






github项目地址:https://github.com/Wegnery/New_WordCount
一、基础功能部分:代码编写+单元测试
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| Estimate | 估计任务需要多少时间 | 30 | 35 |
| Development | 开发 | 325 | 340 |
| Analysis | 需求分析 | 25 | 30 |
| Design Spec | 生成设计文档 | 25 | 20 |
| Design Review | 设计复审 | 25 | 20 |
| Coding Standard | 代码规范 | 25 | 30 |
| Design | 具体设计 | 30 | 25 |
| Coding | 具体编码 | 100 | 90 |
| Code Review | 代码复审 | 35 | 45 |
| Test | 测试 | 60 | 70 |
| Reporting | 报告 | 75 | 85 |
| Test Report | 测试报告 | 25 | 30 |
| Size Measurement | 计算工作量 | 25 | 30 |
| Postmortem | 总结 | 25 | 25 |
| 合计 | 430 | 460 |
整体架构与代码整合
我负责的模块为main模块与整体架构,即获取Output输出控制模块传入的已排序单词(同词频按字母顺序)与词频(升序),将其写入生成的result.txt文档,并添加执行时间进行追踪。故而并不涉及接口的设计与实现内容,这里简要地介绍一下整体架构与代码整合的过程。
根据老师要求的本程序四个封装模块:
(1)输入控制
对输入进行有效性校验,识别和处理无效输入,并针对有效输入,从中提取所需数据。
(2)核心处理
对输入进行处理,如单词词频统计,排序等,完成对应业务需求。
(3)输出控制
对结果以合理方式输出,将单词词频排序的结果输出到文件。
(4)其他
一些特殊模块,如和架构相关的(例如main函数等)。
我对小组成员的任务进行了分工如下:
周雨贝:Input.class
输入模块实现功能:1.识别.txt文件并读入;2.判定哈法输入与不合法输入
输出:一个Vector,包含文件中的所有单词。
宁宁:Calc.class
实现统计功能:对周雨贝传下来的Vector进行词频统计,并用map存储
输出:map类型,Map<string,integer>,其中string对应的是单词,int对应的是次数。
朱全:Output.class
实现输出功能:1.对宁宁传入的map类型的数据进行跑徐,即对map里的int进行整体排序。
2.将统计好的数组进行输出,输出到新生成的一个txt文件(result.txt) 中。
输出:无输出,string和int写到.txt文件里即可。
易成龙:整体架构与代码整合
任务内容:根据整个项目的功能需求进行架构设计,明确小组分工,特别是对于各模块的核心问题以及相关细节进行提示与说明;将其他三个功能模块的.calss文件进行整合,通过添加Main函数调用前三个模块的方法对.txt文件进行处理使其形成一个项目的雏形;在github上提交项目时使用——tags参数,并将tag推送到github上,例如使用git tag stage1,标记基本任务已经完成。
函数参数规定:周雨贝的函数参数为文件名funcname(String filename)
宁宁的为funcname(Vector<string> inputword)
朱全的为funcname(map<string,int> mp)
以下为Main函数的代码部分,这里要说明一下,在实际的开发过程中由于Input模块缺失了对文件为空情况的处理以及output模块在写入txt文件时没有对执行时间的记录,所以我针对这两个不足统一在Main函数中做了优化:一是通过条件语句if将读入文件分成了空文件与非空文件两种情况,通过读取单词长度来判断文件是否为空,当文件为空时提示文件无单词,非空时则执行正常的读入、排序、输出三项功能操作。
/*main函数部分*/
public static void main(String[] args) throws Exception
{
Vector<String> words = Input.InputManage(args);
int num = words.size();//获取单词长度
if (num == 0)
{
System.out.println("\n文件中无单词");//对于文件为空情况的处理
}
else
{
//进行下面的操作
ArrayList<Entry<String, Integer>> list=Output.printData((TreeMap<String, Integer>) calc.account(words));
FileOutputStream fos = null;
//output.print((TreeMap<String, Integer>) calc.account(words));
try{
File writename = new File("result.txt"); // 相对路径,如果没有则要建立一个新的output.txt文件
writename.createNewFile(); // 创建新文件
BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("result.txt"),"GBK"));//指定文件输出流的编码格式为GBK,解决编码依赖的问题
//p.print(output.printData(calc.account(words)));
Date day=new Date();
SimpleDateFormat df = new SimpleDateFormat("-------------------------执行日期:yyyy-MM-dd HH:mm:ss\r\n"); //构造执行时间记录
for (Map.Entry<String,Integer> entry1 :list) {
out.write(entry1.getKey() + " " + entry1.getValue()+"\r\n");//将排序后的关键字与对应值写入文档
}
out.write(df.format(day));//写入执行时间
out.flush(); // 把缓存区内容压入文件
}
catch(Exception e){
e.printStackTrace();
}
finally {
if (fos != null) {
fos.close();
}
}
}
}
}
以下为协助朱全的Output模块解释说明部分(接口部分与测试部分,灰色字体)
接口设计
public static TreeMap<String , Integer>account(Vector<String> strs)
统计读入的txt文档检索出的单词及词频
public static ArrayList printData(TreeMap<String , Integer>data)
对calc.class模块统计后的单词与词频进行排序并输出
接口实现
printData()函数传入的是一个Treemap,也就是说对于Key会按照首字母由a-z的顺序自动进行排序,其中key是单词,value是该单词出现的次数(原理为红黑二叉树算法)。随后将Treemap转化为ArrayList,再通过value创建比较器来实现value升序排列,排序结果符合项目需求。
/*单词与词频排序输出部分*/
public static ArrayList printData(TreeMap<String , Integer>data) throws IOException {
// TODO 自动生成的方法存根
/*利用Map的Comparator函数对关键字的值value进行排序并输出*/
Set<Entry<String, Integer>> entrys=data.entrySet(); //获取map缓存中的内容
ArrayList<Entry<String, Integer>> list = new ArrayList<Entry<String,Integer>>(data.entrySet());//将map转换为list便于排序
for (Entry<String, Integer> entry : entrys) { //通过增强for循环遍历输出
Comparator<Entry<String, Integer>> valueComparator = new Comparator<Entry<String,Integer>>() {//通过Comparator接口对集合对象进行排序
public int compare(Entry<String, Integer> o1,Entry<String, Integer> o2) { //定义比较函数的方法体
// TODO自动生成方法存根
return o1.getValue()-o2.getValue();
}
};
Collections.sort(list,valueComparator); // 调用系统自带函数对list中关键字的数值进行排序
}
return list;
}
测试设计
- 测试设计思路:首先要尽量覆盖所能够考虑到的所有出错情况,模块内应当采用白盒测试包括判定测试、等价类测试与边界测试,模块间由于不易观察出细节应采用黑盒测试。就output输出模块而言,printData()函数的测试设计主要为黑盒测试设计,辅助使用白盒测试设计。具体操作步骤为:首先创建并初始化一个LinkedHashMap(有序,解决了Hashmap无顺序的问题),随后调用printData()函数,并将实际输出与期望输出利用断言进行对比,进而得出测试结果。
- 测试用例设计(20个)如下:
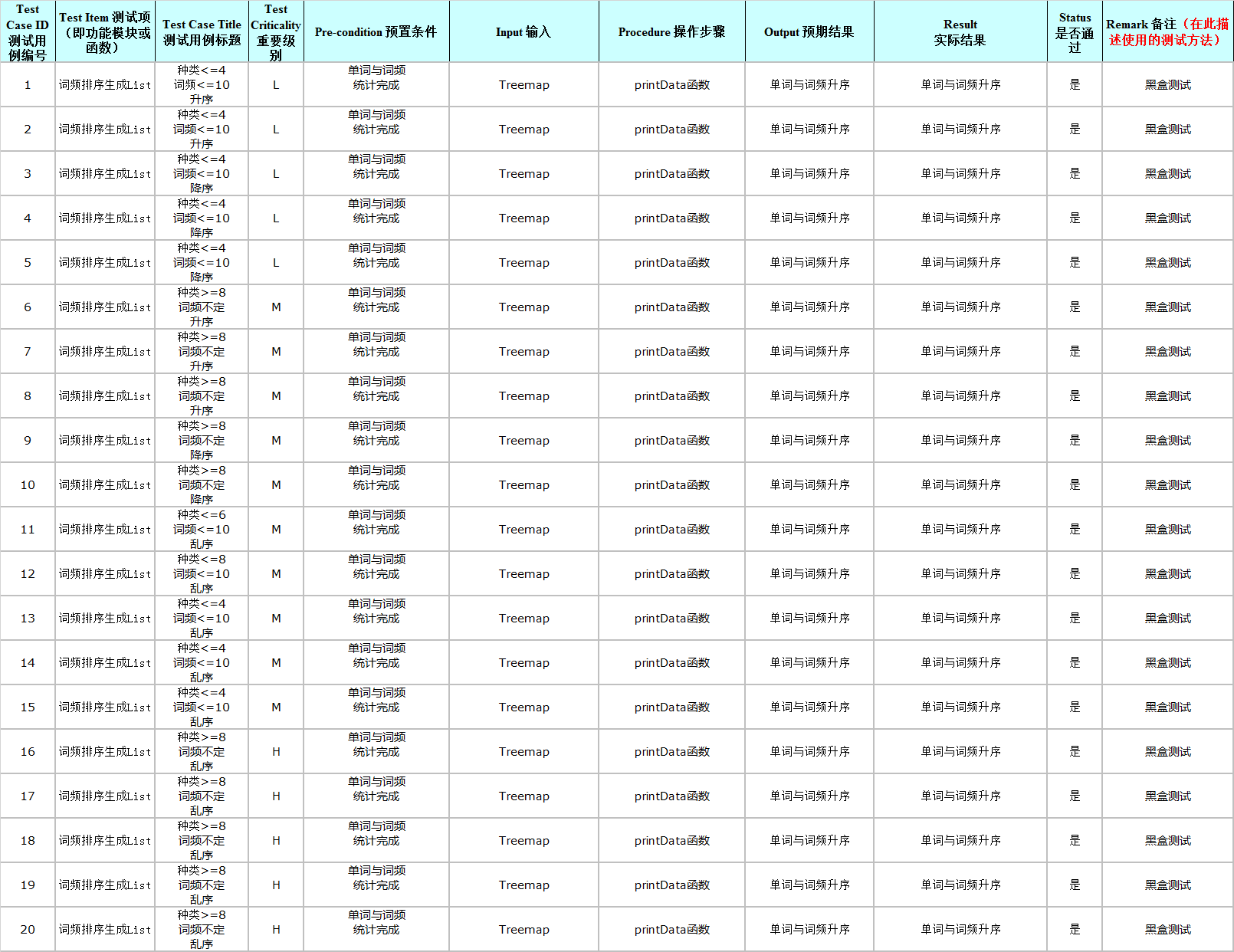
测试结果
测试评价
output模块的printData()所有测试单元顺利通过,并且由于使用了LinkedHashMap,大大地简化了测试的流程,提高了测试脚本的整体质量效率,可以较好地处理单词(key)与词频(value)的一般排序工作。
以上为协助朱全的Output模块解释说明部分(接口部分与测试部分,灰色字体)
小组贡献
我负责的是整体架构与代码整合部分,一个项目的整体架构决定了项目的功能模块划分、小组成员分工以及模块进度的安排,同时我在架构的过程中指明了各模块在实现的过程中应当注意的细节和问题,在一定程度上帮助了其他组员提高开发的效率。
后期我支援了朱全的output模块帮助他实现了词频的排序与结果的输出,同时提出了用LinkedHashMap代替Treemap进行测试的建议完成了针对输出模块测试脚本的编写;同时我还在main函数中对于输入和输出一些考虑不到位的地方进行了优化,如空文件的判断处理和结果输出的执行时间追踪,这些都能够帮助我们这个程序整体更好地运行。
所以综合的来看,我做的工作还是比较重要的,所以我的小组贡献占比是0.25,我对本次自己所做的工作还是比较满意的。
小组贡献评分
0.25
二、拓展功能部分:静态测试
1、开发规范理解——现代软件工程讲义3 代码规范与代码复审
代码风格规范:1、对于缩进,在Tab键与2、4、8空格中应当选用4空格,因为编译环境本身有自身的默认格式包括段落、语句的主次,不同的情况下使用Tab键会出现不同的长度,导致代码无法对齐,而2、4、8空格从空间距离给人的舒适感上来看4个空格是最优的选择;2、对于命名,通用的“匈牙利命名法”优点在于同时兼顾了语义和类型两个方面,例如str_result,程序员一眼就能看出这个变量是字符串类型并且表示的是结果,在一定程度上提高了编程的效率;3、对于注释的必要性,我认为这是一个程序的代码中非常重要和关键的一部分,缺少注释的代码总是让其他人理解代码时一头雾水,也不利于程序员在优化修改代码时可以根据注释将新旧代码功能进行对照,特别是在程序员自定义的类或者方法时,注释扮演着一个举足轻重的角色。
代码设计规范:1、对于错误处理与断言,我们应当合理地辨析好二者之间的关系,断言是程序员对于某些语句的执行结果有肯定的预期时使用的,例如断言(i!=null),则后面就可以直接使用,而错误处理是程序员认为某事即将发生时使用的,具体操作是对一个执行语句分成功和失败两种情况考虑并得出相应的结果;2、对于异常的捕获和抛出,不要用异常作为逻辑控制来处理程序的主要流程,应当在充分考虑了异常的花销占比的情况下对其进行使用,直接跳过异常、不考虑不合理操作可能产生的异常情况,会导致程序在运行的时候即使出现了错误却不能捕捉抛出异常,降低代码的可读性和执行效率。3、对于类型继承,使用时应当慎重一些,只有在必要时才使用类型继承,因为类型的继承会增加代码的层次结构,实例化继承类的机制是 先复制父类成员到内存中,然后复制自己的成员。然后执行父类构造函数,然后执行自己的构造函数,这会在一定程度上影响程序的执行速度。
2、组员代码评价——针对朱全的Output.class的map排序部分
map排序部分代码如下:
/*map值排序部分*/
public static ArrayList printData(TreeMap<String , Integer>data) throws IOException {
// TODO 自动生成的方法存根
/*利用Map的Comparator函数对关键字的值value进行排序并输出*/
Set<Entry<String, Integer>> entrys=data.entrySet(); //获取map缓存中的内容
ArrayList<Entry<String, Integer>> list = new ArrayList<Entry<String,Integer>>(data.entrySet());//将map转换为list便于排序
for (Entry<String, Integer> entry : entrys) { //通过增强for循环遍历输出
Comparator<Entry<String, Integer>> valueComparator = new Comparator<Entry<String,Integer>>() {//通过Comparator接口对集合对象进行排序
public int compare(Entry<String, Integer> o1,Entry<String, Integer> o2) { //定义比较函数的方法体
// TODO自动生成方法存根
return o1.getValue()-o2.getValue();
}
};
Collections.sort(list,valueComparator); // 调用系统自带函数对list中关键字的数值进行排序
}
1、 缩进部分,程序段大体采用了4空格缩进的方式,少部分用的还是tab键缩进,故而程序段总的看起来还是比较规范整齐的。
2、 命名部分,命名并未采用“匈牙利命名法”,部分命名如list存在二义性,无法根据语义判断其作用,类型可以看出是ArrayList型。
3、 注释部分,程序段的注释相对比较精简完整,但是部分注释的内容与代码存在关联性不大的问题。
4、 错误处理与断言部分,程序段未使用错误处理与断言,根据功能和可维护性来看,建议使用一下错误处理。
5、 异常部分,程序段充分考虑了异常的捕获与抛出,对IO异常进行了处理。
6、 类型继承,由于确实没有继承的必要,故而未使用类型继承,保证执行效率。
3、静态代码检查
静态代码检查工具:FindBugs 3.0.1
FindBugs下载链接地址:https://sourceforge.net/projects/findbugs/files/findbugs/1.3.9/findbugs-1.3.9.zip/download?use_mirror=jaist&download=
检查结果如下所示:

缺陷一:类名应该以大写字母开头。
类名应该是名词,在混合情况下,每个内部词的首字母大写。尽量保持类名的简单和描述性。使用完整的单词——避免首字母缩写和缩写(除非缩写词比长格式更广泛使用,比如URL或HTML)。
分析改进:我的类名为wcMain,小写字母开头,应当改为WcMain,这是一个不好的命名习惯,以后应当努力克服改进。
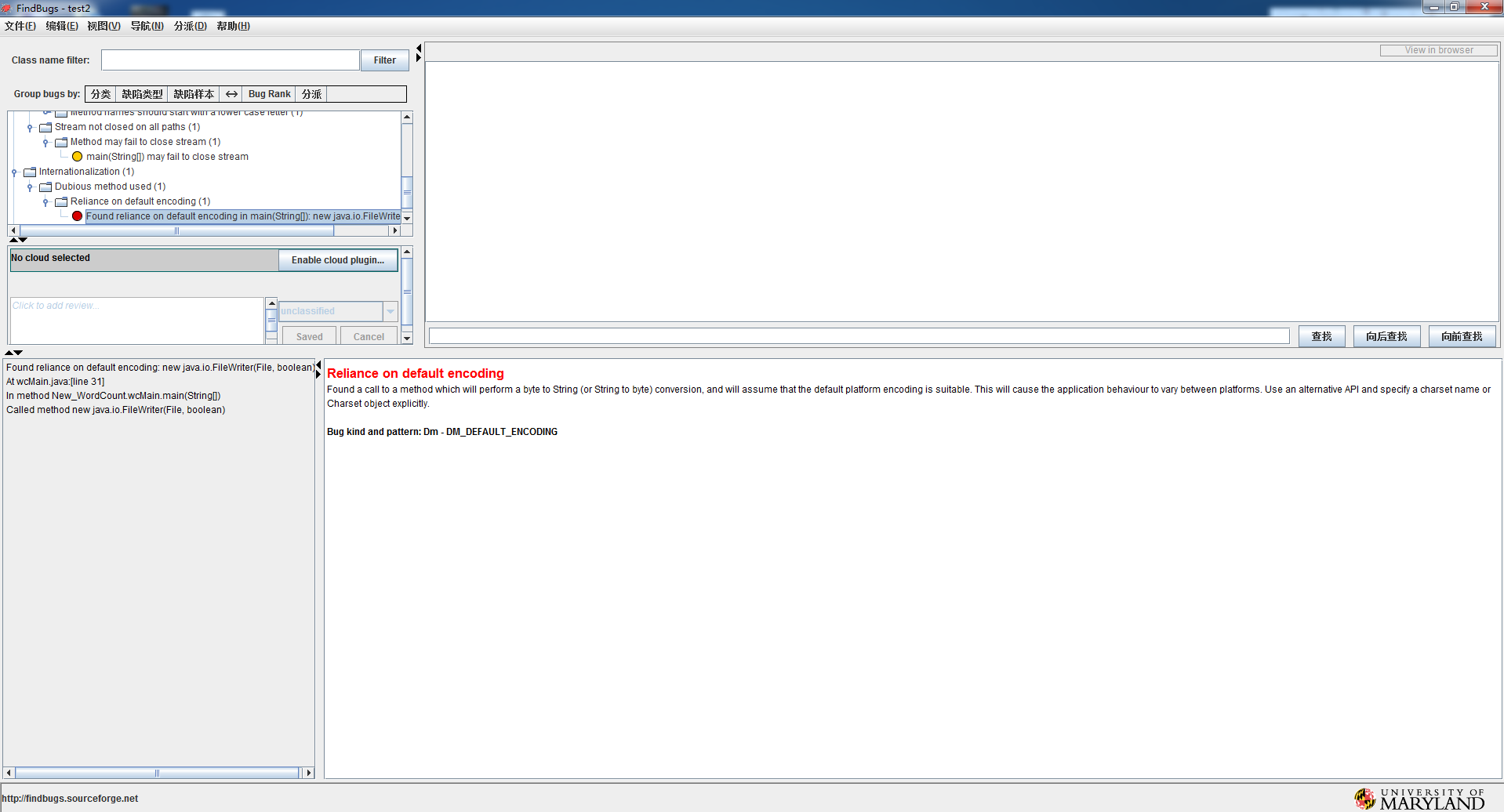
缺陷二:依赖默认编码
找到对一个方法的调用,该方法将执行一个字节到字符串(或字符串到字节)转换,并假定默认的平台编码是合适的。这将导致应用程序行为在不同的平台之间变化。使用另一个API并显式地指定charset名称或charset对象。
分析改进:由于文件是输出到.txt文件中,但是Myeclipse的编码格式并不是.txt的GBK,所以原语句应当指定输出编码格式,解决代码依赖的问题
原语句改为:BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("result.txt"),"GBK"));
4、个人代码改进
类名改为WcMain,同时对于输出文件流指定编码为GBK,加入finally来确保关闭输出流,代码风格规范与代码设计规范依照邹欣老师的《代码规范与代码复审》对相关部分进行优化处理。
改进后的代码如下:
public class WcMain {
public static void main(String[] args) throws Exception
{
Vector<String> words = Input.InputManage(args);
int num = words.size();//获取单词长度
if (num == 0)
{
System.out.println("\n文件中无单词");//对于文件为空情况的处理
}
else
{
//进行下面的操作
ArrayList<Entry<String, Integer>> list=Output.printData((TreeMap<String, Integer>) calc.account(words));
FileOutputStream fos = null;
//output.print((TreeMap<String, Integer>) calc.account(words));
try{
File writename = new File("result.txt"); // 相对路径,如果没有则要建立一个新的output.txt文件
writename.createNewFile(); // 创建新文件
BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("result.txt"),"GBK"));//指定文件输出流的编码格式为GBK,解决编码依赖的问题
//p.print(output.printData(calc.account(words)));
Date day=new Date();
SimpleDateFormat df = new SimpleDateFormat("-------------------------执行日期:yyyy-MM-dd HH:mm:ss\r\n"); //构造执行时间记录
for (Map.Entry<String,Integer> entry1 :list) {
out.write(entry1.getKey() + " " + entry1.getValue()+"\r\n");//将排序后的关键字与对应值写入文档
}
out.write(df.format(day));//写入执行时间
out.flush(); // 把缓存区内容压入文件
}
catch(Exception e){
e.printStackTrace();
}
finally {
if (fos != null) {
fos.close();
}
}
}
}
}
小组代码分析
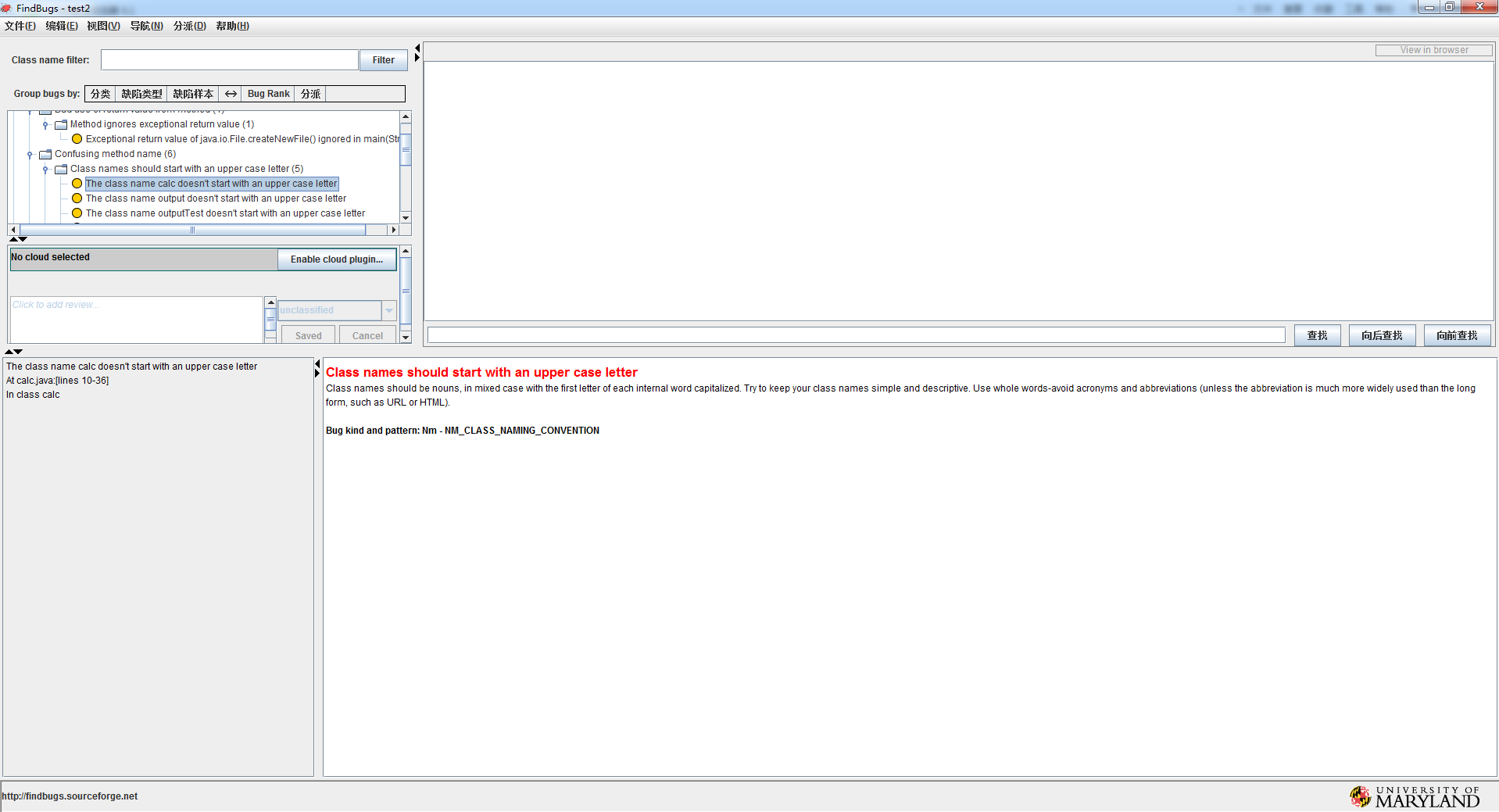
小组代码存在的其他缺陷:
缺陷一:方法忽略异常返回值。
该方法返回未选中的值。应该检查返回值,因为它可以指示异常或意外的函数执行。例如,如果文件不能被成功删除(而不是抛出异常),File.delete()方法将返回false。如果您不检查结果,您将不会注意到方法调用是否通过返回非典型的返回值来表示意外行为。
改进措施:原语句改为ArrayList<Entry<String, Integer>> list=Output.printData((TreeMap<String, Integer>) calc.account(words));
缺陷二:类名应该以大写字母开头。
类名应该是名词,在混合情况下,每个内部词的首字母大写。尽量保持类名的简单和描述性。使用完整的单词——避免首字母缩写和缩写(除非缩写词比长格式更广泛使用,比如URL或HTML)。
改进措施:对类名统一进行修改,calc改为Clac,output改为Output。
缺陷三:没有效率地使用keySet迭代器而不是entrySet迭代器。
该方法使用从keySet迭代器检索的键来访问映射条目的值。在map的entrySet上使用迭代器更有效,以避免map .get(key)查找。
将Set<String> set = expectList.keySet();中的keyset()改为entrySet(),在entrtSet上使用迭代器。
代码规范存在的问题:
1、 命名部分,命名并未采用“匈牙利命名法”,部分命名如list存在二义性,无法根据语义判断其作用,类型可以看出是ArrayList型。
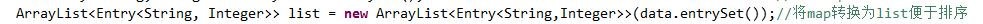
2、 注释部分,程序段的注释相对比较精简完整,但是部分注释的内容与代码存在关联性不大的问题。

3、 错误处理与断言部分,有的程序段未使用错误处理与断言,根据功能和可维护性来看,建议使用一下错误处理。

三、高级功能部分:性能测试和优化
1、数据集设计思路
一个为选取的较大的英文小说的txt,一个为自己用代码写的用规定字符随机生成的不同大小的txt。
length很小时执行结果
a 1
b 1
else 1
exception 1
good 1
if 1
input 1
inputmanage 1
it 1
learn 1
let 1
main 1
n 1
out 1
println 1
public 1
s 1
size 1
software 1
static 1
system 1
table 1
throws 1
vector 1
very 1
void 1
args 2
int 2
is 2
num 2
string 2
words 2
-------------------------执行日期:2018-04-07 23:27:08
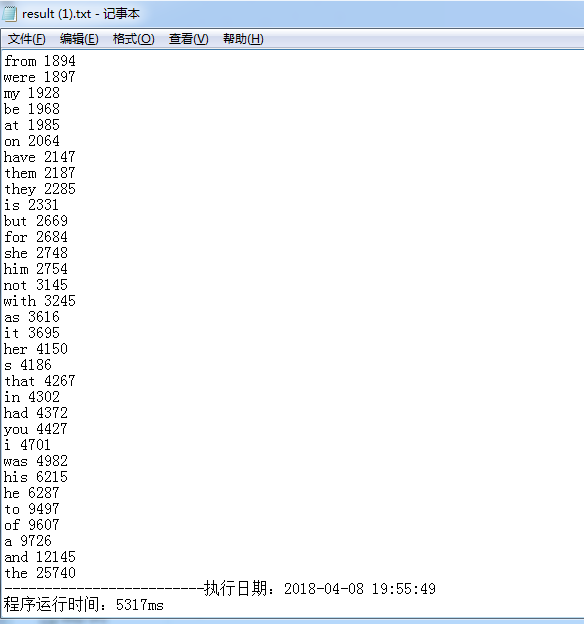
length=100000时执行结果

length=1000000时执行结果
2、同行评审
小组分工:主持人:宁宁17009 评审员:宁宁17009、朱全17031、周雨贝17011 作者:宁宁17009,朱全17031,周雨贝17011,易成龙17020 讲解员:易成龙17020 记录员:易成龙17020
我们对每个人代码规范,代码中可以提出的优化进行评审,最终认为影响性能指标的主要因素如下:
1.输入文件大小
2.输入文件中包含特殊字符比例
3.输入文件中包含由空格隔开的字符串数量
4.排序时所采用的算法是否高效。
5.硬件制约因素如:磁盘I/O,CPU性能等。
6.单词重复率,TreeMap中是否有该单词,如果一个单词重复率很高,那每次在Treemap中找单词的时间并加一的时间要比直接添加到TreeMap中的时间长。
参考文献
3、Java如何正确的使用try catch finally关闭文件流的总结















 2413
2413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









