






MR编程模型之执行步骤:
1、准备map处理的输入数据
2、mapper处理
3、Shuffle
4、Reduce处理
5、结果输出
(input)<k1,v1> -> map -><k2,v2> -> combine -> <k2,v2> ->reduce -> <k3,v3>(output)
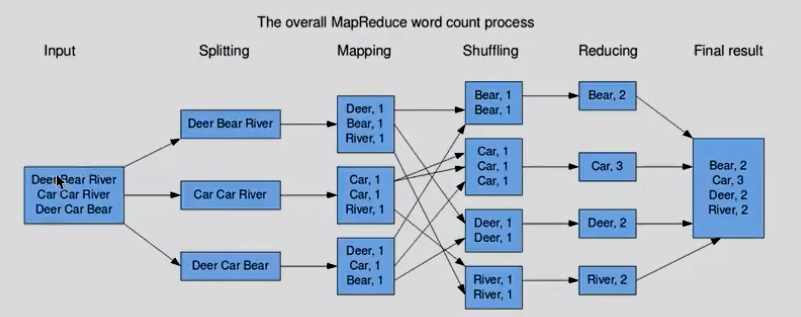
处理流程:
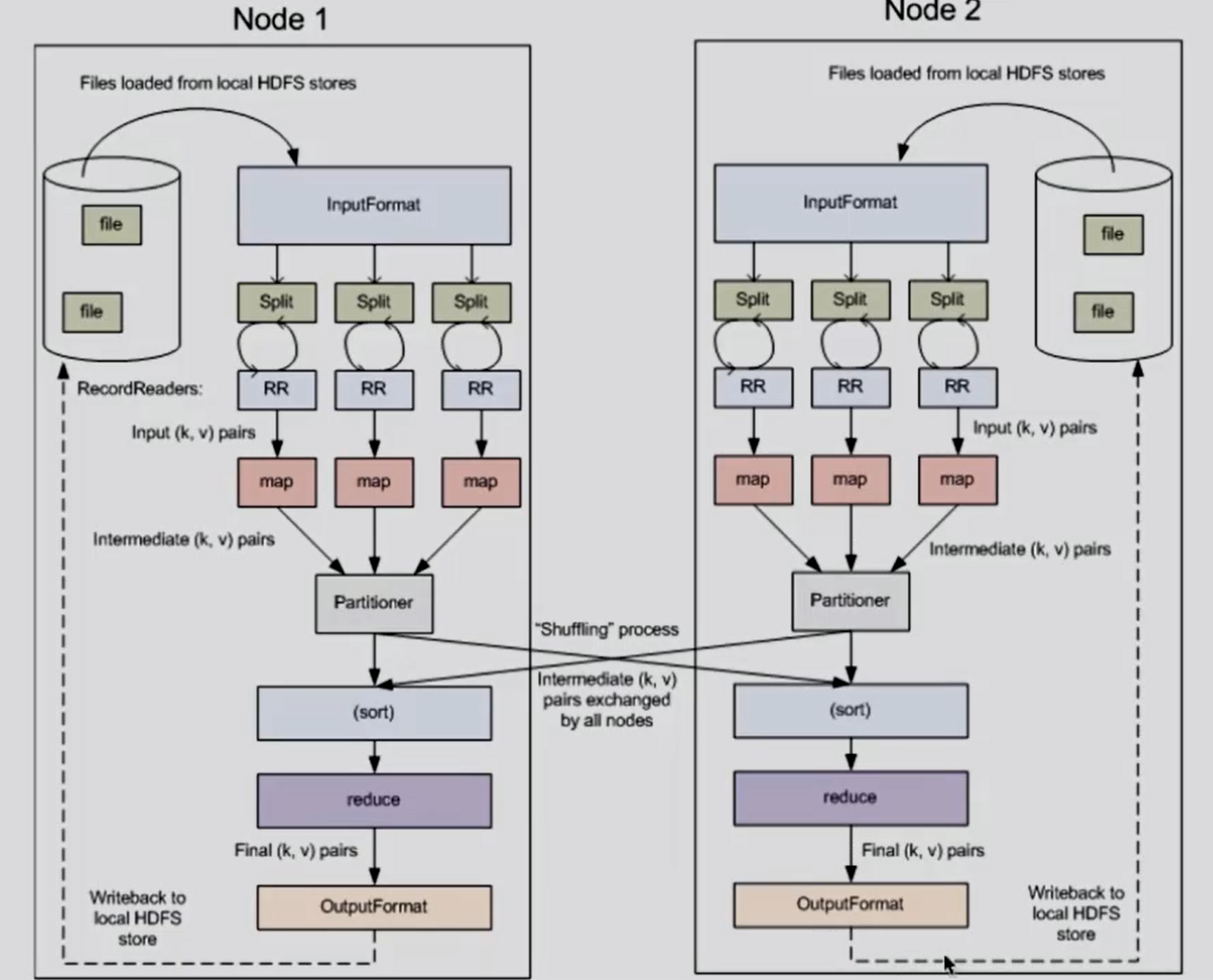
流程:
1、输入文本信息,由InputFormat -> FileInputFormat -> TextInputFormat,通过getSplits方法获得Split数组,然后在用getRecordReader 方法对Split做处理,每读一行交给一个map处理
2、每个节点上的所有map,交由该节点上的Partitioner处理(Shuffling的过程),按key将map放在其他节点上去还是继续在该节点下处理
3、排序
4、结果交由reduce处理
5、处理完成后由 OutputFormat ->FileOutputFormat ->TextOutputFormat 写到本地或Hadoop上
Split:MR处理的的数据块,MR中最小的计算单元,默认是与HDFS中的Block(HDFS中的最小存储单元,默认128M)是一一对应的,也可以手工设置(不建议修改)
InputFormat:将输入的数据进行分片(Split) InputSplit[] getSplits(JobConf var1, int var2)
TextInputFormat:用来处理文本格式的数据
OutputFormat: 输出
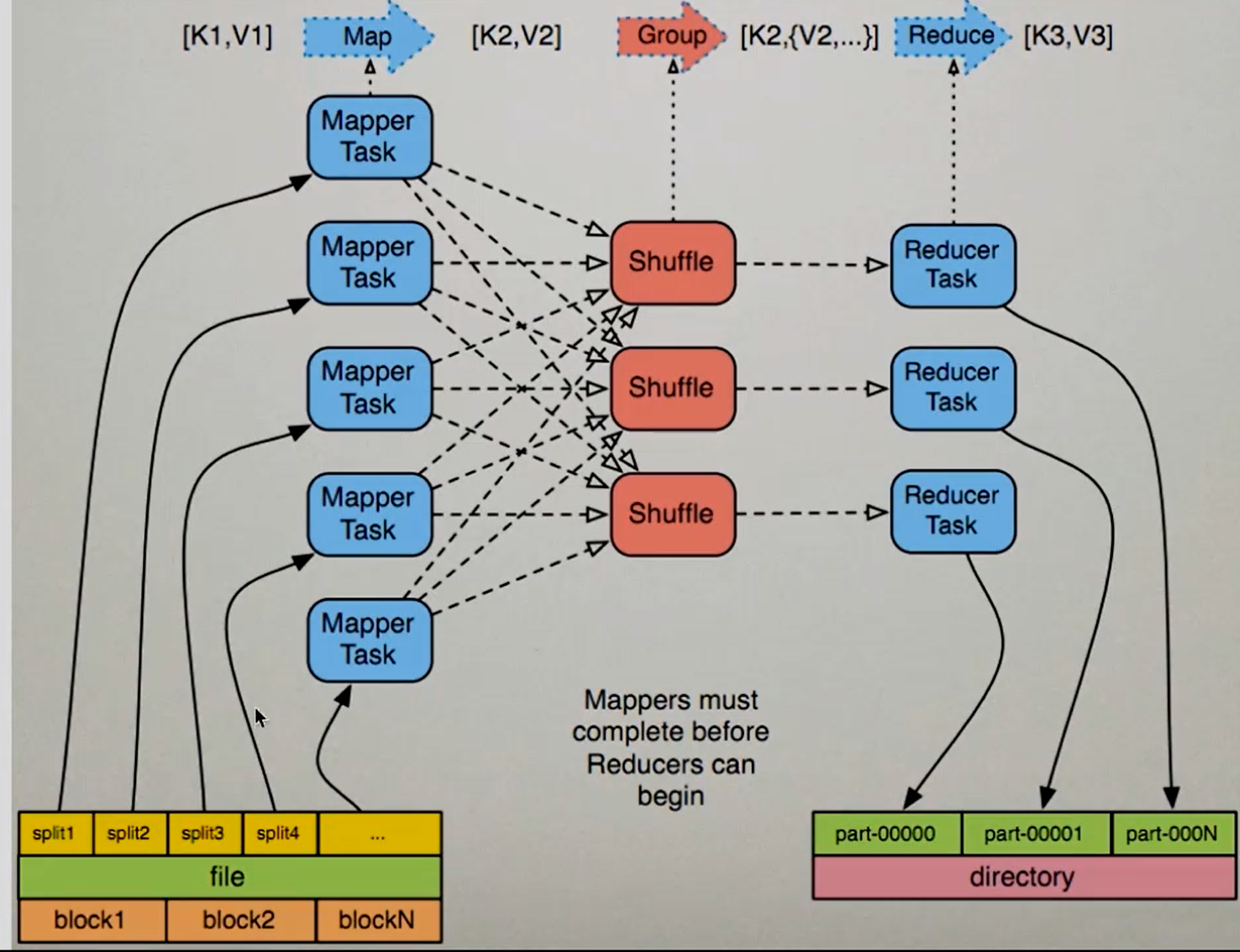
上图图解:
一般来说,一个Split对应一个Block,但上图是一个设置过后的。
一个file文件被分成了n个Block,对应着就是2n个Split,经过InputFormat处理后,每个Split交由一个Mapper处理,通过Shuffling的分组和排序后产生多个Reducer,每个Reducer就会产生一个文件
MapReduce 1.x的架构:一个JobTracker+多个taskTracker
JobTracker:负责资源管理和作业调度
TrakTracker:定期向JobTracker汇报节点的健康、资源、作业情况,接收JT的命令,比如启动/杀死任务
MapReduce 2.x:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









