






Redis主从复制
主从复制
主从复制,将一台Redis服务器的数据,复制到其他Redis服务器。前者称为主(master)节点,后者称为从(slave)节点 。
在默认的情况下,Redis都是主节点,每个从节点只能有一个主节点,一个主节点可以有多个从节点。复制的数据只能从主节点复制到从节点。
配置方式
- 在从节点的配置文件中配置:slaveof {masterip} {masterport}
- 在redis-server启动命令后加入:--slaveof {masterip} {masterport}
- 在redis客户端使用命令:slaveof {masterip} {masterport}
建立主从关系
启动两个实例
//实例一:默认端口6379
./redis-server
//实例二:修改端口为6380
./redis-server --port 6380结果如下图


建立主从连接
// 把端口为6380的redis-server挂在6379的redis-server下
./redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK主节点添加key
127.0.0.1:6379} set masterKey 'This is master Key'
OK从节点查询key
127.0.0.1:6380> get masterKey
"This is master Key"可以发现主节点的Key已经同步到从节点了
主节点删除key
127.0.0.1:6379} del masterKey
(integer) 1从节点再次查询key
127.0.0.1:6380> get masterKey
(nil)可以发现从节点的key也已经被删除了
断开连接
通过slaveof {masterip} {masterport}命令建立主从复制关系以后,可以通过slaveof no one断开。从节点断开复制后,不会删除已有的数据,只是不再接受主节点新的数据变化。
使用命令slaveof no one
127.0.0.1:6380> slaveof no one
OK原理
在从节点执行slaveof命令后,主从复制的过程就开始了,可以分为6个步骤:
保存主节点信息
//从节点的redis-server中日志
27604:S 21 Aug 22:38:56.934 * SLAVE OF 127.0.0.1:6379 enabled (user request from 'id=3 addr=127.0.0.1:60092 fd=8 name= age=69 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')从上面的日志中可以看到salveof中的masterhost和masterport都被保存了下来。
建立连接
//从节点的redis-server中日志
27604:S 21 Aug 22:38:57.444 * Connecting to MASTER 127.0.0.1:6379
27604:S 21 Aug 22:38:57.445 * MASTER {-} SLAVE sync started从节点内部会使用一个每秒运行的定时任务,当发现了新的主节点后根据主节点的host和port建立一个socket连接。
当连接失败的时候定时任务会无限重试连接直到连接成功或者使用slaveof on one命令取消主从连接。
//从节点的redis-server中日志
27639:S 21 Aug 22:50:02.825 # Error condition on socket for SYNC: Connection refused发送ping命令
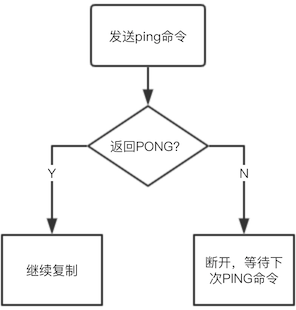
连接建立成功后从节点(salve)发送ping命令进行首次通信,主要目的是:
- 检查主从之间网络套接字是否可用
- 检查主节点当前是否可接受处理命令
从节点发送ping命令后会收到主节点的pong回复或者是超时问题,从节点便会断开连接,下次定时任务时再次发送ping命令
权限验证
如果主节点设置了requierpass参数,则从节点必须配置masterauth参数进行密码验证。
从节点会向主节点发送auth命令进行验证,auth参数为masterauth参数的值。如果验证没通过从节点会断开连接,并重连
从节点发送端口信息
身份验证之后,从节点会向主节点发送其监听的端口号,主节点将该信息保存到该从节点对应的客户端的slave_listening_port字段中
数据同步
主从复制能正常通信后,首次建立连接后主节点会把全部数据发送给从节点,相当于从节点完成数据初始化工作。
同步的方式有全量同步和部分同步。
命令复制
当主节点把所有数据复制给从节点后,主节点会把命令传输给从节点,从节点接收到命令后执行,以保证数据完整性
数据同步方式
Redis数据同步方式有全量同步和部分同步,Redis使用psync命令进行主从同步。
psync命令需要以下组件支持:
- 主从节点各自复制偏移量
- 主节点复制积压缓冲区
- 主节点运行id
复制偏移量
主节点和从节点都会维护自身复制偏移量(offset),主节点在处理完命令后,会将命令的字节长度做累加并记录,统计在info replication中的master_repl_offset中。
127.0.0.1:6379> info replication
# Replication
role:master
...
master_repl_offset:308从节点在接收到主节点发送的命令后,同样累计记录自身的偏移量,统计在info replication中的slave_repl_offset中。
127.0.0.1:6380> info replication
# Replication
role:slave
...
slave_repl_offset:1050从节点每秒钟把自身的复制偏移量上报给主节点,主节点会保存这个从节点的复制偏移量。记录在从节点对应的ip,port行的offset中
127.0.0.1:6379> info replication
# Replication
role:master
...
slave0:ip=127.0.0.1,port=6380,state=online,offset=308,lag=1复制积压缓冲区
复制积压缓冲区是主服务器维护的一个固定长度,先进先出的队列,默认为1M大小。当主节点有连接的从节点时被创建,主节点将命令发送给从节点时,还会写入复制积压缓冲区,作为写命令的备份,并且会为队列里的每个字节记录相应的复制偏移量。
复制积压缓冲区的一些数据保存在info replication中
127.0.0.1:6379> info replication
# Replication
role:master
...
repl_backlog_active:1 # 开启复制积压缓冲区
repl_backlog_size:1048576 # 缓冲区最大长度
repl_backlog_first_byte_offset:1 # 起始偏移量,计算当前缓冲区可用范围
repl_backlog_histlen:308 # 已保存数据的有效长度主节点运行ID
每个Redis节点在启动后都会动态分配一个唯一的40位十六进制字符串作为运行ID(run_id)。当Redis重启后,运行ID也会改变。
127.0.0.1:6379> info server
# Server
...
run_id:9cc202d7825028c28e91207452e993de8cdb145c
tcp_port:6379
...当主从节点第一次复制的时候,主节点会将run_id发送给从节点,从节点断线重新连接的时候,从节点将run_id发送给主节点,主节点和当前的自身的run_id判断是否需要全量复制。
- 当从节点发送run_id和主节点当前的run_id不相同,说明从节点在断线前和断线后的主节点不相同,需要全量复制
- 当从节点发送run_id和主节点当前的run_id相同,主节点根据复制偏移量和复制积压缓冲区判断是需要全量复制还是部分复制
psync命令
从节点使用psync {run_id} {offset}命令完成全量复制或者部分复制
- run_id:从节点保存的主节点run_id
- offset:从节点的复制偏移量
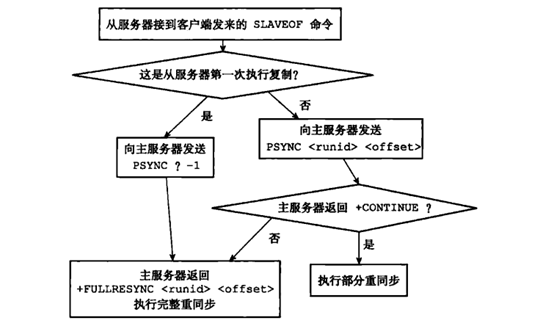
(psync运行流程, 图片来自《Redis设计与实现》)
从节点向主节点发送命令
- 从节点从未执行过slaveof或者最近一次执行了slaveof no one,从节点向主节点发送psync ? -1请求全量复制。
- 从节点执行过slaveof,从节点向主节点发送psync {run_id} {offset}命令,主节点判断是否需要全量复制。
主节点判断是否需要全量复制
- 主节点根据pysnc参数和自身服务器状态,判断是全量复制还是部分复制
- 如果主节点的Redis版本小于2.8,则返回+ERR,从节点发送重新sync命令触发全量复制
- 如果主节点的run_id和psync命令中run_id参数相同,且命令中的offset参数之后的数据都存在复制积压缓冲区,则返回+CONTINUE,从节点等待主节点的部分复制
- 如果主节点的run_id和psync命令中run_id参数不同,或者命令中的offset参数之后的数据有部分不再复制积压缓冲区中,则返回+FULLRESYNC {run_id} {offset},从节点触发全量复制,并且保存主节点的run_id和offset
心跳机制
主从复制建立之后,主从节点之间会维护两个心跳机制
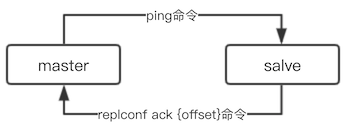
PING
主节点向从节点默认每隔10秒发送PING命令,判断从节点是否存活和连接状态。配置参数repl-ping-slave-period可以控制PING命令的频率。
REPLCONF ACK
从节点向主节点默认每隔1秒发送replconf ack {offset}命令。它的作用是:
实时监测主从节点网络状态
127.0.0.1:6379> info replication
# Replication
role:master
...
slave0:ip=127.0.0.1,port=6380,state=online,offset=308,lag=1在主节点的info replication中可以看到lag=1,表示主节点上次收到replconf ack命令的间隔,正常情况下应该为0或者1
上报自身的偏移量
从节点上报自身偏移量判断是否丢失数据,主节点把自身的offset和从节点的offset,如果从节点丢失数据,主节点会推送数据给从节点,如果从节点的offset之后的数据不在复制积压缓冲区中,则需要全量复制否则为部分复制。
实现保证从节点的数量和延迟功能
主节点中使用min-slaves-to-write(默认3个)和min-slaves-max-lag(默认10s)参数,保证从节点小于3个或所有从节点延迟大于10秒,主节点拒绝执行写命令。从节点的延迟数据是通过replconf ack命令的时间判断的,保存在info replication中的lag信息中。如果超过repl-timeout(默认60s)配置的值,则判断从节点下线并断开复制连接。















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









