







参考书目: 《R的极客理想——工具篇 》
xts介绍
xts是对时间序列数据(zoo)的一种扩展实现,目标是为了统一时间序列的操作接口。实际上,xts类型继承了zoo类型,丰富了时间序列数据处理的函数,API定义更贴近使用者,更实用.
xts数据结构
xts扩展zoo的基础结构,由3部分组成,如图2-7所示。
索引部分:时间类型向量。
数据部分:以矩阵为基础类型,支持可以与矩阵相互转换的任何类型。
属性部分:附件信息,包括时区和索引时间类型的格式等。
xtsAPI介绍
(1)xts基础
xts: 定义xts数据类型,继承zoo类型。
coredata.xts: 查看或编辑xts对象的数据部分。
xtsAttributes: 查看或编辑xts对象的属性部分。
dimnames.xts: 查看或编辑xts维度名。
sample_matrix: 测试数据集,包括180条xts对象的记录,matrix类型。
xtsAPI: C语言API接口。
(2)类型转换
as.xts: 转换对象到xts(zoo)类型。
as.xts.methods: 转换对象到xts函数。
plot.xts: 为plot函数提供xts的接口作图。
.parseISO8601: 把字符串(ISO8601格式)输出为POSIXct类型的,包括开始时间和结束时间的list对象。
firstof: 创建一个开始时间,POSIXct类型。
lastof: 创建一个结束时间,POSIXct类型。
indexClass: 取索引类型。
.indexDate: 索引的日期。
.indexday: 索引的日期,同.indexDate。
.indexyday: 索引的年(日)值。
.indexmday: 索引的月(日)值。
.indexwday: 索引的周(日)值。
.indexweek: 索引的周值。
.indexmon: 索引的月值。
.indexyear: 索引的年值。
.indexhour: 索引的时值。
.indexmin: 索引的分值。
.indexsec: 索引的秒值。
(3)数据处理
align.time: 以下一个时间对齐数据,秒,分钟,小时。
endpoints: 按时间单元提取索引数据。
merge.xts: 合并多个xts对象,重写zoo::merge.zoo函数。
rbind.xts: 数据按行合并,为rbind函数提供xts的接口。
split.xts: 数据分割,为split函数,提供xts的接口。
na.locf.xts: 替换NA值,重写zoo:na.locf函数。
(4)数据统计
apply.daily: 按日分割数据,执行函数。
apply.weekly: 按周分割数据,执行函数。
apply.monthly: 按月分割数据,执行函数。
apply.quarterly: 按季分割数据,执行函数。
apply.yearly: 按年分割数据,执行函数。
to.period: 按期间分割数据。
period.apply: 按期间执行自定义函数。
period.max: 按期间计算最大值。
period.min: 按期间计算最小值。
period.prod: 按期间计算指数。
period.sum: 按期间求和。
nseconds: 计算数据集包括多少秒。
nminutes: 计算数据集包括多少分。
nhours: 计算数据集包括多少时。
ndays: 计算数据集包括多少日。
nweeks: 计算数据集包括多少周。
nmonths: 计算数据集包括多少月。
nquarters: 计算数据集包括多少季。
nyears: 计算数据集包括多少年。
periodicity: 查看时间序列的期间。
(5)辅助工具
first: 从开始到结束设置条件取子集。
last: 从结束到开始设置条件取子集。
timeBased: 判断是否是时间类型。
timeBasedSeq: 创建时间的序列。
diff.xts: 计算步长和差分。
isOrdered: 检查向量是否是顺序的。
make.index.unique: 强制时间唯一,增加毫秒随机数。
axTicksByTime: 计算X轴刻度标记位置按时间描述。
indexTZ: 查询xts对象的时区。
#xts使用
##基本操作
> sample.xts <- as.xts(sample_matrix, descr='my new xts object')
# 创建一个xts对象,并设置属性descr
> class(sample.xts) # xts是继承zoo类型的对象
[1] "xts" "zoo"
> str(sample.xts) # 打印对象结构
An 'xts' object on 2007-01-02/2007-06-30 containing:
Data: num [1:180, 1:4] 50 50.2 50.4 50.4 50.2 ...
- attr(*, "dimnames")=List of 2
..$ : NULL #行名
..$ : chr [1:4] "Open" "High" "Low" "Close" # 列名字
Indexed by objects of class: [POSIXct,POSIXt] TZ:
xts Attributes:
List of 1
$ descr: chr "my new xts object" #描述
> attr(sample.xts,'descr') # 查看对象的属性descr
[1] "my new xts object" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在[]中,通过字符串匹配进行xts数据查询。
> head(sample.xts['2007']) # 选出2007年的数据
Open High Low Close
2007-01-02 50.03978 50.11778 49.95041 50.11778
2007-01-03 50.23050 50.42188 50.23050 50.39767
2007-01-04 50.42096 50.42096 50.26414 50.33236
2007-01-05 50.37347 50.37347 50.22103 50.33459
2007-01-06 50.24433 50.24433 50.11121 50.18112
2007-01-07 50.13211 50.21561 49.99185 49.99185
> head(sample.xts['2007-03/']) # 选出2007年03月的数据
Open High Low Close
2007-03-01 50.81620 50.81620 50.56451 50.57075
2007-03-02 50.60980 50.72061 50.50808 50.61559
2007-03-03 50.73241 50.73241 50.40929 50.41033
2007-03-04 50.39273 50.40881 50.24922 50.32636
2007-03-05 50.26501 50.34050 50.26501 50.29567
2007-03-06 50.27464 50.32019 50.16380 50.16380
> head(sample.xts['2007-03-06/2007']) # 选出2007年03月06日到2007年的数据
Open High Low Close
2007-03-06 50.27464 50.32019 50.16380 50.16380
2007-03-07 50.14458 50.20278 49.91381 49.91381
2007-03-08 49.93149 50.00364 49.84893 49.91839
2007-03-09 49.92377 49.92377 49.74242 49.80712
2007-03-10 49.79370 49.88984 49.70385 49.88698
2007-03-11 49.83062 49.88295 49.76031 49.78806
> sample.xts['2007-01-03'] # 选出2007年01月03日的数据
Open High Low Close - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
用xts对象画图
用xts对象可以画曲线图和K线图,下面是产生这两种图的代码,首先是曲线图:
> data(sample_matrix)
> plot(as.xts(sample_matrix))
Warning message:
In plot.xts(as.xts(sample_matrix)) :
only the univariate series will be plotted- 1
- 2
- 3
- 4
- 5
警告信息提示,只有单变量序列将被绘制,即只画出第一列数据sample_matrix[,1]的曲线。
k线图
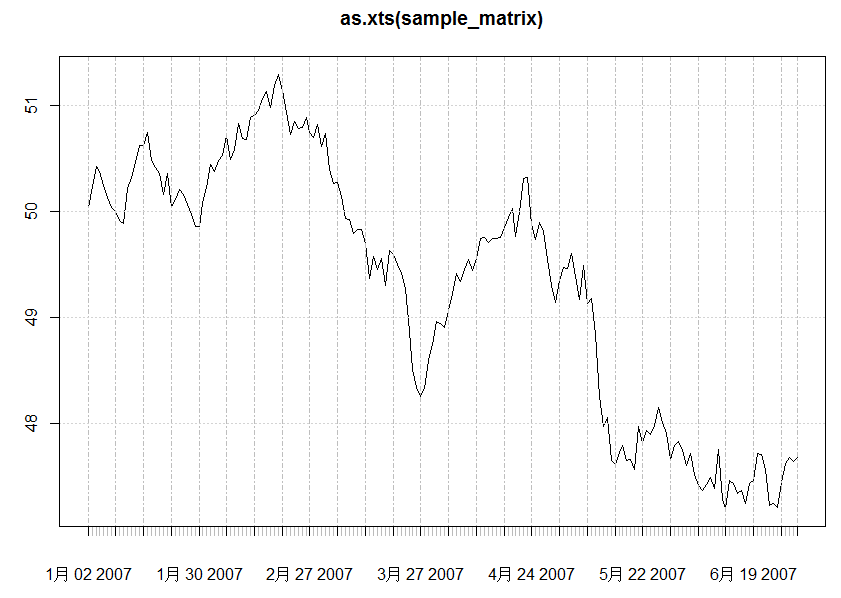
plot(as.xts(sample_matrix), type='candles') #画K线图- 1
Better financial plots can be found in the quantmod package, though these are generally incompatible with standard R graphics tools.
xts对象的类型转换
创建首尾时间函数firstof()和lastof()
> firstof(2000) # 2000年的第一天,时分秒显示省略
[1] "2000-01-01 CST"
> firstof(2005,01,01)
[1] "2005-01-01 CST"
> lastof(2007) # 2007年的最后一天,最后一秒
[1] "2007-12-31 23:59:59.99998 CST"
> lastof(2007,10)
[1] "2007-10-31 23:59:59.99998 CST"
> .parseISO8601('2000') # 以ISO8601格式,创建2000年首尾时间
$first.time
[1] "2000-01-01 CST"
$last.time
[1] "2000-12-31 23:59:59.99998 CST"
> .parseISO8601('2000-05/2001-02')
# 以ISO8601格式,创建2000年05月开始,2001年02月结束的时间
$first.time
[1] "2000-05-01 CST"
$last.time
[1] "2001-02-28 23:59:59.99998 CST"
> .parseISO8601('2000-01/02')
$first.time
[1] "2000-01-01 CST"
$last.time
[1] "2000-02-29 23:59:59.99998 CST"
> .parseISO8601('T08:30/T15:00')
$first.time
[1] "1970-01-01 08:30:00 CST"
$last.time
[1] "1970-12-31 15:00:59.99999 CST" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
创建以时间类型为索引的xts对象
> x <- timeBasedSeq('2010-01-01/2010-01-02 12:00') # 创建POSIXt类型时间
> head(x)
[1] "2010-01-01 00:00:00 CST"
[2] "2010-01-01 00:01:00 CST"
[3] "2010-01-01 00:02:00 CST"
[4] "2010-01-01 00:03:00 CST"
[5] "2010-01-01 00:04:00 CST"
[6] "2010-01-01 00:05:00 CST"
> class(x)
[1] "POSIXt" "POSIXct"
> x <- xts(1:length(x), x) # 以时间为索引创建xts对象
> head(x)
[,1]
2010-01-01 00:00:00 1
2010-01-01 00:01:00 2
2010-01-01 00:02:00 3
2010-01-01 00:03:00 4
2010-01-01 00:04:00 5
2010-01-01 00:05:00 6
> indexClass(x)
[1] "POSIXt" "POSIXct"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
格式化索引时间的显示
> indexFormat(x) <- "%Y-%b-%d %H:%M:%OS3" # 通过正则格式化索引的时间显示
> head(x)
[,1]
2010-一月-01 00:00:00.000 1
2010-一月-01 00:01:00.000 2
2010-一月-01 00:02:00.000 3
2010-一月-01 00:03:00.000 4
2010-一月-01 00:04:00.000 5
2010-一月-01 00:05:00.000 6 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
查看索引时间
> .indexhour(head(x)) # 按小时取索引时间
[1] 0 0 0 0 0 0
> .indexmin(head(x)) # 按分钟取索引时间
[1] 0 1 2 3 4 5 - 1
- 2
- 3
- 4
xts对象的数据处理
数据对齐
x <- Sys.time() + 1:30
> align.time(x, 10) #整10秒对齐,秒位为10的整数倍
[1] "2013-11-18 15:42:30 CST" "2013-11-18 15:42:30 CST"
[3] "2013-11-18 15:42:30 CST" "2013-11-18 15:42:40 CST"
[5] "2013-11-18 15:42:40 CST" "2013-11-18 15:42:40 CST"
[7] "2013-11-18 15:42:40 CST" "2013-11-18 15:42:40 CST"
[29] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
> align.time(x, 60) #整60秒对齐,秒位为0,分位为整数
[1] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
[3] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
[5] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
[7] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
[9] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST"
[11] "2013-11-18 15:43:00 CST" "2013-11-18 15:43:00 CST" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
按时间分割数据,并计算
xts.ts <- xts(rnorm(231),as.Date(13514:13744,origin="1970-01-01"))
> apply.monthly(xts.ts,mean) # 按月计算均值,以每月的最后一日显示
[,1]
2007-01-31 0.17699984
2007-02-28 0.30734220
2007-03-31 -0.08757189
2007-04-30 0.18734688
2007-05-31 0.04496954
2007-06-30 0.06884836
2007-07-31 0.25081814
2007-08-19 -0.28845938
> apply.monthly(xts.ts,function(x) var(x))
# 按月计算自定义函数(方差),以每月的最后一日显示
[,1]
2007-01-31 0.9533217
2007-02-28 0.9158947
2007-03-31 1.2821450
2007-04-30 1.2805976
2007-05-31 0.9725438
2007-06-30 1.5228904
2007-07-31 0.8737030
2007-08-19 0.8490521
> apply.quarterly(xts.ts,mean) # 按季计算均值,以每季的最后一日显示
[,1]
2007-03-31 0.12642053
2007-06-30 0.09977926
2007-08-19 0.04589268
> apply.yearly(xts.ts,mean) # 按年计算均值,以年季的最后一日显示
[,1]
2007-08-19 0.09849522 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
使用to.period()函数按间隔分割数据
> data(sample_matrix)
> to.period(sample_matrix) # 默认按月分割矩阵数据
sample_matrix.Open sample_matrix.High sample_matrix.Low sample_matrix.Close
2007-01-31 50.03978 50.77336 49.76308 50.22578
2007-02-28 50.22448 51.32342 50.19101 50.77091
2007-03-31 50.81620 50.81620 48.23648 48.97490
2007-04-30 48.94407 50.33781 48.80962 49.33974
2007-05-31 49.34572 49.69097 47.51796 47.73780
2007-06-30 47.74432 47.94127 47.09144 47.76719
> class(to.period(sample_matrix))
[1] "matrix"
> samplexts <- as.xts(sample_matrix) # 默认按月分割xts类型数据
> to.period(samplexts)
samplexts.Open samplexts.High samplexts.Low samplexts.Close
2007-01-31 50.03978 50.77336 49.76308 50.22578
2007-02-28 50.22448 51.32342 50.19101 50.77091
2007-03-31 50.81620 50.81620 48.23648 48.97490
2007-04-30 48.94407 50.33781 48.80962 49.33974
2007-05-31 49.34572 49.69097 47.51796 47.73780
2007-06-30 47.74432 47.94127 47.09144 47.76719
> class(to.period(samplexts))
[1] "xts" "zoo" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
使用endpoints()函数,按间隔分割索引数据
> data(sample_matrix)
> endpoints(sample_matrix) # 默认按月分割
[1] 0 30 58 89 119 150 180
> endpoints(sample_matrix, 'days',k=7) # 按每7日分割
[1] 0 6 13 20 27 34 41 48 55 62 69 76 83 90 97 104 111 118 125
[20] 132 139 146 153 160 167 174 180
> endpoints(sample_matrix, 'weeks') # 按周分割
[1] 0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 105 112 119 126
[20] 133 140 147 154 161 168 175 180
> endpoints(sample_matrix, 'months') # 按月分割
[1] 0 30 58 89 119 150 180 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用merge()函数进行数据合并,按列合并
> (x <- xts(4:10, Sys.Date()+4:10)) # 创建2个xts数据集
[,1]
2013-11-22 4
2013-11-23 5
2013-11-24 6
2013-11-25 7
2013-11-26 8
2013-11-27 9
2013-11-28 10
> (y <- xts(1:6, Sys.Date()+1:6))
[,1]
2013-11-19 1
2013-11-20 2
2013-11-21 3
2013-11-22 4
2013-11-23 5
2013-11-24 6
> merge(x,y) # 按列合并数据,空项以NA填空
x y
2013-11-19 NA 1
2013-11-20 NA 2
2013-11-21 NA 3
2013-11-22 4 4
2013-11-23 5 5
2013-11-24 6 6
2013-11-25 7 NA
2013-11-26 8 NA
2013-11-27 9 NA
2013-11-28 10 NA
> merge(x,y, join='inner') #按索引合并数据
x y
2013-11-22 4 4
2013-11-23 5 5
2013-11-24 6 6
> merge(x,y, join='left') #以左侧为基础合并数据
x y
2013-11-22 4 4
2013-11-23 5 5
2013-11-24 6 6
2013-11-25 7 NA
2013-11-26 8 NA
2013-11-27 9 NA
2013-11-28 10 NA - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
使用split()函数切片,按行切片
> data(sample_matrix)
> x <- as.xts(sample_matrix)
> split(x)[[1]] # 默认按月进行切片,打印第一个月的数据
Open High Low Close
2007-01-02 50.03978 50.11778 49.95041 50.11778
2007-01-03 50.23050 50.42188 50.23050 50.39767
2007-01-04 50.42096 50.42096 50.26414 50.33236
2007-01-05 50.37347 50.37347 50.22103 50.33459
2007-01-06 50.24433 50.24433 50.11121 50.18112
2007-01-07 50.13211 50.21561 49.99185 49.99185
2007-01-08 50.03555 50.10363 49.96971 49.98806
> split(x, f="weeks")[[1]] # 按周切片,打印前1周数据
Open High Low Close
2007-01-02 50.03978 50.11778 49.95041 50.11778
2007-01-03 50.23050 50.42188 50.23050 50.39767
2007-01-04 50.42096 50.42096 50.26414 50.33236
2007-01-05 50.37347 50.37347 50.22103 50.33459
2007-01-06 50.24433 50.24433 50.11121 50.18112
2007-01-07 50.13211 50.21561 49.99185 49.99185
2007-01-08 50.03555 50.10363 49.96971 49.98806 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
NA值处理
> x <- xts(1:10, Sys.Date()+1:10)
> x[c(1,2,5,9,10)] <- NA
> x
[,1]
2013-11-19 NA
2013-11-20 NA
2013-11-21 3
2013-11-22 4
2013-11-23 NA
2013-11-24 6
2013-11-25 7
2013-11-26 8
2013-11-27 NA
2013-11-28 NA
> na.locf(x) #取NA的前一个,替换NA值
[,1]
2013-11-19 NA
2013-11-20 NA
2013-11-21 3
2013-11-22 4
2013-11-23 4
2013-11-24 6
2013-11-25 7
2013-11-26 8
2013-11-27 8
2013-11-28 8
> na.locf(x, fromLast=TRUE) #取NA后一个,替换NA值
[,1]
2013-11-19 3
2013-11-20 3
2013-11-21 3
2013-11-22 4
2013-11-23 6
2013-11-24 6
2013-11-25 7
2013-11-26 8
2013-11-27 NA
2013-11-28 NA - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
xts对象的数据统计计算
取xts对象的开始时间和结束时间
> xts.ts <- xts(rnorm(231),as.Date(13514:13744,origin="1970-01-01"))
> start(xts.ts) # 取开始时间
[1] "2007-01-01"
> end(xts.ts) # 取结束时间
[1] "2007-08-19"
> periodicity(xts.ts) # 以日为单位,打印开始和结束时间
Daily periodicity from 2007-01-01 to 2007-08-19- 1
- 2
- 3
- 4
- 5
- 6
- 7
计算时间区间
> data(sample_matrix)
> ndays(sample_matrix) # 计算数据有多少日
[1] 180
> nweeks(sample_matrix) # 计算数据有多少周
[1] 26
> nmonths(sample_matrix) # 计算数据有多少月
[1] 6
> nquarters(sample_matrix) # 计算数据有多少季
[1] 2
> nyears(sample_matrix) # 计算数据有多少年
[1] 1 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
按期间计算统计指标
> zoo.data <- zoo(rnorm(31)+10,as.Date(13514:13744,origin="1970-01-01"))
> ep <- endpoints(zoo.data,'weeks') # 按周获得期间索引
> ep
[1] 0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 105 112 119
[19] 126 133 140 147 154 161 168 175 182 189 196 203 210 217 224 231
> period.apply(zoo.data, INDEX=ep, FUN=function(x) mean(x)) # 计算周的均值
2007-01-07 2007-01-14 2007-01-21 2007-01-28 2007-02-04 2007-02-11 2007-02-18
10.200488 9.649387 10.304151 9.864847 10.382943 9.660175 9.857894
2007-02-25 2007-03-04 2007-03-11 2007-03-18 2007-03-25 2007-04-01 2007-04-08
10.495037 9.569531 10.292899 9.651616 10.089103 9.961048 10.304860
2007-04-15 2007-04-22 2007-04-29 2007-05-06 2007-05-13 2007-05-20 2007-05-27
9.658432 9.887531 10.608082 9.747787 10.052955 9.625730 10.430030
2007-06-03 2007-06-10 2007-06-17 2007-06-24 2007-07-01 2007-07-08 2007-07-15
9.814703 10.224869 9.509881 10.187905 10.229310 10.261725 9.855776
2007-07-22 2007-07-29 2007-08-05 2007-08-12 2007-08-19
9.445072 10.482020 9.844531 10.200488 9.649387
> head(period.max(zoo.data, INDEX=ep)) # 计算周的最大值
[,1]
2007-01-07 12.05912
2007-01-14 10.79286
2007-01-21 11.60658
2007-01-28 11.63455
2007-02-04 12.05912
2007-02-11 10.67887
> head(period.min(zoo.data, INDEX=ep)) # 计算周的最小值
[,1]
2007-01-07 8.874509
2007-01-14 8.534655
2007-01-21 9.069773
2007-01-28 8.461555
2007-02-04 9.421085
2007-02-11 8.534655
> head(period.prod(zoo.data, INDEX=ep)) # 计算周的一个指数值
[,1]
2007-01-07 11140398
2007-01-14 7582350
2007-01-21 11930334
2007-01-28 8658933
2007-02-04 12702505
2007-02-11 7702767 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
xts对象的时间序列操作
检查时间类型
> class(Sys.time());timeBased(Sys.time()) # Sys.time() 是时间类型POSIXct
[1] "POSIXct" "POSIXt"
[1] TRUE
> class(Sys.Date());timeBased(Sys.Date()) # Sys.Date() 是时间类型Date
[1] "Date"
[1] TRUE
> class(20070101);timeBased(20070101) # 20070101 不是时间类型
[1] "numeric"
[1] FALSE- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用timeBasedSeq()函数创建时间序列
> timeBasedSeq('1999/2008') # 按年
[1] "1999-01-01" "2000-01-01" "2001-01-01" "2002-01-01" "2003-01-01"
[6] "2004-01-01" "2005-01-01" "2006-01-01" "2007-01-01" "2008-01-01"
> head(timeBasedSeq('199901/2008')) # 按月
[1] "十二月 1998" "一月 1999" "二月 1999" "三月 1999" "四月 1999"
[6] "五月 1999"
> head(timeBasedSeq('199901/2008/d'),40) # 按日
[1] "十二月 1998" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[6] "一月 1999" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[11] "一月 1999" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[16] "一月 1999" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[21] "一月 1999" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[26] "一月 1999" "一月 1999" "一月 1999" "一月 1999" "一月 1999"
[31] "一月 1999" "一月 1999" "二月 1999" "二月 1999" "二月 1999"
[36] "二月 1999" "二月 1999" "二月 1999" "二月 1999" "二月 1999"
> timeBasedSeq('20080101 0830',length=100) # 按数量创建,100分钟的数据集
$from
[1] "2008-01-01 08:30:00 CST"
$to
[1] NA
$by
[1] "mins"
$length.out
[1] 100- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
按索引取数据first()和last()
> x <- xts(1:100, Sys.Date()+1:100)
> head(x)
[,1]
2013-11-19 1
2013-11-20 2
2013-11-21 3
2013-11-22 4
2013-11-23 5
2013-11-24 6
> first(x, 10) # 取前10条数据
[,1]
2013-11-19 1
2013-11-20 2
2013-11-21 3
2013-11-22 4
2013-11-23 5
2013-11-24 6
2013-11-25 7
2013-11-26 8
2013-11-27 9
2013-11-28 10
> first(x, '1 day') # 取1天的数据
[,1]
2013-11-19 1
> last(x, '1 weeks') # 取最后1周的数据
[,1]
2014-02-24 98
2014-02-25 99
2014-02-26 100- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
计算步长lag()和差分diff()
> x <- xts(1:5, Sys.Date()+1:5)
> lag(x) # 以1为步长
[,1]
2013-11-19 NA
2013-11-20 1
2013-11-21 2
2013-11-22 3
2013-11-23 4
> lag(x, k=-1, na.pad=FALSE) # 以-1为步长,并去掉NA值
[,1]
2013-11-19 2
2013-11-20 3
2013-11-21 4
2013-11-22 5
> diff(x) # 1阶差分
[,1]
2013-11-19 NA
2013-11-20 1
2013-11-21 1
2013-11-22 1
2013-11-23 1
> diff(x, lag=2) # 2阶差分
[,1]
2013-11-19 NA
2013-11-20 NA
2013-11-21 2
2013-11-22 2
2013-11-23 2 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
使用isOrdered()函数,检查向量是否排序好的
> isOrdered(1:10, increasing=TRUE)
[1] TRUE
> isOrdered(1:10, increasing=FALSE)
[1] FALSE
> isOrdered(c(1,1:10), increasing=TRUE)
[1] FALSE
> isOrdered(c(1,1:10), increasing=TRUE, strictly=FALSE)
[1] TRUE - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用make.index.unique()函数,强制唯一索引
> x <- xts(1:5, as.POSIXct("2011-01-21") + c(1,1,1,2,3)/1e3)
> x
[,1]
2011-01-21 00:00:00.000 1
2011-01-21 00:00:00.000 2
2011-01-21 00:00:00.000 3
2011-01-21 00:00:00.002 4
2011-01-21 00:00:00.003 5
> make.index.unique(x) # 增加毫秒级精度,保证索引的唯一性
[,1]
2011-01-21 00:00:00.000999 1
2011-01-21 00:00:00.001000 2
2011-01-21 00:00:00.001001 3
2011-01-21 00:00:00.002000 4
2011-01-21 00:00:00.003000 5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
查询xts对象时区
> x <- xts(1:10, Sys.Date()+1:10)
> indexTZ(x) # 时区查询
[1] "UTC"
> tzone(x)
[1] "UTC"
> str(x)
An 'xts' object on 2013-11-19/2013-11-28 containing:
Data: int [1:10, 1] 1 2 3 4 5 6 7 8 9 10
Indexed by objects of class: [Date] TZ: UTC
xts Attributes:
NULL 














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









