







MapReduce作业运行过程中内存溢出错误分类
1、Mapper/Reducer阶段JVM内存溢出(一般都是堆)
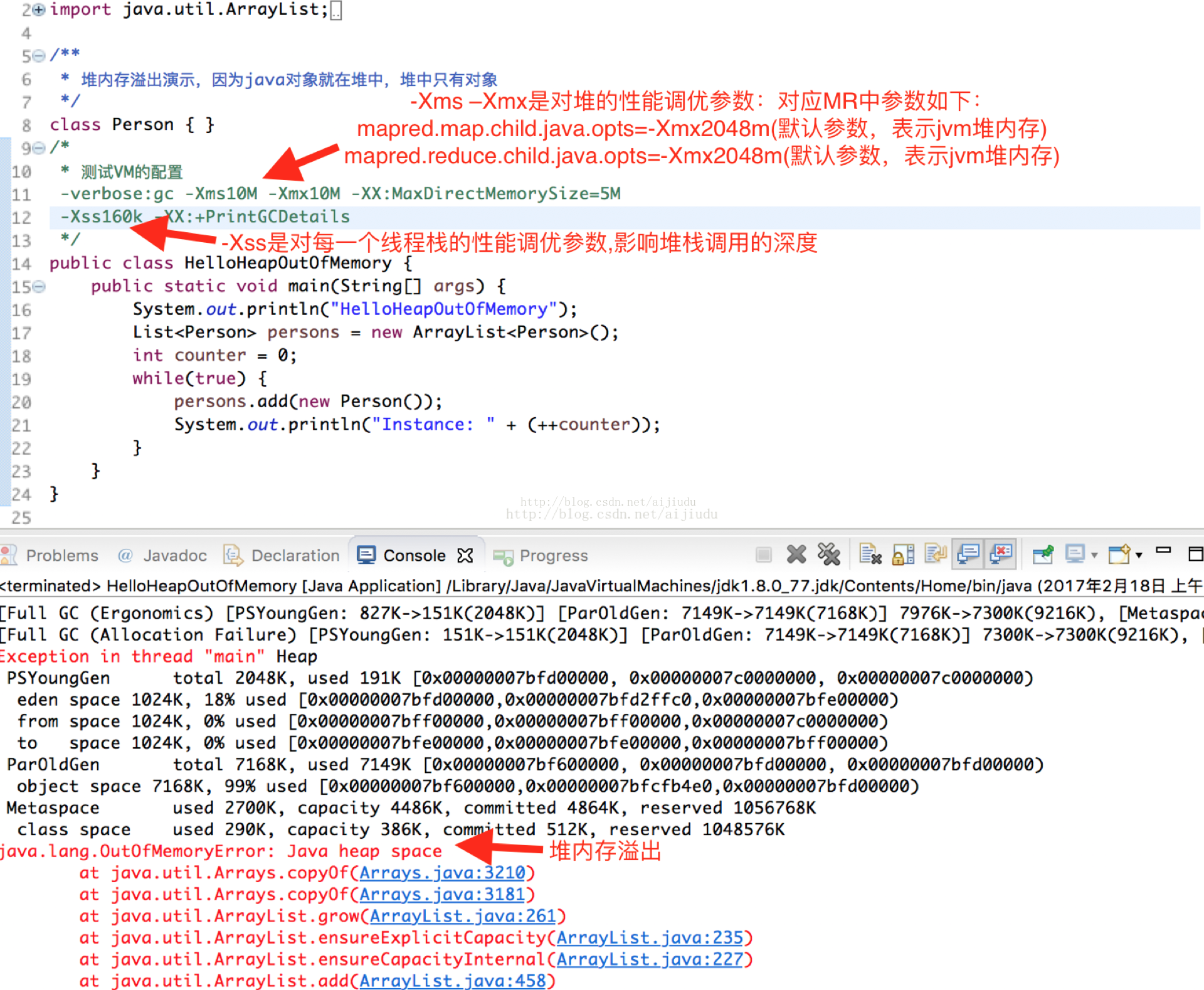
1)JVM堆(Heap)内存溢出:堆内存不足时,一般会抛出如下异常:
第一种:“java.lang.OutOfMemoryError:” GC overhead limit exceeded;
第二种:“Error: Java heapspace”异常信息;
第三种:“running beyondphysical memory limits.Current usage: 4.3 GB of 4.3 GBphysical memory used; 7.4 GB of 13.2 GB virtual memory used. Killing container”。
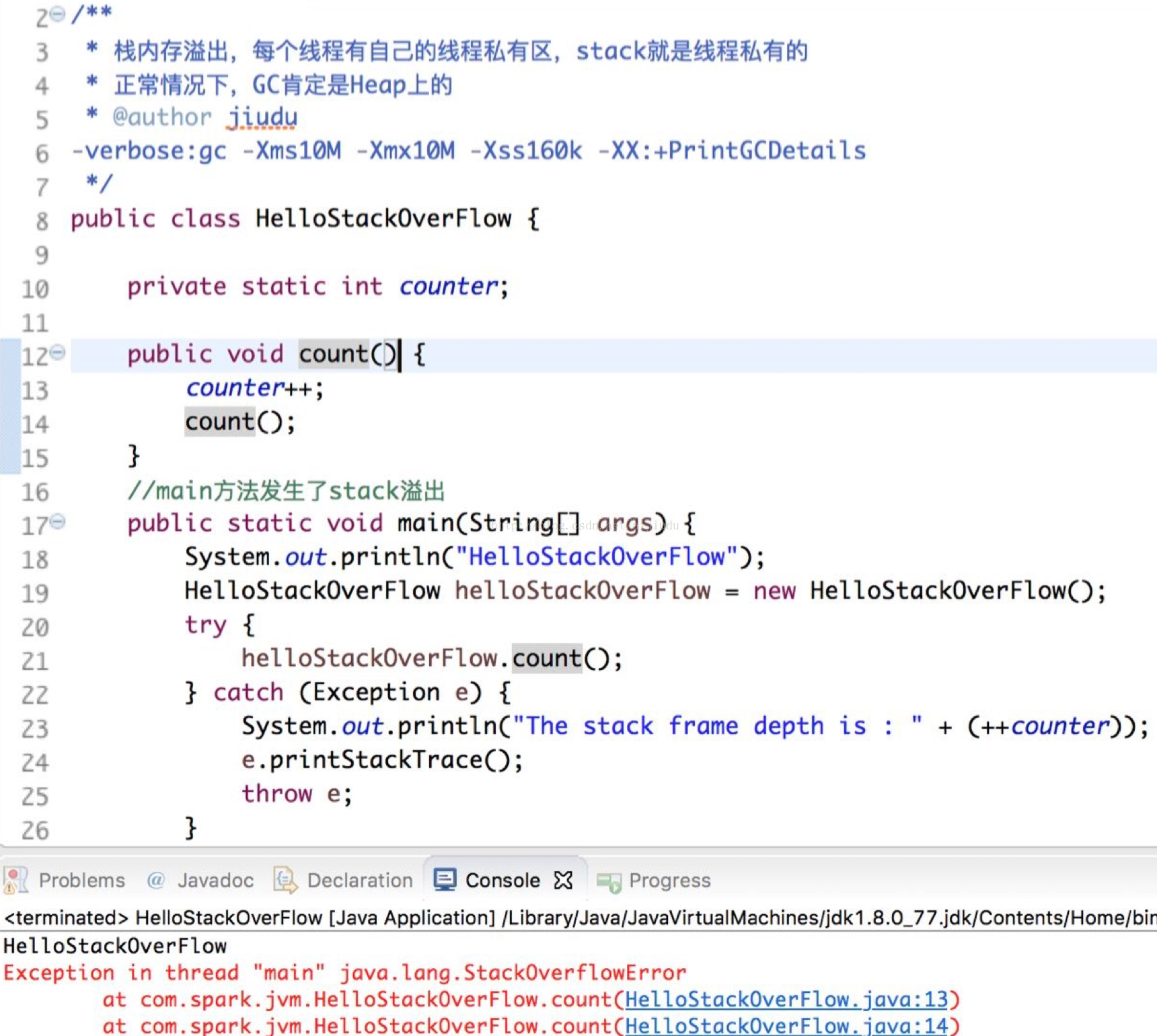
2) 栈内存溢出:抛出异常为:java.lang.StackOverflowError
常会出现在SQL中(SQL语句中条件组合太多,被解析成为不断的递归调用),或MR代码中有递归调用。这种深度的递归调用在栈中方法调用链条太长导致的。出现这种错误一般说明程序写的有问题。
2、MRAppMaster内存不足
如果作业的输入的数据很大,导致产生了大量的Mapper和Reducer数量,致使MRAppMaster(当前作业的管理者)的压力很大,最终导致MRAppMaster内存不足,作业跑了一般出现了OOM信息
异常信息为:
Exception: java.lang.OutOfMemoryError thrown from theUncaughtExceptionHandler in thread "Socket Reader #1 for port 30703
Halting due to Out Of Memory Error...
Halting due to Out Of Memory Error...
Halting due to Out Of Memory Error...
3、非JVM内存溢出
异常信息一般为:java.lang.OutOfMemoryError:Direct buffer memory
自己申请使用操作系统的内存,没有控制好,出现了内存泄露,导致的内存溢出。
错误解决参数调优
1、Mapper/Reducer阶段JVM堆内存溢出参数调优
目前MapReduce主要通过两个组参数去控制内存:(将如下参数调大)
Maper:
mapreduce.map.java.opts=-Xmx2048m(默认参数,表示jvm堆内存,注意是mapreduce不是mapred)
mapreduce.map.memory.mb=2304(container的内存)
Reducer:
mapreduce.reduce.java.opts=-=-Xmx2048m(默认参数,表示jvm堆内存)
mapreduce.reduce.memory.mb=2304(container的内存)
注意:因为在yarn container这种模式下,map/reduce task是运行在Container之中的,所以上面提到的mapreduce.map(reduce).memory.mb大小都大于mapreduce.map(reduce).java.opts值的大小。mapreduce.{map|reduce}.java.opts能够通过Xmx设置JVM最大的heap的使用,一般设置为0.75倍的memory.mb,因为需要为java code等预留些空间
2、MRAppMaster:
yarn.app.mapreduce.am.command-opts=-Xmx1024m(默认参数,表示jvm堆内存)
yarn.app.mapreduce.am.resource.mb=1536(container的内存)
注意在Hive ETL里面,按照如下方式设置:
set mapreduce.map.child.java.opts="-Xmx3072m"(注:-Xmx设置时一定要用引号,不加引号各种错误)
set mapreduce.map.memory.mb=3288
或
set mapreduce.reduce.child.java.opts="xxx"
set mapreduce.reduce.memory.mb=xxx
涉及YARN参数:
•yarn.scheduler.minimum-allocation-mb (最小分配单位1024M)
•yarn.scheduler.maximum-allocation-mb (8192M)
•yarn.nodemanager.vmem-pmem-ratio (虚拟内存和物理内存之间的比率默认 2.1)
•yarn.nodemanager.resource.memory.mb
Yarn的ResourceManger(简称RM)通过逻辑上的队列分配内存,CPU等资源给application,默认情况下RM允许最大AM申请Container资源为8192MB(“yarn.scheduler.maximum-allocation-mb“),默认情况下的最小分配资源为1024M(“yarn.scheduler.minimum-allocation-mb“),AM只能以增量(”yarn.scheduler.minimum-allocation-mb“)和不会超过(“yarn.scheduler.maximum-allocation-mb“)的值去向RM申请资源,AM负责将(“mapreduce.map.memory.mb“)和(“mapreduce.reduce.memory.mb“)的值规整到能被(“yarn.scheduler.minimum-allocation-mb“)整除,RM会拒绝申请内存超过8192MB和不能被1024MB整除的资源请求。(不同配置会有不同)
错误模拟和分析
一、错误模拟(JVM架构和GC垃圾回收机制)
(1) 堆内存溢出
(2) 栈内存溢出
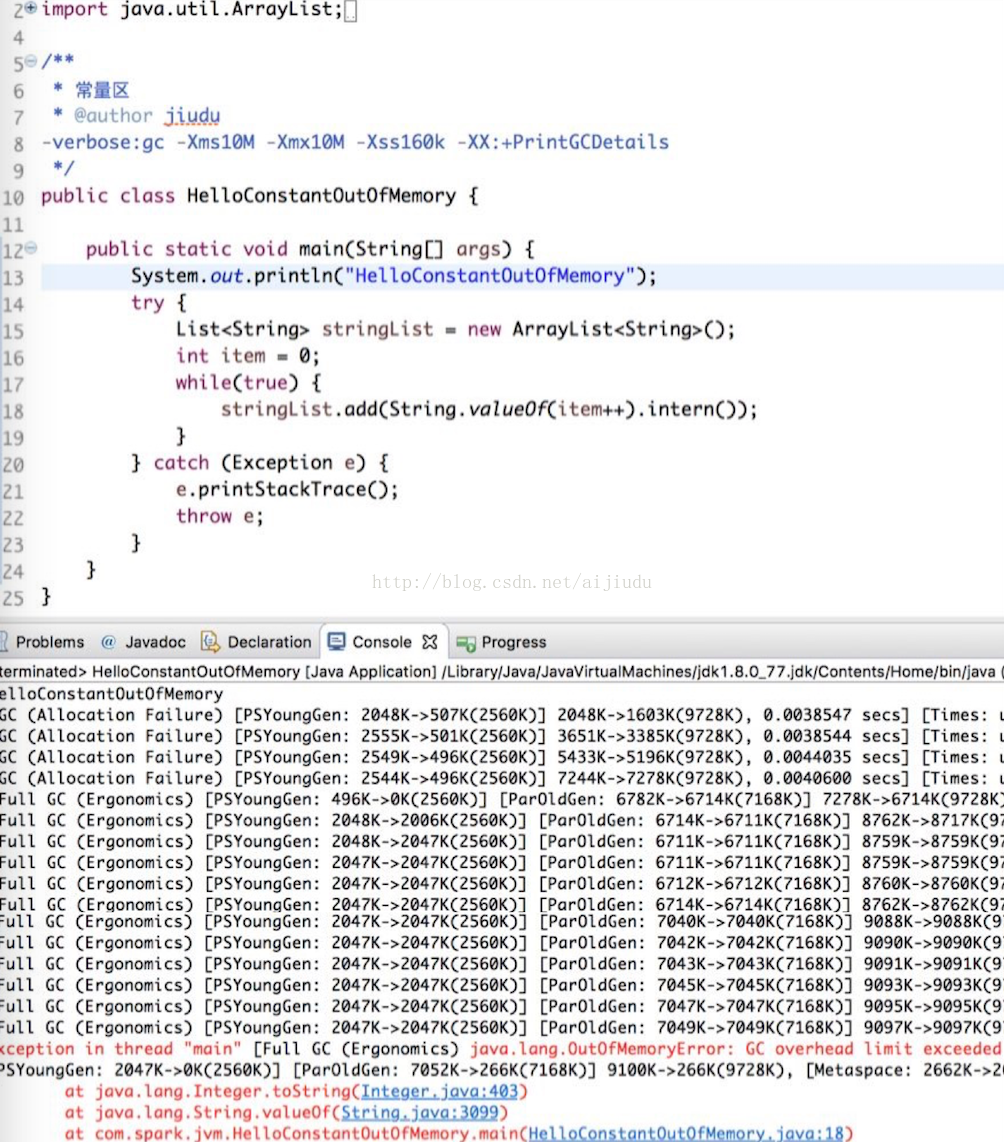
(3) 方法区内存溢出
(4) 非JVM内存溢出

二、原因分析(归根揭底都是GC导致的)
1)JVM的三大核心区域

2)JVMHeap区域(年轻代、老年代)和方法区(永久代)结构图

3)通过一段代码分析GC的整个过程:
public class HelloJVM {
//在JVM运行的时候会通过反射的方式到Method区域找到入口方法main
public static void main(String[] args) {//main方法也是放在Method方法区域中的
/**
* student(小写的)是放在主线程中的Stack区域中的
* Student对象实例是放在所有线程共享的Heap区域中的
*/
Student student = new Student("spark");
/**
* 首先会通过student指针(或句柄)(指针就直接指向堆中的对象,句柄表明有一个中间的,student指向句柄,句柄指向对象)
* 找Student对象,当找到该对象后会通过对象内部指向方法区域中的指针来调用具体的方法去执行任务
*/
student.sayHello();
}
}
class Student {
// name本身作为成员是放在stack区域的但是name指向的String对象是放在Heap中
private String name;
public Student(String name) {
this.name = name;
}
//sayHello这个方法是放在方法区中的
public void sayHello() {
System.out.println("Hello, this is " + this.name);
}
}从Java GC的角度解读代码:程序20行new的Person对象会首先会进入年轻代的Eden中(如果对象太大可能直接进入年老代)。在GC之前对象是存在Eden和from中的,进行GC的时候Eden中的对象被拷贝到To这样一个survive空间(survive(幸存)空间:包括from和to,他们的空间大小是一样的,又叫s1和s2)中(有一个拷贝算法),From中的对象(算法会考虑经过GC幸存的次数)到一定次数(阈值(如果说每次GC之后这个对象依旧在Survive中存在,GC一次他的Age就会加1,默认15就会放到Old Generation。但是实际情况比较复杂,有可能没有到阈值就从Survive区域直接到Old Generation区域。在进行GC的时候会对Survive中的对象进行判断,Survive空间中有一些对象Age是一样的,也就是经过的GC次数一样,年龄相同的这样一批对象的总和大于等于Survive空间一半的话,这组对象就会进入old Generation中,(是一种动态的调整))),会被复制到Old Generation,如果没到次数From中的对象会被复制到To中,复制完成后To中保存的是有效的对象,Eden和From中剩下的都是无效的对象,这个时候就把Eden和From中所有的对象清空。在复制的时候Eden中的对象进入To中,To可能已经满了,这个时候Eden中的对象就会被直接复制到OldGeneration中,From中的对象也会直接进入Old Generation中。就是存在这样一种情况,To比较小,第一次复制的时候空间就满了,直接进入old Generation中。复制完成后,To和From的名字会对调一下,因为Eden和From都是空的,对调后Eden和To都是空的,下次分配就会分配到Eden。一直循环这个流程。好处:使用对象最多和效率最高的就是在Young Generation中,通过From to就避免过于频繁的产生Full GC(Old Generation满了一般都会产生FullGC)
虚拟机在进行MinorGC(新生代的GC)的时候,会判断要进入Old Generation区域对象的大小,是否大于Old Generation剩余空间大小,如果大于就会发生Full GC。
刚分配对象在Eden中,如果空间不足尝试进行GC,回收空间,如果进行了MinorGC空间依旧不够就放入Old Generation,如果OldGeneration空间还不够就OOM了。
比较大的对象,数组等,大于某值(可配置)就直接分配到老年代,(避免频繁内存拷贝)
年轻代和年老代属于Heap空间的
Permanent Generation(永久代)可以理解成方法区,(它属于方法区)也有可能发生GC,例如类的实例对象全部被GC了,同时它的类加载器也被GC掉了,这个时候就会触发永久代中对象的GC。
如果OldGeneration满了就会产生FullGC
想了解更多的GC的内容请查看:http://blog.csdn.net/aijiudu/article/details/72991993















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









