>)
请描述你的方法里面用到的关键的数据结构和算法,估算这个方法需要的内存空间、网络流和运算时间,并说明你的推导过程。















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









