






接到测试提了一个bug,说有个校验姓名是否是汉字的功能不正确。测试的汉字为:㑇
查看代码,校验方法是用正则表达式。正则为 "^[\u4e00-\u9fa5@]{0,}$"
然后网上查了一下相关的验证方式。通过正则验证的,正则表达式都是上面那个,比如 验证1,验证2
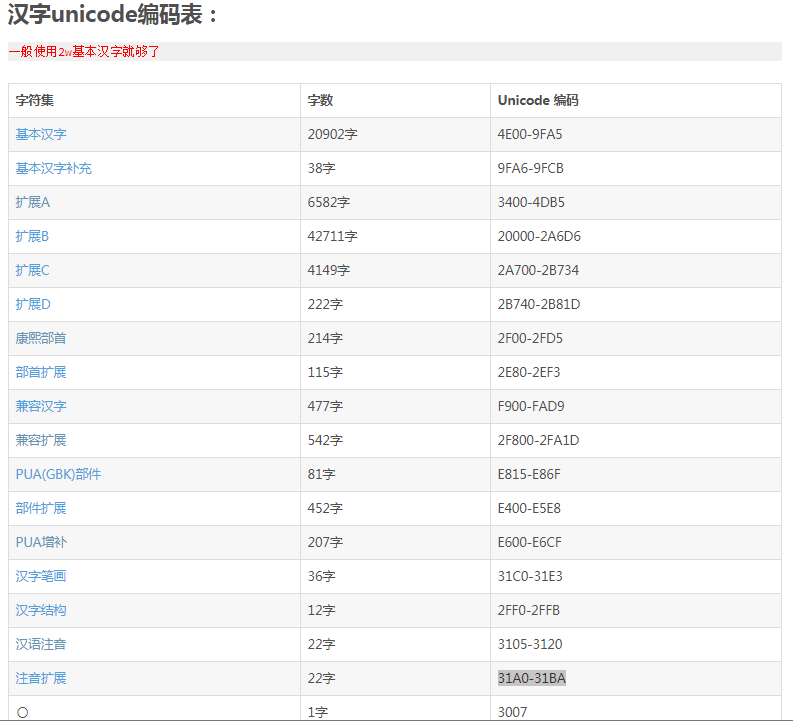
因为这个验证是大部分汉字都能校验通过,部分汉字校验不通过,猜想应该是这个汉字校验的字符集不全的问题,转而查一下汉字的Unicode编码表。果不其然,\u4e00-\u9fa5只是汉字的基本字符集,还有好多增补、扩展的字符集没有包括进来。到这里,为题迎刃而解,把其它增补、扩展的字符集的Unicode编码范围添加到正则表达式中就把问题搞定了。
string reg = "^[\u4e00-\u9fa5\u9fa6-\u9fcb\u3400-\u4db5\u20000-\u2a6d6\u2A700-\u2B734\u2B740-\u2B81D\u2F00-\u2FD5\u2E80-\u2EF3\uF900-\uFAD9\u2F800-\u2FA1D\uE815-\uE86F\uE400-\uE5E8\uE600-\uE6CF\u31C0-\u31E3\u2FF0-\u2FFB\u3105-\u3120\u31A0-\u31BA@]{0,}$";















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









