






用户画像作为“大数据”的核心组成部分,在众多互联网公司中一直有其独特的地位。作为国内旅游OTA的领头羊,携程也有着完善的用户画像平台体系。目前用户画像广泛用于个性化推荐,猜你喜欢等;针对旅游市场,携程更将其应用于“房型排序”“机票排序”“客服投诉”等诸多特色领域。
本文将从目的,架构、组成等几方面,带你了解携程在该领域的实践。
1.携程为什么做用户画像

首先,先分享一下携程用户画像的初衷。一般来说,推荐算法基于两个原理“根据人的喜好推荐对应的产品”“推荐和目标客人特征相似客人喜好的产品”。而这两条都离不开用户画像。
根据用户信息、订单、行为等等推测出其喜好,再针对性的给出产品可以极大提升用户感受,能避免用户被无故打扰的不适感。同时针对不同画像的用户提供个性化的服务也是携程用户画像的出发点之一。
2.携程用户画像的架构
2.1.携程用户画像的产品架构
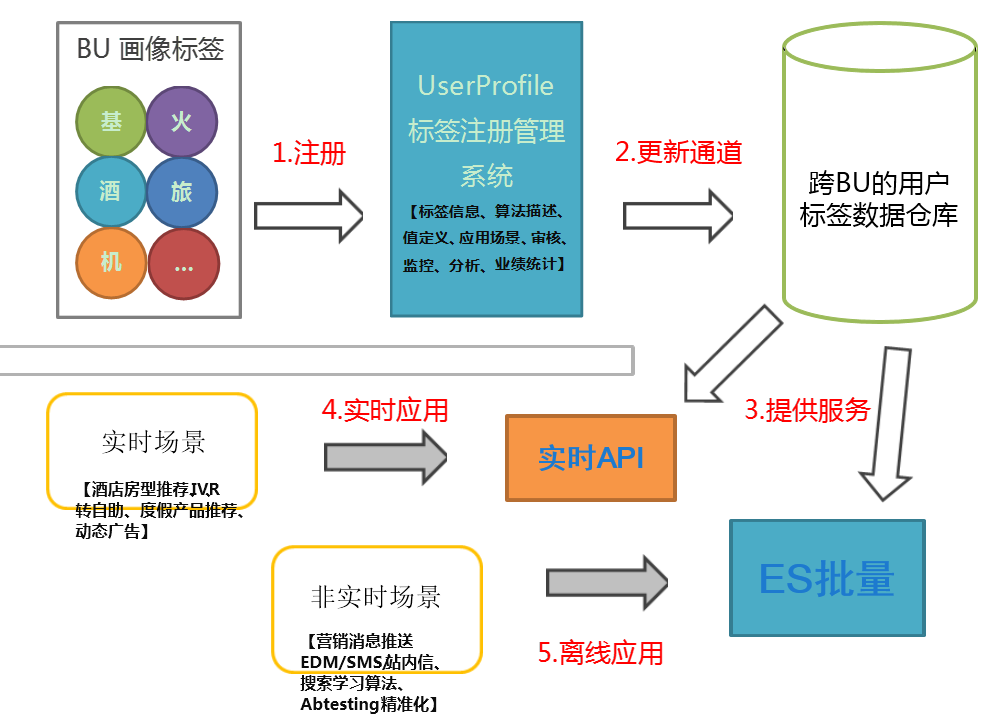
如上图所示,携程用户画像的产品架构大体可以总结为
- 注册
- 采集
- 计算
- 存储/查询
- 监控
所有的用户画像都会在”UserProfile平台”中进行注册,由专人审核,审核通过的画像才可以在“数据仓库”中流转;之后会通过用户信息、订单、行为等等进行信息采集,采集的目标是明确的、海量的、无序的。
信息收集的下一步是画像的计算,携程有专人制定计算公式、算法、模型,而计算分为批量(非实时)和流式(实时)两种,经过严密的计算,画像进入“画像仓库”中;而根据不同的使用场景,我们又会提供实时和批量两种查询API供各调用方使用,实时的服务侧重高可用,批量服务侧重高吞吐;最后所有的画像都在监控平台中得到有效的监控和评估,保证画像的准确性。
2.2.携程用户画像的技术架构
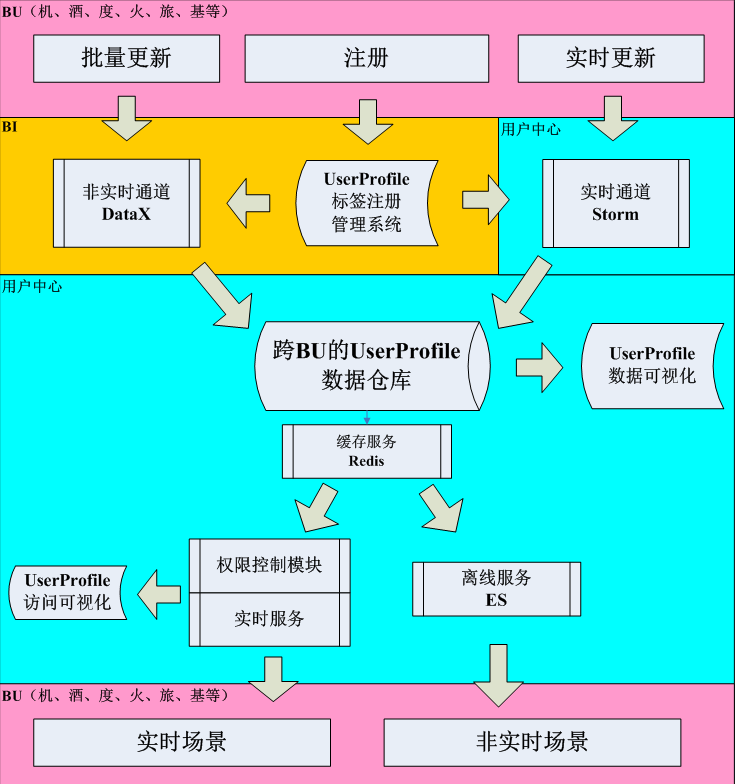
携程发展到今天规模,更强调松耦合、高内聚,实行BU化的管理模式。而用户画像是一种跨BU的模型,故从技术架构层面,携程用户画像体系如上图所示。
各BU都可以贡献有价值的画像,而基础部门也会根据BU的需要不断制作新的画像。画像经过开源且经我们二次开发的DataX和Storm进入携程跨BU的UserProfile数据仓库。在仓库之上,我们会有Redis缓存层以保证数据的高可用,同时有实时和借助elasticsearch两种方式的API,供调用方使用。
该架构有如下关键点:
- 有异步和实时两种通道满足不同场景、不同画像的需要,事实类画像一般采用实时计算方式,而复合类画像一般采用异步方式。
- 携程强调专人专用,每个人做自己最适合的事。故整个UserProfile是多个团队合作完成的,其中包括但不限于各BU的开发、BI,基础的开发、BI等。
- 所有API都是可降级、可熔断的,可以根据需要切数据流量。
- 由于用户画像极为敏感,出于数据安全的考虑,我们查询服务有严格的权限控制方案,所有信息必须经过授权才可以访问。
- 出于对用户画像准确性负责的目的,我们有专门的UserProfile数据可视化平台监控数据的一致性、可用性、正确性。
上述是用户画像的总体描述,下面我将详细分享各个细节。
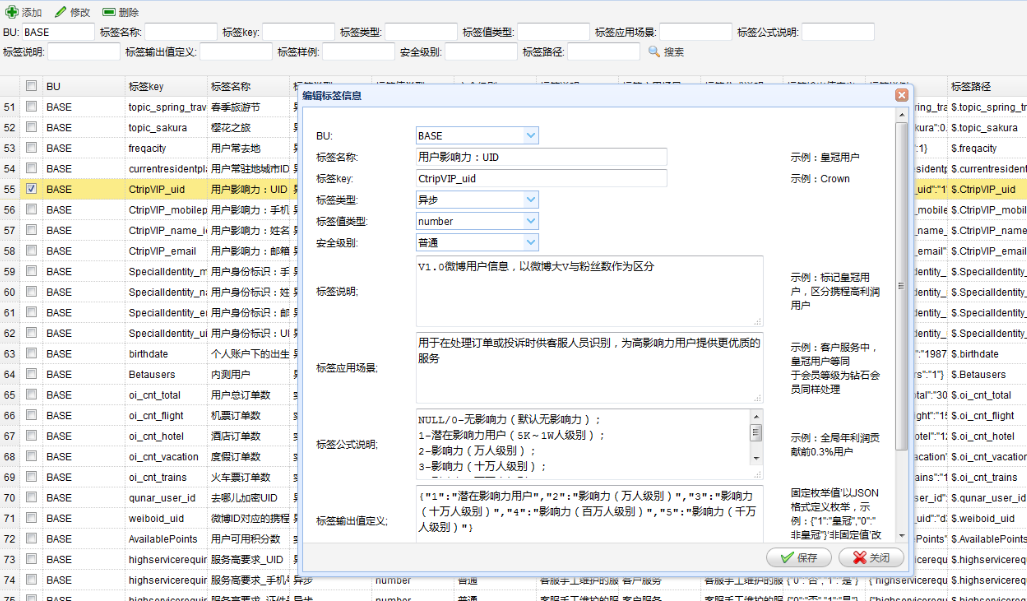
如上图所示,用户画像的注册在一个典型的Mis系统中完成,UserProfile数据的提供方在这里申请,由专人审核。申请时,必须填写画像的含义、计算方式、可能的值等。

3.携程用户画像的组成
3.1.信息采集
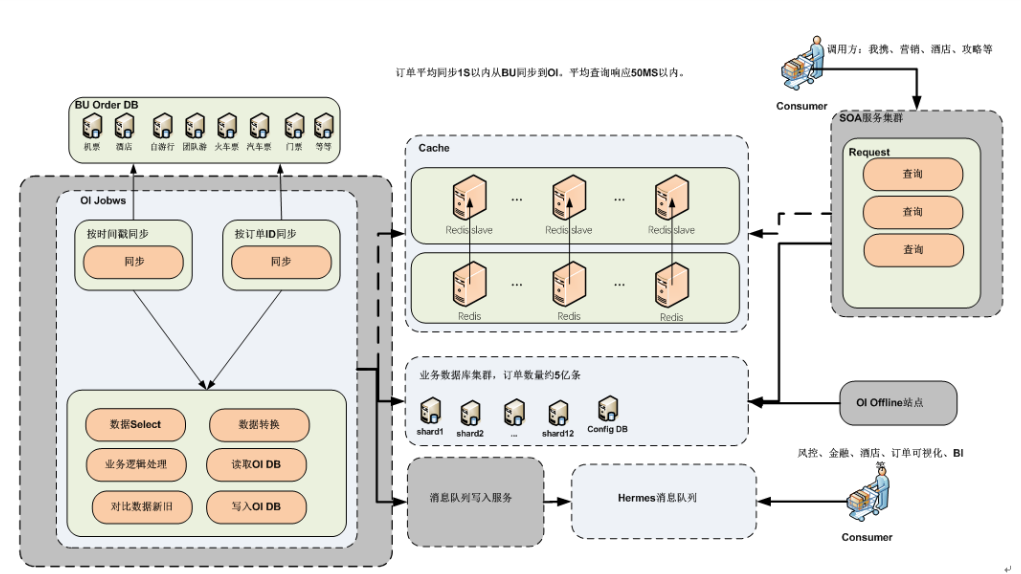
基础信息的采集是数据流转的开始,我们会收集UserInfo(比如用户个人信息、用户出行人信息、用户积分信息)、UBT(用户在APP、网站、合作站点的行为信息)、用户订单信息、爬虫信息、手机APP信息等。而上述每个基础信息的采集又是一个专门领域。比如下图展示了用户订单信息采集流程。
3.2.画像计算
基础信息是海量的、无序的,不经加工没有太大的价值。故用户画像的计算是数据流转的关键所在。我们的BI团队会制定严密的公式和模型,根据场景的需要,制定规则和参数,对采集信息做异步计算。这样的计算由于耗时较长,一般我们会采用T+N的方式异步更新,根据画像的不同,数据新鲜度的要求亦不同。动态和组合标签大多采用异步方式计算更新。Hive、DataX等开源工具被使用在这个步骤中。
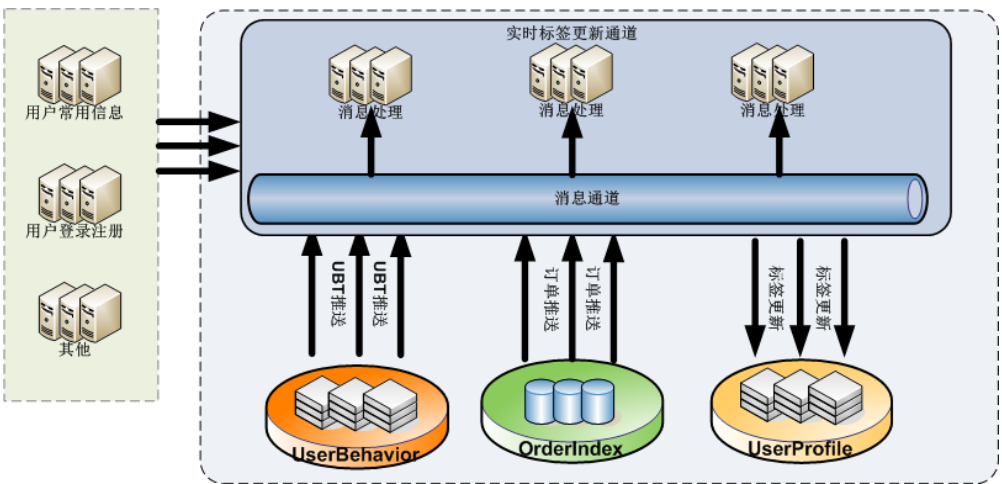
而有些画像是事实或对新鲜度要求比较高的,故我们会采用Kafka+Storm的流式方案去实时更新计算。比如下图,UBT(用户行为数据)使用消息通道Hermes对接Kafka+Storm为UserProfile的实时计算提供了有力的支持。
3.3.信息存储
用户画像的数据是海量的,被称作最典型的”大数据”,故Sharding分布式存储、分片技术、缓存技术被必然的引入进来。
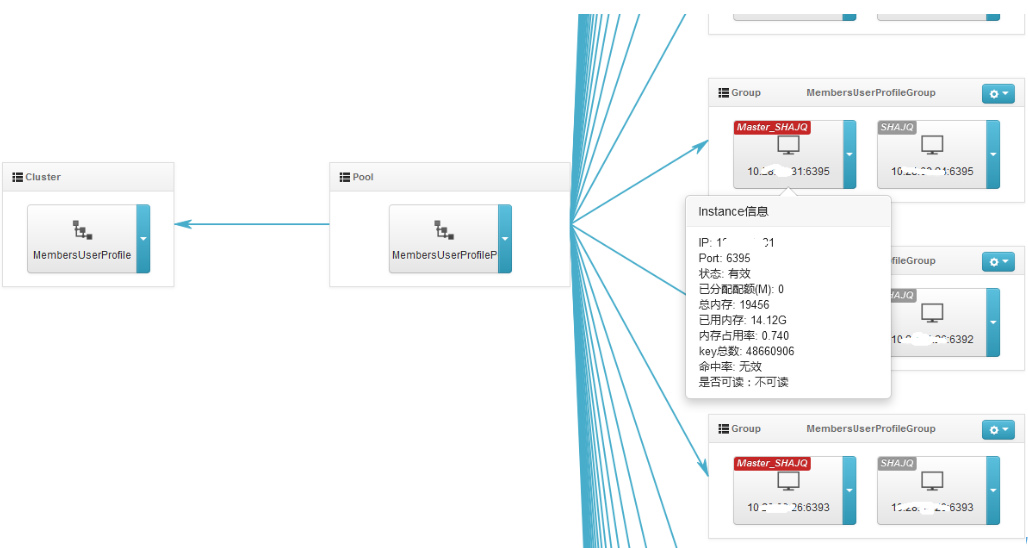
携程的用户画像仓库一共有160个数据分片,分布在4个物理数据集群中,同时采用跨IDC热备、一主多备、SSD等主流软硬件技术,保证数据的高可用、高安全。
由于用户画像的的使用场景非常多、调用量也异常庞大,这就要求用户画像的查询服务一定要做到高可用。故我们采用自降级、可熔断、可切流量等方案,在仓库前端增加缓存。如下图所示,数据仓库和缓存的存储目的不同,故是异构的。
3.4.高可用查询
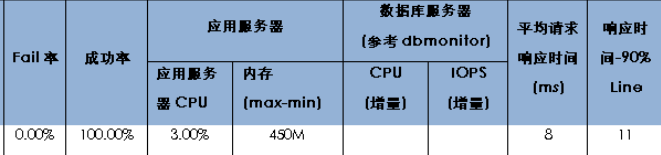
响应时间和TPS是衡量服务可用性的关键指标,携程要求所有API响应时间低于250ms(包括网络和框架埋点消耗),而我们用户画像实时服务采用自降级、可熔断、自短路等技术,服务平均响应时间控制在8ms(包括网络和框架埋点消耗),99%响应时间控制在11ms。
大部分场景都是通过单个用户获取用户画像,但部分营销场景则需要满足特定画像的用户群体,比如获取年龄大于30岁、消费能力强、有亲子偏好的女性。这种情况下会返回大量用户,此时就需要借助批量查询工具。经过多次技术选型,我们决定采用elasticsearch作为批查询的平台,封装成API后很好的支持上述场景。
3.5.监控和跟踪
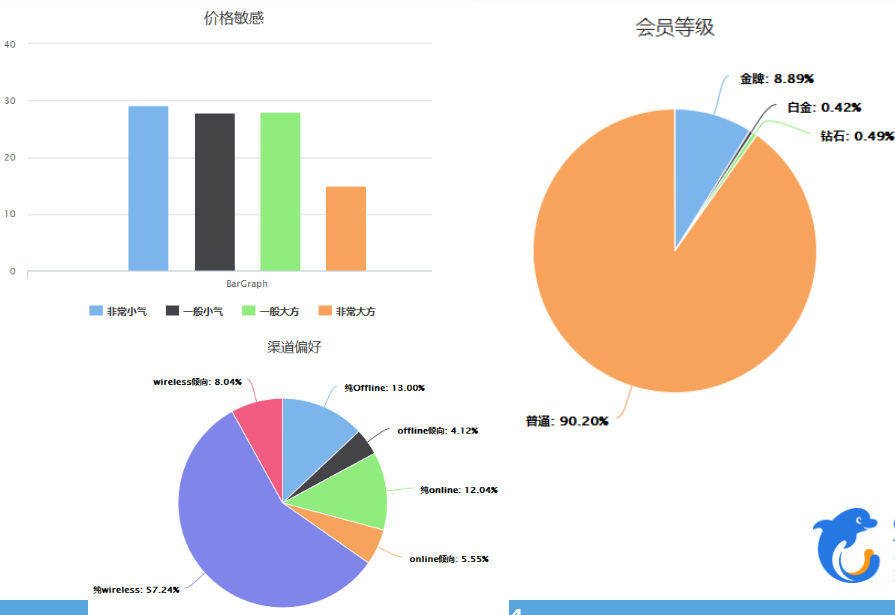
在数据流转的最后,数据的准确性是衡量用户画像价值的关键指标。基于高质量信息优于大数量信息的基调,我们设置了多层监控平台。从多个维度衡量数据的准确性。比如就用户消费能力这个画像,我们从用户等级、用户酒店星级、用户机票两舱等多个维度进行验证和斧正。同时我们还要监控数据的环比和同比表现,出现较大标准差、方差波动的数据,我们会重新评估算法。
上述所有环节组成了携程跨BU用户画像平台。当然技术日新月异,我们也在不断更新和局部创新,或许明年又会有很多新的技术被引入到我们用户画像中,希望我的分享对你有所帮助

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









