







实验目的:
- 了解第一个用户进程创建过程
- 了解系统调用框架的实现机制
- 了解ucore如何实现系统调用sys_fork/sys_exec/sys_exit/sys_wait来进行进程管理
让用户进程在用户态执行,且在需要ucore支持时,可通过系统调用来让ucore提供服务。为此需要构造出第一个用户进程,并通过系统调用sys_fork/sys_exec/sys_exit/sys_wait来支持运行不同的应用程序,完成对用户进程的执行过程的基本管理。
练习0:填写已有实验
本实验依赖实验1/2/3/4。请把你做的实验1/2/3/4的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”的注释相应部分。注意:为了能够正确执行lab5的测试应用程序,可能需对已完成的实验1/2/3/4的代码进行进一步改进。
- alloc_proc
static struct proc_struct *
alloc_proc(void) {
// lab5修改
//PCB新增的条目,初始化进程等待状态
proc->wait_state = 0;
// 新proc相关的proc
proc->cptr = proc->optr = proc->yptr = NULL;
}
- idt_init
void idt_init(void) {
// lab5补充,从用户态切换到内核态的idt设置
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);
}
- do_fork
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc);
// lab5修改
set_links(proc);
// list_add(&proc_list, &proc->list_link);
// nr_process++;
}
local_intr_restore(intr_flag);
}
- trap_dispatch
static void
trap_dispatch(struct trapframe *tf) {
if (ticks % TICK_NUM == 0) {
// 设置当前的process current->need_resched = 1
assert(current != NULL);
// 设置need_resched = 1
current->need_resched = 1;
// print_ticks();
}
}
用户进程
参考:创建用户进程 · ucore_os_docs (gitbooks.io)
lab5里面,在Makefile里面可以看到
RUN_PREFIX := _binary_$(OBJDIR)_$(USER_PREFIX)
$(kernel): $(KOBJS) $(USER_BINS)
@echo + ld $@
$(V)$(LD) $(LDFLAGS) -T tools/kernel.ld -o $@ $(KOBJS) -b binary $(USER_BINS)
@$(OBJDUMP) -S $@ > $(call asmfile,kernel)
@$(OBJDUMP) -t $@ | $(SED) '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $(call symfile,kernel)
make的过程:
ld -m elf_i386 -nostdlib -T tools/user.ld -o obj/__user_pgdir.out obj/user/libs/panic.o obj/user/libs/syscall.o obj/user/libs/ulib.o obj/user/libs/initcode.o obj/user/libs/stdio.o obj/user/libs/umain.o obj/libs/string.o obj/libs/printfmt.o obj/libs/hash.o obj/libs/rand.o obj/user/pgdir.o
ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel obj/kern/init/entry.o obj/kern/init/init.o obj/kern/libs/stdio.o obj/kern/libs/readline.o obj/kern/debug/panic.o obj/kern/debug/kdebug.o obj/kern/debug/kmonitor.o obj/kern/driver/ide.o obj/kern/driver/clock.o obj/kern/driver/console.o obj/kern/driver/picirq.o obj/kern/driver/intr.o obj/kern/trap/trap.o obj/kern/trap/vectors.o obj/kern/trap/trapentry.o obj/kern/mm/vmm.o obj/kern/mm/swap_fifo.o obj/kern/mm/swap.o obj/kern/mm/kmalloc.o obj/kern/mm/swap_extended_clock.o obj/kern/mm/default_pmm.o obj/kern/mm/pmm.o obj/kern/mm/buddy_pmm.o obj/kern/fs/swapfs.o obj/kern/process/entry.o obj/kern/process/switch.o obj/kern/process/proc.o obj/kern/schedule/sched.o obj/kern/syscall/syscall.o obj/libs/string.o obj/libs/printfmt.o obj/libs/hash.o obj/libs/rand.o -b binary obj/__user_hello.out obj/__user_badarg.out obj/__user_forktree.out obj/__user_badsegment.out obj/__user_faultread.out obj/__user_divzero.out obj/__user_exit.out obj/__user_softint.out obj/__user_waitkill.out obj/__user_spin.out obj/__user_yield.out obj/__user_testbss.out obj/__user_faultreadkernel.out obj/__user_forktest.out obj/__user_pgdir.out
在lab5里面大概的内存布局:
/* *
* Virtual memory map: Permissions
* kernel/user
*
* 4G ------------------> +---------------------------------+
* | |
* | Empty Memory (*) |
* | |
* +---------------------------------+ 0xFB000000
* | Cur. Page Table (Kern, RW) | RW/-- PTSIZE
* VPT -----------------> +---------------------------------+ 0xFAC00000
* | Invalid Memory (*) | --/--
* KERNTOP -------------> +---------------------------------+ 0xF8000000
* | |
* | Remapped Physical Memory | RW/-- KMEMSIZE
* | |
* KERNBASE ------------> +---------------------------------+ 0xC0000000
* | Invalid Memory (*) | --/--
* USERTOP -------------> +---------------------------------+ 0xB0000000
* | User stack |
* +---------------------------------+
* | |
* : :
* | ~~~~~~~~~~~~~~~~ |
* : :
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* | User Program & Heap |
* UTEXT ---------------> +---------------------------------+ 0x00800000
* | Invalid Memory (*) | --/--
* | - - - - - - - - - - - - - - - |
* | User STAB Data (optional) |
* USERBASE, USTAB------> +---------------------------------+ 0x00200000
* | Invalid Memory (*) | --/--
* 0 -------------------> +---------------------------------+ 0x00000000
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired.
*
* */
lab4与lab5的init_main方法的区别
// lab4
static int
init_main(void *arg) {
cprintf("this initproc, pid = %d, name = \"%s\"\n", current->pid, get_proc_name(current));
cprintf("To U: \"%s\".\n", (const char *)arg);
cprintf("To U: \"en.., Bye, Bye. :)\"\n");
return 0;
}
// lab5
static int
init_main(void *arg) {
size_t nr_free_pages_store = nr_free_pages();
size_t kernel_allocated_store = kallocated();
int pid = kernel_thread(user_main, NULL, 0);
if (pid <= 0) {
panic("create user_main failed.\n");
}
while (do_wait(0, NULL) == 0) {
schedule();
}
cprintf("all user-mode processes have quit.\n");
assert(initproc->cptr == NULL && initproc->yptr == NULL && initproc->optr == NULL);
assert(nr_process == 2);
assert(list_next(&proc_list) == &(initproc->list_link));
assert(list_prev(&proc_list) == &(initproc->list_link));
cprintf("init check memory pass.\n");
return 0;
}
lab5通过kernel_thread新建了一个user_main线程来执行用户态的进程,do_wait等待子进程user_main退出。
再看kernel_execve与user_main
static int
kernel_execve(const char *name, unsigned char *binary, size_t size) {
int ret, len = strlen(name);
asm volatile (
"int %1;"
: "=a" (ret)
: "i" (T_SYSCALL), "0" (SYS_exec), "d" (name), "c" (len), "b" (binary), "D" (size)
: "memory");
return ret;
}
#define __KERNEL_EXECVE(name, binary, size) ({ \
cprintf("kernel_execve: pid = %d, name = \"%s\".\n", \
current->pid, name); \
kernel_execve(name, binary, (size_t)(size)); \
})
#define KERNEL_EXECVE(x) ({ \
extern unsigned char _binary_obj___user_##x##_out_start[], \
_binary_obj___user_##x##_out_size[]; \
__KERNEL_EXECVE(#x, _binary_obj___user_##x##_out_start, \
_binary_obj___user_##x##_out_size); \
})
#define __KERNEL_EXECVE2(x, xstart, xsize) ({ \
extern unsigned char xstart[], xsize[]; \
__KERNEL_EXECVE(#x, xstart, (size_t)xsize); \
})
static int
user_main(void *arg) {
#ifdef TEST
KERNEL_EXECVE2(TEST, TESTSTART, TESTSIZE);
#else
KERNEL_EXECVE(exit);
#endif
panic("user_main execve failed.\n");
}
_binary_obj___user_##x##_out_start和_binary_obj___user_##x##_out_size都是编译的时候自动生成的符号。注意这里的##x##,按照C语言宏的语法,会直接把x的变量名代替进去。即如果x是hello,那么
就是_binary_obj___user_hello_out_start和_binary_obj___user_hello_out_size
于是,我们在user_main()所做的,就是执行了
kern_execve("exit", _binary_obj___user_exit_out_start,_binary_obj___user_exit_out_size)。
实际上,就是加载exit程序并在user_main这个进程里开始执行。这时user_main就从内核进程变成了用户进程。
练习1: 加载应用程序并执行(需要编码)
do_execv函数调用load_icode(位于kern/process/proc.c中)来加载并解析一个处于内存中的ELF执行文件格式的应用程序,建立相应的用户内存空间来放置应用程序的代码段、数据段等,且要设置好proc_struct结构中的成员变量trapframe中的内容,确保在执行此进程后,能够从应用程序设定的起始执行地址开始执行。需设置正确的trapframe内容。
练习1主要是设置好trapframe,即保证跳转到用户进程后能正确执行,其实在注释里面已经讲的很清楚了。
static int
load_icode(unsigned char *binary, size_t size) {
......
/* LAB5:EXERCISE1 YOUR CODE
* should set tf_cs,tf_ds,tf_es,tf_ss,tf_esp,tf_eip,tf_eflags
* NOTICE: If we set trapframe correctly, then the user level process can return to USER MODE from kernel. So
* tf_cs should be USER_CS segment (see memlayout.h)
* tf_ds=tf_es=tf_ss should be USER_DS segment
* tf_esp should be the top addr of user stack (USTACKTOP)
* tf_eip should be the entry point of this binary program (elf->e_entry)
* tf_eflags should be set to enable computer to produce Interrupt
*/
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
// tf->tf_esp
tf->tf_esp = USTACKTOP;
// tf->eip
tf->tf_eip = elf->e_entry;
// tf->eflags
tf->tf_eflags = FL_IF;
......
}
请在实验报告中简要说明你的设计实现过程。
其实就是设置好相关的代码段、数据段、esp(栈顶寄存器)、eip(执行的入口),以及eflags寄存器(这里只Interrupt Flag, 该标志用于控制处理器对可屏蔽中断请求(maskable interrupt requests)的响应。置1以响应可屏蔽中断,反之则禁止可屏蔽中断)。
请在实验报告中描述当创建一个用户态进程并加载了应用程序后,CPU是如何让这个应用程序最终在用户态执行起来的。即这个用户态进程被ucore选择占用CPU执行(RUNNING态)到具体执行应用程序第一条指令的整个经过。
上面已经介绍过用户进程了,从user_main开始看:
user_main->KERNEL_EXECVE->kern_execve("exit", _binary_obj___user_exit_out_start,_binary_obj___user_exit_out_size)
再看kernel_execve
static int
kernel_execve(const char *name, unsigned char *binary, size_t size) {
int ret, len = strlen(name);
asm volatile (
"int %1;"
: "=a" (ret)
: "i" (T_SYSCALL), "0" (SYS_exec), "d" (name), "c" (len), "b" (binary), "D" (size)
: "memory");
return ret;
}
通过内联汇编INT 0x80执行软中断,且把5个参数传过去:
0:SYS_exec->系统调用号
1:name->方法名称
2:len->方法名称长度
3:binary->方法二进制起始地址
4:size->方法二进制长度
然后,kernel_execve->vectors.S(vector128)->trapentry.S(__alltraps,保存中断前的寄存器的信息到一个oldtrapframe结构里面)->trap.c(trap, current肯定不为NULL)->trap_in_kernel(tf,更改tf指向的CS寄存器为内核代码段选择子KERNEL_CS)->trap_dispatch->syscall->tf->tf_regs.reg_eax = syscalls[num](arg)(调用syscalls,并把结果放到tf->tf_regs.reg_eax)->do_execve->load_icode->trapentry.S( __trapret, iret)->initcode.S->umain->main->exit.c:main->中断->
vectors.S(vector128)->trapentry.S(__alltraps,保存中断前的寄存器的信息到一个oldtrapframe结构里面)->trap.c(trap, current肯定不为NULL)->trap_in_kernel(tf,更改tf指向的CS寄存器为内核代码段选择子KERNEL_CS)->trap_dispatch->syscall
->sys_putc->…
这样一直不断的执行用户进程,不断的通过软中断(INT 0x80)的方式,执行系统调用,调用系统提供的接口。
int
main(void) {
int pid, code;
cprintf("I am the parent. Forking the child...\n");
if ((pid = fork()) == 0) {
cprintf("I am the child.\n");
yield();
yield();
yield();
yield();
yield();
yield();
yield();
exit(magic);
}
else {
cprintf("I am parent, fork a child pid %d\n",pid);
}
assert(pid > 0);
cprintf("I am the parent, waiting now..\n");
assert(waitpid(pid, &code) == 0 && code == magic);
assert(waitpid(pid, &code) != 0 && wait() != 0);
cprintf("waitpid %d ok.\n", pid);
cprintf("exit pass.\n");
return 0;
}
练习2: 父进程复制自己的内存空间给子进程(需要编码)
创建子进程的函数do_fork在执行中将拷贝当前进程(即父进程)的用户内存地址空间中的合法内容到新进程中(子进程),完成内存资源的复制。具体是通过copy_range函数(位于kern/mm/pmm.c中)实现的,请补充copy_range的实现,确保能够正确执行。
代码如下
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
......
// (1) find src_kvaddr: the kernel virtual address of page
void *src_kvaddr = page2kva(page);
// (2) find dst_kvaddr: the kernel virtual address of npage
void *dst_kvaddr = page2kva(npage);
// (3) memory copy from src_kvaddr to dst_kvaddr, size is PGSIZE
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
// (4) build the map of phy addr of nage with the linear addr start
// 将该页面设置至对应的PTE中
ret = page_insert(to, npage, start, perm);
......
return 0;
}
请在实验报告中简要说明如何设计实现”Copy on Write 机制“,给出概要设计,鼓励给出详细设计。
Copy-on-write(简称COW)的基本概念是指如果有多个使用者对一个资源A(比如内存块)进行读操作,则每个使用者只需获得一个指向同一个资源A的指针,就可以该资源了。若某使用者需要对这个资源A进行写操作,系统会对该资源进行拷贝操作,从而使得该“写操作”使用者获得一个该资源A的“私有”拷贝—资源B,可对资源B进行写操作。该“写操作”使用者对资源B的改变对于其他的使用者而言是不可见的,因为其他使用者看到的还是资源A。
设计实现”Copy on Write 机制“
其实就是copy_range里面需要根据参数share来判断是不是共享,如果是,则使用COW机制。
需要考虑的是,当用户态的父进程创建子进程过程中,父进程会把自己申请的用户内存空间设置为只读,即把PTE属性设置为只读。子进程共享使用父进程占用的用户内存空间的页面,然后当其中任意一个进程(父进程、子进程,可能有多个子进程)修改对应用户内存空间的某个页面时,发生page_fault,然后ucore通过page fault完成页面的拷贝,使得两个进程都有各自的内存页面。这样一个进程所做的修改不会被另外一个进程可见了。
练习3: 阅读分析源代码,理解进程执行 fork/exec/wait/exit 的实现,以及系统调用的实现(不需要编码)
请在实验报告中简要说明你对 fork/exec/wait/exit函数的分析。并回答如下问题:
- 请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
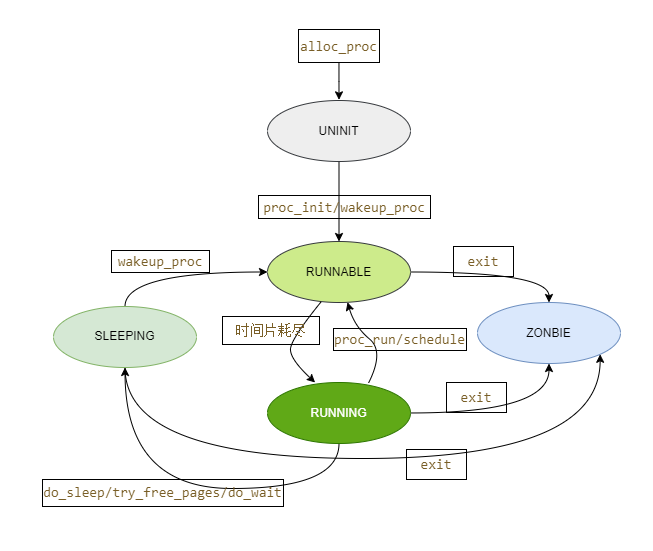
- 请给出ucore中一个用户态进程的执行状态生命周期图(包执行状态,执行状态之间的变换关系,以及产生变换的事件或函数调用)。(字符方式画即可)
do_fork
从父进程fork出来一个子进程,fork出来的进程关系图如下所示:
+----------------+
| parent process |
+----------------+
parent ^ \ ^ parent
/ \ \
/ \ cptr \
/ yptr V \ yptr
+-------------+ --> +-------------+ --> NULL
| old process | | New Process |
NULL <-- +-------------+ <-- +-------------+
optr optr
do_exec
do_exec是由sys_exec调用过来的,此函数做的事情比较简单回收当前线程的内存空间:
if (mm != NULL) {
lcr3(boot_cr3);
if (mm_count_dec(mm) == 0) {
exit_mmap(mm);
put_pgdir(mm);
mm_destroy(mm);
}
current->mm = NULL;
}
根据传入的程序二进制的起始地址*binary和大小size,调用load_icode设置好新的内存空间
int ret;
if ((ret = load_icode(binary, size)) != 0) {
goto execve_exit;
}
该函数几乎释放原进程所有的资源,除了PCB。也就是说,do_execve保留了原进程的PID、原进程的属性、原进程与其他进程之间的关系等等。
do_wait
一直等待,直到(特定)子进程退出后,该进程会彻底回收子进程所占的资源(比如子进程的内核栈和进程控制块)。如果pid = 0,等待回收特定的子进程(子进程的pid = pid),如果 != 0,等待回收所有子进程。
代码如下:
int
do_wait(int pid, int *code_store) {
...
if (haskid) {
// 如果没有,设置当前进程状态为PROC_SLEEPING,并执行schedule调度其他进程运行
// 当该进程的某个子进程结束运行后,当前进程会被唤醒,并在do_wait函数中回收子进程的PCB内存资源。
// wait_state是WT_CHILD
current->state = PROC_SLEEPING;
current->wait_state = WT_CHILD;
schedule();
if (current->flags & PF_EXITING) {
do_exit(-E_KILLED);
}
goto repeat;
}
return -E_BAD_PROC;
// 如果有,则回收该进程并函数返回
found:
if (proc == idleproc || proc == initproc) {
panic("wait idleproc or initproc.\n");
}
if (code_store != NULL) {
*code_store = proc->exit_code;
}
local_intr_save(intr_flag);
{
unhash_proc(proc);
remove_links(proc);
}
local_intr_restore(intr_flag);
put_kstack(proc);
kfree(proc);
return 0;
}
在下面的do_exit会有对父进程的唤醒
if (proc->state == PROC_ZOMBIE) {
if (initproc->wait_state == WT_CHILD) {
wakeup_proc(initproc);
}
}
do_exit
释放进程自身所占内存空间和相关内存管理(如页表等)信息所占空间,唤醒父进程,好让父进程收了自己,让调度器切换到其他进程。
代码如下:
// do_exit - called by sys_exit
// 1. call exit_mmap & put_pgdir & mm_destroy to free the almost all memory space of process
// 2. set process' state as PROC_ZOMBIE, then call wakeup_proc(parent) to ask parent reclaim itself.
// 3. call scheduler to switch to other process
int
do_exit(int error_code) {
if (current == idleproc) {
panic("idleproc exit.\n");
}
if (current == initproc) {
panic("initproc exit.\n");
}
struct mm_struct *mm = current->mm;
if (mm != NULL) {
// cr3切换为内核态的页目录表地址
lcr3(boot_cr3);
// 释放进程自身所占内存空间和相关内存管理(如页表等)信息所占空间
if (mm_count_dec(mm) == 0) {
exit_mmap(mm);
put_pgdir(mm);
mm_destroy(mm);
}
current->mm = NULL;
}
// 更改当前进程的状态
current->state = PROC_ZOMBIE;
current->exit_code = error_code;
bool intr_flag;
struct proc_struct *proc;
local_intr_save(intr_flag);
{
// 唤醒父进程回收自己
proc = current->parent;
if (proc->wait_state == WT_CHILD) {
wakeup_proc(proc);
}
while (current->cptr != NULL) {
proc = current->cptr;
current->cptr = proc->optr;
proc->yptr = NULL;
if ((proc->optr = initproc->cptr) != NULL) {
initproc->cptr->yptr = proc;
}
proc->parent = initproc;
initproc->cptr = proc;
if (proc->state == PROC_ZOMBIE) {
if (initproc->wait_state == WT_CHILD) {
wakeup_proc(initproc);
}
}
}
}
local_intr_restore(intr_flag);
// 线程调度
schedule();
panic("do_exit will not return!! %d.\n", current->pid);
}
总的来说:
fork会修改创建的子进程的状态为PROC_RUNNABLE,而当前进程状态不变。
exec不修改当前进程的状态,但会替换内存空间里所有的数据与代码。
wait会先检测是否存在子进程。如果存在进入PROC_ZONBIE的子进程,则回收该进程并函数返回。但若存在尚处于PROC_RUNNABLE的子进程,则当前进程会进入PROC_SLEEPING状态,并等待子进程唤醒。
exit会将当前进程状态设置为PROC_ZONBIE,并唤醒父进程,使其处于PROC_RUNNABLE的状态,之后主动让出CPU。
ucore中一个用户态进程的执行状态生命周期图:
扩展练习 Challenge :实现 Copy on Write (COW)机制
给出实现源码,测试用例和设计报告(包括在cow情况下的各种状态转换(类似有限状态自动机)的说明)。
这个扩展练习涉及到本实验和上一个实验“虚拟内存管理”。在ucore操作系统中,当一个用户父进程创建自己的子进程时,父进程会把其申请的用户空间设置为只读,子进程可共享父进程占用的用户内存空间中的页面(这就是一个共享的资源)。当其中任何一个进程修改此用户内存空间中的某页面时,ucore会通过page fault异常获知该操作,并完成拷贝内存页面,使得两个进程都有各自的内存页面。这样一个进程所做的修改不会被另外一个进程可见了。请在ucore中实现这样的COW机制。
由于COW实现比较复杂,容易引入bug,请参考 https://dirtycow.ninja/ 看看能否在ucore的COW实现中模拟这个错误和解决方案。需要有解释。
参考练习3的COW机制设计和uCore实验 - Lab5 | Kiprey’s Blog,需要修改两个函数:copy_range和do_pgfault。代码如下:
copy_range
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
// 0x00200000 ~ 0xB0000000
assert(USER_ACCESS(start, end));
// copy content by page unit.
do {
//call get_pte to find process A's pte according to the addr start
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL) {
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
//call get_pte to find process B's pte according to the addr start. If pte is NULL, just alloc a PT
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
// alloc a page for process B
struct Page *npage=alloc_page();
assert(page!=NULL);
assert(npage!=NULL);
int ret=0;
if (share) {
cprintf("Sharing the page 0x%x\n", page2kva(page));
// 物理页面共享,并设置两个PTE上的标志位为只读
page_insert(from, page, start, perm & ~PTE_W);
ret = page_insert(to, page, start, perm & ~PTE_W);
} else {
// (1) find src_kvaddr: the kernel virtual address of page
void *src_kvaddr = page2kva(page);
// (2) find dst_kvaddr: the kernel virtual address of npage
void *dst_kvaddr = page2kva(npage);
// (3) memory copy from src_kvaddr to dst_kvaddr, size is PGSIZE
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
// (4) build the map of phy addr of nage with the linear addr start
// 将该页面设置至对应的PTE中
ret = page_insert(to, npage, start, perm);
}
assert(ret == 0);
}
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
do_pgfault
int
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) {
// 页访问异常错误码有32位。
// 位0为1表示对应物理页不存在;
// 位1为1表示写异常(比如写了只读页;位2为1表示访问权限异常(比如用户态程序访问内核空间的数据)
// CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。
// CR2用于发生页异常时报告出错信息。当发生页异常时,处理器把引起页异常的线性地址保存在CR2中。
// 操作系统中对应的中断服务例程可以检查CR2的内容,从而查出线性地址空间中的哪个页引起本次异常。
int ret = -E_INVAL;
//try to find a vma which include addr
// 根据addr从vma中查找对应的vma_struct
DEBUG("mm = [%p], error_code = [%x], addr = [%x]", mm, error_code, addr);
struct vma_struct *vma = find_vma(mm, addr);
pgfault_num++;
//If the addr is in the range of a mm's vma?
DEBUG("mm = [%p], vma = [%p], addr = [%x]\n", mm, vma, addr);
if (vma == NULL || vma->vm_start > addr) {
cprintf("not valid addr %x, and can not find it in vma\n", addr);
goto failed;
}
//check the error_code
// 与 00000011
//
switch (error_code & 3) {
default:
/* error code flag : default is 3 ( W/R=1, P=1): write, present */
case 2: /* error code flag : (W/R=1, P=0): write, not present */
if (!(vma->vm_flags & VM_WRITE)) {
cprintf("do_pgfault failed: error code flag = write AND not present, but the addr's vma cannot write\n");
goto failed;
}
break;
case 1: /* error code flag : (W/R=0, P=1): read, present */
cprintf("do_pgfault failed: error code flag = read AND present\n");
goto failed;
case 0: /* error code flag : (W/R=0, P=0): read, not present */
if (!(vma->vm_flags & (VM_READ | VM_EXEC))) {
cprintf("do_pgfault failed: error code flag = read AND not present, but the addr's vma cannot read or exec\n");
goto failed;
}
}
/* IF (write an existed addr ) OR
* (write an non_existed addr && addr is writable) OR
* (read an non_existed addr && addr is readable)
* THEN
* continue process
*/
uint32_t perm = PTE_U;
if (vma->vm_flags & VM_WRITE) {
perm |= PTE_W;
}
addr = ROUNDDOWN(addr, PGSIZE);
ret = -E_NO_MEM;
pte_t *ptep=NULL;
// 根据get_pte来获取pte如果不存在,则分配一个新的
ptep = get_pte(mm->pgdir, addr, 1);
if (ptep == NULL) {
cprintf("get_pte in do_pgfault failed\n");
goto failed;
}
struct Page *p;
// 如果对应的物理页不存在,分配一个新的页,且把物理地址和逻辑地址映射
if (*ptep == 0) {
p = pgdir_alloc_page(mm->pgdir, addr, perm);
if (p == NULL) {
cprintf("alloc_page in do_pgfault failed\n");
goto failed;
}
} else {
struct Page *page=NULL;
// 如果当前页错误的原因是写入了只读页面
if (*ptep & PTE_P) {
// 写时复制:复制一块内存给当前进程
cprintf("\n\nCOW: ptep 0x%x, pte 0x%x\n",ptep, *ptep);
// 原先所使用的只读物理页
page = pte2page(*ptep);
// 如果该物理页面被多个进程引用
if (page_ref(page) > 1) {
struct Page* newPage = pgdir_alloc_page(mm->pgdir, addr, perm);
void * kva_src = page2kva(page);
void * kva_dest = page2kva(newPage);
memcpy(kva_dest, kva_src, PGSIZE);
} else {
page_insert(mm->pgdir, pa2page, addr, perm);
}
}
// 如果不全为0,则可能被交换到了swap磁盘中
if(swap_init_ok) {
struct Page *page=NULL;
int swapIn;
// 从磁盘中换出
swapIn = swap_in(mm, addr, &page);
if (swapIn != 0) {
cprintf("swap_in in do_pgfault failed\n");
goto failed;
}
// build the map of phy addr of an Page with the linear addr la
page_insert(mm->pgdir, page, addr, perm);
swap_map_swappable(mm, addr, page, 1);
page->pra_vaddr = addr;
} else {
cprintf("no swap_init_ok, but ptep is %x, failed\n", *ptep);
goto failed;
}
}
ret = 0;
failed:
return ret;
}
参考:
uCore实验 - Lab5 | Kiprey’s Blog















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









