







论文链接:https://arxiv.org/abs/2409.02834
论文名称:CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models研究概述
-
研究问题:这篇文章要解决的问题是如何评估和提升大型多模态模型(LMMs)在数学推理方面的能力。具体来说,现有的文本数学推理数据集主要关注英语,缺乏中文的多模态数学数据集,且这些数据集在问题的复杂性和多样性方面存在不足。
-
研究难点:该问题的研究难点包括:现有数据集主要集中在文本信息,忽略了问题的视觉上下文;现有的多模态数学数据集在规模和多样性方面有限,无法全面评估和提升LMMs的性能。
-
相关工作:该问题的研究相关工作有:Mishra等人提出的MATH数据集,Cobbe等人提出的GSM8K数据集,以及Lu等人提出的MATHVISTA和Wang等人提出的MATH-V数据集。这些数据集主要关注文本信息,缺乏对视觉上下文的考虑。
研究方法
这篇论文提出了一个中文多模态数学数据集(CMM-Math),并基于该数据集训练了一个特定的数学多模态模型(Math-LMM)。具体来说,
-
数据集构建:首先,作者收集了中国从小学到高中的12个年级的超过10,000张试卷,提取了其中的文本和图像数据。然后,将这些数据转化为JSON格式,并进行多轮验证以确保数据质量。最后,将数据分为评估集和训练集。
-
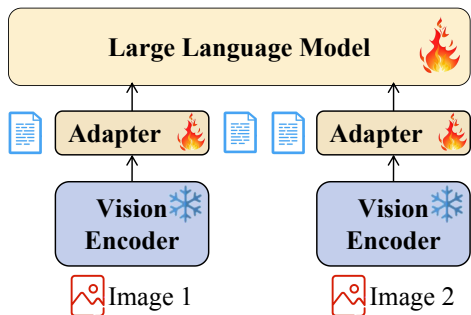
模型架构:作者提出了一个数学特定的多模态模型(Math-LMM),主要包括视觉编码器、适配器和大语言模型(LLM)。视觉编码器用于编码图像信息,适配器用于模态对齐,LLM用于数学推理。输入样本被转换为混合指令,以训练Math-LMM。
-
训练阶段:模型的训练分为三个阶段:基础预训练、基础微调和数学微调。基础预训练阶段,适配器与LLM对齐;基础微调阶段,学习任务处理能力;数学微调阶段,调整适配器和LLM模块以提高数学推理能力。
实验设计
-
数据集选择:选择了CMM-Math数据集作为评估和训练的基础,并使用了MATHVISTA和MATH-V数据集进行进一步的验证。
-
模型选择:评估了一系列开源和闭源的大型多模态模型,包括CogVLM2、InternLM-VL、Qwen-VL、Gemini和GPT-4o等。
-
参数配置:Math-LMM模型使用了一个轻量级的DFN5B-H-14+视觉编码器,总参数为8.26亿。适配器使用了两层MLP,嵌入维度为GELU函数。
-
评估指标:使用准确率和GPT-4o分数来衡量模型性能。准确率用于选择题和是非题,GPT-4o分数用于填空题和分析题。
结果与分析
-
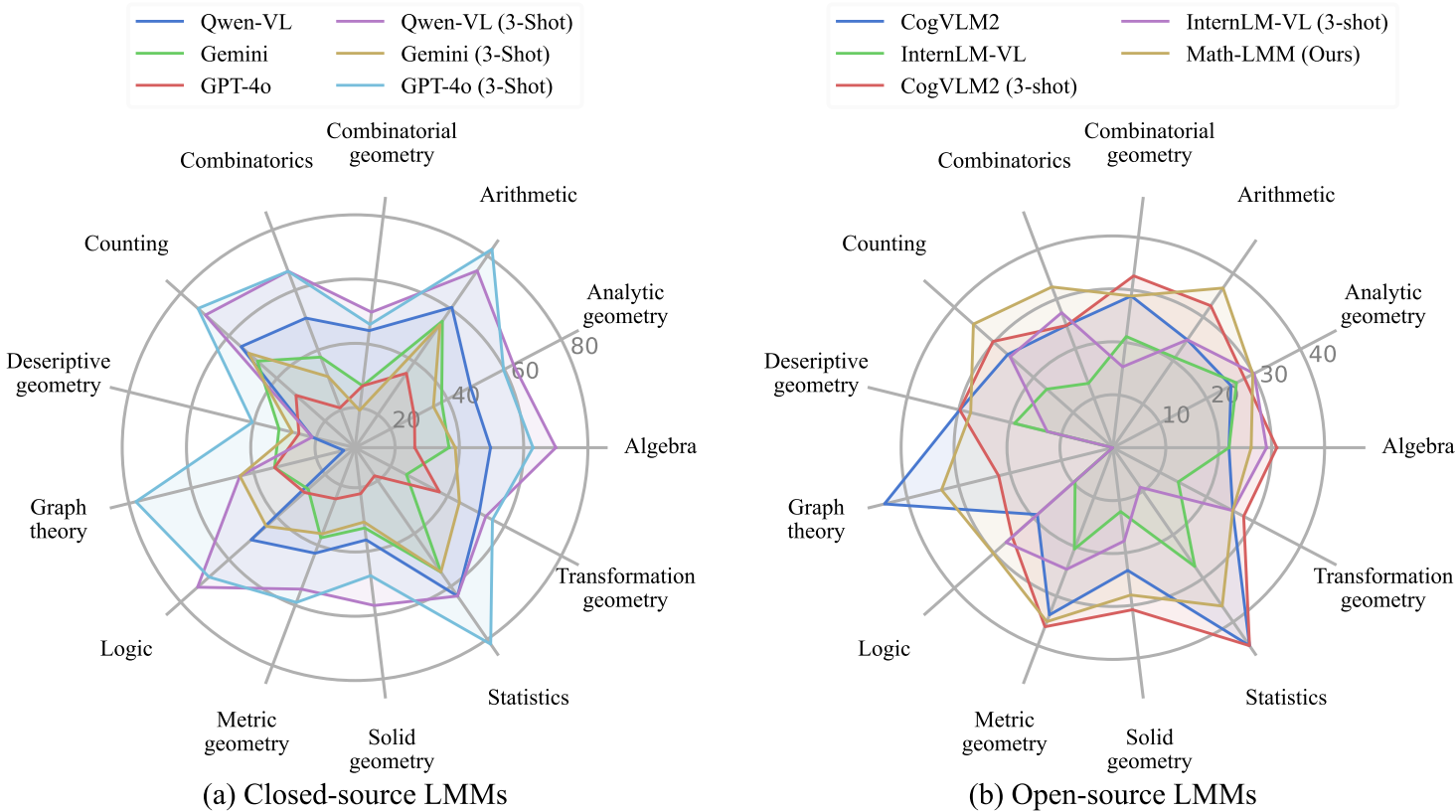
在CMM-Math数据集上的表现:Math-LMM模型在整体准确率上超过了其他开源LMMs,达到了32.10分,尽管其参数规模仅为82.6亿。算术和统计学科的平均准确率超过了45分,但在几何学科上的表现较差,平均准确率低于38.86分。
-
在不同学科上的表现:Math-LMM在算术和统计学科上表现最佳,而在几何学科上表现最差。具体来说,在算术学科上,Math-LMM的准确率为35.11分,而在几何学科上,准确率仅为26.11分。
-
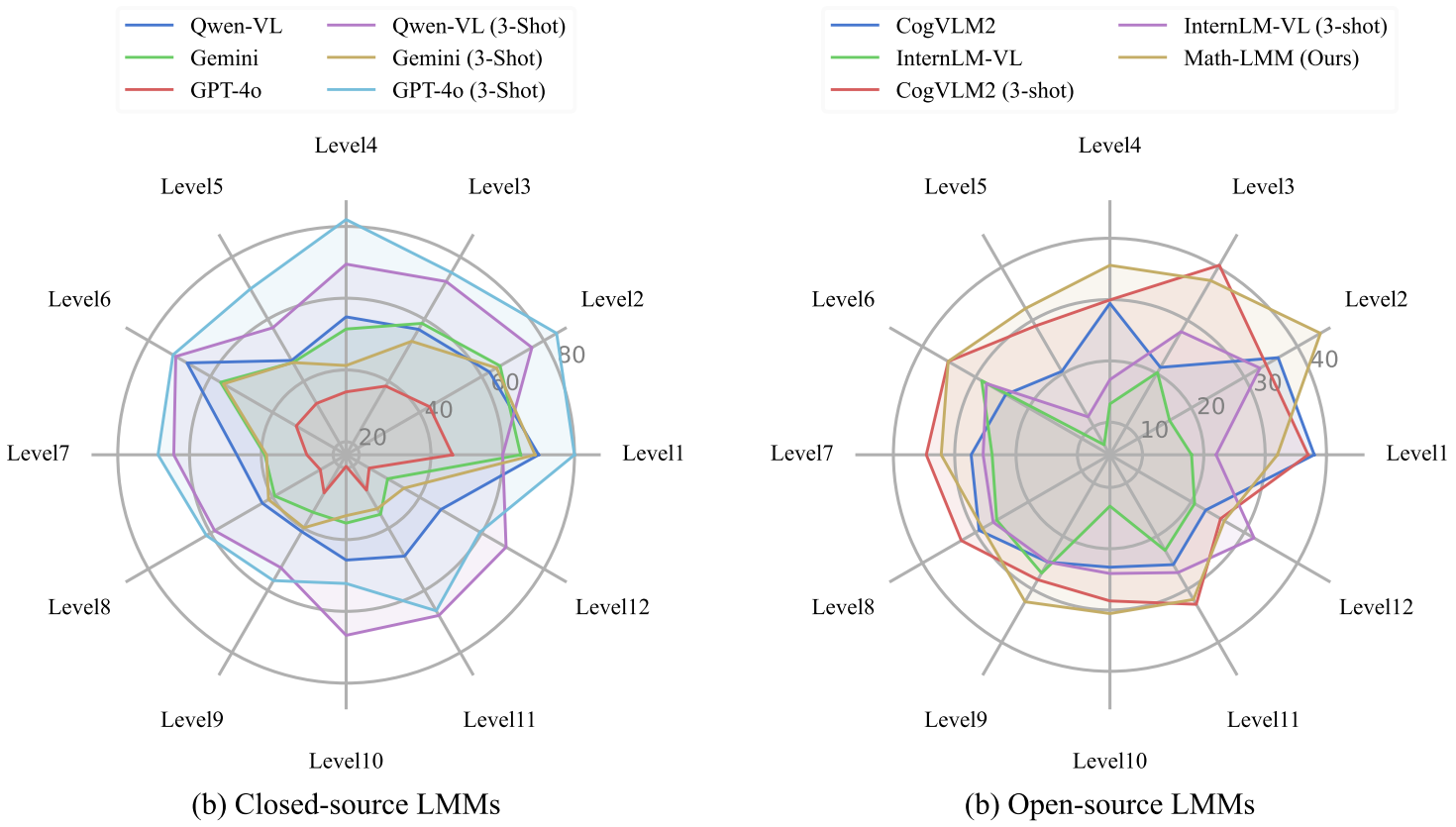
在不同年级上的表现:LMMs在小学级别的问题上表现良好,但在高中级别的问题上表现下降。例如,使用GPT-4o进行三枪提示时,模型在二年级问题上的准确率为84.08分,但在十年级问题上的准确率仅为52.23分。
-
在MATHVISTA和MATH-V数据集上的表现:在MATHVISTA数据集上,Math-LMM的总体得分为34.9分,仅次于GPT-4V。在MATH-V数据集上,Math-LMM在拓扑学科上表现最佳,得分为11.58分。
总体结论
这篇论文介绍了CMM-Math数据集,一个全面的中文多模态数学数据集,旨在评估和提升大型多模态模型在数学推理方面的性能。CMM-Math以其规模、多样性和复杂性脱颖而出,包含了超过28,000个高质量样本,覆盖了12个年级和多种问题类型。实验结果表明,现有的最先进的LMMs在CMM-Math数据集上面临挑战,强调了在这一领域进一步改进的必要性。作者提出的Math-LMM模型通过三个阶段的学习显著提高了多模态数学推理性能,尽管其模型规模相对较小。
优点与创新
-
数据集规模大且多样:CMM-Math包含超过28,000个高质量样本,覆盖了中国从小学到高中的12个年级,问题类型多样,包括选择题、填空题和分析题等。
-
视觉上下文丰富:数据集中的问题可能包含多个图像,视觉上下文更加丰富,使得数据集更具挑战性。
-
中文数据集:CMM-Math专注于中文,填补了非英文(特别是中文)多模态数学数据集的空白。
-
详细的解决方案:数据集中包含超过23,800个详细的解决方案,有助于模型的调试和改进。
-
多模态数学模型(Math-LMM):提出了一个专门针对数学的多模态语言模型(Math-LMM),通过三个阶段进行训练:基础预训练、基础微调和数学微调。
-
实验结果显著:实验结果表明,Math-LMM在多模态数学推理任务中表现优异,尤其是在与现有最先进模型的比较中表现突出。
关键问题及回答
问题1:CMM-Math数据集在构建过程中有哪些独特的特点和步骤?
-
数据收集:从中国和美国的中小学数学竞赛中收集了超过10,000份试卷,包含12个年级的数学测试题。使用Mathpix API提取试卷中的文本和图像。
-
数据标注:将提取的问题转换为JSON格式,包括问题类型、模态、问题、选项、答案和解决方案等字段。经过多轮验证,确保数据质量。
-
数据划分:将数据集划分为评估集(5,821个样本)和训练集(22,248个样本),并按1:4的比例划分。
-
问题类型和难度:数据集包含多种问题类型,如选择题、填空题、分析题和是非题,覆盖了从小学到高中的各个年级和学科。
-
数据多样性:数据集中的问题可能包含多个图像,设计的目的是为了让大型多模态模型(LMMs)更好地处理复杂的数学问题。
问题2:Math-LMM模型的三个训练阶段是如何设计的?各阶段的具体目标是什么?
-
基础预训练:使用大规模通用多模态数据集对适配器进行预训练,使适配器能够将图像输入与LLM对齐。具体目标是让适配器学会如何有效地将图像信息转化为适合LLM处理的格式。
-
基础微调:通过指令调优学习任务处理能力,主要使用涉及一般领域问题的数据集进行训练。具体目标是提升模型在处理多样化任务时的泛化能力。
-
数学微调:通过调整适配器和LLM模块,使用与数学相关的数据集进行微调,以提高模型的数学推理能力。具体目标是让模型在处理数学问题时能够更好地利用其数学知识和推理能力。
问题3:在实验结果中,Math-LMM模型在不同学科和年级的表现如何?有哪些具体的发现?
-
总体性能:在CMM-Math数据集上,Math-LMM模型的总体准确率为32.10%,超过了其他开源LMMs。与现有最先进的模型相比,Math-LMM在参数较少的情况下表现出色。
-
学科性能:在代数、算术和统计等学科上,LMMs表现较好,平均准确率超过45%。然而,在几何学科上,包括解析几何、组合几何、描述几何、度量几何和变换几何,LMMs的表现较差,平均准确率低于38.86%。
-
年级性能:LMMs在小学级别的问题上表现较好,但在高中级别的问题上表现下降。例如,使用GPT-4o进行三 shot 提示时,模型在二年级问题上的准确率为84.08%,但在十年级问题上的准确率仅为52.23%。
-
问题类型性能:LMMs在选择题和是非题上表现较好,但在填空题和分析题上的表现有限。这可能是由于大多数训练数据集是选择题和是非题,导致模型在生成逐步解决方案和分析性答案方面的能力较弱。

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









