







前言:
基于最近面试,两次被问到sparkstreaming消费kafka数据,程序突然退出怎么保证重新启动程序,数据不丢失和重复消费。因为项目本身也没怎么用到kafka这块,所以这个不是很清楚,以前也就让kafka默认管理offsets的方式,自动更新offsets到zookeeper。
1。我使用的软件及版本:apache-flume-1.6.0-bin,kafka_2.10-0.9.0.0,spark-1.5.0-bin-hadoop2.6
2。先整合Kafka和flume,其实可以自己写一个kafka的生产类,不过我配置了flume所以就使用了flume作为生产者
flume的配置文件:spool.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
//设置监控目录
a1.sources.r1.spoolDir =/data/spark/adxdata
a1.sources.r1.fileHeader = true
# Describe the sink
#a1.sinks.k1.type = logger
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ChinYouthD
a1.sinks.k1.brokerList = hadoop01:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume的命令将启动日子打印到flumespool.log:flume-ng agent -c . -f /data/app/apache-flume-1.6.0-bin/flumeconf/spool.conf -n a1 -Dflume.root.logger=INFO,console > flumespool.log 2>&1 &
3。先上一个kafak的消费demo。不做任何处理
import java.io.RandomAccessFile;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class KafkaOffset {
@SuppressWarnings("resource")
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Properties props = new Properties();
/* 定义kakfa 服务的地址,不需要将所有broker指定上 */
props.put("bootstrap.servers", "hadoop01:9092");
//props.put("zookeeper.connect","hadoop01:2181");
/* 制定consumer group */
props.put("group.id", "International");
/* 是否自动确认offset */
props.put("enable.auto.commit", "true");
/* 自动确认offset的时间间隔 */
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
/* key的序列化类 */
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
/* value的序列化类 */
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("advertised.listeners","PLAINTEXT://hadoop01:9092");
/* 定义consumer */
@SuppressWarnings("resource")
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
String context = null;
/* 消费者订阅的topic, 可同时订阅多个 */
consumer.subscribe(Arrays.asList("SprFestival"));
String fileName = "/Users/licao/Documents/tools/KafkaOffset.log";
System.out.println("begin");
while (true) {
//System.out.println(1);
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
RandomAccessFile randomFile = new RandomAccessFile(fileName, "rw");
long fileLength = randomFile.length();
randomFile.seek(fileLength);
if(record.value()!=null){
context ="offset "+"{ "+record.offset()+" } -- "+" value { "+ record.value()+" }";
System.out.println(context);
randomFile.writeBytes(context+"\r\n");
}
randomFile.close();
}
}
//bw.close();
}
} 将数据写入一个文件,方便检查程序退出,重启后。消费数据是否出现重复消费或数据丢失。经过观察,发现存在重复消费的情况,推测原因:数据已消费,Kafka还没来的及更新最新被消费数据的offsets。
4。作为对比,来一个将offsets持久化到mysql的demo
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import cn.db.SQLUtils;
public class kafkaManuOffset {
@SuppressWarnings({ "static-access", "resource" })
public static void main(String[] args) throws Exception {
SQLUtils su = new SQLUtils();
Properties props = new Properties();
String consumergroup = "Int";
String topic = "IntWor";
int partitions = 0;
props.put("bootstrap.servers", "hadoop01:9092");
props.put("metadata.broker.list", "hadoop01:2181");
props.put("group.id", "consumergroup");
/* 关闭自动确认选项 */
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
@SuppressWarnings("resource")
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
String fileName = "/Users/licao/Documents/tools/KafkaOffset.log";
String context = null;
consumer.subscribe(Arrays.asList(topic));
TopicPartition tp = new TopicPartition(topic, 0);
RandomAccessFile randomFile = null;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
//该方法,在重新启动后去mysql获取最新的offsets,+1 表示从下一条继续消费
consumer.seek(tp, su.getlastoffsets(consumergroup, topic, partitions)+1);
for (ConsumerRecord<String, String> record : records) {
try {
randomFile = new RandomAccessFile(fileName, "rw");
long fileLength = randomFile.length();
randomFile.seek(fileLength);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
context ="offset "+"{ "+record.offset()+" } -- "+" value { "+ record.value()+" }";
System.out.println(context);
randomFile.writeBytes(context+"\r\n");
//消费数据后,更新mayql里的offsets值
su.updateOffsets(consumergroup, topic, 0, record.offset());
//手动提交offset
consumer.commitSync();
}
}
}
} 该类可以解决重复消费的问题,需要注意的是要手动插入初始化数据到mysql里,也可以自己写程序插入
5.最后,最重要的sparkstearming整合kafaka出场。直接上code
package cn.rgyun.directStream
/**
* Created by licao on 17/6/5.
*/
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.common.TopicAndPartition
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.{SparkConf, SparkException}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.{KafkaUtils,HasOffsetRanges}
import scalikejdbc._
import com.typesafe.config.ConfigFactory
import scala.collection.JavaConverters._
class SprKafkaNew {
}
object SetupJdbc {
def apply(driver: String, host: String, user: String, password: String): Unit = {
Class.forName(driver)
ConnectionPool.singleton(host, user, password)
}
}
//主类
object SimpleApp{
def main(args: Array[String]): Unit = {
val conf = ConfigFactory.load
// 加载工程resources目录下application.conf文件,该文件中配置了databases信息,以及topic及group消息
val kafkaParams = Map[String, String](
"metadata.broker.list" -> conf.getString("kafka.brokers"),
"group.id" -> conf.getString("kafka.group"),
"serializer.class" -> "kafka.serializer.StringEncoder",
"enable.auto.commit" -> "true",
"auto.offset.reset" -> "smallest",
"zookeeper.connect" -> "hadoop01:2181")
val jdbcDriver = conf.getString("jdbc.driver")
val jdbcUrl = conf.getString("jdbc.url")
val jdbcUser = conf.getString("jdbc.user")
val jdbcPassword = conf.getString("jdbc.password")
val topic = conf.getString("kafka.topics")
val group = conf.getString("kafka.group")
val ssc = setupSsc(kafkaParams, jdbcDriver, jdbcUrl, jdbcUser, jdbcPassword,topic, group)()
ssc.start()
ssc.awaitTermination()
}
def createStream(taskOffsetInfo: Map[TopicAndPartition, Long], kafkaParams: Map[String, String], conf:SparkConf, ssc: StreamingContext, topics:String):InputDStream[_] = {
// 若taskOffsetInfo 不为空, 说明这不是第一次启动该任务, database已经保存了该topic下该group的已消费的offset,
// 则对比kafka中该topic有效的offset的最小值和数据库保存的offset,去比较大作为新的offset.
println("taskOffsetInfo "+taskOffsetInfo)
if(taskOffsetInfo.size != 0){
println("taskOffsetInfo size: "+taskOffsetInfo.size)
val kc = new KafkaCluster(kafkaParams)
val earliestLeaderOffsets = kc.getEarliestLeaderOffsets(taskOffsetInfo.keySet)
if(earliestLeaderOffsets.isLeft)
throw new SparkException("get kafka partition failed:")
val earliestOffSets = earliestLeaderOffsets.right.get
println("earliestOffSets: "+earliestOffSets+" earliestOffSets: "+earliestOffSets)
val offsets = earliestOffSets.map(r =>
new TopicAndPartition(r._1.topic, r._1.partition) -> r._2.offset)
println("offsets "+offsets)
val newOffsets = taskOffsetInfo.map(r => {
val t = offsets(r._1)
println("t1: "+t+" t2: "+r._2)
if (t > r._2) {
r._1 -> t
} else {
r._1 -> r._2
}
}
)
println("newOffsets: "+newOffsets)
val messageHandler = (mmd: MessageAndMetadata[String, String]) => mmd.message()
println("messageHandler: "+messageHandler)
println("kafkaParams: "+kafkaParams+" | newOffsets: "+newOffsets+" |messageHandler: "+messageHandler)
//println("KafkaUtils: "+KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, Long](ssc, kafkaParams, newOffsets, messageHandler))
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](ssc, kafkaParams, newOffsets, messageHandler)
} else {
val topicSet = topics.split(",").toSet
println("topicSet: "+topicSet)
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams,topicSet)
}
}
def setupSsc(
kafkaParams: Map[String, String],
jdbcDriver: String,
jdbcUrl: String,
jdbcUser: String,
jdbcPassword: String,
topics:String,
group:String
)(): StreamingContext = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("SprKafkaNew")
.set("spark.worker.timeout", "500")
.set("spark.cores.max", "10")
.set("spark.streaming.kafka.maxRatePerPartition", "500")
.set("spark.rpc.askTimeout", "600s")
.set("spark.network.timeout", "600s")
.set("spark.streaming.backpressure.enabled", "true")
.set("spark.task.maxFailures", "1")
.set("spark.speculationfalse", "false")
val ssc = new StreamingContext(conf, Seconds(60))
val kc = new KafkaCluster(kafkaParams)
//ssc.checkpoint("hdfs://hadoop01:9000/shouzhucheckpoint")
//获取mysql链接
SetupJdbc(jdbcDriver, jdbcUrl, jdbcUser, jdbcPassword) // connect to mysql
// begin from the the offsets committed to the database
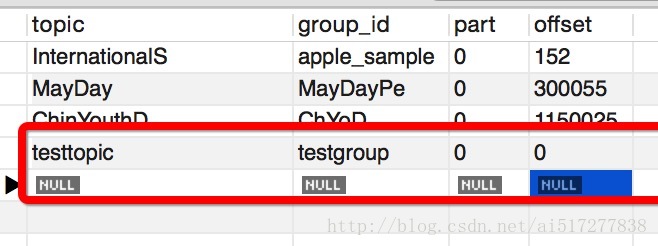
val fromOffsets = DB.readOnly { implicit session =>
sql"select topic, part, offset from streaming_task where group_id=$group".
map { resultSet =>
new TopicAndPartition(resultSet.string(1), resultSet.int(2)) -> resultSet.long(3)
}.list.apply().toMap
}
println("fromOffsets: "+fromOffsets)
val stream = createStream(fromOffsets, kafkaParams, conf, ssc, topics)
println("stream: "+stream.count())
println("step1")
stream.foreachRDD { rdd =>
if(rdd.count != 0){
// you task
//println("lines boole is: " + rdd.isEmpty() + " linescout: " + rdd.count())
rdd.foreach(x => println("value: "+x))
//rdd.map(record => (record, 1)).reduceByKey {_+_}.collect
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// persist the offset into the database
println(offsetRanges.map(ors =>println("topic: "+ors.topic+" partition: "+ors.partition+" untilOffset: "+ors.untilOffset)))
DB.localTx { implicit session =>
offsetRanges.foreach { osr =>
sql"""replace into streaming_task values(${osr.topic}, ${group}, ${osr.partition}, ${osr.untilOffset})""".update.apply()
if(osr.partition == 0){
println(osr.partition, osr.untilOffset)
}
}
}
//更新zookeeper上的消费offsets
for (offsets <- offsetRanges) {
val topicAndPartition = TopicAndPartition(offsets.topic, offsets.partition)
val o = kc.setConsumerOffsets(group, Map((topicAndPartition, offsets.untilOffset)))
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
}
}
println("step2")
stream.print()
ssc
}
} 不出意外,直接考进idea会有各种报错,先上下maven的pox
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.rgyun.adxRealtime</groupId>
<artifactId>adxRealtime</artifactId>
<version>1.0-SNAPSHOT</version>
<name>RiskControl</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--Spark core 及 streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<!-- Spark整合Kafka-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.10</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Hadoop依赖包-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<!--build test MAVEN 编译使用的JDK版本
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build> -->
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project> 然后需要特别注意的是KafkaCluster这个类的引用,需要将源码考出来放到和主类的同一个包下,然后去掉源码里的private修饰,才能正常引用。这样应该就能跑了,对了最好还是初始化一下mysql里的数据。想之前一样。
我测试了消费情况为,每分钟能只能消费3w条数据感觉这样手动管理了offsets消费的能力还是降了不少。
最后的最后忘了一个kafka的监控工具KafkaMonitor
给一个安装文章链接http://blog.csdn.net/lizhitao/article/details/27199863
荆轲刺秦王


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









