







前言
开发语言:Java
使用的技术:OpenCV 版本3.4.15,Tesseract 版本5.3.0
开发环境准备
OpenCV官方GitHub下载:下载地址
OpenCV个人百度云下载:
链接:https://pan.baidu.com/s/1QlEuTmC5RQdd8-Z1T1hEzw
提取码:n57j
程序运行后生成一个OpenCV的目录:
需要在系统环境变量中添加:
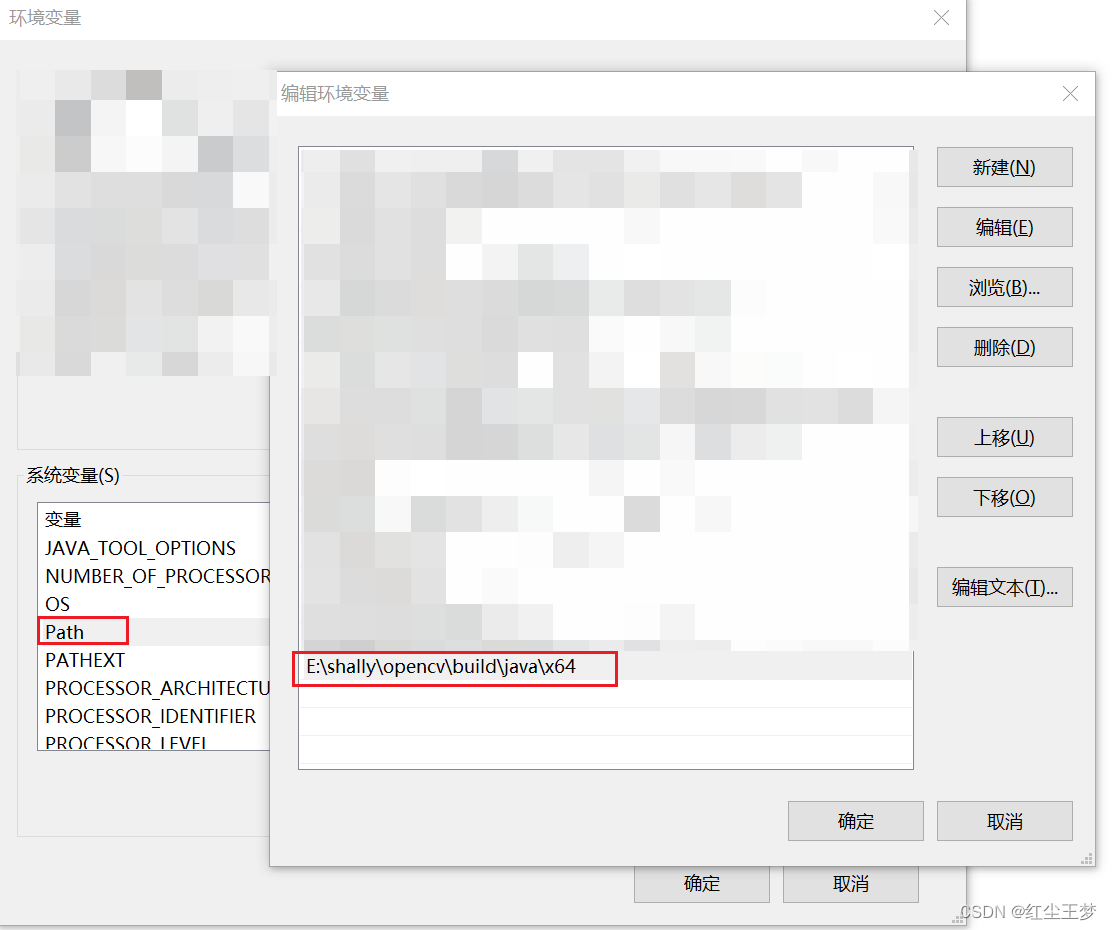
如果后续代码使用中不起作用,添加如下代码:
System.load("E:\\shally\\opencv\\build\\java\\x64\\opencv_java3415.dll");
Tesseract是通过maven导入的:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.3.0</version>
</dependency>
实例代码
测试方法:
public void oct() throws IOException {
testSRC();//计算身份证大小和位置
SIFTDemo sift = new SIFTDemo();//识别信息
sift.st();
}
计算身份证大小和位置方法:
public void testSRC() {
System.load("E:\\shally\\opencv\\build\\java\\x64\\opencv_java3415.dll");
Mat srcImg = Imgcodecs.imread("./file/3.jpg"); // 读取图片
// 转换为灰度图像,并应用高斯模糊进行平滑处理
Mat grayImg = new Mat();
Imgproc.cvtColor(srcImg, grayImg, Imgproc.COLOR_BGR2GRAY);
Imgproc.GaussianBlur(grayImg, grayImg, new Size(5, 5), 0);
// 使用Canny算子检测边缘
Mat edges = new Mat();
Imgproc.Canny(grayImg, edges, 50, 150, 3, false);
// 对边缘二值化
Mat binary = new Mat();
Imgproc.threshold(edges, binary, 0, 255, Imgproc.THRESH_BINARY_INV | Imgproc.THRESH_OTSU);
// 查找轮廓
List<MatOfPoint> contours = new ArrayList<>();
Mat hierarchy = new Mat();
Imgproc.findContours(binary, contours, hierarchy, Imgproc.RETR_TREE, Imgproc.CHAIN_APPROX_SIMPLE);
// 筛选符合条件的轮廓
double maxArea = -1;
Rect rect = null;
for (int i = 0; i < contours.size(); i++) {
double area = Imgproc.contourArea(contours.get(i));
if (area > srcImg.width() * srcImg.height() * 0.01 && area > maxArea) {
maxArea = area;
rect = Imgproc.boundingRect(contours.get(i));
}
}
// 输出识别结果
if (rect != null) {
System.out.println("身份证位置:(" + rect.x + ", " + rect.y + ")");
System.out.println("身份证尺寸:" + rect.width + " x " + rect.height);
}
// 释放内存
srcImg.release();
grayImg.release();
edges.release();
binary.release();
hierarchy.release();
for (MatOfPoint contour : contours) {
contour.release();
}
}
识别方法:
public void st() throws IOException {
// Mat image = Imgcodecs.imread("./file/3.jpg");
System.load("E:\\shally\\opencv\\build\\java\\x64\\opencv_java3415.dll");
Mat image = Imgcodecs.imread("./file/3.jpg");
// 将图像转换为灰度图像
Imgproc.cvtColor(image, image, Imgproc.COLOR_BGR2GRAY);
// 对图像进行高斯模糊以减少噪声
Imgproc.GaussianBlur(image, image, new Size(3, 3), 0);
// 将图像进行二值化处理,使得身份证正反面文字等信息更加突出
Imgproc.threshold(image, image, 0, 255, Imgproc.THRESH_BINARY + Imgproc.THRESH_OTSU);
// 查找身份证区域轮廓,并选择具有最大面积的轮廓
List<MatOfPoint> contours = new ArrayList<>();
Imgproc.findContours(image, contours, new Mat(), Imgproc.RETR_LIST, Imgproc.CHAIN_APPROX_SIMPLE);
double maxArea = 0;
MatOfPoint largestContour = null;
for (MatOfPoint contour : contours) {
if (Imgproc.contourArea(contour) > maxArea) {
maxArea = Imgproc.contourArea(contour);
largestContour = contour;
}
}
// 使用仿射变换矫正身份证图像
Mat warpedImage = new Mat(new Size(856, 540), CvType.CV_8UC1);
if (largestContour != null) {
// MatOfPoint2f src = new MatOfPoint2f(largestContour.toArray());
MatOfPoint2f src = new MatOfPoint2f(new Point(0, 0), new Point(1529, 0), new Point(1529, 953), new Point(0, 953));
MatOfPoint2f dst = new MatOfPoint2f(new Point(0, 0), new Point(855, 0), new Point(855, 539), new Point(0, 539));
Mat perspectiveTransform = Imgproc.getPerspectiveTransform(src, dst);
Imgproc.warpPerspective(image, warpedImage, perspectiveTransform, warpedImage.size(), Imgproc.INTER_LINEAR, Core.BORDER_CONSTANT, Scalar.all(0));
Rect rect = new Rect(20, 50, 350, 200);
Mat frontSideImage = new Mat(warpedImage, rect);
Imgcodecs.imwrite("./file/4.jpg", warpedImage);
rect = new Rect(25, 280, 230, 90);
Mat backSideImage = new Mat(warpedImage, rect);
Imgcodecs.imwrite("./file/5.jpg", warpedImage);
}
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
ITesseract tesseract = new Tesseract();
//tesseract.setDatapath(System.getenv("TESSDATA_PREFIX"));
tesseract.setDatapath("C:\\Program Files\\Tesseract-OCR\\tessdata");
//tesseract.setLanguage(language);
// 设置识别语言
tesseract.setLanguage("chi_sim");
//tesseract.setLanguage("jpn");
// 设置识别引擎
BufferedImage imageFile = ImageIO.read(new File("./file/4.jpg"));
tesseract.setOcrEngineMode(1);
tesseract.setPageSegMode(6);
try {
String str = tesseract.doOCR(imageFile);
str = str.trim().replaceAll("\\s+", "");
System.out.println(str);
//System.out.println(tesseract.doOCR(imageFile));
} catch (TesseractException e) {
throw new RuntimeException(e);
}
}















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









